Python基础知识(八):模块化、标准库、第三方库
一、模块化编程理念_什么是模块_哲学思想
1、模块和包概念的进化史

- Python 程序由模块组成。一个模块对应python 源文件,一般后缀名是:.py。
- 模块由语句组成。运行Python 程序时,按照模块中语句的顺序依次执行。
- 语句是Python 程序的构造单元,用于创建对象、变量赋值、调用函数、控制语句等。
2、标准库模块(standard library)
与函数类似,模块也分为标准库模块和用户自定义模块。
Python 标准库提供了操作系统功能、网络通信、文本处理、文件处理、数学运算等基本的功能。比如:random(随机数)、math(数学运算)、time(时间处理)、file(文件处理)、os(和操作系统交互)、sys(和解释器交互)等。
另外,Python 还提供了海量的第三方模块,使用方式和标准库类似。功能覆盖了我们能想象到的所有领域,比如:科学计算、WEB 开发、大数据、人工智能、图形系统等。
3、为什么需要模块化编程
模块(module)对应于Python 源代码文件(.py 文件)。模块中可以定义变量、函数、类、普通语句。这样,我们可以将一个Python 程序分解成多个模块,便于后期的重复应用。
模块化编程(Modular Programming)将一个任务分解成多个模块。每个模块就像一个积木一样,便于后期的反复使用、反复搭建。
模块化编程有如下几个重要优势:
- 便于将一个任务分解成多个模块,实现团队协同开发,完成大规模程序
- 实现代码复用。一个模块实现后,可以被反复调用。
- 可维护性增强。
二、模块化编程的流程_设计和实现分离
1、模块化编程的流程
- 设计API,进行功能描述。
- 编码实现API 中描述的功能。
- 在模块中编写测试代码,并消除全局代码。
- 使用私有函数实现不被外部客户端调用的模块函数。
2、模块的API 和功能描述要点
API(Application Programming Interface 应用程序编程接口)是用于描述模块中提供的函数和类的功能描述和使用方式描述。
模块化编程中,首先设计的就是模块的API(即要实现的功能描述),然后开始编码实现API 中描述的功能。最后,在其他模块中导入本模块进行调用。
我们可以通过help(模块名)查看模块的API。一般使用时先导入模块然后通过help函数查看。
【示例】导入math 模块,并通过help()查看math 模块的API:
import math
help(math)
也可以在python 的api 文档中查询。首先进入python 的安装目录下的docs 子目录:

双击打开chm 文档,即可通过索引输入“math”查询到对应的API 内容:
【示例】设计计算薪水模块的API
"""
本模块用于计算公司员工的薪资
"""
company = "北京学堂"
def yearSalary(monthSalary):
"""根据传入的月薪,计算出年薪"""
pass
def daySalary(monthSalary):
"""根据传入的月薪,计算出每天的薪资"""
pass
如上模块只有功能描述和规范,需要编码人员按照要求实现编码。
我们可以通过__doc__可以获得模块的文档字符串的内容。
test.py 的源代码:
import salary
print(salary.__doc__)
print(salary.yearSalary.__doc__)
运行结果:
本模块用于计算公司员工的薪资
根据传入的月薪,计算出年薪
3、模块的创建和测试代码
每个模块都有一个名称,通过特殊变量__name__可以获取模块的名称。在正常情况下,模块名字对应源文件名。仅有一个例外,就是当一个模块被作为程序入口时(主程序、交互式提示符下),它的__name__的值为“main”。我们可以根据这个特点,将模块源代码文件中的测试代码进行独立的处理。例如:
import math
math.__name__ #输出'math'
【示例】通过__name==“main”独立处理模块的测试代码(MySalary.py)
"""
本模块用于计算公司员工的薪资
"""
company = "北京尚学堂"
def yearSalary(monthSalary):
"""根据传入的月薪,计算出年薪"""
return monthSalary * 12
def daySalary(monthSalary):
"""根据传入的月薪,计算出每天的薪资"""
return monthSalary / 22.5 # 国家规定每个月的平均工作日是22.5
if __name__ == "__main__": # 测试代码
print(yearSalary(3000))
print(daySalary(3000))
7 模块文档字符串和API 设计
我们可以在模块的第一行增加一个文档字符串,用于描述模块的相关功能。然后,通过__doc__可以获得文档字符串的内容。
【示例】模块文档字符串示例以及导入后如何读取文档字符串
test.py 的源代码:
import MySalary
print(MySalary.__doc__)
print(MySalary.yearSalary.__doc__)
运行结果:
本模块实现根据月薪计算各种薪水的功能
根据月薪,计算年薪
三、模块导入 import 和 from_import 语句详解和区别
模块化设计的好处之一就是“代码复用性高”。写好的模块可以被反复调用,重复使用。模块的导入就是“在本模块中使用其他模块”。
1、import 语句导入
import 语句的基本语法格式如下:
- import 模块名#导入一个模块
- import 模块1,模块2… #导入多个模块
- import 模块名as 模块别名#导入模块并使用新名字
import 加载的模块分为四个通用类别:
- 使用python 编写的代码(.py 文件);
- 已被编译为共享库或DLL 的C 或C++扩展;
- 包好一组模块的包
- 使用C 编写并链接到python 解释器的内置模块;
我们一般通过import 语句实现模块的导入和使用,import 本质上是使用了内置函数__import__()。
当我们通过import 导入一个模块时,python 解释器进行执行,最终会生成一个对象,这个对象就代表了被加载的模块。
import math
print(id(math))
print(type(math))
print(math.pi) #通过math.成员名来访问模块中的成员
执行结果是:
31840800
由上,我们可以看到math 模块被加载后,实际会生成一个module 类的对象,该对象被math 变量引用。我们可以通过math 变量引用模块中所有的内容。
我们通过import 导入多个模块,本质上也是生成多个module 类的对象而已。
有时候,我们也需要给模块起个别名,本质上,这个别名仅仅是新创建一个变量引用加载的模块对象而已。
import math as m
#import math
#m = math
print(m.sqrt(4)) #开方运算
2、from…import 导入
Python 中可以使用from…import 导入模块中的成员。基本语法格式如下:
from 模块名import 成员1,成员2,…
如果希望导入一个模块中的所有成员,则可以采用如下方式:
from 模块名import *
【注】尽量避免“from 模块名import ”这种写法。 它表示导入模块中所有的不是以下划线(_)开头的名字都导入到当前位置。但你不知道你导入什么名字,很有可能会覆盖掉你之前已经定义的名字。而且可读性极其的差。一般生产环境中尽量避免使用,学习时没有关系。
【示例】使用from…import 导入模块指定的成员
from math import pi,sin
print(sin(pi/2)) #输出1.0
3、import 语句和from…import 语句的区别
import 导入的是模块。from…import 导入的是模块中的一个函数/一个类。
如果进行类比的话,import 导入的是“文件”,我们要使用该“文件”下的内容,必须前面加“文件名称”。from…import 导入的是文件下的“内容”,我们直接使用这些“内容”即可,前面再也不需要加“文件名称”了。
我们自定义一个模块:calculator.py:
"""一个实现四则运算的计算器"""
def add(a,b):
return a+b
def minus(a,b):
return a-b
class MyNum():
def print123(self):
print(123)
我们在另一个模块test.py 测试:
import calculator
a = calculator.add(30,40)
# add(100,200) #不加模块名无法识别
print(a)
from calculator import *
a = add(100,200) #无需模块名,可以直接引用里面的函数/类
print(a)
b = MyNum()
b.print123()
四、import加载底层原理_importlib模块
1、 __import__()动态导入
import 语句本质上就是调用内置函数__import__(),我们可以通过它实现动态导入。给__import__()动态传递不同的的参数值,就能导入不同的模块。
【示例】使用__import__()动态导入指定的模块
s = "math"
m = __import__(s) #导入后生成的模块对象的引用给变量m
print(m.pi)
注意:一般不建议我们自行使用__import__()导入,其行为在python2 和python3 中有差异,会导致意外错误。如果需要动态导入可以使用importlib 模块。
import importlib
a = importlib.import_module("math")
print(a.pi)
2、模块的加载问题
当导入一个模块时, 模块中的代码都会被执行。不过,如果再次导入这个模块,则不会再次执行。
Python 的设计者为什么这么设计?因为,导入模块更多的时候需要的是定义模块中的变量、函数、对象等。这些并不需要反复定义和执行。“ 只导入一次import-only-once”就成了一种优化。
一个模块无论导入多少次,这个模块在整个解释器进程内有且仅有一个实例对象。
test02.py 的源代码:
print("test 模块被加载了...")
test03.py 的源代码:
import test02 #会执行test02 模块中的语句
import test02 #不会再执行test02 模块中的语句
重新加载:有时候我们确实需要重新加载一个模块,这时候可以使用:importlib.reload()方法:
import test02
import test02
print("####")
import importlib
importlib.reload(test02)
五、包的概念和创建包和导入包
1、包(package)的概念和结构
当一个项目中有很多个模块时,需要再进行组织。我们将功能类似的模块放到一起,形成了“包”。本质上,“包”就是一个必须有__init__.py 的文件夹。典型结构如下:

包下面可以包含“模块(module)”,也可以再包含“子包(subpackage)”。就像文件夹下面可以有文件,也可以有子文件夹一样。
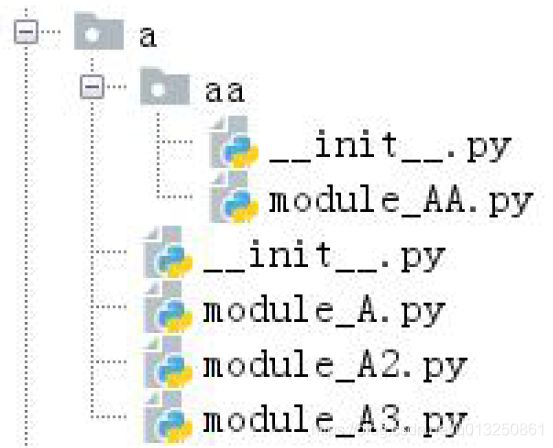
上图中,a 是上层的包,下面有一个子包:aa。可以看到每个包里面都有__init__.py 文件。
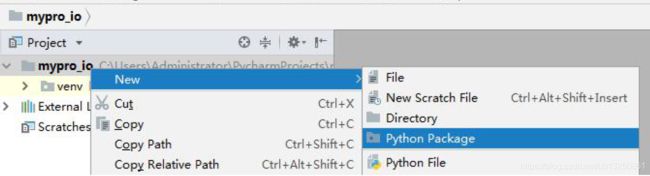
2、pycharm 中创建包
在pycharm 开发环境中创建包,非常简单。在要创建包的地方单击右键:New–>Python package 即可。pycharm 会自动帮助我们生成带有__init__.py 文件的包。
六、包的本质和init文件_批量导入_包内引用
1、导入包操作和本质
上一节中的包结构,我们需要导入module_AA.py。方式如下:
- import a.aa.module_AA
在使用时,必须加完整名称来引用,比如:a.aa.module_AA.fun_AA() - from a.aa import module_AA
在使用时,直接可以使用模块名。比如:module_AA.fun_AA() - from a.aa.module_AA import fun_AA 直接导入函数
在使用时,直接可以使用函数名。比如:fun_AA()
【注】
- from package import item 这种语法中,item 可以是包、模块,也可以是函数、类、变量。
- import item1.item2 这种语法中,item 必须是包或模块,不能是其他。
导入包的本质其实是“导入了包的__init__.py”文件。也就是说,”import pack1”意味着执行了包pack1 下面的__init__.py 文件。这样,可以在__init__.py 中批量导入我们需要的模块,而不再需要一个个导入。
init.py 的三个核心作用:
- 作为包的标识,不能删除。
- 用来实现模糊导入
- 导入包实质是执行__init__.py 文件,可以在__init__.py 文件中做这个包的初始化、以及需要统一执行代码、批量导入。
【示例】测试包的__init__.py 文件本质用法
a 包下的__init__.py 文件写入以下内容:
import turtle
import math
print("导入a 包")
b 包下的module_B1.py 文件中导入a 包,代码如下:
import a
print(a.math.pi)
执行结果如下:
导入a 包
3.141592653589793
【注】如上测试我们可以看出python 的设计者非常巧妙的通过__init__.py 文件将包转成了模块的操作。因此,可以说“包的本质还是模块”。
2、用*导入包
import * 这样的语句理论上是希望文件系统找出包中所有的子模块,然后导入它们。这可能会花长时间等。Python 解决方案是提供一个明确的包索引。
这个索引由__init__.py 定义__all__ 变量,该变量为一列表,如上例a 包下的__init__.py 中,可定义__all__ = [“module_A”,“module_A2”]
这意味着, from sound.effects import * 会从对应的包中导入以上两个子模块;
【注】尽管提供import * 的方法,仍不建议在生产代码中使用这种写法。
3、包内引用
如果是子包内的引用,可以按相对位置引入子模块以aa 包下的module_AA 中导入a包下内容为例:
from .. import module_A #..表示上级目录.表示同级目录
from . import module_A2 #.表示同级目录
七、sys.path和模块搜索路径
当我们导入某个模块文件时, Python 解释器去哪里找这个文件呢?只有找到这个文件才能读取、装载运行该模块文件。
它一般按照如下路径寻找模块文件(按照顺序寻找,找到即停不继续往下寻找):
- 内置模块
- 当前目录
- 程序的主目录
- pythonpath 目录(如果已经设置了pythonpath 环境变量)
- 标准链接库目录
- 第三方库目录(site-packages 目录)
- .pth 文件的内容(如果存在的话)
- sys.path.append()临时添加的目录
当任何一个python 程序启动时,就将上面这些搜索路径(除内置模块以外的路径)进行收集,放到sys 模块的path 属性中(sys.path)。
八、模块的本地发布_模块的安装
1、模块的本地发布
当我们完成了某个模块开发后,可以将他对外发布,其他开发者也可以以“第三方扩展库”的方式使用我们的模块。我们按照如下步骤即可实现模块的发布:
- 为模块文件创建如下结构的文件夹(一般,文件夹的名字和模块的名字一样):

- 在文件夹中创建一个名为『setup.py』的文件,内容如下:
from distutils.core import setup
setup(
name='baizhanMath2', # 对外我们模块的名字
version='1.0', # 版本号
description='这是第一个对外发布的模块,测试哦', #描述
author='gaoqi', # 作者
author_email='[email protected]',
py_modules=['baizhanMath2.demo1','baizhanMath2.demo2'] # 要发布的模块
)
- 构建一个发布文件。通过终端,cd 到模块文件夹c 下面,再键入命令:
python setup.py sdist
执行完毕后,目录结构变为:
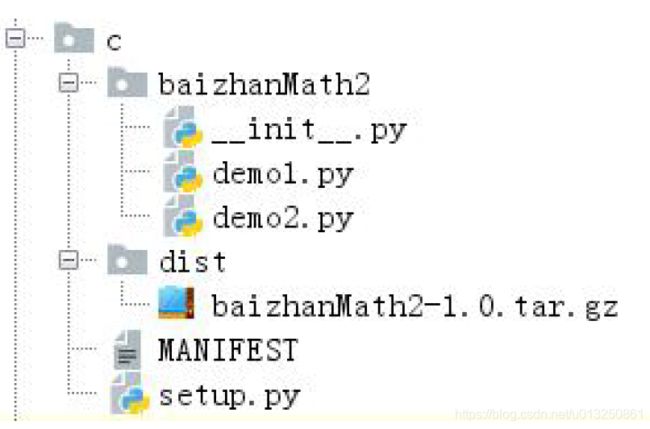
2、本地安装模块
将发布安装到你的本地计算机上。仍在cmd 命令行模式下操作,进setup.py 所在目录,键入命令:
python setup.py install
安装成功后,我们进入python 目录/Lib/site-packages 目录(第三方模块都安装的这里,python 解释器执行时也会搜索这个路径):

安装成功后,直接使用import 导入即可。
import baizhanMath2.demo1
九、PyPI官网_远程上传和管理模块_PIP方式安装模块
1、上传模块到PyPI
将自己开发好的模块上传到PyPI 网站上,将成为公开的资源,可以让全球用户自由使用。按照如下步骤做,很容易就实现上传模块操作。
- 注册PyPI 网站:http://pypi.python.org
【注意】会发送一封邮件到你的邮箱。请点击验证后继续下面的步骤。 - 创建用户信息文件.pypirc
- 方式1: 使用命令(适用Linux): 输入并执行后python setup.py register ,然后输入用户名和密码,即可。
- 方式2:使用文件(适用windows,Linux): 在用户的家目录里创建一个文件名为.pypirc, 内容为:
[distutils]
index-servers=pypi
[pypi]
repository = https://upload.pypi.org/legacy/
username = 账户名
password = 你自己的密码
【注】
Linux 的家目录: ~/.pypirc
Windows 的家目录是: c:/user/用户名
在windows 下直接创建不包含文件名的文件会失败,因此创建时文件名为“.pypirc.”,前后都有两个点即可。
- 上传并远程发布:
进入setup.py 文件所在目录,使用命令“python setup.py sdist upload”,即可以将模块代码上传并发布:

- 管理你的模块
我们登录pypi 官网,可以看到:如果你的模块已经上传成功,那么当你登录PyPI 网站后应该能在右侧导航栏看到管理入口。

点击包名进去后你可以对你的模块进行管理,当然你也可以从这里删除这个模块。
- 让别人使用你的模块
模块发布完成后,其他人只需要使用pip 就可以安装你的模块文件。比如:
pip install package-name

如果你更新了模块,别人可以可以通过–update 参数来更新:
pip install package-name update
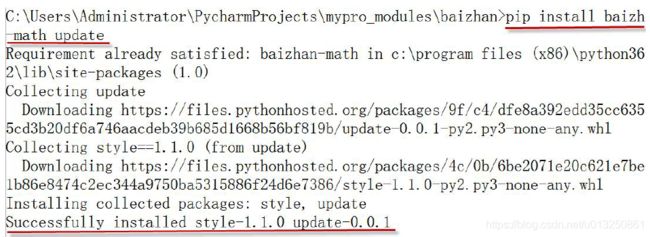
十、Python库(Library)
Python 中库是借用其他编程语言的概念,没有特别具体的定义。模块和包侧重于代码组织,有明确的定义。
一般情况,库强调的是功能性,而不是代码组织。我们通常将某个功能的“模块的集合”,称为库。
1、标准库(Standard Library)
Python 拥有一个强大的标准库。Python 语言的核心只包含数字、字符串、列表、字典、文件等常见类型和函数,而由Python 标准库提供了系统管理、网络通信、文本处理、数据库接口、图形系统、XML 处理等额外的功能。
Python 标准库的主要功能有:
- 文本处理,包含文本格式化、正则表达式匹配、文本差异计算与合并、Unicode 支持,二进制数据处理等功能
- 文件处理,包含文件操作、创建临时文件、文件压缩与归档、操作配置文件等功能
- 操作系统功能,包含线程与进程支持、IO 复用、日期与时间处理、调用系统函数、日志(logging)等功能
- 网络通信,包含网络套接字,SSL 加密通信、异步网络通信等功能
- 网络协议,支持HTTP,FTP,SMTP,POP,IMAP,NNTP,XMLRPC 等多种网络协议,并提供了编写网络服务器的框架
- W3C 格式支持,包含HTML,SGML,XML 的处理
- 其它功能,包括国际化支持、数学运算、HASH、Tkinter 等目前学过的有:random、math、time、file、os、sys 等模块。可以通过random 模块实现随机数处理、math 模块实现数学相关的运算、time 模块实现时间的处理、file 模块实现对文件的操作、OS 模块实现和操作系统的交互、sys 模块实现和解释器的交互。
2、第三方扩展库
强大的标准库奠定了python 发展的基石,丰富和不断扩展的第三方库是python 壮大的保证。我们可以进入PyPI 官网:https://pypi.org
我们可以看到发布的第三方库达到了十多万种,众多的开发者为Python 贡献了自己的力量。
常用第三方库大汇总
| 分类库 | 名称 | 说明 |
|---|---|---|
| 环境管理 | P | 非常简单的交互式python 版本管理工具 |
| 环境管理 | Pyenv | 简单的Python 版本管理工具 |
| 环境管理 | Vex | 可以在虚拟环境中执行命令 |
| 环境管理 | Virtualenv virtualenvwrapper | 创建独立Python 环境的工具 |
| 包管理 | pip | Python 包和依赖关系管理工具 |
| 包管理 | pip-tools | P保证Python 包依赖关系更新的一组工具 |
| 包管理 | Pipenv | P Python 官方推荐的新一代包管理工具 |
| 包管理 | Poetry | P 可完全取代setup.py 的包管理工具 |
| 包仓库 | warehouse | 下一代PyPI |
| 包仓库 | Devpi | PyPI 服务和打包/测试/分发工具 |
| 分发(打包为可执行文件以便分发) | PyInstaller | 将Python 程序转成独立的执行文件(跨平台) |
| 分发(打包为可执行文件以便分发) | Nuitka | 将脚本、模块、包编译成可执行文件或扩展模块 |
| 分发(打包为可执行文件以便分发) | py2app | 将Python 脚本变为独立软件包(Mac OS X) |
| 分发(打包为可执行文件以便分发) | py2exe | 将Python 脚本变为独立软件包(Windows) |
| 分发(打包为可执行文件以便分发) | pynsist | 一个用来创建Windows 安装程序的工具,可以在安装程序中打包Python 本身 |
| 构建工具(将源码编译成软件) | Buildout | 构建系统,从多个组件来创建,组装和部署应用 |
| 构建工具(将源码编译成软件) | BitBake | 针对嵌入式Linux 的类似make 的构建工具 |
| 构建工具(将源码编译成软件) | Fabricate | 对任何语言自动找到依赖关系的构建工具 |
| 交互式Python 解析器 | IPython | 功能丰富的工具, 非常有效的使用交互式Python |
| 交互式Python 解析器 | bpython | 界面丰富的Python 解析器 |
| 交互式Python 解析器 | Ptpython | 高级交互式Python 解析器, 构建于python-prompt-toolkit 之上 |
| 文件管理 | Aiofiles | 基于asyncio,提供文件异步操作 |
| 文件管理 | Imghdr | (Python 标准库)检测图片类型 |
| 文件管理 | Mimetypes | (Python 标准库)将文件名映射为MIME 类型 |
| 文件管理 | path.py | 对os.path 进行封装的模块 |
| 文件管理 | Pathlib | (Python3.4+ 标准库)跨平台的、面向对象的路径操作库 |
| 文件管理 | Unipath | 用面向对象的方式操作文件和目录 |
| 文件管理 | Watchdog | 管理文件系统事件的API 和shell 工具 |
| 日期和时间 | Arrow | 更好的Python 日期时间操作类库 |
| 日期和时间 | Chronyk | 解析手写格式的时间和日期 |
| 日期和时间 | Dateutil | Python datetime 模块的扩展 |
| 日期和时间 | PyTime | 一个简单易用的Python 模块,用于通过字符串来操作日期/时间 |
| 日期和时间 | when.py | 提供用户友好的函数来帮助用户进行常用的日期和时间操作 |
| 文本处理 | chardet | 字符编码检测器,兼容Python2 和Python3 |
| 文本处理 | Difflib | (Python 标准库)帮助我们进行差异化比较 |
| 文本处理 | Fuzzywuzzy | 模糊字符串匹配 |
| 文本处理 | Levenshtein | 快速计算编辑距离以及字符串的相似度 |
| 文本处理 | Pypinyin | 汉字拼音转换工具Python 版 |
| 文本处理 | Shortuuid | 一个生成器库,用以生成简洁的,明白的,URL安全的UUID |
| 文本处理 | simplejson | Python 的JSON 编码、解码器 |
| 文本处理 | Unidecode | Unicode 文本的ASCII 转换形式 |
| 文本处理 | Xpinyin | 一个用于把汉字转换为拼音的库 |
| 文本处理 | Pygment | 通用语法高亮工具 |
| 文本处理 | Phonenumbers | 解析,格式化,储存,验证电话号码 |
| 文本处理 | Sqlparse | 一个无验证的SQL 解析器 |
| 特殊文本格式处理 | Tablib | 一个用来处理中表格数据的模块 |
| 特殊文本格式处理 | Pyexcel | 用来读写,操作Excel 文件的库 |
| 特殊文本格式处理 | python-docx | 读取,查询以及修改word 文件 |
| 特殊文本格式处理 | PDFMiner | 一个用于从PDF 文档中抽取信息的工具 |
| 特殊文本格式处理 | Python-Markdown2 | 纯Python 实现的Markdown 解析器 |
| 特殊文本格式处理 | Csvkit | 用于转换和操作CSV 的工具 |
| 自然语言处理 | NLTK | 一个先进的平台,用以构建处理人类语言数据的Python 程序 |
| 自然语言处理 | Jieba | 中文分词工具 |
| 自然语言处理 | langid.py | 独立的语言识别系统 |
| 自然语言处理 | SnowNLP | 一个用来处理中文文本的库 |
| 自然语言处理 | Thulac | 清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包 |
| 下载器 | you-get | 一个YouTube/Youku/Niconico 视频下载器 |
| 图像处理 | pillow | 最常用的图像处理库 |
| 图像处理 | imgSeek | 一个使用视觉相似性搜索一组图片集合的项目 |
| 图像处理 | face_recognition | 简单易用的python 人脸识别 |
| 图像处理 | python-qrcode | 一个纯Python 实现的二维码生成器 |
| OCR | Pyocr | Tesseract 和Cuneiform 的一个封装(wrapper) |
| OCR | pytesseract | Google Tesseract OCR 的另一个封装(wrapper) |
| 音频处理 | Audiolazy | Python 的数字信号处理包 |
| 音频处理 | Dejavu | 音频指纹提取和识别 |
| 音频处理 | id3reader | 一个用来读取MP3 元数据的Python 模块 |
| 音频处理 | TimeSide | 开源web 音频处理框架 |
| 音频处理 | Tinytag | 一个用来读取MP3, OGG, FLAC 以及Wave文件音乐元数据的库 |
| 音频处理 | Mingus | 一个高级音乐理论和曲谱包,支持MIDI 文件和回放功能 |
| 视频和GIF 处理 | Moviepy | 一个用来进行基于脚本的视频编辑模块,适用于多种格式,包括动图GIFs |
| 视频和GIF 处理 | scikit-video | SciPy 视频处理常用程序 |
| 地理位置 | GeoDjango | 世界级地理图形web 框架 |
| 地理位置 | GeoIP | MaxMind GeoIP Legacy 数据库的Python API |
| 地理位置 | Geopy | Python 地址编码工具箱 |
| HTTP | requests | 人性化的HTTP 请求库 |
| HTTP | httplib2 | 全面的HTTP 客户端库 |
| HTTP | urllib3 | 一个具有线程安全连接池,支持文件post,清晰友好的HTTP 库 |
| Python 实现的数据库 | pickleDB | 一个简单,轻量级键值储存数据库 |
| Python 实现的数据库 | PipelineDB | 流式SQL 数据库 |
| Python 实现的数据库 | TinyDB | 一个微型的,面向文档型数据库 |
| web 框架 | Django | Python 界最流行的web 框架 |
| web 框架 | Flask | 一个Python 微型框架 |
| web 框架 | Tornado | 一个web 框架和异步网络库 |
| CMS 内容管理系统 | odoo-cms | 一个开源的,企业级CMS,基于odoo |
| CMS 内容管理系统 | djedi-cms | 一个轻量级但却非常强大的Django CMS ,考虑到了插件,内联编辑以及性能 |
| CMS 内容管理系统 | Opps | 一个为杂志,报纸网站以及大流量门户网站设计的CMS 平台,基于Django |
| 电子商务和支付系统 | django-oscar | 一个用于Django 的开源的电子商务框架 |
| 电子商务和支付系统 | django-shop | 一个基于Django 的店铺系统 |
| 电子商务和支付系统 | Shoop | 一个基于Django 的开源电子商务平台 |
| 电子商务和支付系统 | Alipay | Python 支付宝API |
| 电子商务和支付系统 | Merchant | 一个可以接收来自多种支付平台支付的Django 应用 |
| 游戏开发 | Cocos2d | 用来开发2D 游戏 |
| 游戏开发 | Panda3D | 由迪士尼开发的3D 游戏引擎,并由卡内基梅陇娱乐技术中心负责维护。使用C++ 编写, 针对Python 进行了完全的封装 |
| 游戏开发 | Pygame | Pygame 是一组Python 模块,用来编写游戏 |
| 游戏开发 | RenPy | 一个视觉小说(visual novel)引擎 |
| 计算机视觉库 | OpenCV | 开源计算机视觉库 |
| 计算机视觉库 | Pyocr | Tesseract 和Cuneiform 的包装库 |
| 计算机视觉库 | SimpleCV | 一个用来创建计算机视觉应用的开源框架 |
| 机器学习人工智能 | TensorFlow | 谷歌开源的最受欢迎的深度学习框架 |
| 机器学习人工智能 | keras | 以tensorflow/theano/CNTK 为后端的深度学习封装库,快速上手神经网络 |
| 机器学习人工智能 | Hebel | GPU 加速的深度学习库 |
| 机器学习人工智能 | Pytorch | 一个具有张量和动态神经网络,并有强大GPU加速能力的深度学习框架 |
| 机器学习人工智能 | scikit-learn | 基于SciPy 构建的机器学习Python 模块 |
| 机器学习人工智能 | NuPIC | 智能计算Numenta 平台 |
| 科学计算和数据分析 | NumPy | 使用Python 进行科学计算的基础包 |
| 科学计算和数据分析 | Pandas | 提供高性能,易用的数据结构和数据分析工具 |
| 科学计算和数据分析 | SciPy | 用于数学,科学和工程的开源软件构成的生态系统 |
| 科学计算和数据分析 | PyMC | 马尔科夫链蒙特卡洛采样工具 |
| 代码分析和调试 | code2flow | 把你的Python 和JavaScript 代码转换为流程图 |
| 代码分析和调试 | Pycallgraph | 这个库可以把你的Python 应用的流程(调用图)进行可视化 |
| 代码分析和调试 | Pylint | 一个完全可定制的源码分析器 |
| 代码分析和调试 | autopep8 | 自动格式化Python 代码,以使其符合PEP8规范 |
| 代码分析和调试 | Wdb | 一个奇异的web 调试器,通过WebSockets工作 |
| 代码分析和调试 | Lineprofiler | 逐行性能分析 |
| 代码分析和调试 | Memory Profiler | 监控Python 代码的内存使用 |
| 图形用户界面 | Pyglet | 一个Python 的跨平台窗口及多媒体库 |
| 图形用户界面 | PyQt | 跨平台用户界面框架Qt 的Python 绑定,支持Qt v4 和Qt v5 |
| 图形用户界面 | Tkinter Tkinter | 是Python GUI 的一个事实标准库 |
| 图形用户界面 | wxPython | wxPython 是wxWidgets C++ 类库和Python 语言混合的产物 |
| 网络爬虫和HTML分析 | Scrapy | 一个快速高级的屏幕爬取及网页采集框架 |
| 网络爬虫和HTML分析 | Cola | 一个分布式爬虫框架 |
| 网络爬虫和HTML分析 | Grab | 站点爬取框架 |
| 网络爬虫和HTML分析 | Pyspider | 一个强大的爬虫系统 |
| 网络爬虫和HTML分析 | html2text | 将HTML 转换为Markdown 格式文本 |
| 网络爬虫和HTML分析 | python-goose | HTML 内容/文章提取器 |
| 硬件编程 | Ino | 操作Arduino 的命令行工具 |
| 硬件编程 | Pyro | Python 机器人编程库 |
| 硬件编程 | PyUserInput | 跨平台的,控制鼠标和键盘的模块 |
| 硬件编程 | Pingo | Pingo 为类似Raspberry Pi,pcDuino, IntelGalileo 等设备提供统一的API |
PyPI 网站和PIP 模块管理工具
PyPI(Python Package Index)是python 官方的第三方库的仓库,所有人都可以下载第三方库或上传自己开发的库到PyPI。PyPI 推荐使用pip 包管理器来下载第三方库。
pip 是一个现代的,通用的Python 包管理工具。提供了对Python 包的查找、下载、安装、卸载的功能。pip 可正常工作在Windows、Mac OS、Unix/Linux 等操作系统上,但是需要至少2.6+和3.2+的CPython 或PyPy 的支持。python 2.7.9 和3.4 以后的版本已经内置累pip 程序,所以不需要安装。
安装第三方扩展库的2 种方式
第三方库有数十万种之多,以pillow 库为例讲解第三方扩展库的安装。pillow 是Python 平台事实上的图像处理标准库,本节以安装pillow 为例,给大家介绍第三方库的两种常用的安装方法。
- 第一种方式:命令行下远程安装,以安装第三方pillow 图像库为例,在命令行提示符下输入:
pip install pillow
安装完成后,我们就可以开始使用。
安装完,输入pip show pillow, 进行确认:

- 第二种方式:Pycharm 中直接安装到项目中,在Pycharm 中,依次点击:file–>setting–>Project 本项目名–>Project Interpreter

点击“+”,然后输入要安装的第三方库“pillow”,再点击按钮“Install Package”,等待安装即可,几秒种后,即提示安装成功:

这样,我们就可以在项目中直接使用第三方库pillow 了。