【学习笔记-吴恩达】目标检测(Object Detection)
文章目录
- 一、基本概念
-
- 1.1 Classification with localization
- 二、Landmark Detection
- 三、Object Detection
-
- 3.1 Sliding windows detection
- 3.2 YOLO
-
- 3.2.1 Non-max suppression
- 3.2.2 Anchor box
- 四、 Evaluation
-
- 4.1 IoU(Intersection over union)(交并比)
一、基本概念
Classification with localization:在图像识别的基础上,要把图像给“框”出来。

landmark detection:在一张图片中找到一些你想要的点的坐标。例如,你想要人脸的64个特征点的坐标。

目标检测(Object Detection):给一个图片,找出这个图片中有哪些物体,把物体框起来,并标上类别。

1.1 Classification with localization
思路:如果假设一个图片里只有一个物体,那就可以在原来图像分类的CNN的基础上,让 y y y 多五个值:是否检测到物体;物体的左上角的坐标、物体的长宽。
例如,假设Label有四种,那么若检测出了物体, y ^ \hat{y} y^ 的值就可以是:
y ^ = [ p c b x b y b h b w c 0 c 1 c 2 c 3 ] = [ 1 0.1 0.2 0.3 0.4 0 0 1 0 ] 含 义 为 → [ 检 测 到 了 物 体 该 物 体 左 上 角 的 坐 标 为 ( 0.1 , 0.2 ) 该 物 体 长 为 0.3 宽 为 0.4 该 物 体 的 类 别 是 第 三 种 ] \hat{y} = \begin{bmatrix} p_c \\ b_x\\ b_y\\ b_h\\ b_w\\ c_0 \\ c_1 \\ c_2 \\ c_3 \\ \end{bmatrix} = \begin{bmatrix} 1 \\ 0.1 \\ 0.2 \\ 0.3 \\ 0.4 \\ 0 \\ 0 \\ 1 \\ 0 \\ \end{bmatrix} \underrightarrow{含义为} \begin{bmatrix} 检测到了物体 \\ 该物体左上角的坐标为(0.1, 0.2) \\ \\ 该物体长为0.3 \\ 宽为0.4 \\ \\ \\ 该物体的类别是第三种 \\ \\ \end{bmatrix} y^=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡pcbxbybhbwc0c1c2c3⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡10.10.20.30.40010⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤含义为⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡检测到了物体该物体左上角的坐标为(0.1,0.2)该物体长为0.3宽为0.4该物体的类别是第三种⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
若没检测出物体,则 y ^ \hat{y} y^ 可能是:
y ^ = [ p c b x b y b h b w c 0 c 1 c 2 c 3 ] = [ 0 0.3 0.2 0.5 0.7 0 1 0 0 ] 含 义 为 → [ 未 检 测 到 物 体 剩 下 的 想 输 出 什 么 都 无 所 谓 , 不 管 ] \hat{y} = \begin{bmatrix} p_c \\ b_x\\ b_y\\ b_h\\ b_w\\ c_0 \\ c_1 \\ c_2 \\ c_3 \\ \end{bmatrix} =\begin{bmatrix} 0 \\ 0.3\\ 0.2 \\ 0.5 \\ 0.7 \\ 0 \\ 1 \\ 0 \\ 0 \\ \end{bmatrix} \underrightarrow{含义为} \begin{bmatrix} 未检测到物体 \\ 剩下的想输出什么 \\ 都无所谓,不管 \\ \\ \\ \\ \\ \\ \\ \end{bmatrix} y^=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡pcbxbybhbwc0c1c2c3⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡00.30.20.50.70100⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤含义为⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡未检测到物体剩下的想输出什么都无所谓,不管⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
对于损失函数,若 y = 1 y = 1 y=1 (即样本中存在物体),则应该考虑 y ^ \hat{y} y^ 的所有字段,若 y = 0 y=0 y=0,则只需要考虑第一个即可。
二、Landmark Detection
思路:让CNN的 y y y 输出的是点的坐标。
例如,你想要找的是人脸的64个特征点的坐标,那你就可以让 y y y 输出128个值,分别代表这64个坐标点。
其他应用:利用可以做人体肢体检测

三、Object Detection
3.1 Sliding windows detection
实现目标检测的一个基本的思路:使用滑动窗口。

和卷积过程类似,让一个矩阵不断的向后向下移动,每次检测一个区域内的图片有没有物体,如果有,就可以用Classification with localization的方法标注出来。相当于每次检测都是通过一个CNN网络。
缺点:① 计算成本大 ② 窗口大小不好选择 ③ 目标物体可能正好夹在所有的窗口之间,即所有的窗口都不能很好的包裹住目标物体
计算慢的问题解决思路:先决定要将整个图片分成几个窗口,然后把整个图片输入CNN,对应的输出 y y y 包含每个窗口的分类情况。(但这个方法仍不能解决②③问题)例如:
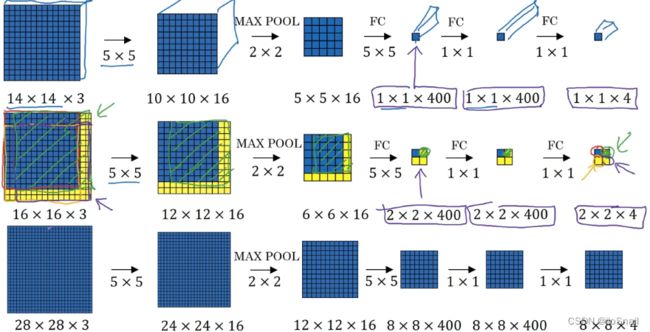
图一中,只有一个窗口(即整张图片),最后输出 y y y 的维度为 1x1x4,即 1个窗口,4表示有四种类型(用的one-hot编码)
图二中,将16x16的图片分成四个窗口,CNN的输出 y y y 的维度为 2x2x4,表示这4个窗口各自的类型
图三中,将28x28的图片分成64(8x8)个窗口,CNN的输出 y y y 的维度为 8x8x4,即这64个窗口各自的类别
3.2 YOLO
YOLO(You only look once)是一种目标检测算法,思路为:将图片分成 n × n n \times n n×n 窗口,然后将整张图片送给CNN,然后输出 y y y 的维度为 n × n × ( 5 + k ) n \times n \times(5+k) n×n×(5+k) ,其中 k k k 为类别数,而 5 分别是:该窗口是否包含物体,物体的中心点坐标和物体的长宽。 即 输出的含义为 n × n n\times n n×n 个窗口中每个窗口的物体情况。
例如:
这是一个100x100的图片,将其分成 3x3 个窗口,其中第4个和第6个包含汽车(当物体横跨多个窗口时,以物体中心点为准),对于每个窗口有8个数值,即 [ p c , b x , b y , b h , b w , c 1 , c 2 , c 3 ] [p_c,b_x,b_y,b_h,b_w,c_1,c_2,c_3] [pc,bx,by,bh,bw,c1,c2,c3]:
- 第1个参数 p c p_c pc 表示该窗口是否有物体(1代表有,0代表没有)。当然,实际的输出是一个0到1之间的数,即有多少可能性该窗口有物体。所以这里涉及一个超参,即当该值小于多少时,就认为这个窗口没有发现物体。
- 第2,3个参数 b x , b y b_x, b_y bx,by 表示该窗口中物体的中心点坐标。窗口的坐上角坐标为(0,0),右下角为(1,1)。若该窗口不包含物体,那么这俩输出啥都无所谓。
- 第3,4个参数 b h , b w b_h,b_w bh,bw 表示物体的高和宽。由于物体可能横跨多个窗口,所以该值可能会大于1。(由于是整张图片送给CNN,并不是一个窗口一个窗口送,所以是可以检测出来的)
- 最后三个是图片的类别
如果你担心一个窗口里可能包含多个物体时,你可将窗口调小(也就是窗口数量调多)
3.2.1 Non-max suppression
当你的窗口比较小时,有可能临近的好几个窗口都表示自己发现了物体(即几个临近的窗口都认为物体中心点在我这个窗口内),就会出现下图的场景:

图上面的数字是 p c p_c pc,含义为:该窗口有多大可能性它是对的。
面对这种情况,选择 p c p_c pc 最大的即可(当然, p c p_c pc 一定要大于你设置的阈值,例如,小于0.5的一律否决)。
3.2.2 Anchor box
虽然你的窗口已经足够小了,但是依然可能会出现两个物体的中心出现在同一个窗口内,重叠在一起的物体称为overlapping objects。

对于这种场景,可以使用Anchor box,让模型可以做到在一个窗口内识别多个对象。
思路为:之前 y y y 只能包含一个物体,现在让 y y y 可以多包含几个物体。例如,之前是
y = [ p c , b x , b y , b h , b w , c 1 , c 2 , c 3 ] T y = [p_c,b_x,b_y,b_h,b_w,c_1,c_2,c_3]^T y=[pc,bx,by,bh,bw,c1,c2,c3]T
现在 y y y 为
y n e w = [ y , y , ⋯ ] T = [ p c , b x , b y , b h , b w , c 1 , c 2 , c 3 , p c , b x , b y , b h , b w , c 1 , c 2 , c 3 , ⋯ ] T y_{new} = [y, y, \cdots]^T = [p_c,b_x,b_y,b_h,b_w,c_1,c_2,c_3, ~~~p_c,b_x,b_y,b_h,b_w,c_1,c_2,c_3, ~~~~\cdots]^T ynew=[y,y,⋯]T=[pc,bx,by,bh,bw,c1,c2,c3, pc,bx,by,bh,bw,c1,c2,c3, ⋯]T
其中,每一个 [ p c , b x , b y , b h , b w , c 1 , c 2 , c 3 ] T [p_c,b_x,b_y,b_h,b_w,c_1,c_2,c_3]^T [pc,bx,by,bh,bw,c1,c2,c3]T 称为一个 Anchor box。 注意两点:① anchor box的数量小于等于类别数量;② 某个类别的物体在anchor box的位置最好固定,例如汽车类别都放在第二个anchor box上,别搞的有些汽车在第一anchor box,有些汽车在第二个。
举例,例如这张图片:
对于第8个窗口的标签 y y y 如下:
y = [ 1 , b x , b y , b h , b w , 1 , 0 , 0 , 1 , b x , b y , b h , b w , 0 , 1 , 0 ] T y = [1,b_x,b_y,b_h,b_w,1,0,0, ~~~ 1,b_x,b_y,b_h,b_w,0,1,0]^T y=[1,bx,by,bh,bw,1,0,0, 1,bx,by,bh,bw,0,1,0]T
如果某个窗口只有汽车,没有行人,那么 y y y 如下:
y = [ 0 , ? , ? , ? , ? , ? , ? , ? , 1 , b x , b y , b h , b w , 0 , 1 , 0 ] T y = [0,?,?,?,?,?,?,?, ~~~ 1,b_x,b_y,b_h,b_w,0,1,0]^T y=[0,?,?,?,?,?,?,?, 1,bx,by,bh,bw,0,1,0]T
四、 Evaluation
评价你的目标检测算法好不好
4.1 IoU(Intersection over union)(交并比)
IoU算法思路:让你的框和实际的框求交集,交集的面积占这两个框的总面积越大,则说明表现越好。
例如:
在该图中,紫色的框是你预测的,将其区域记为 A A A ,红色的框是实际区域,将其记为 B B B。它们两个的交集则为 A ∩ B A \cap B A∩B,并集记为 A ∪ B A \cup B A∪B 那么,IoU就为:
IoU = ∣ A ∩ B ∣ ∣ A ∪ B ∣ \text{IoU} = \frac{|A \cap B|}{|A \cup B|} IoU=∣A∪B∣∣A∩B∣
显然, IoU ∈ [ 0 , 1 ] \text{IoU}\in[0,1] IoU∈[0,1],IoU越大,表示模型表现越好,反之亦然。