前言
增加了论文中的余弦退火下降方式。如图所示:

学习率是深度学习中非常重要的一环,好好学习吧!
为什么要调控学习率
在深度学习中,学习率的调整非常重要。
学习率大有如下优点:
1、加快学习速率。
2、帮助跳出局部最优值。
但存在如下缺点:
1、导致模型训练不收敛。
2、单单使用大学习率容易导致模型不精确。
学习率小有如下优点:
1、帮助模型收敛,有助于模型细化。
2、提高模型精度。
但存在如下缺点:
1、无法跳出局部最优值。
2、收敛缓慢。
学习率大和学习率小的功能是几乎相反的。因此我们适当的调整学习率,才可以最大程度的提高训练性能。
下降方式汇总
1、阶层性下降
在Keras当中,常用ReduceLROnPlateau函数实现阶层性下降。阶层性下降指的就是学习率会突然变为原来的1/2或者1/10。
使用ReduceLROnPlateau可以指定某一项指标不继续下降后,比如说验证集的loss、训练集的loss等,突然下降学习率,变为原来的1/2或者1/10。
ReduceLROnPlateau的主要参数有:
1、factor:在某一项指标不继续下降后学习率下降的比率。
2、patience:在某一项指标不继续下降几个时代后,学习率开始下降。
# 导入ReduceLROnPlateau from keras.callbacks import ReduceLROnPlateau # 定义ReduceLROnPlateau reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=2, verbose=1) # 使用ReduceLROnPlateau model.fit(X_train, Y_train, callbacks=[reduce_lr])
2、指数型下降
在Keras当中,我没有找到特别好的Callback直接实现指数型下降,于是利用Callback类实现了一个。
指数型下降指的就是学习率会随着指数函数不断下降。
具体公式如下:
![]()
1、learning_rate指的是当前的学习率。
2、learning_rate_base指的是基础学习率。
3、decay_rate指的是衰减系数。
效果如图所示:

实现方式如下,利用Callback实现,与普通的ReduceLROnPlateau调用方式类似:
import numpy as np
import matplotlib.pyplot as plt
import keras
from keras import backend as K
from keras.layers import Flatten,Conv2D,Dropout,Input,Dense,MaxPooling2D
from keras.models import Model
def exponent(global_epoch,
learning_rate_base,
decay_rate,
min_learn_rate=0,
):
learning_rate = learning_rate_base * pow(decay_rate, global_epoch)
learning_rate = max(learning_rate,min_learn_rate)
return learning_rate
class ExponentDecayScheduler(keras.callbacks.Callback):
"""
继承Callback,实现对学习率的调度
"""
def __init__(self,
learning_rate_base,
decay_rate,
global_epoch_init=0,
min_learn_rate=0,
verbose=0):
super(ExponentDecayScheduler, self).__init__()
# 基础的学习率
self.learning_rate_base = learning_rate_base
# 全局初始化epoch
self.global_epoch = global_epoch_init
self.decay_rate = decay_rate
# 参数显示
self.verbose = verbose
# learning_rates用于记录每次更新后的学习率,方便图形化观察
self.min_learn_rate = min_learn_rate
self.learning_rates = []
def on_epoch_end(self, epochs ,logs=None):
self.global_epoch = self.global_epoch + 1
lr = K.get_value(self.model.optimizer.lr)
self.learning_rates.append(lr)
#更新学习率
def on_epoch_begin(self, batch, logs=None):
lr = exponent(global_epoch=self.global_epoch,
learning_rate_base=self.learning_rate_base,
decay_rate = self.decay_rate,
min_learn_rate = self.min_learn_rate)
K.set_value(self.model.optimizer.lr, lr)
if self.verbose > 0:
print('\nBatch %05d: setting learning '
'rate to %s.' % (self.global_epoch + 1, lr))
# 载入Mnist手写数据集
mnist = keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = np.expand_dims(x_train,-1)
x_test = np.expand_dims(x_test,-1)
#-----------------------------#
# 创建模型
#-----------------------------#
inputs = Input([28,28,1])
x = Conv2D(32, kernel_size= 5,padding = 'same',activation="relu")(inputs)
x = MaxPooling2D(pool_size = 2, strides = 2, padding = 'same',)(x)
x = Conv2D(64, kernel_size= 5,padding = 'same',activation="relu")(x)
x = MaxPooling2D(pool_size = 2, strides = 2, padding = 'same',)(x)
x = Flatten()(x)
x = Dense(1024)(x)
x = Dense(256)(x)
out = Dense(10, activation='softmax')(x)
model = Model(inputs,out)
# 设定优化器,loss,计算准确率
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 设置训练参数
epochs = 10
init_epoch = 0
# 每一次训练使用多少个Batch
batch_size = 31
# 最大学习率
learning_rate_base = 1e-3
sample_count = len(x_train)
# 学习率
exponent_lr = ExponentDecayScheduler(learning_rate_base = learning_rate_base,
global_epoch_init = init_epoch,
decay_rate = 0.9,
min_learn_rate = 1e-6
)
# 利用fit进行训练
model.fit(x_train, y_train, epochs=epochs, batch_size=batch_size,
verbose=1, callbacks=[exponent_lr])
plt.plot(exponent_lr.learning_rates)
plt.xlabel('Step', fontsize=20)
plt.ylabel('lr', fontsize=20)
plt.axis([0, epochs, 0, learning_rate_base*1.1])
plt.xticks(np.arange(0, epochs, 1))
plt.grid()
plt.title('lr decay with exponent', fontsize=20)
plt.show()
3、余弦退火衰减
余弦退火衰减法,学习率会先上升再下降,这是退火优化法的思想。(关于什么是退火算法可以百度。)
上升的时候使用线性上升,下降的时候模拟cos函数下降。
效果如图所示:
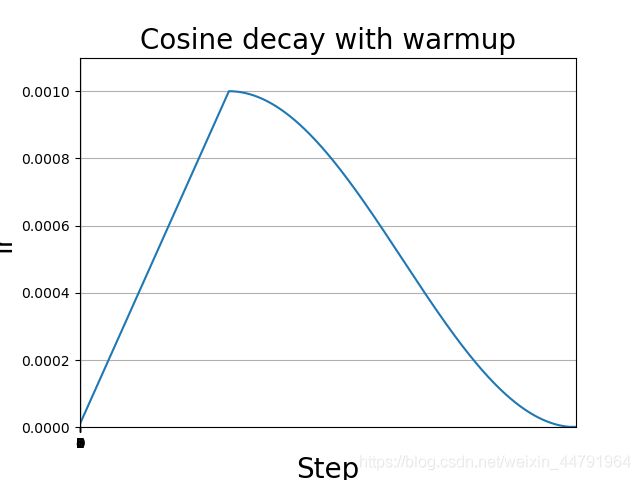
余弦退火衰减有几个比较必要的参数:
1、learning_rate_base:学习率最高值。
2、warmup_learning_rate:最开始的学习率。
3、warmup_steps:多少步长后到达顶峰值。
实现方式如下,利用Callback实现,与普通的ReduceLROnPlateau调用方式类似:
import numpy as np
import matplotlib.pyplot as plt
import keras
from keras import backend as K
from keras.layers import Flatten,Conv2D,Dropout,Input,Dense,MaxPooling2D
from keras.models import Model
def cosine_decay_with_warmup(global_step,
learning_rate_base,
total_steps,
warmup_learning_rate=0.0,
warmup_steps=0,
hold_base_rate_steps=0,
min_learn_rate=0,
):
"""
参数:
global_step: 上面定义的Tcur,记录当前执行的步数。
learning_rate_base:预先设置的学习率,当warm_up阶段学习率增加到learning_rate_base,就开始学习率下降。
total_steps: 是总的训练的步数,等于epoch*sample_count/batch_size,(sample_count是样本总数,epoch是总的循环次数)
warmup_learning_rate: 这是warm up阶段线性增长的初始值
warmup_steps: warm_up总的需要持续的步数
hold_base_rate_steps: 这是可选的参数,即当warm up阶段结束后保持学习率不变,知道hold_base_rate_steps结束后才开始学习率下降
"""
if total_steps < warmup_steps:
raise ValueError('total_steps must be larger or equal to '
'warmup_steps.')
#这里实现了余弦退火的原理,设置学习率的最小值为0,所以简化了表达式
learning_rate = 0.5 * learning_rate_base * (1 + np.cos(np.pi *
(global_step - warmup_steps - hold_base_rate_steps) / float(total_steps - warmup_steps - hold_base_rate_steps)))
#如果hold_base_rate_steps大于0,表明在warm up结束后学习率在一定步数内保持不变
if hold_base_rate_steps > 0:
learning_rate = np.where(global_step > warmup_steps + hold_base_rate_steps,
learning_rate, learning_rate_base)
if warmup_steps > 0:
if learning_rate_base < warmup_learning_rate:
raise ValueError('learning_rate_base must be larger or equal to '
'warmup_learning_rate.')
#线性增长的实现
slope = (learning_rate_base - warmup_learning_rate) / warmup_steps
warmup_rate = slope * global_step + warmup_learning_rate
#只有当global_step 仍然处于warm up阶段才会使用线性增长的学习率warmup_rate,否则使用余弦退火的学习率learning_rate
learning_rate = np.where(global_step < warmup_steps, warmup_rate,
learning_rate)
learning_rate = max(learning_rate,min_learn_rate)
return learning_rate
class WarmUpCosineDecayScheduler(keras.callbacks.Callback):
"""
继承Callback,实现对学习率的调度
"""
def __init__(self,
learning_rate_base,
total_steps,
global_step_init=0,
warmup_learning_rate=0.0,
warmup_steps=0,
hold_base_rate_steps=0,
min_learn_rate=0,
verbose=0):
super(WarmUpCosineDecayScheduler, self).__init__()
# 基础的学习率
self.learning_rate_base = learning_rate_base
# 总共的步数,训练完所有世代的步数epochs * sample_count / batch_size
self.total_steps = total_steps
# 全局初始化step
self.global_step = global_step_init
# 热调整参数
self.warmup_learning_rate = warmup_learning_rate
# 热调整步长,warmup_epoch * sample_count / batch_size
self.warmup_steps = warmup_steps
self.hold_base_rate_steps = hold_base_rate_steps
# 参数显示
self.verbose = verbose
# learning_rates用于记录每次更新后的学习率,方便图形化观察
self.min_learn_rate = min_learn_rate
self.learning_rates = []
#更新global_step,并记录当前学习率
def on_batch_end(self, batch, logs=None):
self.global_step = self.global_step + 1
lr = K.get_value(self.model.optimizer.lr)
self.learning_rates.append(lr)
#更新学习率
def on_batch_begin(self, batch, logs=None):
lr = cosine_decay_with_warmup(global_step=self.global_step,
learning_rate_base=self.learning_rate_base,
total_steps=self.total_steps,
warmup_learning_rate=self.warmup_learning_rate,
warmup_steps=self.warmup_steps,
hold_base_rate_steps=self.hold_base_rate_steps,
min_learn_rate = self.min_learn_rate)
K.set_value(self.model.optimizer.lr, lr)
if self.verbose > 0:
print('\nBatch %05d: setting learning '
'rate to %s.' % (self.global_step + 1, lr))
# 载入Mnist手写数据集
mnist = keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = np.expand_dims(x_train,-1)
x_test = np.expand_dims(x_test,-1)
#-----------------------------#
# 创建模型
#-----------------------------#
inputs = Input([28,28,1])
x = Conv2D(32, kernel_size= 5,padding = 'same',activation="relu")(inputs)
x = MaxPooling2D(pool_size = 2, strides = 2, padding = 'same',)(x)
x = Conv2D(64, kernel_size= 5,padding = 'same',activation="relu")(x)
x = MaxPooling2D(pool_size = 2, strides = 2, padding = 'same',)(x)
x = Flatten()(x)
x = Dense(1024)(x)
x = Dense(256)(x)
out = Dense(10, activation='softmax')(x)
model = Model(inputs,out)
# 设定优化器,loss,计算准确率
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 设置训练参数
epochs = 10
# 预热期
warmup_epoch = 3
# 每一次训练使用多少个Batch
batch_size = 16
# 最大学习率
learning_rate_base = 1e-3
sample_count = len(x_train)
# 总共的步长
total_steps = int(epochs * sample_count / batch_size)
# 预热步长
warmup_steps = int(warmup_epoch * sample_count / batch_size)
# 学习率
warm_up_lr = WarmUpCosineDecayScheduler(learning_rate_base=learning_rate_base,
total_steps=total_steps,
warmup_learning_rate=1e-5,
warmup_steps=warmup_steps,
hold_base_rate_steps=5,
min_learn_rate = 1e-6
)
# 利用fit进行训练
model.fit(x_train, y_train, epochs=epochs, batch_size=batch_size,
verbose=1, callbacks=[warm_up_lr])
plt.plot(warm_up_lr.learning_rates)
plt.xlabel('Step', fontsize=20)
plt.ylabel('lr', fontsize=20)
plt.axis([0, total_steps, 0, learning_rate_base*1.1])
plt.xticks(np.arange(0, epochs, 1))
plt.grid()
plt.title('Cosine decay with warmup', fontsize=20)
plt.show()
4、余弦退火衰减更新版
论文当中的余弦退火衰减并非只上升下降一次,因此我重新写了一段代码用于实现多次上升下降:
实现方式如下,利用Callback实现,与普通的ReduceLROnPlateau调用方式类似:
import numpy as np
import matplotlib.pyplot as plt
import keras
from keras import backend as K
from keras.layers import Flatten,Conv2D,Dropout,Input,Dense,MaxPooling2D
from keras.models import Model
def cosine_decay_with_warmup(global_step,
learning_rate_base,
total_steps,
warmup_learning_rate=0.0,
warmup_steps=0,
hold_base_rate_steps=0,
min_learn_rate=0,
):
"""
参数:
global_step: 上面定义的Tcur,记录当前执行的步数。
learning_rate_base:预先设置的学习率,当warm_up阶段学习率增加到learning_rate_base,就开始学习率下降。
total_steps: 是总的训练的步数,等于epoch*sample_count/batch_size,(sample_count是样本总数,epoch是总的循环次数)
warmup_learning_rate: 这是warm up阶段线性增长的初始值
warmup_steps: warm_up总的需要持续的步数
hold_base_rate_steps: 这是可选的参数,即当warm up阶段结束后保持学习率不变,知道hold_base_rate_steps结束后才开始学习率下降
"""
if total_steps < warmup_steps:
raise ValueError('total_steps must be larger or equal to '
'warmup_steps.')
#这里实现了余弦退火的原理,设置学习率的最小值为0,所以简化了表达式
learning_rate = 0.5 * learning_rate_base * (1 + np.cos(np.pi *
(global_step - warmup_steps - hold_base_rate_steps) / float(total_steps - warmup_steps - hold_base_rate_steps)))
#如果hold_base_rate_steps大于0,表明在warm up结束后学习率在一定步数内保持不变
if hold_base_rate_steps > 0:
learning_rate = np.where(global_step > warmup_steps + hold_base_rate_steps,
learning_rate, learning_rate_base)
if warmup_steps > 0:
if learning_rate_base < warmup_learning_rate:
raise ValueError('learning_rate_base must be larger or equal to '
'warmup_learning_rate.')
#线性增长的实现
slope = (learning_rate_base - warmup_learning_rate) / warmup_steps
warmup_rate = slope * global_step + warmup_learning_rate
#只有当global_step 仍然处于warm up阶段才会使用线性增长的学习率warmup_rate,否则使用余弦退火的学习率learning_rate
learning_rate = np.where(global_step < warmup_steps, warmup_rate,
learning_rate)
learning_rate = max(learning_rate,min_learn_rate)
return learning_rate
class WarmUpCosineDecayScheduler(keras.callbacks.Callback):
"""
继承Callback,实现对学习率的调度
"""
def __init__(self,
learning_rate_base,
total_steps,
global_step_init=0,
warmup_learning_rate=0.0,
warmup_steps=0,
hold_base_rate_steps=0,
min_learn_rate=0,
# interval_epoch代表余弦退火之间的最低点
interval_epoch=[0.05, 0.15, 0.30, 0.50],
verbose=0):
super(WarmUpCosineDecayScheduler, self).__init__()
# 基础的学习率
self.learning_rate_base = learning_rate_base
# 热调整参数
self.warmup_learning_rate = warmup_learning_rate
# 参数显示
self.verbose = verbose
# learning_rates用于记录每次更新后的学习率,方便图形化观察
self.min_learn_rate = min_learn_rate
self.learning_rates = []
self.interval_epoch = interval_epoch
# 贯穿全局的步长
self.global_step_for_interval = global_step_init
# 用于上升的总步长
self.warmup_steps_for_interval = warmup_steps
# 保持最高峰的总步长
self.hold_steps_for_interval = hold_base_rate_steps
# 整个训练的总步长
self.total_steps_for_interval = total_steps
self.interval_index = 0
# 计算出来两个最低点的间隔
self.interval_reset = [self.interval_epoch[0]]
for i in range(len(self.interval_epoch)-1):
self.interval_reset.append(self.interval_epoch[i+1]-self.interval_epoch[i])
self.interval_reset.append(1-self.interval_epoch[-1])
#更新global_step,并记录当前学习率
def on_batch_end(self, batch, logs=None):
self.global_step = self.global_step + 1
self.global_step_for_interval = self.global_step_for_interval + 1
lr = K.get_value(self.model.optimizer.lr)
self.learning_rates.append(lr)
#更新学习率
def on_batch_begin(self, batch, logs=None):
# 每到一次最低点就重新更新参数
if self.global_step_for_interval in [0]+[int(i*self.total_steps_for_interval) for i in self.interval_epoch]:
self.total_steps = self.total_steps_for_interval * self.interval_reset[self.interval_index]
self.warmup_steps = self.warmup_steps_for_interval * self.interval_reset[self.interval_index]
self.hold_base_rate_steps = self.hold_steps_for_interval * self.interval_reset[self.interval_index]
self.global_step = 0
self.interval_index += 1
lr = cosine_decay_with_warmup(global_step=self.global_step,
learning_rate_base=self.learning_rate_base,
total_steps=self.total_steps,
warmup_learning_rate=self.warmup_learning_rate,
warmup_steps=self.warmup_steps,
hold_base_rate_steps=self.hold_base_rate_steps,
min_learn_rate = self.min_learn_rate)
K.set_value(self.model.optimizer.lr, lr)
if self.verbose > 0:
print('\nBatch %05d: setting learning '
'rate to %s.' % (self.global_step + 1, lr))
# 载入Mnist手写数据集
mnist = keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = np.expand_dims(x_train,-1)
x_test = np.expand_dims(x_test,-1)
y_train = y_train
#-----------------------------#
# 创建模型
#-----------------------------#
inputs = Input([28,28,1])
x = Conv2D(32, kernel_size= 5,padding = 'same',activation="relu")(inputs)
x = MaxPooling2D(pool_size = 2, strides = 2, padding = 'same',)(x)
x = Conv2D(64, kernel_size= 5,padding = 'same',activation="relu")(x)
x = MaxPooling2D(pool_size = 2, strides = 2, padding = 'same',)(x)
x = Flatten()(x)
x = Dense(1024)(x)
x = Dense(256)(x)
out = Dense(10, activation='softmax')(x)
model = Model(inputs,out)
# 设定优化器,loss,计算准确率
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 设置训练参数
epochs = 10
# 预热期
warmup_epoch = 2
# 每一次训练使用多少个Batch
batch_size = 256
# 最大学习率
learning_rate_base = 1e-3
sample_count = len(x_train)
# 总共的步长
total_steps = int(epochs * sample_count / batch_size)
# 预热步长
warmup_steps = int(warmup_epoch * sample_count / batch_size)
# 学习率
warm_up_lr = WarmUpCosineDecayScheduler(learning_rate_base=learning_rate_base,
total_steps=total_steps,
warmup_learning_rate=1e-5,
warmup_steps=warmup_steps,
hold_base_rate_steps=5,
min_learn_rate=1e-6
)
# 利用fit进行训练
model.fit(x_train, y_train, epochs=epochs, batch_size=batch_size,
verbose=1, callbacks=[warm_up_lr])
plt.plot(warm_up_lr.learning_rates)
plt.xlabel('Step', fontsize=20)
plt.ylabel('lr', fontsize=20)
plt.axis([0, total_steps, 0, learning_rate_base*1.1])
plt.grid()
plt.title('Cosine decay with warmup', fontsize=20)
plt.show()
以上就是python神经网络Keras常用学习率衰减汇总的详细内容,更多关于Keras学习率衰减的资料请关注脚本之家其它相关文章!