深度学习调参技巧及各种机器学习知识
深度学习调参经验
深度学习调参经验汇总
关于深度学习优化器 optimizer 的选择,你需要了解这些(详细介绍了几大优化器算法及其特点)
见之底部:面向小数据集构建图像分类模型 - Keras中文文档
通过下面的方法你可以达到95%以上的正确率:
-
更加强烈的数据提升
-
更加强烈的dropout
-
使用L1和L2正则项(也称为权重衰减)
-
fine-tune更多的卷积块(配合更大的正则)
正则化详解(使用吴恩达的课件)
常见范数(向量范数、矩阵范数、L1范数、L2范数)及其在机器学习算法的应用
深度学习手册——深度神经网络的超参数调试、正则化及优化方法(长文多图,非常全面)
一个很牛逼的loss函数
科学空间的介绍
知乎对此类方法的介绍
其中pi是预测的分布,而qi是真实的分布,比如输出为[z1,z2,z3],目标为[1,0,0],那么
只要z1已经是[z1,z2,z3]的最大值,那么我们总可以“变本加厉”——通过增大训练参数,使得z1,z2,z3增加足够大的比例(等价地,即增大向量[z1,z2,z3]的模长,就是随意地增大网络的权重使z1增大),从而![]() 足够接近1(等价地,loss足够接近0)。这就是通常softmax过于自信的来源:只要盲目增大模长,就可以降低loss,训练器肯定是很乐意了,这代价太低了。为什么代价低,因为它搜索空间变小了,
足够接近1(等价地,loss足够接近0)。这就是通常softmax过于自信的来源:只要盲目增大模长,就可以降低loss,训练器肯定是很乐意了,这代价太低了。为什么代价低,因为它搜索空间变小了,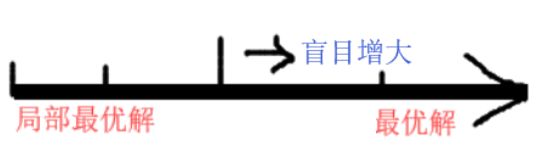 一味地拟合最优解导致过拟合,凡事留有余地。
一味地拟合最优解导致过拟合,凡事留有余地。
为了使得分类不至于太自信,一个方案就是不要单纯地去拟合one hot分布,分一点力气去拟合一下均匀分布,即改为新loss:
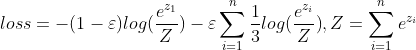
这样,盲目地增大比例使得![]() 接近于1,就不再是最优解了,从而可以缓解softmax过于自信的情况,不少情况下,这种策略还可以增加测试准确率(防止过拟合)。
接近于1,就不再是最优解了,从而可以缓解softmax过于自信的情况,不少情况下,这种策略还可以增加测试准确率(防止过拟合)。
上面那个loss左边和原来的一样占比0.9,右边乘以1/3后,占比0.03,说明盲目增大向量[z1,z2,z3]的模长总是差0.07达到最优解。
基础知识
从M-P神经元模型到感知机
常用激活函数的比较
机器学习
线性回归
概率论
极大似然估计详解,写的太好了!还有贝叶斯公式。
精确率、召回率、F1 值、ROC、AUC 各自的优缺点是什么?
来源
图示与下面的解释清晰讲解了precision与recall的区别
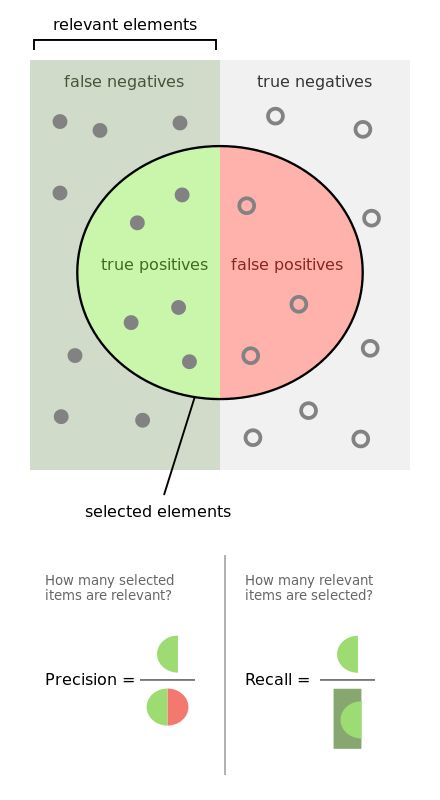
- recall是相对真实的答案而言: true positive / golden set 。假设测试集里面有100个正例,你的模型能预测覆盖到多少,如果你的模型预测到了40个正例,那你的recall就是40%。
- precision是相对你自己的模型预测而言:true positive /retrieved set。假设你的模型一共预测了100个正例,而其中80个是对的正例,那么你的precision就是80%。我们可以把precision也理解为,当你的模型作出一个新的预测时,它的confidence score 是多少,或者它做的这个预测是对的的可能性是多少。
- 一般来说呢,鱼与熊掌不可兼得。如果你的模型很贪婪,想要覆盖更多的sample,那么它就更有可能犯错。在这种情况下,你会有很高的recall,但是较低的precision。如果你的模型很保守,只对它很sure的sample作出预测,那么你的precision会很高,但是recall会相对低。
什么是accuracy

计算多分类的precision
把每个类别单独视为”正“,所有其它类型视为”负“

(内含源码)多分类问题评估的精确率、召回率,f1度量即precision,recall,f1-measure的python代码实现
图像分类Top-1和Top-5的含义
Your classifier gives you a probability for each class. Lets say we had only "cat", "dog", "house", "mouse" as classes (in this order). Then the classifier gives somehting like
0.1; 0.2; 0.0; 0.7
as a result. The Top-1 class is "mouse". The top-2 classes are {mouse, dog}. If the correct class was "dog", it would be counted as "correct" for the Top-2 accuracy, but as wrong for the Top-1 accuracy.
Hence, in a classification problem with $k$ possible classes, every classifier has 100% top-$k$ accuracy. The "normal" accuracy is top-1.
one-hot
数据:{汽车,手机,电脑,汽车,电话}
出现的词有 {汽车,手机,电脑,电话}
{汽车,汽车}的one-hot编码为[1, 0, 0, 0]
{手机,电脑}的one-hot编码为[0, 1, 1, 0]
无偏方差为什么除以n-1
向量内积(点乘)和外积(叉乘)概念及几何意义
怎样理解最小二乘法等价于欧式距离之和最小?
欧式距离是点到点之间的距离,最小二乘法让所有点到直线之间的距离最短的算法。
最小二乘法的本质是什么?
如何通俗地理解“最大似然估计法”?
tensorflow中的tensorboard可视化中的准确率损失率曲线,为什么有类似毛刺一样?
很好理解,不是框架的问题,你用caffe或者别的框架训练分类或者检测模型都会遇到loss起伏,本身样本差异大,当前迭代次数的模型可能对接下来的样本无法区分。只要曲线整体是下降的就正常
贝叶斯深度学习简明解释
知乎用户zKk5cV2019-11-05
的确,增加随机性可能缓解对抗样本问题,而且人脑的确不是确定性的,神经元激发同样有随机分布特征。这个东西似乎是有点 Gaussian belief propagation类的方法的意思,也有点 ensemble 的意思。3
Yan回复知乎用户2019-11-22
觉得这个区别有些trivial. 有些时候很难定义到底是几个网络。multistage网络里面每一个stage,或者几种不同的网络插到一起end2end... 说不清楚是几个网络。对于题主讨论的这个网络模型,可以做一个baseline:同样的架构,不同的初始化,同样的方法训练,最后用essemble合起来。我觉得这个贝叶斯模型未必就能跑过这个baseline。2
OpenAI 研究员Carles Gelada认为深度学习里加贝叶斯无用

他指出,或许贝叶斯神经网络并没有多大用处。大致观点为:1)只有当具有合理的参数先验时,我们才会去使用贝叶斯规则,但没有人知道先验对神经网络权重的编码会是什么,那么为什么我们还要使用这种先验呢?2)许多正则化都可以用贝叶斯解释,但事实上每个人都能够对正则化给出一个解释。那么我们用贝叶斯理论来解释正则化,有什么意义呢?3)或许有人会说BNNs可以让我们直接用经验来找到正则化。但谁来保证BNNs找到的这种正则化空间就是最优的呢?4)BNNs可以用在贝叶斯元学习框架当中。但没有理由相信这种应用会比其他元学习框架更好。针对Carles提出的这些反对意见,在Twitter上迅速吸引了大批的研究人员加入讨论。多数引经据典,从历史发展、当前研究、实践经验等各种角度进行辩论,或赞同,或反对,不一而足。
深度贝叶斯化
贝叶斯深度学习就是把传统的(线性)模型换成深度网络。与其讨论它和传统神经网络,不如简化为讨论把线性回归的3种用法的区别:
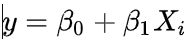 (DL调包侠: 这也太简单了吧,看我Deep Learning)
(DL调包侠: 这也太简单了吧,看我Deep Learning)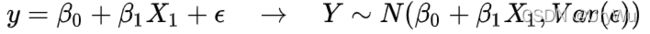 (DL调包侠:???)
(DL调包侠:???) (DL调包侠:????????)
(DL调包侠:????????)
发布于 2020-06-22 09:39