机器学习一 集成学习
一、何为机器学习?
机器学习最近那么火,博主自学习以来,也看过不少有关机器学习的资料,首先对于机器学习的定义就又五花八门,什么让机器像人一样去学习,说的总感觉有些浮夸而不现实,把机器学习搞的也太神秘了,有幸看了吴恩达的课程,最喜欢课程里吴恩达引用的卡内基梅隆大学,Tom Michael Mitchell 1997年对机器学习下的定义:
A computer program is said to learn from experience E with respect to some task T and some performance measure P,if its performance on T,as measured by P,improves with experience E.
简单来讲就是:
对于某给定的任务T,在合理的性能度量方案P的前提下,某计算程序可以自主学习任务T的经验E;随着提供合适,优质,大量的经验E,该程序对于任务T的性能逐步提高。
我觉得这个思想也一直贯穿着机器学习的方方面面。
这里最重要的机器学习的对象:
任务Task,T, 一个或者多个
经验Experience,E
性能Performance,P
即:随着任务的不断执行,经验的积累会带来计算性能的提升。
二、Python概述
这里简单介绍下python语言,相信研究机器学习的人里,用python的人还是比较多的。
python数据分析大家族
1)numpy数据结构基础
开源的数值计算扩展:用来存储和处理大型矩阵,定义了数据分析的数据结构基础
2)scipy强大的科学计算方法(矩阵分析,信号分析,数据分析)
3)matplotlib丰富的可视化套件(又称:MLlib)(用来做各种图表)
用来绘图的,相当于一个绘图库。
4)pandas:基础的数据分析套件(一些比较基础的数据分析)
5)scikit-learn:强大的数据分析建模库(支持人工神经网络)
6)keras:人工神经网络(可以实现深度神经网络)
三、分类和决策树
我们讲机器学习的典型任务包括:回归,分类,聚类,降维度等,分类当中最常用的莫过于二分类啦,我们这里主要介绍二分类的一些应用。那么到底什么是分类呢?机器学习算法中用什么来做分类呢?
先了解一些基本概念:
1、分类是从特定的数据中挖掘模式做出判断,以Gmail垃圾邮件分类器为例。我们一开始使用Gmail接收邮件时,可能什么都不过滤,我们人工对于每一封邮件都点选“垃圾”或“不是垃圾”,过一段时间,Gmail就体现出一定的智能,能自动过滤掉一些垃圾邮件。这就是最简单的一个二分类模型。“垃圾”和“不是垃圾”就是标签,当我们经过一段时间的手动标记后,Gmail就有了这些带标签的数据,就可以根据这些数据构建一个模型,用来判断后来收到的邮箱是否是垃圾邮件,这里就用到了强监督学习。
2、决策树它着眼于从一组无次序、无规则的实例中推理出以决策树表示的分类规则。构造决策树的目的是找出属性和类别间的关系,用它来预测将来未知类别的记录的类别。它采用自顶向下的递归方式,在决策树的内部节点进行属性的比较,并根据不同属性值判断从该节点向下的分支,在决策树的叶节点得到结论。
举个栗子(网上找的比较好的例子,仅供大家学习交流):
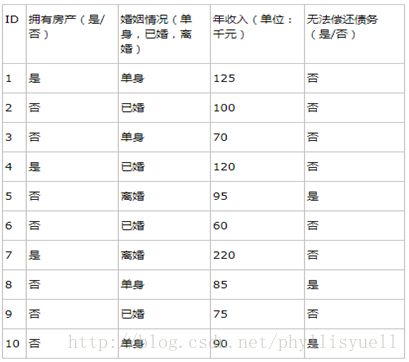
上表根据历史数据,记录已有的用户是否可以偿还债务,以及相关的信息。通过该数据,构建的决策树如下:
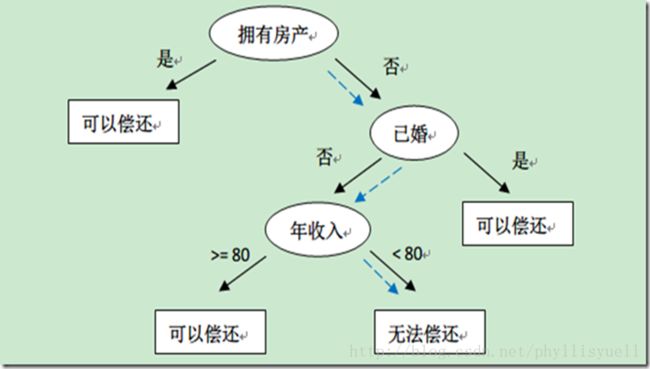
我们可以看出决策树的预测作用——比如新来一个用户:无房产,单身,年收入55K,那么根据上面的决策树,可以预测他无法偿还债务(蓝色虚线路径)。从上面的决策树,还可以知道是否拥有房产可以很大的决定用户是否可以偿还债务,对借贷业务具有指导意义。
3、决策树的结构与构造
一般的,一棵决策树包含一个根节点、若干个内部节点和若干个叶子节点;叶子节点对应于决策结果,其他每个节点则对应于一个属性测试;每个节点包含的样本集合根据属性测试的结果被划分到子节点中;根节点包含样本全集。从根节点到每个叶子节点的路径对应了一个判定测试序列。决策树的学习目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树,其基本流程遵循简单且直观的“分而治之”(divide-and-conquer)策略,如图4.2所示。

4、决策树的分类
根据最优划分的选择决策树可分为三类:
花萼长度、花萼宽度、花瓣长度、花瓣宽度
种类:山鸢尾,杂色鸢尾,维吉尼亚尾
很明显这属于一个分类问题,用python实现如下:
import numpy as np
import pandas as pd
def lrisTrain():
#预处理-引入鸢尾数据:
from sklearn.datasets import load_iris
iris = load_iris()
from sklearn.cross_validation import train_test_split
# 把数据分为测试数据和验证数据
train_data,test_data,train_target,test_target=train_test_split(iris.data,iris.target,test_size=0.2,random_state=1)
#Model(建模)-引入决策树
from sklearn import tree
#建立一个分类器-这里是分类器
clf = tree.DecisionTreeClassifier(criterion="entropy")
#训练集进行训练
clf.fit(train_data,train_target)
#进行预测
y_pred = clf.predict(test_data)
#Verify(验证)
#引入模块
from sklearn import metrics
#法一:通过准确率进行验证
print(metrics.accuracy_score(y_true =test_target,y_pred=y_pred))
#法二:通过混淆矩阵验证(横轴:实际值,纵轴:预测值)(理想情况下是个对角阵)
#print(metrics.confusion_matrix(y_true=test_target,y_pred=y_pred))
#法三:决策树可以直接输出到文件到data目录下
# with open("./data/tree.dot","w") as fw:
# tree.export_graphviz(clf,out_file=fw)
lrisTrain()四、集成学习
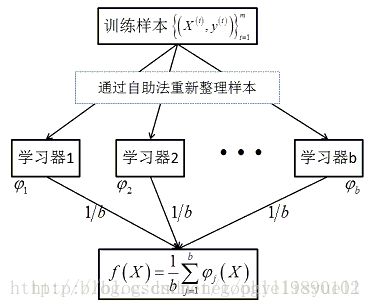
1、定义:集成学习是机器学习中一个非常重要且热门的分支,通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统(multi-classifiersystem)、基于委员会的学习(committee-basedlearning)等。是由多个弱分类器构成的一个强分类器,其哲学思想是“三个臭皮匠顶个诸葛亮”。集成学习示意图如下:
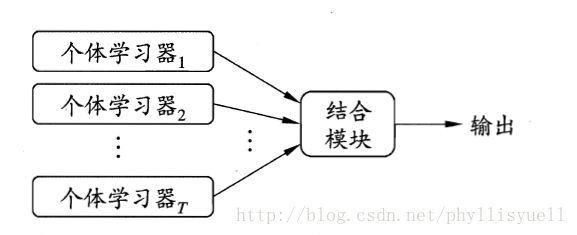
2、集成学习的结构和思想
上图中显示出集成学习的一般结构:先产生一组“个体学习器”,再用某种策略将他们结合起来,个体学习器通常由一个现有的学习算法从训练数据产生,例如决策树算法、神经网络算法等。
集成学习的思想:通过将多个学习器进行结合,常可获得比单一学习器更为显著优越的泛化性能。另一方面,各个体学习器间具有一定差异性(如不同的算法,或相同算法不同参数配置),这会导致生成的分类决策边界不同,也就是说它们在决策时会犯不同的错误。将它们结合后能得到更合理的边界,减少整体错误,实现更好的分类效果。
五、传统集成学习的算法
1、Boosting:先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续训练中受到更多关注(设置权重),然后基于调整后的样本分布来训练下一个基学习器;如此反复进行,直到基学习器数目达到事先指定的值T,最终将这T个基学习器进行加权结合。additive training(加型训练)
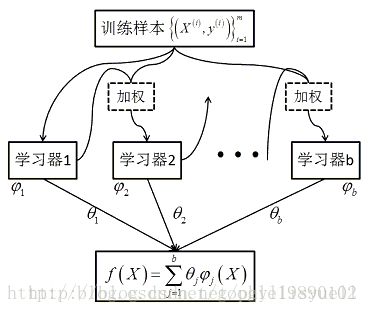
2、Bagging:有放回的进行m次随机抽取,一共记性T次,最终采样出T个含m个训练样本的采样集,然后基于每个采样训练出一个基学习器,再将这些学习器进行结合。
3、随机森林算法是Bagging的一个扩展变体,RF在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性的选择,具体来说,传统决策树在选择划分属性时是在当前节点的属性集合中选择一个最优属性;而在RF中,对基决策树的每个节点,先从该节点的属性集合中随机选择一个包含k个属性的子集,然后从这个子集中选择一个最优属性进行划分。
引入随机属性的选择,是为了增加学习器的“多样性”,从而提升算法的泛化能力。
4、GBDT(GradientBoost Decision Tree)算法(梯度提升决策树):Boosting,迭代,即通过迭代多棵树来共同决策。我们先用一个初始值来学习一棵决策树,叶子处可以得到预测的值,以及预测之后的残差,然后后面的决策树就要基于前面决策树的残差来学习,直到预测值和真实值的残差为零。最后对于测试样本的预测值,就是前面许多棵决策树预测值的累加。additivetraining(加型训练)
GBDT中的树是回归树(不是分类树),GBDT用来做回归预测,调整后也可以用于分类。
GBDT的基本思想是“积跬步以至千里”!也就是说我每次都只学习一点,然后一步步的接近最终要预测的值。
GBDT模型在1999年由JeromeFriedman提出的,是决策树与Boosting方法相结合的应用。GBDT每颗决策树训练的是前面决策树分类结果中的残差。具体体现算法思想如下:
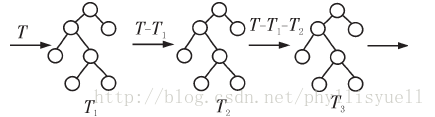
从上图可以看出GBDT的训练过程是线性的,是无法并行训练决策树的。第一棵决策树T1,训练的结果与真实值T的残差是第二棵树T2训练优化的目标,而模型最终的结果是将每一棵决策树的结果进行加和得到的。一个很好的参考。
训练一个提升树模型来预测年龄:
训练集是4个人,A,B,C,D年龄分别是14,16,24,26。样本中有购物金额、上网时长、经常到百度知道提问等特征。提升树的过程如下:
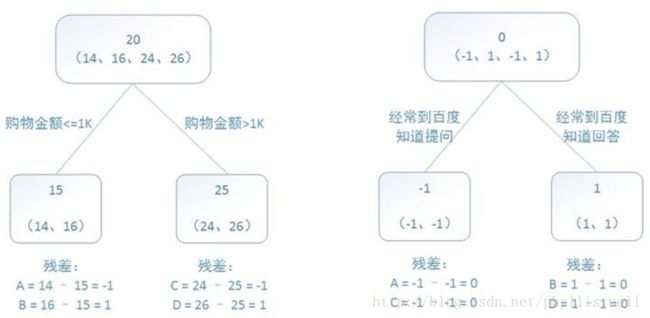
我们可以看出:预测值等于所有树值得累加,如A的预测值= 树1左节点值 15+ 树2左节点-1= 14。
5、Xgboost:在GBDT的基础上对boosting算法进行的改进,内部决策树使用的是回归树。xgboost是大规模并行boostedtree的工具,它是目前最快最好的开源boostedtree工具包,比常见的工具包快10倍以上。xgboost最大的特点在于,它能够自动利用CPU的多线程进行并行,同时在算法上加以改进提高了精度。additivetraining(加型训练)。
六、集成学习的发展历史
1、1988年,Kearns和Valiant在PAC(Probably Approximately Correct)学习模型中,提出了强/弱学习算法的概念。对于一个二元概念(binaryconcept),如果存在一个多项式复杂性的学习算法可以辨别这组概念,并且辨别的错误率比较高,那么这组概念就是强可学习的,如果错误率只是比随机猜测略好(只略大于50%),那么这组概念是弱可学习的。
2、1990年,Schapire证明了多个弱学习机可以通过某种方式被提升(boosting)为一个强学习机,由此奠定了集成学习的理论基础。这个构造性的方法其实就是Boosting算法的雏形。迄今为止,Boosting是集成学习中研究得最深入的一个算法族,而且其影响己经扩展到了计算机视觉等许多其他研究领域。
3、1996年,Breiman提出了与Boosting算法的思想类似的Bagging(Bootstrap Aggregating)算法,该算法也是集成学习领域中目前研究得很多的一个算法族。
4、从20世纪90年代中期开始,机器学习界认识到,构建一个好的集成学习系统并非是轻而易举的。因此,很多学者开始致力于探索集成学习的算法设计和理论研究。
5、1995年,AT&Tbell实验室的香港女学者HoTin Kam最早提出了RF,那个时候还不叫RandomForests, 而叫RDF(RandomDecision Forest),她主要是采用RandomSubspace的思想使用DT(DecisionTree)来构建Forest。
6、2001年,统计学家Breiman已开始在机器学习界站稳脚跟。他在RDF基础上又引入了Bagging技术,并提出了沿用至今的RandomForests。
七、集成学习的应用
集成学习是一种新的机器学习范式,由于它显著提高了一个学习系统的泛化能力,从20世纪90年代开始,对集成学习理论和算法研究就成了机器学习领域中的热点问题之一。目前,集成学习已经被成功的应用于解决语音识别,指纹识别,基因数据分析,遥感数据分析,图像处理,文本分类,蛋白质结构分类,网络入侵检测,疾病诊断等许多实际问题。