java---爬虫
提示:以下代码仅能用于学习使用,部分代码已脱敏
前言
为了帮助女朋友完成作业从没接触过爬虫的我被赶鸭子上架,硬着头皮code。索性是不负所托,虽然代码很垃圾但是所期望的功能也完整实现。下面进入正题希望可以帮助到有同样需求的同学。
一、技术栈
<dependency>
<groupId>net.sourceforge.htmlunitgroupId>
<artifactId>htmlunitartifactId>
<version>2.61.0version>
dependency>
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>1.14.3version>
dependency>
- HtmlUnit可以理解为java版无界面浏览器,我们需要它来帮助我们获取HTML页面。因为boss的一些反爬虫机制直接使用httpclient等很麻烦很难直接获取到页面。
- Java 的HTML解析器,在我们使用HtmlUnit拉取到HTML页面时需要借助此工具来解析从而获取有价值的数据
二、编码
1.创建HtmlUnit浏览器对象
有条件的同学可以到某宝买一下高匿IP,否则请求太快很容易被封掉IP还需要登录解封很麻烦。我这里因为需要的数据量不大就采用最笨的办法增大访问间隔并将登录信息传入cookie尽可能跳过安全监测慢慢爬取。同时我们也可以模拟为登录状态进行访问在我的测试下登录状态加延迟访问的手段下基本没有再次被反扒机制检测。我们主动登录后可以将一些安全验证的cookie添加到HtmlUnit进行模拟,详情可看下方代码我将所有可能用于安全验证的5个cookie都进行了模拟。从控制台也可以看到我们的设想是成功的,完美以登录状态爬取了数据,避免了频繁请求被检测。
WebClient webClient = new WebClient(BrowserVersion.CHROME);
// 设置webClient的相关参数
webClient.setCssErrorHandler(new SilentCssErrorHandler());
//设置ajax
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//设置支持js
webClient.getOptions().setJavaScriptEnabled(true);
//CSS渲染禁止
webClient.getOptions().setCssEnabled(false);
//设置忽略证书
webClient.getOptions().setUseInsecureSSL(true);
//超时时间
webClient.getOptions().setTimeout(50000);
//设置js抛出异常:false
webClient.getOptions().setThrowExceptionOnScriptError(false);
//允许重定向
webClient.getOptions().setRedirectEnabled(true);
//允许cookie
webClient.getCookieManager().setCookiesEnabled(true);
Cookie cookie = new Cookie("www.zhipin.com","acw_tc","0bdd344616516524703935440e01a51535ae8e05f3d512a762a10e8202c9d0D");
Cookie cookie2 = new Cookie("www.zhipin.com","geek_zp_token","V1RNghE-L_31pqVtRvyhweLCi26j3VxCs~");
Cookie cookie3 = new Cookie(".zhipin.com","wt2","DWOBanb0Gmjw7-c54klh6gUVY-IRiUKpX1G-1Kf60OdAV89YbYhlXhJxeKmZADThaivqy3_Kn9i2JRNh6KoKxnA~~");
Cookie cookie4 = new Cookie(".zhipin.com","__zp_stoken__","3f39dZydrfWwRMTE%2FWhxWKicmChRII3sFVGoUWUtmf149HiMDLkdVZEcjVFFPNw8gAjsHfn9fKHRDX0EVLCA8XRtVEwcNPhtqKTF7WhR%2BbyNMXAJNFCogGyBDdS4lGisqQAI1ACRWXQMKbEU%3D");
Cookie cookie5 = new Cookie("www.zhipin.com","wd_guid","98a38c8d-7706-4f05-b59d-bae37e5fc920");
webClient.getCookieManager().addCookie(cookie);
webClient.getCookieManager().addCookie(cookie2);
webClient.getCookieManager().addCookie(cookie3);
webClient.getCookieManager().addCookie(cookie4);
webClient.getCookieManager().addCookie(cookie5);
Ip ip = new Ip();
WebClient connection = HtmlUnitUtils.getConnection(ip, webClient);
// 模拟浏览器打开一个目标网址
// HtmlPage page = connection.getPage("https://api.twitter.com/oauth/authorize?oauth_token=JrbVIAAAAAABASakAAABdsxFCaI");
HtmlPage page = connection.getPage("https://www.zhipin.com/c101280600/?query=%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0&page=2&ka=page-2");
2.解析html
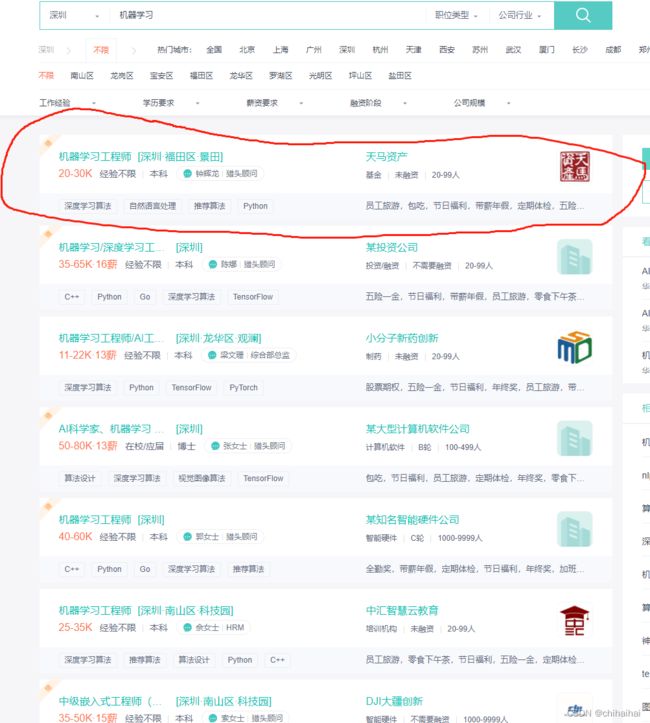
这里我们拿到了整个页面的html代码,我们需要获得下图红框中的有用信息跟点击后进入的详情页
HtmlPage page = connection.getPage("https://www.zhipin.com/c101280600/?query=%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0&page=2&ka=page-2");
Document document = Jsoup.parseBodyFragment(page.asXml());
Elements elements = document.select("div.job-list ul li");
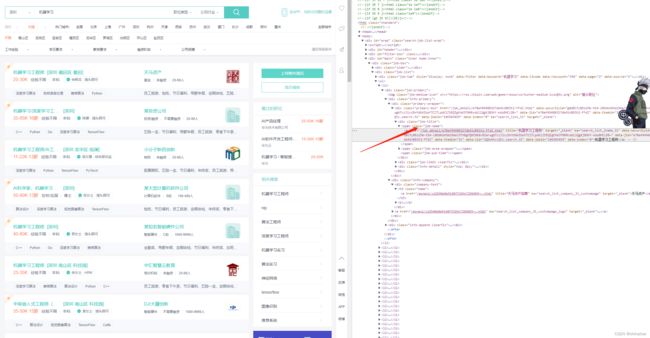
浏览器右键检查,我们来抽取下html代码。看html可以发现整个招聘信息其实就是列表ul标签组成的,所以我们只需要拿到ul下的li逐个遍历即可。document.select(“div.job-list ul li”)拿到的30个li。

3.获取具体数据字段
jsoup中为我们提供了很多方法,可以通过id,tag,class等获得元素节点在获取elements节点时记得要做一下数组非空判断不要像下方代码一样直接获取。并不是所有节点数据都百分百一样,应避免索引越界异常。
elements.forEach(csm -> {
。。。。。。。
Recruiting recruiting = new Recruiting();
Elements elements1 = csm.getElementsByClass("job-name");
String jobName = elements1.get(0).getElementsByTag("a").attr("title");
。。。。。。。
});
比如上面脱敏代码展示,我们此时想要获取职位名称在拿到li后即可通过class元素选择器来拿到span标签。顺腾摸瓜拿到下面的a标签,通过attr()方法获取a标签中的title属性值。
4. 拼接跳转链接
在获取到上述所有信息后我们还需要获取下详细招聘要求,此数据需要点击跳转后获取。这里我们需要注意的点是,之前我们只需要请求一次就可以拿到整个页面的30条数据。但是,在获取详情时,每获取一条就必须得点击一次意味着请求一次后台接口。这里百分之99会被系统检测然后黑掉IP需要重新登陆解封。BOSS直接送你一个403,土豪请买一天的高匿IP。我这里通过增大请求间隔时间的方式也堪堪把数据爬取下来的因为只是完成作业不需要太过庞大的数据量。

跳转链接这里大家需要注意下,请求地址并不是直接跳转的。我们回到a标签可以看一下其中的属性值。
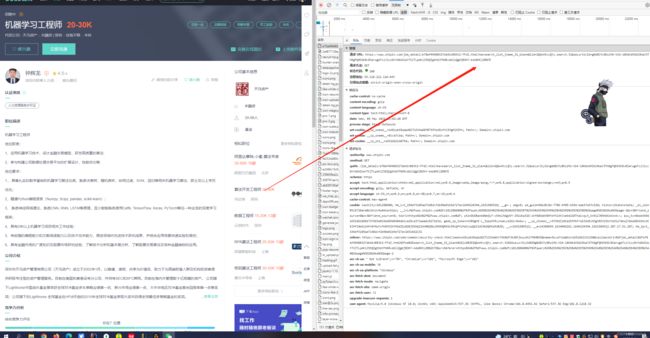
这里含有大量的安全验证字段需要我们拼接,至此我们获取到完整数据后即可写入数据库或者Excel等了。后续再使用布隆过滤器等进行去重数据清洗等。
String link = csm.getElementsByClass("job-name").get(0).getElementsByTag("a").attr("href");
String dataSecurityId = csm.getElementsByClass("job-name").get(0).getElementsByTag("a").attr("data-securityid");
String dataLid = csm.getElementsByClass("job-name").get(0).getElementsByTag("a").attr("data-lid");
String ka = csm.getElementsByClass("job-name").get(0).getElementsByTag("a").attr("ka");
try {
String url = "https://www.zhipin.com" + link + "?ka=" + ka + "_blank" + "&lid=" + dataLid + "&securityId=" + dataSecurityId;
TimeUnit.SECONDS.sleep(5);
HtmlPage detail = connection.getPage(url);
Document detailDocument = Jsoup.parseBodyFragment(detail.asXml());
String detailElements = detailDocument.select("div.text").get(0).text();
recruiting.setWorkDetail(detailElements);
mongoOperations.insert(recruiting);
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}

mongodb持久化类:
@Document(collection = "recruiting")
@NoArgsConstructor
@AllArgsConstructor
@Builder
@Data
@ToString
public class Recruiting {
//职位名称
String jobName;
//工作地区
String jobArea;
// 薪资情况
String remuneration;
// 工作经验
String experience;
//学历
String education;
// 公司名称
String company;
// 公司类型
String companyyType;
// 公司发展阶段
String companyStage;
// 公司规模
String companyScale;
// 职能标签
List<String> tags;
// 福利待遇简介
String desc;
//岗位要求详细信息
String workDetail;
}
总结
上述爬虫方式只是最低级的一种方式,离商业爬虫还差了十万八千里,只是为了帮女朋友完成下作业。望勿嘲。代码已经脱敏只提供了关键部分,如果被boss403需要登录大家也可以了解下webdriver可以帮助我们完成登录验证https://blog.csdn.net/qq_45623864/article/details/121952242?spm=1001.2101.3001.6650.6&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-6.pc_relevant_aa&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-6.pc_relevant_aa&utm_relevant_index=12
最终楼主如愿获取到了上千条招聘信息
