用python让excel 飞起来(数据处理与分析操作)
本文来自《超简单:用Python让Excel飞起来》
- Excel能完成一般办公中绝大多数的数据分析工作,但是当数据量大、数据表格多时,可借助Python中功能丰富而强大的第三方模块来提高工作效率。本章将讲解如何利用pandas、xlwings等模块编写Python代码,快速完成排序、筛选、分类汇总、相关性分析、回归分析等数据分析工作。
105排序一个工作表中的数据(方法一)
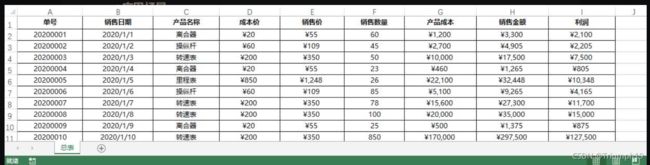
- 如下图所示为工作簿“销售表.xlsx”的工作表“总表”中的数据表格。本案例要通过Python编程对表格按指定列进行排序。
import pandas as pd
data = pd.read_excel('销售表.xlsx',sheet_name='总表') #读取要排序的工作表数据
data = data.sort_values(by='利润',ascending=False) #按“利润”列做降序排序
data.to_excel('销售表33.xlsx',sheet_name='总表',index=False) #将排序后的数据写入新工作簿的工作表
- 第3行代码用于对读取的数据按照“利润”列进行降序排序,读者可根据实际需求修改列名。如果要做升序排序,则将参数ascending设置为True。如果想要先按“利润”列做降序排序,遇到相同的利润值时再按“销售金额”列做降序排序,可将该行代码修改为“data=data.sort_values(by=[‘利润’,‘销售金额’],ascending=False)”。
106 排序一个工作表中的数据(方法二)
- 在案例105中,使用pandas模块操作数据后,数据的格式设置会丢失。如果想要保持格式不变,可结合使用pandas模块和xlwings模块来完成排序。
import xlwings as xw
import pandas as pd
app = xw.App(visible=False,add_book=False) #启动Excel程序
workbook = app.books.open('销售表.xlsx') #打开要排序的工作簿
worksheet = workbook.sheets['总表'] #指定要排序的工作表
data = worksheet.range('A1').expand('table').options(pd.DataFrame).value #读取指定工作表的数据并转换为DataFrame格式
result = data.sort_values(by='利润',ascending=False) #按“利润”列做降序排列
worksheet.range('A1').value = result #将排序结果写入指定工作表,替换原有数据
workbook.save('销售表44.xlsx') #另存为工作簿
workbook.close() #关闭工作簿
app.quit() #退出Excel程序
107 排序一个工作簿中所有工作表的数据
- 在案例105和案例106的基础上,可批量完成多个工作表数据的排序。现在需要对所有工作表的数据按“销售金额”列做降序排序。
import xlwings as xw
import pandas as pd
app = xw.App(visible=False,add_book=False) #启动Excel程序
workbook = app.books.open('销售表.xlsx') #打开要排序的工作簿
worksheet = workbook.sheets #获取工作簿中的所有工作表
for i in worksheet: #遍历工作簿中的工作表
data = i.range('A1').expand('table').options(pd.DataFrame).value # 读取指定工作表的数据并转换为DataFrame格式
result = data.sort_values(by='销售金额', ascending=False) # 按“销售金额”列做降序排列
i.range('A1').value = result #将排序结果写入当前工作表,替换原有数据
workbook.save('销售表221.xlsx') #另存为工作簿
workbook.close() #关闭工作簿
app.quit() #退出Excel程序
108 排序多个工作簿中同名工作簿的数据
- 先要对工作表“销售金额”中的数据按“销售金额”列做降序排列。
from pathlib import Path
import xlwings as xw
import pandas as pd
app = xw.App(visible=False,add_book=False) #启动Excel程序
fold_path = Path('D:\各地区销售数量') #给出要排序的工作簿所在文件夹的路径
file_list = fold_path.glob('*.xlsx') #获取文件夹下所有工作簿的文件路径
for i in file_list:#遍历获取的文件路径
workbook = app.books.open(i) #打开要排序的工作簿
worksheet = workbook.sheets['总表'] #指定要排序的工作表
data = worksheet.range('A1').expand('table').options(pd.DataFrame).value #读取指定工作表的数据并转换为DataFrame
result = data.sort_values(by='销售金额',ascending=False) #按“销售金额”列做降序排列
worksheet.range('A1').value = result #将排序结果写入指定工作表,替换原有数据
workbook.save()
workbook.close()
app.quit() #退出Excel程序
109 根据单个条件筛选一个工作表中的数据
- 筛选是最常用的数据分析工具之一。本案例要通过Python编程对一个工作表中的数据按单个筛选条件进行筛选。
import pandas as pd
data = pd.read_excel('销售表.xlsx',sheet_name='总表') #从工作表中读取要筛选的数据
pro_data = data[data['产品名称'] == '离合器'] #筛选"产品名称”为“离合器”的数据
num_data = data[data['销售数量'] >= 100] #筛选"销售数量“大于等于100的数据
pro_data.to_excel('离合器.xlsx',sheet_name='离合器',index=False) #将筛选出的数据写入新工作簿的工作表中
num_data.to_excel('销售数量大于等于100的记录.xlsx',sheet_name='销售数量大于等于100的记录',index=False) #将筛选出的数据写入新工作簿的工作表中
110 根据多个条件筛选一个工作表中的数据
import pandas as pd
data = pd.read_excel('销售表.xlsx',sheet_name='总表') #从工作表中读取要筛选的数据
condition1 = (data['产品名称']=='转速表')&(data['销售数量']>50) #设置“与”筛选条件
condition2 = (data['产品名称']=='转速表')|(data['销售数量']>=50) #设置“或”筛选条件
data1 = data[condition1] #根据“与”筛选条件筛选数据
data2 = data[condition2] #根据“或”筛选条件筛选数据
data1.to_excel('销售表51.xlsx',sheet_name='与条件筛选',index=False) #将筛选出的数据写入新工作簿的工作表中
data2.to_excel('销售表52.xlsx',sheet_name='或条件筛选',index=False) #将筛选出的数据写入新工作簿的工作表中
111 筛选一个工作簿中所有工作表的数据
import pandas as pd
workbook = pd.ExcelWriter('筛选表.xlsx') #新建工作簿
all_data = pd.read_excel('销售表.xlsx',sheet_name=None) #读取工作簿中所有工作表的数据
for i in all_data: #提取单个工作表的数据
data = all_data[i] #提取单个工作表的数据
filter_data = data[data['产品名称']=='离合器'] #筛选“产品名称”为“离合器”的数据
filter_data.to_excel(workbook,sheet_name=i,index=False) #将筛选出的数据写入新建工作簿的工作表中
workbook.save() #保存工作簿
112 筛选一个工作簿中所有工作表的数据并汇总
- 案例111将筛选出的数据存放在不同的工作表中,本案例则要将筛选出的数据汇总存放在一个工作表中。
import pandas as pd
workbook = pd.ExcelWriter('筛选表.xlsx') #新建工作簿
datas = pd.DataFrame() #创建一个空DataFrame
for i in all_data: #提取单个工作表的数据
data = all_data[i] #提取单个工作表的数据
filter_data = data[data['产品名称']=='离合器'] #筛选“产品名称”为“离合器”的数据
datas = pd.concat([datas,filter_data],axis=0) #纵向合并筛选出的数据
datas.to_excel('离合器.xlsx',sheet_name='离合器',index=False) #将合并后的数据写入新工作簿的工作表中
- 本案例的第7行代码可以修改为“datas=datas.append(filter_data)”。
113 分类汇总一个工作表
- 案例059使用pandas模块中的groupby()函数实现了数据分组,本案例要在此基础上实现数据的分类汇总,即先分组,再对组内数据进行求和、求平均值、计数等汇总运算。
import xlwings as xw
import pandas as pd
app = xw.App(visible=False,add_book=False) #启动Excel程序
workbook = app.books.open('销售表.xlsx') #打开指定工作簿
worksheet = workbook.sheets['总表'] #指定要读取数据的工作表
data = worksheet.range('A1').expand('table').options(pd.DataFrame,dtype=float).value #读取指定工作表的数据并转换为DataFrame格式
result = data.groupby('产品名称').sum() #根据“产品名称”列对数据进行分类汇总,汇总运算方式为求和
worksheet1 = workbook.sheets.add(name='分类汇总') #新增一个名为“分类汇总”的工作表
worksheet1.range('A1').value = result[['销售数量','销售金额']] #将分类汇总结果写入工作表
workbook.save('分类汇总表.xlsx') #另存为工作簿
workbook.close()
app.quit()
- 用groupby()函数对数据进行分组后,接着使用sum()函数对各组数据进行求和运算。如果要进行其他方式的汇总运算,如求平均值、计数、求最大值、求最小值,可以分别使用mean()、count()、max()、min()函数。
114 对一个工作表求和
- 如果不需要对工作表中的数据进行分类汇总,而是直接做求和运算,可以使用pandas模块中的sum()函数实现。
import xlwings as xw
import pandas as pd
app = xw.App(visible=False,add_book=False) #启动Excel程序
workbook = app.books.open('销售表.xlsx') #打开指定工作簿
worksheet = workbook.sheets['总表'] #指定要读取数据的工作表
data = worksheet.range('A1').expand('table').options(pd.DataFrame,dtype=float).value #读取指定工作表的数据并转换为DataFrame格式
result = data['成本价'].sum() #对产品名称列的数据进行求和
worksheet.range('C13').value = '合计' #将文本“合计”写入单元格C13
worksheet.range('D13').value = result #将求和结果写入单元格D13
workbook.save('求和表.xlsx') #另存为工作簿
workbook.close()
app.quit()
- 用于求和的sum()函数也可以修改为mean()、count()、max()、min()等函数来完成其他类型的统计运算。
115 对一个工作簿的所有工作表分别求和
import xlwings as xw
import pandas as pd
app = xw.App(visible=False,add_book=False) #启动Excel程序
workbook = app.books.open('销售表.xlsx') #打开指定的工作簿
worksheet = workbook.sheets #获取工作簿中的所有工作表
for i in worksheet: #遍历工作簿中的工作表
data = i.range('A1').expand('table').options(pd.DataFrame).value #读取当前工作表的数据并转换为DataFrame格式
result = data['成本价'].sum() #对“成本价”列数据进行求和
column = i.range('A1').expand('table').value[0].index('成本价') + 1 #获取“成本价”列的列号
row = i.range('A1').expand('table').shape[0] #获取数据区域最后一行的行号
i.range(row + 1,column - 1).value = '合计' #将文本“合计”写入“成本价”列的前一列最后一个单元格下方的单元格
i.range(row + 1,column).value = result # 将求和结果写入“成本价”列最后一个单元格下方的单元格
workbook.save('求和表1.xlsx') #另存为工作簿
workbook.close()
app.quit()
- 将用于求和的sum()函数修改为mean()、count()、max()、min()等函数来完成其他类型的统计运算。本案例要将求和结果放在“采购金额”列最后一个单元格下方的单元格中,但是每个工作表的数据行数不一定相同,所以先通过第9行和第10行代码获取相关单元格的列号和行号,再通过第11行和第12行代码写入所需内容。
116 在一个工作表中制作数据透视表
- Excel中的数据透视表能快速汇总大量数据并生成报表,是工作中分析数据的好帮手。虽然在Excel中制作数据透视表的过程不算复杂,但是操作步骤也不少。如果想要通过Python编程制作数据透视表,就需要掌握pandas模块中的pivot_table()函数。
import xlwings as xw #导入xlwings模块
import pandas as pd #导入pandas模块
app = xw.App(visible=False,add_book=False) #启动Excel程序
workbook = app.books.open('D:\python自动化office\销售表.xlsx') #打开指定工作簿
worksheet = workbook.sheets['总表'] #指定读取数据的工作表
data = worksheet.range('A1').expand('table').options(pd.DataFrame,dtype=float).value # 读取指定工作表的数据并转换为DataFrame格式
pivot = pd.pivot_table(data,values=['销售数量','销售金额'],index=['产品名称'],aggfunc={'销售数量':'sum','销售金额':'sum'},fill_value=0,
margins=True,margins_name='合计') #用读取的数据制作数据透视表
worksheet1 = workbook.sheets.add(name='数据透视表') #新增一个名为“数据透视表”的工作表
worksheet1.range('A1').value=pivot #将制作的数据透视表写入新增的工作表
workbook.save('数据透视表.xlsx') #另存工作簿
workbook.close()
app.quit()
- 第7行代码是制作数据透视表的核心代码。其中“销售数量”和“销售金额”是数据透视表的值字段,“产品名称”是数据透视表的行字段,可根据实际需求修改;‘sum’是指使用pandas模块中的sum()函数对值字段进行求和,可根据实际需求修改为’mean’、‘count’、‘max’、'min’等其他统计函数。
- 第10行代码中的A1是指在工作表中写入数据透视表的起始单元格,读者可根据实际需求修改为其他单元格。
- 第7行代码中的pivot_table()是pandas模块中的函数,用于创建一个电子表格样式的数据透视表。函数的第1个参数用于指定数据透视表的数据源;参数values用于指定值字段;参数index用于指定行字段;参数aggfunc用于指定汇总计算的方式,如’sum’(求和)、‘mean’(求平均值),如果要设置多个值字段的计算方式,可使用字典的形式,其中字典的键是值字段,值是计算方式;参数fill_value用于指定填充缺失值的内容,默认不填充;参数margins用于设置是否显示行列的总计数据,为False时不显示;参数margins_name用于设置总计数据行的名称。
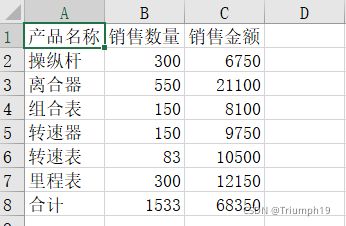
运行结果
117 使用相关系数判断数据的相关性
- 如下页图所示为某公司的产品销售利润、广告费用和成本费用数据,现要判断产品销售利润与哪些费用的相关性较大。在Excel中,可以使用CORREL()函数和相关系数工具来分析数据的相关性。在Python中,则可以使用pandas模块中DataFrame对象的相关系数计算函数——corr()。
import pandas as pd #导入pandas模块
data = pd.read_excel('销售额统计表.xlsx',sheet_name=0,index_col='序号') #读取工作簿中第1个工作表的数据
result = data.corr() #计算任意两个变量之间的相关系数
print(result) #输出计算出的相关系数
- 第2行代码用于读取工作簿“销售额统计表.xlsx”的第1个工作表中的数据,并使用“序号”列的数据作为行索引。
- 第3行代码用于计算第2行代码读取的数据中任意两个变量之间的相关系数。如果只想判断某个变量与其他变量之间的相关性,可将第3行代码修改为“result=data.corr()[‘销售利润(万元)’]”,它表示计算销售利润与其他变量之间的相关系数
- 运行本案例的代码后,会得到如下所示的相关系数矩阵。第4行第2列的数值为0.985442,表示销售利润与广告费用的相关系数,其余数值的含义依此类推。需要说明的是,矩阵中从左上角至右下角的对角线上的数值都为1,这个1没有实际意义,因为它表示变量自身与自身的相关系数,自然是1。从该矩阵可以看出,销售利润与广告费用之间存在较强的线性正相关,而与成本费用之间的相关性较弱。

118 使用描述统计和直方图制定目标
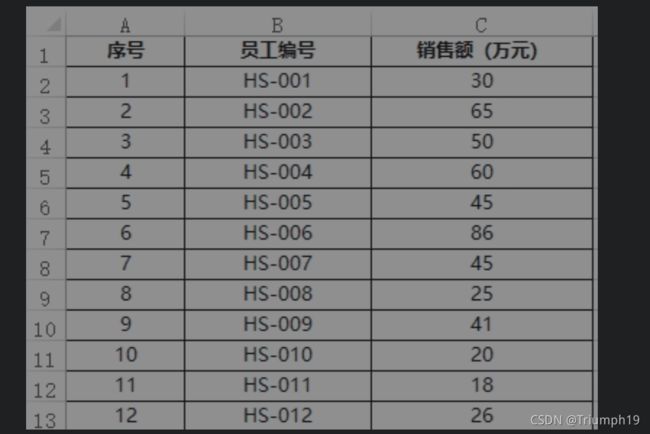
- 某公司计划对销售员实行目标管理。为了制定出科学且合理的销售目标,销售主管从几百名销售员的销售额数据中随机抽取了部分数据,作为制定销售目标的依据,如下页图所示。通过仔细观察可以发现,有很大一部分数据都落在一定的区间内,因此,可以运用Excel中的描述统计工具获取这批数据的平均数、中位数等指标,从而估算出销售目标。本案例则要通过Python编程对销售额数据进行分组并绘制直方图,然后通过进一步分析,制定出合理的销售目标。
import pandas as pd #导入pandas模块
import matplotlib.pyplot as plt #导入Matplotlib模块
import xlwings as xw #导入xlwings模块
data = pd.read_excel('员工销售业绩表.xlsx',sheet_name=0) #读取工作簿中第1个工作表的数据
data_describe = data['销售额(万元)'].astype(float).describe() #计算数据的个数、平均值、最大值和最小值等描述性统计数据
data_cut = pd.cut(data['销售额(万元)'],6) #将“销售额(万元)”列的数据分成6个均等的区间
data1 = pd.DataFrame() #创建一个空DataFrame用于汇总数据
data1['计数'] = data['销售额(万元)'].groupby(data_cut).count() #统计各区间的人数
data2 = data1.reset_index() #将行索引重置为数字序号
data2['销售额(万元)'] = data2['销售额(万元)'].apply(lambda x:str(x)) #将“销售额(万元)”列的数据转换为字符串类型
figure = plt.figure() #创建绘图窗口
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文乱码问题
plt.rcParams['axes.unicode_minus'] = False #解决坐标值为负数时无法显示负号的问题
n,bins,patches = plt.hist(data['销售额(万元)'],bins=6,edgecolor='black',linewidth=1) #使用“销售额(万元)”列的数据绘制直方图
plt.xticks(bins) #将直方图x轴的刻度标签设置为各区间的端点值
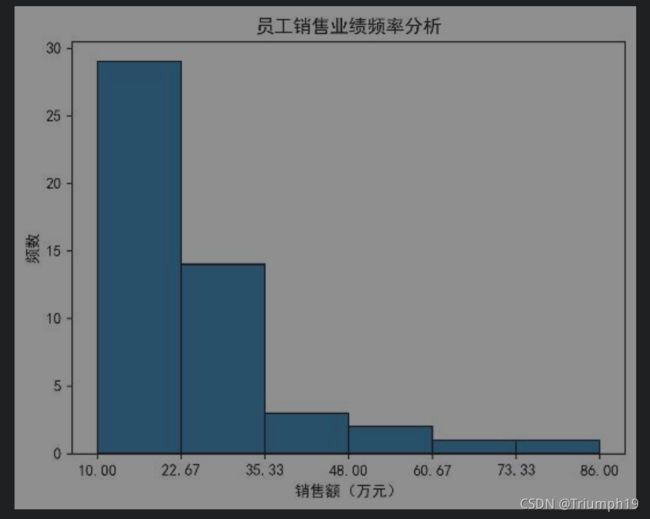
plt.title('员工销售业绩频率分析') #设置直方图的图标标题
plt.xlabel('销售额(万元)') #设置直方图x轴的标题
plt.ylabel('频数') #设置直方图y轴的标题
app = xw.App(visible=False,add_book=False) #启动Excel程序
workbook = app.books.open('员工销售业绩表.xlsx') #打开要写入分析结果的工作簿
worksheet = workbook.sheets[0] #指定工作簿中的第1个工作表
worksheet.range('H1').value = data_describe #将计算出的个数、平均值、最大值和最小值等描述性统计数据写入指定工作表
worksheet.range('E1').value = data2 #将销售额的区间及区间的人数写入指定工作表
worksheet.pictures.add(figure,name='图片1',update=True,left=400,top=200) #将绘制的直方图以图片形式插入指定的工作表
worksheet.autofit() #根据数据内容自动调整工作表的行高和列宽
workbook.save('描述统计.xlsx') #另存工作簿
app.quit() #退出Excel程序
- 第5行代码用于计算数据的个数、平均值、最大值和最小值等描述统计数据。第6行代码用于将“销售额(万元)”列的数据分为6个均等的区间,第8行代码用于统计各个区间的人数。第9行和第10行代码将第5、6、8行代码的分析结果整理成数据表格。
- 第11~18行代码完成直方图的绘制。其中最核心的是第14行代码,它使用Matplotlib模块中的hist()函数绘制直方图,绘制时将数据平均划分为6个区间(bins=6),与第6行代码所做的分组统计保持一致,此外还适当设置了直方图中柱子边框的颜色和粗细,以提高图表的可读性。第15行代码将绘制直方图的过程中划分区间得到的端点值标注在x轴上。
- 第19~25行代码用于打开工作簿“员工销售业绩表.xlsx”,在第1个工作表中写入分析结果,并以图片的形式插入绘制的直方图。其中第22行和第23行代码中的单元格E1和H1为要写入数据的区域左上角的单元格,可根据实际需求修改为其他单元格。
- (1)第2行代码中导入的Matplotlib模块是一个绘图模块,第7章将详细介绍该模块的用法。
- (2)第5行代码中的describe()是pandas模块中的函数,对于一维数组,describe()函数会返回一系列描述统计数据,如count(个数)、mean(平均值)、std(标准差)、min(最小值)、25%(下四分位数)、50%(中位数)、75%(上四分位数)和max(最大值)。
- (3)第6行代码中的cut()是pandas模块中的函数,用于对数据进行离散化处理,也就是将数据从最大值到最小值进行等距划分。函数的第1个参数是要进行离散化的一维数组;第2个参数如果为整数,表示将第1个参数中的数组划分为多少个等间距的区间,如果为序列,表示将第1个参数中的数组划分在指定的序列中。
- (4)第9行代码中的reset_index()是pandas模块中DataFrame对象的函数,用于将Data Frame对象的行索引重置为从0开始的数字序列。
运行结果

119 拟合回归方程并判断拟合程度
- 如下图所示为某公司某年每月的销售额和在两种渠道投入的广告费,如果现在需要根据广告费预测销售额,可以使用Excel中的回归分析工具拟合出线性回归方程,并通过计算R2值判断方程的拟合程度。本案例要使用Scikit-Learn模块的LinearRegression()函数快速拟合出线性回归方程,然后使用score()函数计算R2值。
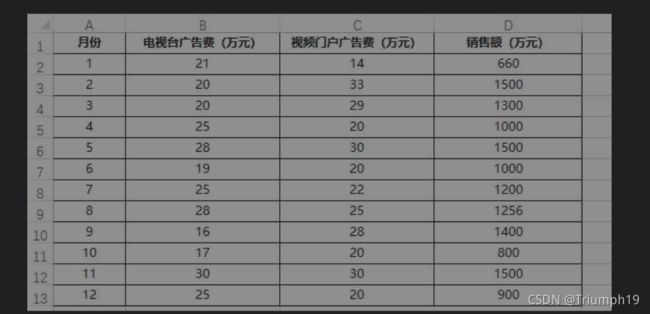
import pandas as pd #导入pandas模块
from sklearn import linear_model #导入Scikit-Learn模块中的linear_model子模块
df = pd.read_excel('各月销售额与广告费支出表.xlsx',sheet_name=0) #读取指定工作簿中第1个工作表的数据
x = df[['视频门户广告费(万元 )','电视台广告费(万元)']] #选取作为自变量的列数据
y = df['销售额(万元)'] #选取作为因变量的列数据
model = linear_model.LinearRegression() #创建一个线性回归模型
model.fit(x,y) #用自变量和因变量数据训练线性回归模型,拟合出线性回归方程
R2 = model.score(x,y) #计算R2值
print(R2) #输出R2值
120 使用回归方程预测未来值
- 案例119中通过计算R2值知道了方程的拟合程度较高,接下来就可以利用这个方程进行预测。假设某月在电视台和视频门户投入的广告费分别为30万元和40万元,下面通过Python编程预测该月的销售额。
import pandas as pd #导入pandas模块
from sklearn import linear_model #导入Scikit-Learn模块中的linear_model子模块
df = pd.read_excel('各月销售额与广告费支出表.xlsx',sheet_name=0) #读取指定工作簿中第1个工作表的数据
x = df[['视频门户广告费(万元 )','电视台广告费(万元)']] #选取作为自变量的列数据
y = df['销售额(万元)'] #选取作为因变量的列数据
model = linear_model.LinearRegression() #创建一个线性回归模型
model.fit(x,y) #用自变量和因变量数据训练线性回归模型,拟合出线性回归方程
coef = model.coef_ #获取方程中各自变量的系数
model_intercept = model.intercept_ #获取方程的截距
equation = f'y={coef[0]}*x1+{coef[1]}*x2{model_intercept:+}' #构造表达线性回归方程的字符串
print(equation) #输出线性回归方程
x1 = 40 #设置视频门户广告费
x2 = 30 #设置电视台广告费
y = coef[0] * x1 + coef[1] * x2 +model_intercept #根据线性回归方程计算出销售额
print(y) #输出计算出的销售额
- 第10行代码使用f-string方法拼接字符串。其中{model_intercept:+}表示在拼接截距时,不论截距值是正数还是负数,都显示相应的正号或负号。
运行结果
