考研--C语言
文章目录
- 一、基本数据类型
- 一、顺序程序设计
-
- 1.1 基础知识
-
- 空语句 ;
- 省略头文件的库函数:printf、scanf
- putchar
- getchar
- printf
-
-
- (?)多个printf和单个printf
-
- scanf
- sizeof():获取数据类型的字节长度
- abs、fabs
- 总结
- 1.2 程序练习
-
- 三角形面积
- 一元二次方程求解
- 二、分支程序设计
-
-
- 运算符优先级
-
-
- 1.1 关系运算符
- 1.2 算术运算符
- 1.3 逻辑运算符
-
- 关系表达式
- 总结
- 判断语句
-
-
- if语句
-
- 条件表达式
- switch语句
-
- 作业
-
-
- 闰年
- 运费
- sqrt():求平方根函数
- 判断第几天
-
- while...do、do...while
- for语句
- 程序练习
- 几种循环的比较
- 跳出循环:goto、break和continue
-
-
- goto语句
- break
- continue
- getch()和putch()
- 作业
-
- 1. 练习1
- 2. 求Π——有疑问,跑一跑
- 3. 斐波那契数列
- 4. 素数/质数
- 5. 破译密码--不会
-
-
- 三、数组
-
-
- 3.1 一维数组
-
-
- 1、赋值
- 2、斐波那契数列
-
- 3.2 二维数组
-
-
- 1、初始化(四种方法)
- 练习
- 1、成绩
- 2、行列互换
- 3、规则输出
- 4、找出数组中值最大的元素,及其行列号
-
- 3.3 二分法
-
-
- 宏
- 提高程序健壮性(有疑问)
-
- 3.4 字符数组
-
-
- 1、字符串比较
- 2、字符数组赋值
- 3、改变习惯-字符数组赋值
- 5、两个搭配-字符数组赋值
-
-
- 四、函数
-
-
- 3.1 返回值
- 3.2 参数
- 3.3 参数调用顺序
- 3.4 递归
- 3.5 函数声明
-
-
- 作业
- 1、幂:n 的 m 次方计算函数
- 2、平方根
- 3、统计输入字符
- 4、阶乘
- 5、汉诺塔问题--递归——待运行,待思考
-
- 3.6 数组元素作参数
-
-
- 作业
- 1、平均数
-
- 3.7 获取数组长度
- 3.8 变量
-
-
- 1、局部变量、全局变量
- 作业
- 2、静态存储、动态存储
- 3、static变量、auto变量、register变量、extern变量
-
- 3.1 static
- 3.2 阶乘--static、register
- 3.3 extern
- 4、多文件声明外部变量
-
- 4.1 用 extern 声明外部变量
- 4.2 用 static 声明外部变量
- 5、小结
- 6、内部函数、外部函数
-
- 练习
-
-
- 五、指针【重点章】
-
- (一)指向变量的指针
-
- 5.1 取值操作符 *、取址操作符 &
-
-
- 1、指针、指针变量
- 2、*、&运算
- 3、*、++ 优先级相同
-
- 练习——排序
-
- 5.2 数组和指针
- 5.3 用数组名做参数
-
-
-
- 练习——倒序
-
-
- 5.4 指针做参数
-
-
-
- 作业——从10个数中取出最大、最小值(指针实现)
-
-
- 5.5【本章重点】小结
-
-
- 1-1 形参:数组名,实参:数组名
- 1-2 形参:数组名,实参:指针变量
- 2-1 形参:指针变量,实参:数组名
- 2-2 形参:指针变量,实参:指针变量
-
- 5.6【本章重点】多维数组、指针
-
-
- 1、多维数组的地址
-
- 多维数组地址展示
- 2、多维数组的指针
- 打印二维数组各个元素——指针实现
- 3、作业——待验证
-
- 5.7【本章重点】字符串、指针
-
-
- 1、数组存取字符串——用数组名指向首地址,获取字符串
-
- 执行过程图解
- 2、指针存取字符串——用字符指针指向字符串
- 3、获取字符串中的某个字符——下标法、指针法
- 4、字符数组名做参数
- 5、字符指针变量做参数
-
- 优化1
- 优化2
- 优化3
- 优化4
- 优化5
- 优化6
- 6、a[ ]、*a 的区别
- 7、五大内存分区
- 8、【重要】字符指针变量、字符数组的讨论
-
- 输入语句
- 改变指针变量的值
-
- (二)指向函数的指针
-
- 1、补充知识——预编译
- 2、正文
- 3、函数指针做参数
- 4、返回指针值的函数
-
-
- 例题1——自己写
- 例题2——自己写
-
- 5、指针函数、函数指针
- 6、指针数组、指向指针的指针
-
-
- 例题1——指针数组
- 例题2——指向指针的指针
-
- (三)main() 函数的形参
-
-
-
- main() 函数传参测试
-
-
- (四)总结
- (五)指针运算(总结)
-
- 1、运算小结
- 2、void指针、const指针
- (六)知识补充——memcpy
- 九、预处理命令
-
-
- 9.1 无参宏
- 9.2 有参宏
- 9.3 宏定义替换表达式
- 9.4 宏
-
-
- 1、文件引用
- 2、条件编译
-
-
- 小结——是否分配内存
- 十、结构体、共用体
-
- (一)结构体
-
- 10.1 结构体
-
-
- 1、定义结构体类型变量
- 2、结构嵌套
- 3、结构体变量的引用
- 4、结构体变量初始化
-
- 10.2 结构体数组
-
-
- 1、定义结构体数组
- 2、结构体数组初始化
- 3、【实战】:投票系统程序实现
-
- 10.3 结构指针:指向结构体类型数据 的指针
-
-
- 1、结构指针变量-赋值
- 2、结构指针变量-访问成员
-
- 10.3 函数参数
-
-
- 1、【实战】:输出学生信息
-
- 10.4 动态存储分配
-
-
- 1、内存管理函数
- 2、链表
- 【实战】-成绩管理系统
- ==疑问==
-
- (二)共用体
-
- 10.1 一般形式
- 10.2 共用体变量的引用
- 10.3 共用体类型的特点
- 10.4 【实战】-教务管理系统
- (三)枚举类型
-
- 枚举类型两个实例
- (四)typedef
- (五)结构体、共用体 区别
- (六)宏定义、typedef 区别
一、基本数据类型
C语言中的数据类型分为:
- 基本类型:整型int,字符型char,实型/浮点型float、double,枚举型enum
- 构造类型:数组,结构体(struct),共用体(union)
- 指针类型
- 空类型:void
C语言变量:
- 内容值——普通变量
- 地址值——指针变量
一、顺序程序设计
1.1 基础知识
空语句 ;

省略头文件的库函数:printf、scanf

putchar

getchar


printf
f:format 格式




(?)多个printf和单个printf
多个printf和一个printf输出以下,结果是不同的,因为执行printf时执行了–、++,多个printf是有顺序的


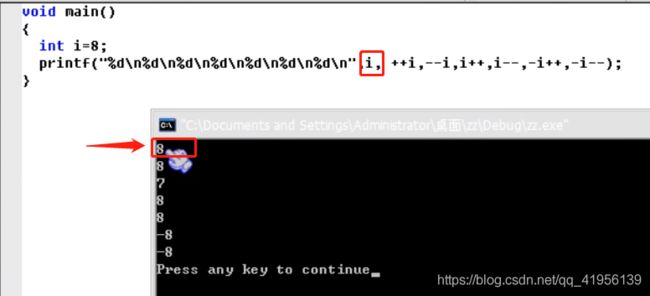

scanf
scanf()函数返回值:成功读入的变量的个数
scanf("%d%d",&a,&b);
如果a和b都被冲成功读入,scanf()返回值为2;
如果a被成功读入,scanf()返回值为1;
如果a和b都没有成功读入,scanf()返回值为0;
如果遇到错误或者end of file,scanf()返回值为EOF








sizeof():获取数据类型的字节长度
abs、fabs
- abs返回整型数据的绝对值
头文件:# include <math.h>
用法:int abs(int i);
- fabs返回浮点型数据的绝对值
头文件:# include <math.h>
用法:double fabs(double x)
求绝对值的数据类型是整型用abs,是浮点型用fabs
原文链接:ttps://blog.csdn.net/xiaotian2516/article/details/93210636
总结
| 方法 | 结果 |
|---|---|
| \n | 换行 |
| \t | Tab |
| scanf() | 格式输入函数;不需要引入头文件;2个参数 |
| printf() | 格式输出函数;不需要引入头文件;2个参数 |
| getchar() | 键盘输入函数;需要引入头文件;0个参数 |
| putchar() | 字符输出函数;需要引入头文件;1个参数 |
1.2 程序练习
三角形面积

一元二次方程求解

二、分支程序设计
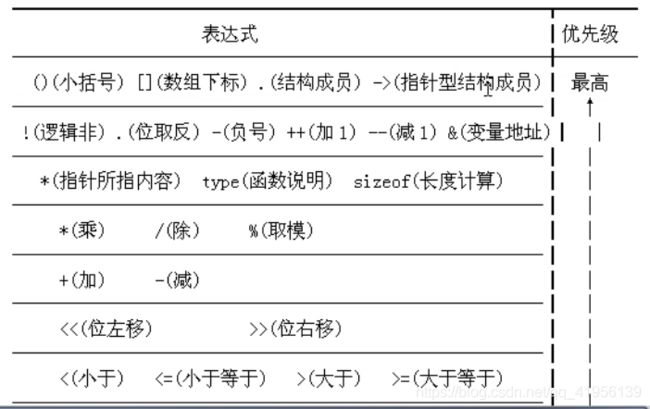
运算符优先级
!(非)、算术运算符、关系运算符、&&和||、赋值运算符
i++*2 // 相当于i*2,再i++
1.1 关系运算符
高一级:<、<=、>、>=
低一级:==、!=
1.2 算术运算符
高一级:*、/、%
低一级:+、-
1.3 逻辑运算符
优先级:!(非)、&&(与)、||(或)
关系表达式
真和假在系统中用1和0表示???


总结
判断语句
if语句
就近原则:else与其最近的if相匹配

条件表达式
表达式1 ? 表达式2 : 表达式3
| ? : | 条件运算符/三目运算符 |
|---|
嵌套:a>b?a:(c>d?c:d)
switch语句
switch(条件){
case 表达式1:
语句1;
case 表达式2:
语句2;
case 表达式3:
语句3;
default: 语句n;
}
当不写default时,在不满足条件的情况下,会跳出 {}
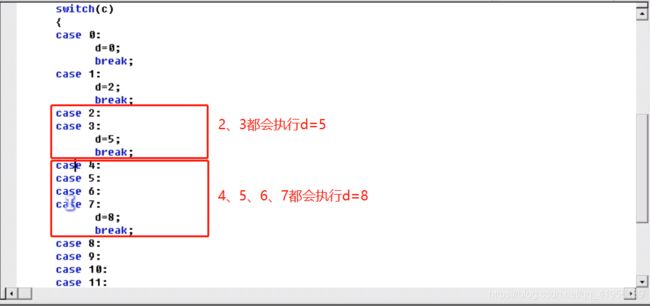
作业
闰年

闰年:该年能被bai4整除并且不能被100整除du,或者是可以被400整除
#include <stdio.h>
void main() {
int year;
scanf("%d",&year);
if(year%4==0&&year%100!=0||year%400==0) {
printf("%d 是闰年", year);
} else {
printf("%d 是平年", year);
}
}
运费

sqrt():求平方根函数
判断第几天

while…do、do…while
while…do

do…while



for语句



表达式2是判断语句,条件成立即可执行循环体:

程序练习




几种循环的比较

跳出循环:goto、break和continue
goto语句


break
break:只向外跳一层,终止循环(一层循环,判断语句不是循环)


continue
continue:结束本次循环,进入下一次循环(不会终止循环)

getch()和putch()

作业
1. 练习1

#include <stdio.h>
#include <conio.h>
void main(){
char c;
for(;;){ // 相当于while(1),永远为真
c=getch();
if(c=='') continue; // 回车
if(c=='') break; // Esc
putch(c);
}
}

#include <stdio.h>
#include <conio.h>
void main(){
for(i=100;i<200;i++){
if(i%3==0) continue;
putch(i);
}
}
2. 求Π——有疑问,跑一跑
pi的精度设置为3.141593,6位小数,10的-6次方

fabs():取绝对值

s=-s??

#include <stdio.h>
#include <math.h>
// 错误
void main(){
double sum, pi;
int count = 0;
for(i=1;i<n;i+2){
t = 1.0/i;
if(count%2==0) t = -t;
sum += t
count++;
}
pi = sum*4;
printf("%10.6f", pi);
}
// 正确
void main(){
int flag = 1;
float pi = 0, addend, denominator;
addend = 1.0; // 加数
denominator = 1; // 分母
while(fabs(addend) > 1e-6){
denominator += 2; // 分母
flag = -flag; // 符号: +1,-1
addend = flag/denominator; // 加数
pi += denominator;
}
pi = pi*4;
printf("%10.6f", pi);
}
3. 斐波那契数列

#include <stdio.h>
void main(){
int one=1, two=1;
int sum=0;
for(i=4;i<40;i++){
if(i%2==0){
one = sum;
}else{
two = sum;
}
sum = one + two;
printf("%d", sum);
}
}
答案:
#include <stdio.h>
void main(){
long F1=1, F2=1;
for(i=1;i<40;i++){
printf("%12ld,%12ld", F1,F2);
F1 = F1 + F2;
F2 = F2 + F1;
}
}
4. 素数/质数
素数:除了1和自身外,不能被其他数整除

#include <stdio.h>
#include <conio.h>
void main(){
int num;
scanf("请输入数字:%d", &num);
while(num){
for(i=1;i<num;i++){
if(num%i==0&&i!=1&&num!=i){
printf("%d不是素数", num);
break;// 不是素数
}
printf("%d是素数", num);// 是素数
}
}
}
答案:k=sqrt(m)取平方根作为最大的除数,而非数字自身作为最大的除数
因为一个合数n如果有素因子p,则必有另一个因数n/p,p与n/p必有1个小于或等于√n,从而只需要算到平方根

5. 破译密码–不会
要求:只转换字母,不转换符号


#include <stdio.h>
#include <conio.h>
void main(){
printf("------输入密码------\n");
char ch = getch();
printf("------输出密码------\n");
if(ch>'A'&&ch<'Z'){
ch
}
}
三、数组
数值数组、字符数组、指针数组、结构数组等
3.1 一维数组
定义数组:int a[10]; // 10为长度
元素赋值:a[10]=10;// 10为下标
1、赋值
- 初始化赋值:a[5]={0,1,2},进行部分赋值,其余默认为0
a[5]={0,0,0,0,0} 和 a[5]={0} 一样
还可以 a[]={0,1,2,3,4}
还可以 a[0]=0,a[1]=1,…,a[i]=i - 动态赋值:for(i=1;i<10;i++){a[i]=i}
2、斐波那契数列
动态赋值来实现
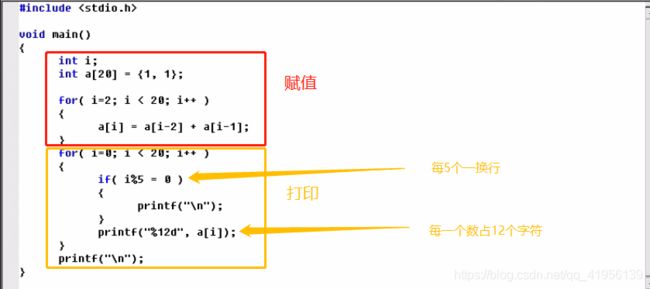

3.2 二维数组
定义数组:int a[3][4];// 3、4为行、列数
元素赋值:a[3][4]=3;// 3、4为下标,3为第四行,4为第五列
1、初始化(四种方法)
(1)分行/分段赋值
int a[3][4] = {
{0,1,2,3},
{4,5,6,7},
{8,9,10,11}
};
(2)连续赋值
int a[3][4] = {0,1,2,3,4,5,6,7,8,9,10,11};
(3)部分赋值:其余部分自动补0(和一维数组部分赋值一样)
int a[3][4] = {
{0,1},
{4},
{8}
};
(4)可以省略第一维长度(行长度),不能省略第二维长度(列长度不能省略)
举例:
int a[3][4] = {0,1,2,3,4,5,6,7,8,9,10,11};
等价于
int a[][4] = {0,1,2,3,4,5,6,7,8,9,10,11}
练习
1、成绩
三个科目,五个人。求各科平均成绩和总平均成绩。
#include 2、行列互换
#include 3、规则输出

#include 4、找出数组中值最大的元素,及其行列号
#include 3.3 二分法

宏
宏定义:类似于变量统一定义(管理时方便)
#define M 10 // 注意:其后不需要分号;
提高程序健壮性(有疑问)
下面程序中存在一个问题:当输入非法时(不满足while条件),n 的值一直是首次输入的值(因为首次输入之后边存储起来了),无法再次输入新的值
解决方法:使用 getchar() 消耗掉一个字符

更好的解决方法:使用scnaf()返回值进行判断
scanf()函数返回成功读入的变量的个数。如果它没有读取任何项目(输入非法字符,例如:希望得到数字,而用户却输入的是字符),scanf()返回值为0.当检测到“文件结尾”是,会返回EOF(EOF是在文件stdio.h中定义的特殊值,一般,#define指令把EOF的值定义为-1)
原文链接:https://blog.csdn.net/dogww/article/details/84095416
#include3.4 字符数组
| 定义 | 存放 字符 / 字符串 的数组 |
|---|---|
| 一般形式 | char 数组名[长度]; |
| 数组元素 | 一个元素存放一个字符;一个元素占一个字节 |
C语言中没有字符串类型,字符串存放在字符数组中
| 字符串输入函数 | 结束符 | |
|---|---|---|
| scanf() | 空格、回车 | 回车会存放在缓冲区中 |
| gets() | 回车 | 回车不会存放在缓冲区 |
gets() 类似于 getchar(),可以向缓冲区输入字符串和读取缓冲区中的字符串
1、字符串比较
使用 strcmp() 函数:可以比较两个字符串是否相等
int strcmp(char *str1, char *str2);
比较规则:从左到右,依次比较各个字符的ASCII码大小
// 示例
char a[]="aa";
char b[]="aaa";
strcmp(a, b); // 返回值 -97
char a[]="aa";
char b[]="aa";
strcmp(a, b); // 返回值 0
char a[]="aa";
char b[]="a";
strcmp(a, b); // 返回值 97
// 示例
char a[]="abab";
char b[]="baba";
strcmp(a, b); // 返回值 -1
char a[]="ababbaba";
char b[]="babaabab";
strcmp(a, b); // 返回值 -1
| 返回值 | 含义 |
|---|---|
| 0 | 两个字符串(字符数组)一样长 |
| >0 | 第一个参数字符串ASCII大 |
| <0 | 第二个参数字符串ASCII大 |
| -1 | 第一个参数字符串长度小 |
| 1 | 第二个参数字符串长度小 |
2、字符数组赋值
(1)初始化:可以直接赋值
char str[] = {"aaa"};
char str[] = "aaa"; // 省略 {}
(2)赋值:需要借助 strcpy() 函数
char str[20];
// str = "aaa"; // 错误
strcpy(str, "aaa"); // 正确
3、改变习惯-字符数组赋值
字符串赋值方式
| 语言 | 方式 |
|---|---|
| C语言 | candidate[0].name = "one";candidate[1].name = "two";candidate[2].name = "three"; |
| JavaScript | string name = {"one", "two", "three"}; |
candidate[i].name 相当于 js 中的 Object 对象
| C语言 | 不能写:char candidate[3] = {“one”, “two”, “three”}; 因为字符数组存储的是一个个的字符——一个元素存储一个字符,占一个字节 | 正确写法:将每一个字符串(“one”, “two”, “three”)写进结构体中 |
|---|
5、两个搭配-字符数组赋值
搭配一:
char str[20];
strcpy(str, "string");
搭配二:
char *str;
str = "string";
// 有警告:deprecated conversion from string constant to ‘char*’
// 已弃用从字符串常量到char*的转换
// 不赞成从字符串常量到char*的转换
混合使用均会报错
#include 四、函数
3.1 返回值
1、函数返回值不是必须的,需要根据函数情况设置。
2、函数返回值需要是一个确定的类型,和定义的函数类型(默认是int类型)一致,以函数类型为准(不一致也可以,会以函数类型为准进行转换,可能会存在精度缺失问题)。
3、以 void 作为函数类型定义的函数,没有 return 语句,没有返回值



- 标准函数/库函数
- 自定义函数
#include 3.2 参数
- 无参函数
- 有参函数:有返回值;定义时必须指定参数数据类型(调用时传参要类型相同,或者相兼容–按照赋值规则进行转换)

3.3 参数调用顺序
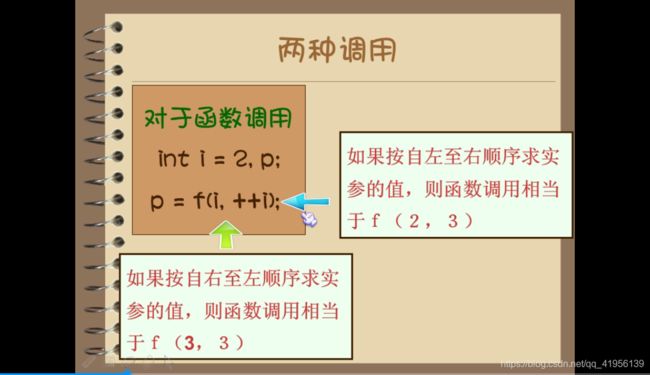
VC++6.0调用顺序是自右向左

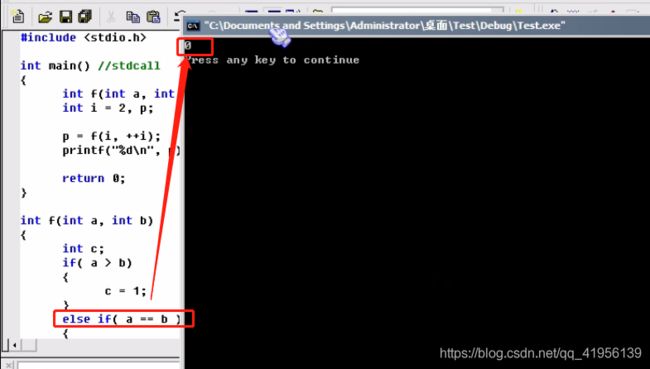
3.4 递归
函数自己作为自己的参数
m = max(a, max(b, c));
3.5 函数声明
在主函数中调用自定义函数之前,需要先编写函数声明语句
如果自定义函数定义在main函数之前,调用时可以不添加声明语句

有参函数声明时,也可以不带参数
作业

1、幂:n 的 m 次方计算函数
#include 2、平方根
支持 int 类型数据
#include 3、统计输入字符
#include 4、阶乘
递归实现(递归效率低)
#include 迭代实现(循环)
#include 使用 static 变量实现,见下面 3.8 作业
5、汉诺塔问题–递归——待运行,待思考

#include 
3.6 数组元素作参数
两种方式:
| 方式 | 传递方式 | 要求 |
|---|---|---|
| a[i] | 值传递(单向传递,赋值处理) | 数组类型(实参:数组中的元素)与形参类型一致 |
| 数组名(是数组的首地址) | 地址传递(不进行赋值处理,而是把实参数组的首地址赋值给形参数组名,二者指向相同的内存空间) | 实参数组与形参数组,是类型一致的数组 |
传递方式差异的本质原因:是否分配内存
- 前者的形参,会分配内存单元,形参与实参有着不同的内存单元
- 后者的形参,不会分配内存单元
#include 
作业
1、平均数

#include 3.7 获取数组长度
使用 sizeof() 获取所占内存空间
int data[4];
int length;
length = sizeof(data) / sizeof(data[0]); //数组占内存总空间,除以单个元素占内存空间大小
注意:当参数为数组名时,不能获取数组长度,因为是地址传递,传来的参数相当于是指针,指向内存地址
3.8 变量
| 分类依据 | 分类 |
|---|---|
| 作用域 | 局部变量、全局变量 |
| 生存时间 | 动态存储方式、静态存储方式 |
1、局部变量、全局变量
在同一个程序中,局部变量和全局变量的变量名可以相同,系统会分配两个内存,二者并不冲突。
作业

#include 2、静态存储、动态存储
| 静态存储 | 分配固定的存储空间 |
|---|---|
| 动态分配 | 根据需要动态分配存储空间 |
用户存储空间:程序区、静态存储区、动态存储区

3、static变量、auto变量、register变量、extern变量
static 变量(静态存储)不能做形参,动态存储可以做形参——auto/自动变量、形参 在内存的动态存储区
| static 变量(需要指定) | 静态存储 | 存在整个运行期间(函数执行结束不销毁,下次调用函数时,该变量值为上次结束的值) | 定义性声明,会创建存储空间 | 局部变量 |
|---|---|---|---|---|
| auto 变量(变量默认为 auto) | 动态存储 | 存在某个运行期间(如某个函数执行期间) | 定义性声明,会创建存储空间 | 局部变量 |
| register变量(存储在寄存器中,而不是内存中) | 寄存器变量 | 从寄存器中取值,速度快 | 定义性声明,会创建存储空间 | 局部变量 |
|---|---|---|---|---|
| extern变量(类似于函数调用前的声明) | 外部变量(用于声明全局变量,定义在函数内部,作用域是整个程序) | 分配在静态存储区 | 引用性声明,不会创建存储空间 | 外部变量 |



3.1 static
程序展示 static 变量值变化:
#include 3.2 阶乘–static、register
#include 3.3 extern
使用 extern 的情况:(和函数声明一样)
- 当全局变量定义在使用之后,可以通过 extern 关键字来进行声明
- 当全局变量定义在使用之前,不需要进行声明
情况一:
#include 情况二:
#include 4、多文件声明外部变量
4.1 用 extern 声明外部变量
file1

file2

4.2 用 static 声明外部变量
希望外部变量只限于被本文件引用,而不能被其他文件引用——运行时会报错
5、小结


6、内部函数、外部函数
使用 static 关键字定义的函数为内部函数,只能本文件内使用
使用 extern 关键字定义的函数为外部函数,可以省略该关键字(默认就是这个)【extern 关键字在函数内使用,而非全局使用】
练习
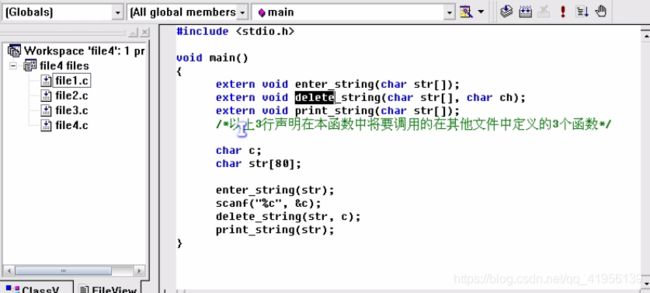

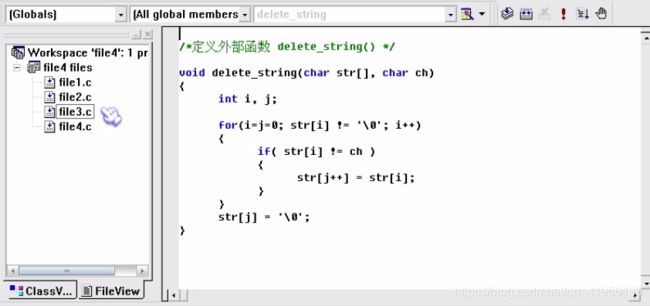
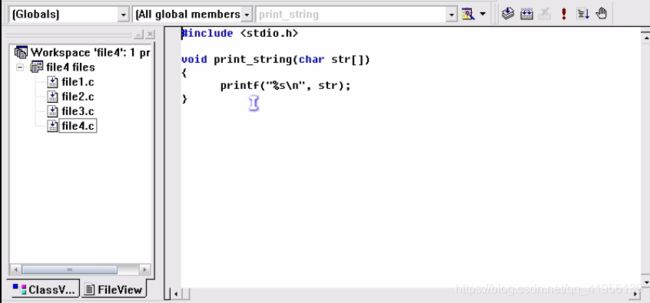
运行结果:去掉 i

五、指针【重点章】
直接访问、间接访问
指针:间接访问 | 存放地址
(一)指向变量的指针
指针变量定义且初始化之后才能使用
5.1 取值操作符 *、取址操作符 &
| 符号 | 意义 |
|---|---|
| * | 两个含义:(1)定义指针变量;(2)取值操作符 |
| & | 取址操作符 |
取值操作符:使用 ¶m 之前,需要先声明 param
int i = 2000;
int *pointer; // 定义指针变量
pointer = &i; // 取址操作符:将 i 的地址赋值给 pointer
printf("%d",*pointer); // 取值操作符:取出pointer指向的地址的数值。*pointer = 2000
1、指针、指针变量
| 名词 | 意义 |
|---|---|
| 指针 | 地址(变量的地址) |
| 指针变量 | 变量(存放变量的地址/存放指针) |
指针变量:只能存放地址。若是将非地址赋值给指针变量,也会当成地址进行处理。
基类型:指针指向的变量的数据类型




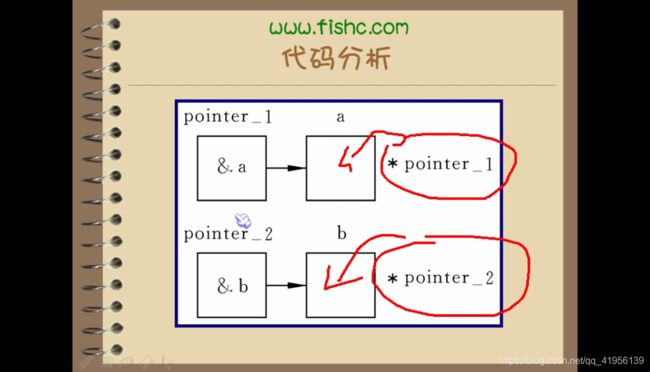
2、*、&运算
二者优先级相同,但是结合方式:自右向左。
&*pointer // 先取值*pointer,再取址&(*pointer)——结果为:值
*&pointer // 先取址&pointer,再取址*(&pointer)——结果为:址
*&a 等价于 *a
3、*、++ 优先级相同
++、* 优先级相同,结合方式:自左向右
*p++
先 *p
再 *(p+1)
练习——排序
#include 5.2 数组和指针
- 数组和指针的指向都是地址
- 定义时,二者均分配了内存空间,但是指针的空间可以随时消除,数组空间不行
- 指针变量可以指向一个普通变量,也可以指向数组元素
- 数组元素的指针,就是数组元素的地址。eg:
p = &a[2];
引用一个数组元素,可以使用下标法、指针法
下标法:a[i]
指针法:*(a+i) // a 为数组名
指针法:*(p+i) // p 为指针变量,p初值为a(数组首地址,即&a[0])
获取数组中的全部元素,有三种方法:
- 下标法:a[i]
- 根据数组名计算地址:* (a+i) ,其中 a = &a[0]
- 指针变量:* (p+i) ,其中 p = &a[0]
代码实现:


以下程序运行错误:

错误原因:待讲解
5.3 用数组名做参数
数组名作为实参时,要求形参的数据类型为指针类型——因为数组名作实参,传递的实际上是地址
以下两种写法等价:
fn(int arr[]){}
fn(int *arr){}
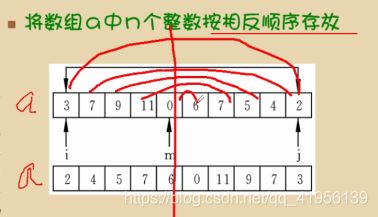
练习——倒序


5.4 指针做参数
指针作为实参时,要求形参的数据类型为指针类型
// 1.函数定义
void fn(int *pointer){} // 形参类型是数组
// 2.函数调用
int *p = &a;
fn(p); // 参数是指针变量(不是 *p / 指针)
回顾:指针——地址,指针变量——存放地址的变量
关于 *pointer:在定义指针变量时,使用 *pointer;在取值时,也是用 pointer。此二者中, 的作用不同,前者是作为指针变量的标记符,后者是作为取值操作符。


作业——从10个数中取出最大、最小值(指针实现)

/*
* 查找数组中的最大值、最小值
* 使用指针实现
*/
#include 

时间复杂度:O(n^2),空间复杂度:O(0)
5.5【本章重点】小结
1-1 形参:数组名,实参:数组名
// 1.函数定义--形参:数组名
void fn(int arr[], int n){}
// 2.函数调用
int a[10] = {1};
fn(a, 10); // fn(数组名)
1-2 形参:数组名,实参:指针变量
// 1.函数定义--形参:数组名
void fn(int arr[], int n){}
// 2.函数调用
int a[10] = {1}, *p = a;
fn(p, 10); // fn(指针变量)
2-1 形参:指针变量,实参:数组名
// 1.函数定义--形参:指针变量
void fn(int *pointer, int n){}
// 2.函数调用
int a[10] = {1};
fn(a, 10); // fn(数组名)
2-2 形参:指针变量,实参:指针变量
// 1.函数定义--形参:指针变量
void fn(int *pointer, int n){}
// 2.函数调用
int a[10] = {1}, *p = a;
fn(p, 10); // fn(指针变量)
5.6【本章重点】多维数组、指针
1、多维数组的地址
二维数组:一个数组里面包含一个数组(A含有B)
三维数组:一个数组里面包含一个数组,被包含的数组里面又包含一个数组(A含有B,B含有C)
对于二维数组,地址如下:
arr // 二维数组名,指向一维数组arr[0],即0行首地址
arr[m] <=> &arr[m][0],指向的是 m 行首地址
arr[m]+i <=> &arr[m][i] <=> *(a+m)+i,指向的是 m 行 i 列的地址
对于二维数组,数值如下:
arr[m][n] <=> *(arr[m]+n) // 对 arr[m]+n 的地址取值
多维数组地址展示



可以看出,第一行首地址和第二行首地址相差16字节(数组一行4个元素,一个元素4字节大小)
2、多维数组的指针
int (*p)[n]; // 定义二维数组
p是一个指针变量,它指向包含n个元素的一维数组,这里的 n 是长度
=> p 指向二维数组
p+i 指向一维数组
=> *(p+i)+j 指向二维数组 i 行 j 列的元素的地址
打印二维数组各个元素——指针实现

3、作业——待验证
根据输入行数、列数,打印出该行该列对应的元素数值。
数组实现:
#include 指针实现:明天实现代码
???
5.7【本章重点】字符串、指针
'\0'是ASCII码,对应的整型是0
用字符串数组存放一个字符串,并输出该字符串。
1、数组存取字符串——用数组名指向首地址,获取字符串
用字符串数组存放一个字符串
#include 疑问:定义数组的时候,是不是一定要指明长度?
执行过程图解

汇编执行比较:


2、指针存取字符串——用字符指针指向字符串
不定义字符数组,而是定义一个字符指针。使用字符指针指向字符串中的字符
指针方式存储字符串,实际上是两个步骤:
(1)存储字符串:存放在常量存储区,会分配一个内存单元
(2)将内存地址给指针变量
然后,就可以通过指针变量获取字符串数据了
这样一来,很明显,只能读不能写(因为常量存储区的不能修改)
#include 3、获取字符串中的某个字符——下标法、指针法
#include 4、字符数组名做参数
将字符串A赋值给字符串B,得到A、B相同的结果。
#include 5、字符指针变量做参数
将字符串A赋值给字符串B,得到A、B相同的结果。
#include 优化1
void copy(char *from, char *to){
while( (*to = *from) != '\0' ){ // 执行了两步:1.赋值;2.比较
from++;
to++;
}
}
优化2
void copy(char *from, char *to){
while( (*to++ = *from++) != '\0' ){ // 执行了三步:1.赋值;22.比较;3.递增
;
}
}
优先级说明:
*to++:先*to,再*(to+1)
优化3
void copy(char *from, char *to){
while( *to++ = *from++ ){
;
}
}
说明:'\0'是ASCII码,对应的整型是0
当 *from=='\0' 时,也就是 *to=0
那么while(*to)也就是while(0),此时,结束while循环
优化4
等价于优化3
void copy(char *from, char *to){
for( ; *to++ = *from++; ){
;
}
}
优化5
void copy(char *from, char *to){
while( *from != '\0' ){
*to++ = *from++;
}
*to = '\0';
}
优化6
等价于优化2
void copy(char from[], char to[]){
char *p1, *p2;
p1 = from; p2 = to;
while( (*p2++ = *p1++) != '\0' ){
;
}
}
6、a[ ]、*a 的区别
字符串存放在常量存储区
通过汇编执行过程,可以看出二者的区别:*a = "string..." 实际上是将字符串在常量存储区的存储单元地址赋值给指针变量a(赋值的是地址);后者不是赋值地址,而是真实的数据

7、五大内存分区
| 分区 | |
|---|---|
| 栈 | 临时空间。在编译器需要的时候分配。栈中的变量通常是局部变量、函数参数 |
| 堆 | new的时候分配的。一般一个new对应一个delete(程序员管,编译器不管)(程序员如果没有写delete,程序结束,系统会自动回收) |
| 自由存储区 | 和堆类似,通过free结束 |
| 全局存储区 / 静态存储区 | |
| 常量存储区 | 存储在常量区的数值,不允许修改 |
8、【重要】字符指针变量、字符数组的讨论
| 字符指针变量 | 存放的是字符串的首地址 | 只读,不能修改 | 赋值:char a[] = “I am a teacher.”; | 分配内存单元 (赋值之前不指向确定数据,即没有赋初值时指向是随意的)【注意输入语句】 | 指针变量的值是可以改变的 |
|---|---|---|---|---|---|
| 字符数组 | 存放的是数值 | 可读,可写 | 赋值:char *a= “I am a teacher.”; | 分配内存单元(是确定数据)【注意输入语句】 |
赋值方式不同:
1.字符指针变量赋值
char *a = "I am a teacher."; // 实际赋值的不是字符串,而是该字符串的第一个字符的地址(首地址)
等价于
char *a;
a = "I am a teacher.";
2.字符数组赋值
char a[] = "I am a teacher.";
不等价于
char a[20];
a = "I am a teacher.";
输入语句
1、字符数组
char str[20];
scanf("%s", str); // 数组名
2、字符指针变量
char *str;
scanf("%s", str); // 不能这样写——因为当指针变量str没有赋初值时,它的指向是随机的
改变指针变量的值
char *str = "Hello World!";
str += 6;
printf("%s", str); // 打印结果:World!——修改了首地址
(二)指向函数的指针
函数指针:函数的入口地址
函数指针变量最常用的是把指针作为参数传递到其他函数,即函数指针变量作参数——传递的是函数入口地址
1、补充知识——预编译
# 代表预编译,宏概念
/*
* 当 if 的参数是 0 时,不会执行if-endif内的代码——可以做注释,并且支持嵌套
* 当 if 的参数是 1 时,会执行if-endif内的代码
*/
#if(0)
/ * code */
#endif
#if(0)
/ * code */
#endif
2、正文
#include 3、函数指针做参数
函数指针做其他函数的参数,可以方便业务管理。
如下图代码中,通过媒介process()函数控制三个函数(max()、min()、add()),方便管理

4、返回指针值的函数
函数返回值可以是:void、整型、字符型、实型等,也可以是指针类型(即地址)
此类函数定义形式:类型名 *函数名(参数)
例题1——自己写
有若干个学生的成绩(每个学生4门课程),要求在用户输入学号之后,系统输出该学生的全部成绩。指针函数实现。
#include 例题2——自己写
针对上例,找出有不及格课程的学生学号。
5、指针函数、函数指针
| 指针函数 | 带指针的函数 |
|---|---|
| 函数指针 | 指向函数的指针变量 |
6、指针数组、指向指针的指针
| 指针数组 | 元素均为指针类型数据的数组 | 每一个元素都是一个指针变量 |
|---|---|---|
| 指向指针的指针 | **p(相当于*(*p),*p定义指针变量,**p定义指针变量的指针变量) |
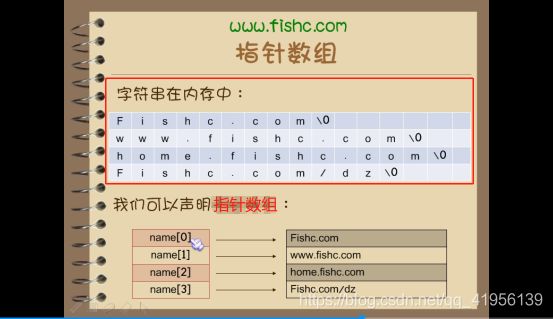
一维指针数组:类型名 数组名[数组2长度]; int *name[10];

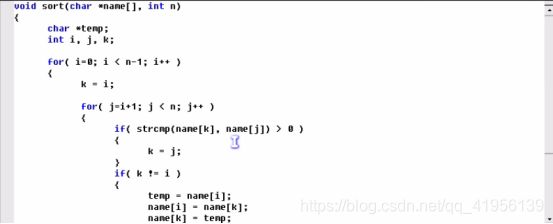
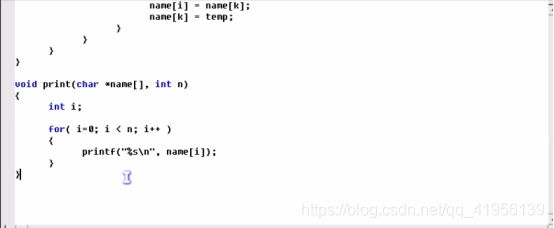
例题1——指针数组


例题2——指向指针的指针

从下面的汇编语句中,可以看出执行了4次偏移地址赋值:

(三)main() 函数的形参
main() 函数是由操作系统调用的,应用程序不会调用——main() 是应用程序的入口
指针数组做main()函数形参
main() 实际是有参数的:
void main(int argc, int *argv[])
int main(int argc, int *argv[])
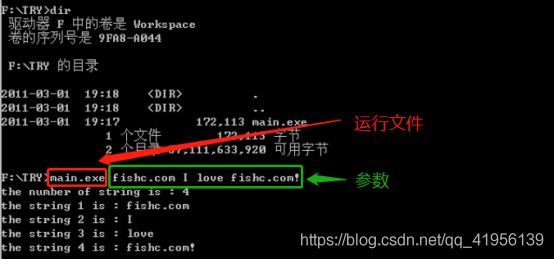
main() 函数传参测试
1、测试一
给main()传参数

运行结果:

2、测试二
修改后:

运行结果:直接运行

运行结果:cmd 窗口运行
(四)总结
int *p[n]; // p:指针数组——定义指针数组 p(每一个元素都是指针变量),数组长度为n
int (*p)[n]; // p:指针变量——指向 n 个元素的一维数组的指针变量
int fn(); // 函数声明
int *p(); // 函数声明——返回值类型为指针的函数,该指针指向的数据的数据类型为 int
int (*p)(); // 函数声明——函数指针做参数,p指向函数

(五)指针运算(总结)
1、运算小结
| 运算 | 形式 |
|---|---|
| 加、减 | p++、p–、p+i、p-i、p+=i、p-=i |
| 赋值 | (1)p=&a;(a是变量)(2)p=array;(数组首地址)(3)p=&array[i];(数组)(4)p=fn;(函数入口地址,fn为函数)(5)p1=p2;(p1、p2都是指针变量,将指针变量p2指向的地址赋值给p1) |
| 空值(不指向任何变量) | p=null(null,宏定义,0) |
| 两个指针变量相减 | p2-p1(若二者指向同一数组,p2>p1——后面的地址大于前面的地址,则二者之差=二者之间的元素个数) |
2、void指针、const指针
void:用于 函数返回值类型、函数参数类型,还可以用于指针类型。当参数类型为 void 时,可接收的参数类型任意
const:常量关键字,不能修改
| void *p | p 不指向一个确定的类型的数据 | 作用是:仅仅用来存放一个地址 | p 可以指向任意数据类型的数据(可以将任意类型的指针直接赋值给 void 指针) | 若要将 void 类型的指针赋值给其他类型的指针,需要进行强制类型转换 |
|---|
| const char *str | const 关键字修饰 *str | 指针变量 str 可以修改,str 指向的数据不能修改 |
|---|---|---|
| char * const str | const 关键字修饰 str | 指针变量 str 不能修改,str 指向的数据可以修改 |



(六)知识补充——memcpy
memcpy():copies characters between buffers.
void *memcpy(void *dest, const void *src, size_t count);
注意:第一个参数指向数据可读可写,第二个参数指向数据可读不可写
九、预处理命令
| # | 预处理命令 |
|---|---|
| #define | 宏定义命令(作用域是当前程序) |
| #undef | 设置结束宏命令作用域 |
9.1 无参宏
无参宏:宏名后不带参数
格式:
#define 标识符 字符串 // 不需要分号 ;
标识符:宏名
字符串:可以是常数、表达式、格式串、函数……
可用宏定义定义全局变量、定义数据类型
#define PI 3.141593 // 定义全局变量
#define INTEGER int // 定义数据类型
#define NAME char* // 定义宏名 NAME 为 char* 类型
typedef char* NAME2; // 有分号;定义 char* 类型的变量 NAME2
二者区别
NAME x, y; // 得到 x 为 *x(指针类型,4字节大小),y 为 y(char 类型,2字节大小)
NAMW2 x, y; // 两个都为指针类型
对输出格式进行宏定义,减少书写麻烦

9.2 有参宏
对带参数的宏,调用时,需要进行:(1)宏展开;(2)实参代形参
格式:
#define 宏名(参数) 字符串
标识符:宏名
字符串:可以是常数、表达式、格式串、函数……
注意:形参不分配内存单元,因此不要求定义数据类型;实参需要指定数据类型
#define M(y) y*y+3*y // 定义有参宏
k=M(5); // 调用宏——类似函数调用,不同之处在于,这里是直接的数值替换(不是值传递),5代替y
值替换、值传递 的区别
9.3 宏定义替换表达式
由于替换时需要处理优先级问题,加大复杂性,还容易遗漏处理,因此不推荐使用宏定义替换表达式
注意:替换规则——直接替换,没有优先级处理
// 1
#define M(y) y*y
k=M(a+1);
替换后,k = a+1*a+1
// 2
#define M(y) (y)*(y)
k=M(a+1);
替换后,k = (a+1)*(a+1)
以上两种结果是不同的
// 1
#define M(y) (y)*(y)
k = 100 / M(a+1);
替换后,k = 100 / (a+1) * (a+1)
// 2
#define M(y) ((y)*(y))
k = 100 / M(a+1);
替换后,k = 100 / ((a+1)*(a+1))
以上两种结果是不同的
9.4 宏
1、文件引用
| 文件包含方式 | 含义 |
|---|---|
| <> | 在文件目录中查找(头文件目录) |
| “” | 在源文件中查找(查不到再去头文件目录查找) |
2、条件编译
| 符号 | 意义 |
|---|---|
| #if(0) | 不执行 |
| #if(1) | 执行 |
| #endif | 结束 |
| #ifdef 标识符 | 如果“标识符”被宏定义了,且取值为真(非0、true),则执行#ifdef里面的代码部分 |
| #ifndef 标识符 | 如果“标识符”没有被宏定义,后者被定义了但取值为假,则执行#ifdef里面的代码部分——相当于:#if !define(标识符) |
| #else | |
| #endif |

小结——是否分配内存
1、变量定义
数组定义:分配内存
指针定义:分配内存
字符数组:分配内存
字符指针变量:分配内存
2、函数形参定义
普通变量:指明数据类型;分配内存,值传递
指针变量:指明数据类型;分配内存??不分配内存,值代替
3、形参定义
函数的形参:分配内存,值传递
宏的形参:不分配内存,值代替
十、结构体、共用体
| 结构体 | 将不同数据类型的数据组合在一起 | struct 结构体名{}; |
|---|---|---|
| 共用体 | 使几个不同的变量共占同一段内存 | union 共用体名{}; |
(一)结构体
10.1 结构体
结构体:将不同数据类型的数据组合在一起
相当于面向对象语言中的
对象
1、定义结构体类型变量
三种方法:
// 1.方法一:先声明结构体,再定义结构体变量
struct 结构名 {
类型 变量名;
};
struct 结构名 结构体变量名; // 定义结构体变量
// 2.方法二:同时声明结构体和定义结构体变量
struct 结构名 {
类型 变量名;
}结构体变量名;
// 3.方法三:省去结构体名
struct {
类型 变量名;
} 结构体变量名;
| 结构名 | 不分配内存单元 |
|---|---|
| 结构体变量(名) | 分配内存单元 |
例子:
// 1.方法一
struct student
{
int sno;
char name[4];
char sex;
int age;
float score;
char address[30];
};
struct student student1, student2; // 类似 char str1, str2;
// student1、student2 具有 struct student 类型
// 2.方法二
struct student
{
int sno;
char name[4];
char sex;
int age;
float score;
char address[30];
} student1, student2;
// 3.方法三
struct
{
int sno;
char name[4];
char sex;
int age;
float score;
char address[30];
} student1, student2;
2、结构嵌套
【图片】
struct date {
int year;
int month;
int day;
};
struct {
int sno;
char name[20];
char sex;
struct date birthday; // 结构体变量
float score;
}stu1,stu2;
3、结构体变量的引用
需要遵循以下规则:
- 获取结构体内的数据时,需要通过
.属性获取每一个成员的数据:结构体变量名.成员名,而不能直接通过结构体变量名来获取 - 给结构体中的成员赋值时,也是上面的方式
- 如果成员本身也是结构体变量,那么进行取值和赋值的时候,也需要继续获取它的成员
- 可以引用结构体变量成员的地址、结构体变量的地址
结构体成员的操作类似 Object 对象
4、结构体变量初始化
struct student{
char name[20];
char sex;
int age;
} stu1, stu2={"zhang", "femal", 20};
// stu2 初始化赋值 {"zhang", "femal", 20}
10.2 结构体数组
结构体数组:每一个数组元素都是一个结构体类型的。
1、定义结构体数组
和定义结构体变量一样,只需要指定变量为数组即可
struct person{
char name[20];
char phone[11];
} man[length];
例题:输入并输出三个学生的信息
#include 2、结构体数组初始化
struct person{
char name[20];
char phone[20];
} stu[3]={ {"one", "13000000000"}, {"teo", "13011111111"}, {"three", "13022222222"} };
或者
struct person{
char name[20];
char phone[20];
};
struct person stu[3]{ {"one", "13000000000"}, {"teo", "13011111111"}, {"three", "13022222222"} };
3、【实战】:投票系统程序实现
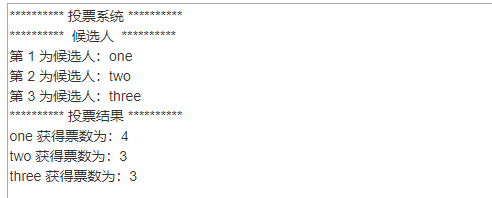
/*
* 投票程序
*/
#include 10.3 结构指针:指向结构体类型数据 的指针
指向结构体类型数据 的指针:该结构体变量所占据的内存段的起始地址。
定义形式:
struct 结构名 *结构指针变量名;
1、结构指针变量-赋值
把 结构体变量 的首地址赋值给指针变量
struct person{
char name[20];
} stu;
struct person *pstu;
pstu = &stu; // 把 结构体变量 的首地址赋值给指针变量
2、结构指针变量-访问成员
一般形式:pstr 为结构指针变量
// 1.方式一
(*pstr).成员名 // *:取值
// 2.方式二
pstr->成员名
10.3 函数参数
三种方法
| 实参 | 函数声明 | 函数定义 | 函数调用 | 实参 |
|---|---|---|---|---|
结构体变量 |
void fn(struct student) | void fn(struct student stu) | fn(stu) | 传值(整个结构体) |
结构体变量指针 |
void fn(struct student *) | void fn(struct student *p) | function(&stu) | 传址(结构体地址) |
| 结构体成员 |
1、【实战】:输出学生信息
题目:有一个结构体变量stu,内含学生学号、姓名、三门课程成绩。输出这些信息。
运行结果:

代码:
#include 10.4 动态存储分配
C语言不允许动态定义数组长度
| 形式 | 对 / 错 |
|---|---|
| int arrr[10]; | √ |
| char str[] = “string”; | √(编译器会自动计算长度,并填充到 [ ] 中) |
| int arr[n]; | ×(n:动态变量)(若n是宏定义,则是可以的) |
1、内存管理函数
| 函数 | 作用 | 返回值 | 使用场景 |
|---|---|---|---|
| malloc() | 分配内存空间 | 执行成功:返回值是一个指针,该指针指向分配域起始地址,指针类型为void;执行失败:返回值为空指针 null |
|
| calloc() | 分配内存空间 | 执行成功:返回值是一个指针,该指针指向分配域起始地址,指针类型为void;执行失败:返回值为空指针 null |
可以为一维数组开辟动态存储空间:元素个数为 n,每个元素长度为 size |
| free() | 释放内存空间 | 无返回值 |
函数原型:
void *malloc(unsigned int size); // size 是一个无符号数,是分配的连续空间的长度
void *calloc(unsigned n, unsigned size); // 分配 n 个长度为 size 的连续空间
void free(void *p); // 释放指针变量 p 指向的内存区
p 是最近一次调用 calloc 或者 malloc 函数的返回值
2、链表
- 创建
- 遍历
- 删除
猜测:
- 删除整个链表:直接将表头指针修改,就不能访问链表中其他结点,就相当于将链表消失了
- 删除某个元素:断开该元素前后指针连接,即可
【实战】-成绩管理系统
- 创建单链表
- 遍历单链表
- 插入单个结点
- 插入多个结点
- 删除结点
所有代码,待运行检验
疑问
// 空链表,直接插入
head = pointer; // ???是把pointer的值(这个值就是地址)给head
pointer->next = NULL; // 等价于 head->next = NULL; 吗???
作业:



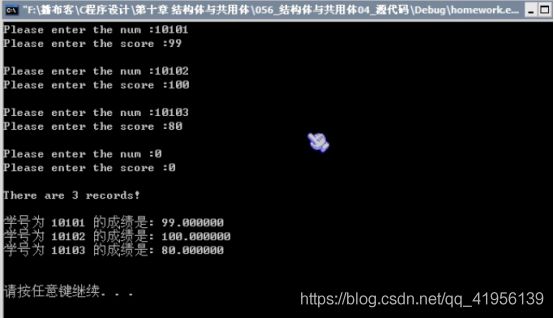
示例一:输入、输出学生信息
示例二:单链表中插入结点

(二)共用体
10.1 一般形式
union 共用体名{
成员列
} 共用体变量;
例子:
// 方式一
union data{
int i;
char ch;
float f;
} a,b,c;
// 方式二
union data{
int i;
char ch;
float f;
};
union data a,b,c;
10.2 共用体变量的引用
只有先定义了共用体变量,才能引用它。而且不能引用共用体变量,只能引用共用体变量中的成员。
10.3 共用体类型的特点
- 同一个内存段可以存放几种不同类型的成员
- 在每一瞬间,只能存放其中一种,而不是同时存放几种
=>在共用体变量中,起作用的成员是最后一个存放的成员 - 共用体变量的地址、以及它的各个成员的地址,都是同一个地址
=>因此,可以知道,共用体变量所占内存长度 = 占内存最大的成员的长度 - 不能对共用体变量名赋值,不能在定义共用体变量的时候对其初始化;也不能通过共用体变量名得到一个值
- 共用体变量不能做函数参数,也不能做函数返回值,但是可以使用指向共用体变量的指针
- 共用体类型可以出现在结构体类型的定义中
可以定义共用体数组
结构体也可以出现在共用体类型的定义中
数组也可以作为共用体的成员
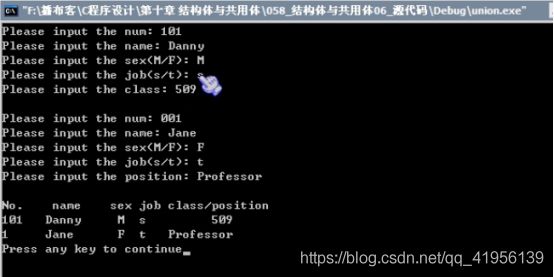
10.4 【实战】-教务管理系统
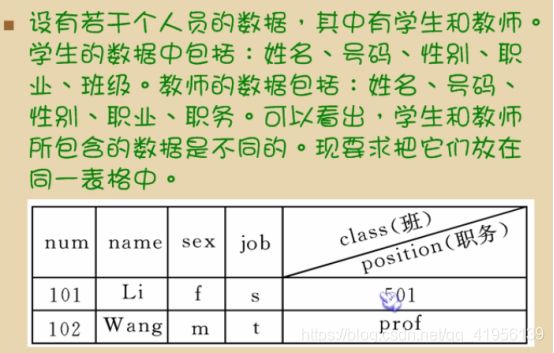
第一行数据是学生的数据,第二行数据是教师的数据

(三)枚举类型
当变量取值有限定的范围时,使用枚举类型更合适
- 应罗列出所有可用值,这些值叫“枚举元素”
- 枚举类型是一种基本数据类型,而不是构造类型(因为不可再分解)
- 在C语言中,枚举元素按照常量处理(枚举常量):不能赋值。但是在编译时,会给枚举元素按照顺序赋值 0,1,2,3,4,5……
- 枚举值 可以比较(因为默认每个枚举值默认都有一个值,就上面的)
- 一个整数不能直接赋值给一个枚举变量???(本来不就是不能赋值吗)
例子:枚举类型定义
// 变量a,b,c被说明为枚举类型
// 方式一
enum weekday{sun,mou,tue,wed,thu,fri,sat};
enum weekday a,b,c;
// 方式二
enum weekday {sun,mou,tue,wed,thu,fri,sat} a,b,c;
// 方式三
enum {sun,mou,tue,wed,thu,fri,sat} a,b,c;
枚举类型两个实例
实例1
#include 
实例2
#include 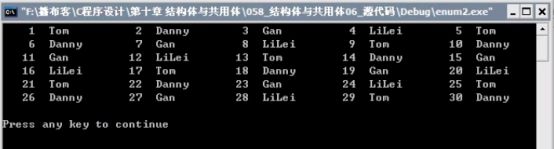
不会有 j>LiLei(因为枚举范围最大是LiLei(4)),所以month[]中存储的是枚举元素
(四)typedef
用typedef声明新的类型名,来代替已有的类型名
与#define宏定义不同
- typedef可以用来声明各种类型名,但是不能用来定义变量
- typedef声明类型时,只是声明了这个类型的一个别名,并不是创造新的类型
- 当不同源文件中都用到一个/些数据类型时,长用typedef声明这个/些数据类型,把它们单独放在一个文件中,然后在需要用的时候把这个文件通过#include命令包含进来
1、声明数据类型–就可以使用 数据类型 来定义变量了
typedef int INTEGER; // 声明INTEGER为整型,则使用INTEGER定义变量就相当于使用int
2、声明结构类型–就可以使用 结构 来定义结构体类型变量了
typedef struct{
int year;
int month;
int day;
}DATE; // 声明DATE为结构体类型
实例:
#include 3、声明数组类型–就可以使用 数组类型 来定义数组变量了
typedef int NUM[10]; // 声明NUM为整型数组类型
实例:
#include 4、声明字符指针类型–就可以使用 字符指针类型 来定义字符指针了
typedef char* STRING; // 声明STRING为字符指针类型
实例:
#include 5、声明指向函数的指针类型–
typedef int (*POINTER)(); // 声明返回值为int类型的函数指针类型
#include 函数指针赋值和调用方式:
p = func; // 赋值
// p = &func; // 也可以,两种都是赋地址
(p)(); // 调用
汇编执行过程:


fun、&fun:都是函数地址
arr、&arr:都是数组地址
函数名、数组名都是首地址,可以直接作取地址用
(五)结构体、共用体 区别
| 名称 | 作用 | 定义形式 | 引用 |
|---|---|---|---|
| 结构体 | 将不同数据类型的数据组合在一起 | struct 结构体名{}; | 可以引用结构体变量、结构体变量成员 |
| 共用体 | 使几个不同的变量共占同一段内存 | union 共用体名{}; | 只能引用共用体成员 |
| 名称 | 长度 | 定义形式 |
|---|---|---|
| 结构体变量 | 结构体变量所占内存长度 = 各个成员内存长度之和 | struct 结构体名{}; |
| 共用体变量 | 共用体变量所占内存长度 = 占内存最大的成员的长度 | union 共用体名{}; |
(六)宏定义、typedef 区别
1、相同之处
- #define可以定义全局变量,也可以声明数据类型
- typedef声明数据类型
二者在声明数据类型上,作用相同,过程本质不同:
typedef int COUNT; // 用COUNT代替int
#define COUNT int // 用COUNT代替int
但是在声明指针类型时,有区别:
#define NAME char* // 定义宏名 NAME 为 char* 类型
typedef char* NAME2; // 有分号;定义 char* 类型的数据类型 NAME2
二者区别
NAME x, y; // 就近原则:得到 x 为 *x(指针类型,4字节大小),y 为 y(char 类型,2字节大小)
NAMW2 x, y; // 一视同仁:两个都为指针类型
本质原因在于:#define是机械替换(本质上它只是一个替换的媒介,傻瓜替换),typedef是类型声明(本质上它就是这个类型了)
2、区别
| #define | 是在预编译的时候处理的 | 并且只是做机械的字符串替换 | 本质上它只是一个替换的媒介,傻瓜替换 |
|---|---|---|---|
| typedef | 是在预编译的时候处理的 | 但是并不是做机械的替换,而是采用像定义变量的方法那样,去声明一个类型 | 本质上它就是这个类型了,相当于是类型关键字 |
使用typedef,有利于程序的通用和移植