基于 Java 机器学习自学笔记 (第59天:数值型数据的Naive Bayes算法)
注意:本篇为50天后的Java自学笔记扩充,内容不再是基础数据结构内容而是机器学习中的各种经典算法。这部分博客更侧重与笔记以方便自己的理解,自我知识的输出明显减少,若有错误欢迎指正!
目录
一、基础的概率论回顾
二、数值型Naive Bayes算法
三、代码实现
1.准备
2.计算\(\mu_{ij}\)与\(\sigma_{ij}\)
3.计算\(d(\mathbf{x})\)
4.外部执行框架
四、运行效果测试与同KNN比对
今天的内容是昨日的衍生,关于Naive Bayes的内容不再推导,这只说明对于数值型离散数据特殊添加的东西。
基于 Java 机器学习自学笔记 (第58天:符号型数据的Naive Bayes算法)_LTA_ALBlack的博客-CSDN博客注意:本篇为50天后的Java自学笔记扩充,内容不再是基础数据结构内容而是机器学习中的各种经典算法。这部分博客更侧重与笔记以方便自己的理解,自我知识的输出明显减少,若有错误欢迎指正!目录一、算法概念· 概率论回顾-条件概率与贝叶斯公式· 基本Naive Bayes推导· 基于程序设计的算法调整· Laplacian 平滑二、代码的变量确定三、代码实现1.构造函数2.计算\(P^{L}(D_i)\)3.计算\(P^{L}(x_jD_i)\)4.计算\(d(\mahttps://blog.csdn.net/qq_30016869/article/details/124624411
一、基础的概率论回顾
数值型数据体现在坐标轴上是一段连续的数据,这在概率上表示上不同于传统古典概型的离散的基于不同实例条件的概率问题:
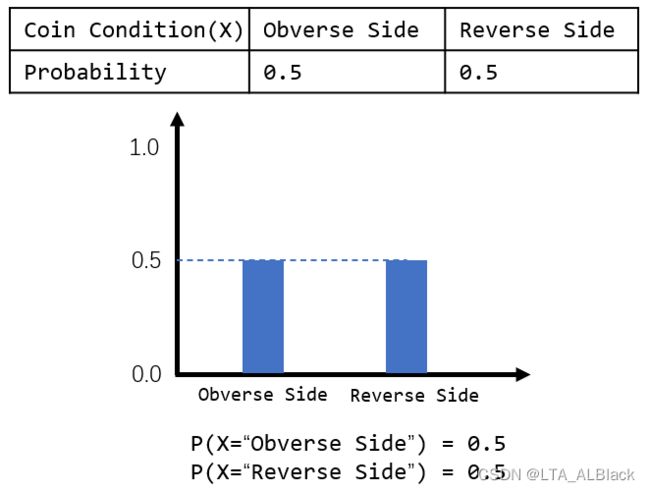
数值型的概率其往往基于具体的连续函数,并且表示的概率往往是通过随机变量的区间关系确定:
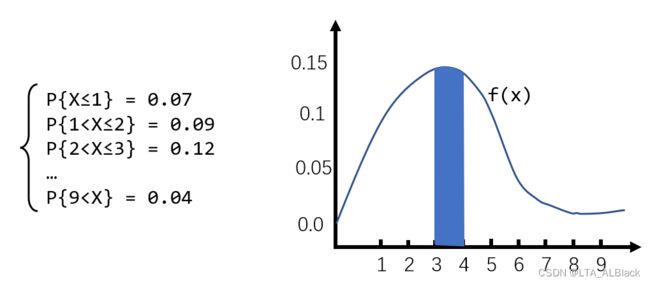
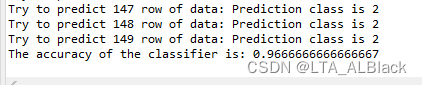
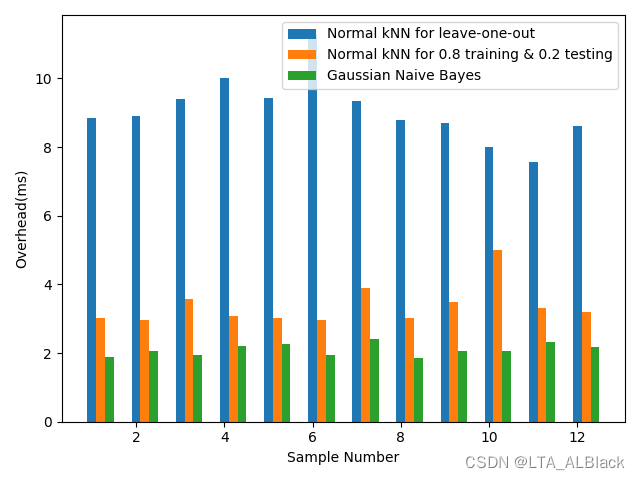
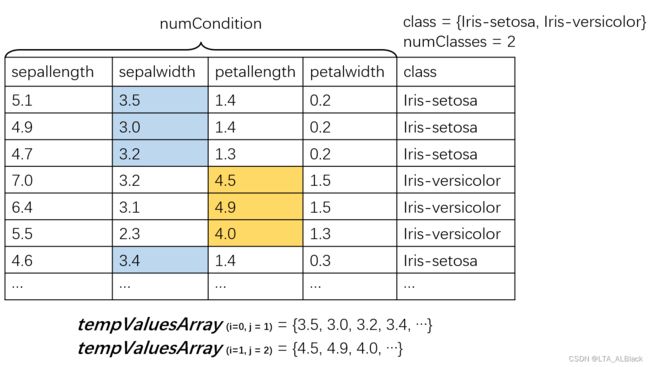
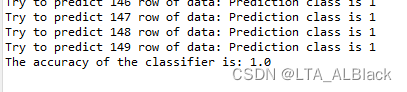
这样的概率问题我们往往都是通过计算概率密度函数积分范围的面积而确定概率,例如上图中\(P\{3 < X \leq 4\}\)的概率就可以用途中蓝色阴影部分的值来表示,同时可以确定,这个\(f(x)\)所覆盖的区间的值的总和就是1。即原本的概率计算有\[P\left\{x_{1} \leq X 依旧是那我们的iris数据说: 怎么描述呢,因为脱离了离散概率的特性,我们的概率表示应当是随机变量的区间,即假设对于第一列,sepallength为5.0的概率我可以使用\(P\left\{4.9 \leq sepallength<5.1\right\}=\int_{4.9}^{5.1} f(x) d x\)。但是针对离散的点集使用这种连续处理太过于麻烦了,于是我们进一步简化这个过程。 因为最终我们都是比对这些概率条件下的大小问题,因此我们可以让所有的数据列都适用一种概率评价指标。假设对于某个属性列\(X\)(随机变量),存在一个离散值\(x\)。这时我们设法将概率计算的区间缩小到足够小的范围\(\delta\)(\(\delta\)>0),理论上,计算\(X = x\)概率的公式应连续化表示为\[P\left\{x-\frac{\delta}{2} \leq X 那么我们怎么知道每个属性列服从何种分布呢?这里可以假设认为服从正态分布的,这种假设对于通常的未知数据是可靠的,稳定的。当然如果实现大概了解数据的特殊分布,使用这种分布的公式就好了!因此我们得到了数值型的离散数据的概率计算公式: (因为人们喜欢用\(p(x)\)表示概率密度函数,所以下式我就用\(p(x)\)代替\(f(x)\)了)\[p(x)=\frac{1}{\sqrt{2 \pi} \sigma} \exp \left(-\frac{(x-\mu)^{2}}{2 \sigma^{2}}\right) \tag{1}\] 昨天我们得到的Naive Bayes公式在未经过Laplacian平滑的环境下有公式\[d(\mathbf{x})={\arg \max }\left(\log P^{L}\left(D_{i}\right)+\sum_{j=1}^{m} \log P^{L}\left(x_{j} \mid D_{i}\right)\right) \tag{2} \] 这里2式中的\( P^{L} \left(x_{j} \mid D_{i}\right) \)拿出来,这里含义是在\(D_i\)决策下对于\(x_j\)属性列的概率计算,转化为数值型之后,这里的\(x_j\)列管辖的所有元素都是确定的数值而非字符了,因此可以计算出确定的在\(D_i\)条件下的\(\mu_{j}\),即\(\mu_{ij}\),同理也有\(\sigma_{ij}\)。但是上式中的\(P^{L}(D_i)\)并不需要代替,因为无论是数值型问题还是字符型问题,我们的决策结果总是一个确定的分类描述,这个描述是字符型的,这个是由我们研究的分类问题本质决定的。回归问题研究决策信息才是连续的数值。综上,用\(p(x_j)\)来代表2式中的\( P^{L} \left(x_{j} \mid D_{i}\right) \),从而得到下面的式子:\[d(\mathbf{x})=\underset{1 \leq i \leq k}{\arg \max } \left( \log P^{L}\left(D_{i}\right)+\sum_{j=1}^{m}-\log \left ( \frac{1}{\sqrt{2 \pi} \sigma_{ij}} e^{ \left(-\frac{(x_{j}-\mu_{ij})^{2}}{2 \sigma_{ij}^{2}}\right)} \right ) \right) \tag{3} \] 这个3式可以化简,首先在共同求最大值的操作中,正的常系数\(\frac{1}{\sqrt{2 \pi}}\)是可以忽略的,因为同时除这个系数不影响全局的大小关系。此外,将内部的指数运算同外部的\(\log\)结合,因此得到最终表达式:\[d(\mathbf{x})=\underset{1 \leq i \leq k}{\arg \max }\left ( \log P^{L}\left(D_{i}\right)+\sum_{j=1}^{m} \left ( -\log \sigma_{i j}-\frac{\left(x_{j}-\mu_{i j}\right)^{2}}{2 \sigma_{i j}^{2}} \right ) \right ) \tag{4}\] 这个式子就是数值型Naive Bayes的推导式了,因为一般都采用正态分布带描述一般的数值数据,而正态分布又叫做高斯分布,所以一般的数值型Naive Bayes又称之为Gaussian Naive Bayes算法。 为了辅助高斯函数,这里特别定义个类: 并无什么特别,只是用于记录\(mu\)与\(sigma\)。 今天的方法只在理论上修改了计算\(d(\mathbf{x})\)的部分内容,所以在代码上有许多昨天的代码可以继续重用,例如实现预先计算所有\(P^{L}(D_i)\)的函数calculateConditionalProbabilities可以继续保留,同时基本的代码逻辑与变量可以完全保留。 但是昨日计算\( P^{L} \left(x_{j} \mid D_{i}\right) \)的函数方法calculateConditionalProbabilities()因为\( P^{L} \left(x_{j} \mid D_{i}\right) \)被代替代而不再使用,同时计算\(d(\mathbf{x}\)的方法classifyNominal()也需要推翻。下面就讲下前者calculateConditionalProbabilities()的代替函数——calculateGausssianParameters()函数。 首先设置了一个numClasses * numConditions大小的数据,这里需要知道,如果要预先得到\(\mu_{ij}\)与\(\sigma_{ij}\)这两个有二维性质的数据,设置二维数组是必须的。这里numClasses表征了\(i\)的范围,numCondition表征了\(j\)的范围。 这个二维数组的数据项其实就是我们刚刚定义的高斯二元组。 通过这个图也许能很快找到意义。外层的两个循环就是敲定当前的\(i\)与\(j\),也就是说基本确定当前的均值与方差是要基于哪个决策类限制下的条件属性列的元素集,通过上图的例子,当\(i=0,j=1\)时得到的就是蓝色数据列,当\(i=1,j=2\)时为黄色数据列。 数值型的NB算法\(d(\mathbf{x})\)公式变化了,因此需要重新设计一个。 对照公式4,并且利用刚刚calculateGausssianParameters函数为我们准备的\(\mu_{ij}\)与\(\sigma_{ij}\),完成下述代码: 这个代码与昨日的classifyNominal非常相似,其实只改变了15行~20行的内容。 这部分执行框架同昨日一样(只有主函数只用的方法不一样)。这里再放出来方便代码的全局性理解与联系 执行的效果非常干脆,直接稳定在1.0的识别率,根本不给你任何横向比对的机会。当然,为了满足好奇心,我还是用KNN的leave-one-out测试跑了这个数据,准确度竟然还是1.0 这是iris-imbalance数据的表现。不服气的我再去试了下iris数据集(多了一个决策的类别): 数值型NB: NB算法执行的结果稳定在0.96,下面我再给出在53天时做KNN的leave-one-out测试时的准确度: 可以见得,KNN以0.967>0.96左右的优势略高一筹。首先,有可能是数据量太小难分伯仲;其次,也有可能这两个算法在准确度上确实很相近,这个有待我之后的学习去解决。 既然因为准确率看不出什么,那么开销总可以稍微看出一些端倪吧?(因为时间可以缩小单位)开销总结来说就是下面这张图: NB算法的开始就统计了全部需要使用的条件概率的关键参数,这些内容无疑都是基于全局的特征得到的结果。所以NB算法是基于leave-one-out的测试,也是因为这个原因,上面列出的KNN相似度我也都是用采用的leave-one-out测试的。 但在比对开销时,为了给KNN一些面子,我用80%训练-20%测试的随机性KNN算法同NB算法比对,但是实际上,NB算法特性的平行比对应该是leave-one-out的KNN。 总的来看,NB的处理速度要显著地快于KNN,就算是分割了训练与测试的样本的KNN,时间上也要略逊与NB,更别说做完全局测试的KNN,那时间开销已经接近若干倍了。 我简单分析了下NB的开销发现,NB具有最大的开销是一个三重循环,即有基础复杂度\(O(kMN)\),这里M为条件属性列个数,\(N\)为表长,\(k\)为决策属性列的类别数。一般来说数据的条件列不会特别地多,而决策类别也相对较少,值往往要远小于表长\(N\)。所以对于某些问题来说,这里的基础复杂度是近似于\(O(cN)\)(\(c\)为常数),可以说是一种伪线性,弱平方级别的。而KNN的基础复杂度就是平方级的,其中实现全数据检测是恐怖的\(O(kN^2)\)。虽然分割训练与测试时,最小的开销是采用\(\sqrt N\)的数据训练实现\(O(kN)\),但是分割测试终究是不公平和严谨的。 (当然。我还没有完全的信心一棒子敲死KNN与NB的比对,毕竟我还是机器学习初学者,更多细节和改正交给未来的我吧...)二、数值型Naive Bayes算法
@RELATION iris
@ATTRIBUTE sepallength REAL
@ATTRIBUTE sepalwidth REAL
@ATTRIBUTE petallength REAL
@ATTRIBUTE petalwidth REAL
@ATTRIBUTE class {Iris-setosa,Iris-versicolor}
@DATA
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
5.0,3.6,1.4,0.2,Iris-setosa
5.4,3.9,1.7,0.4,Iris-setosa
4.6,3.4,1.4,0.3,Iris-setosa
5.0,3.4,1.5,0.2,Iris-setosa
...
6.9,3.1,4.9,1.5,Iris-versicolor
5.5,2.3,4.0,1.3,Iris-versicolor
6.5,2.8,4.6,1.5,Iris-versicolor
5.7,2.8,4.5,1.3,Iris-versicolor
6.3,3.3,4.7,1.6,Iris-versicolor
4.9,2.4,3.3,1.0,Iris-versicolor
6.6,2.9,4.6,1.3,Iris-versicolor
5.2,2.7,3.9,1.4,Iris-versicolor
5.0,2.0,3.5,1.0,Iris-versicolor
...三、代码实现
1.准备
/**
*************************
* An inner class to store parameters.
*************************
*/
private class GaussianParamters {
double mu;
double sigma;
public GaussianParamters(double paraMu, double paraSigma) {
mu = paraMu;
sigma = paraSigma;
}// Of the constructor
public String toString() {
return "(" + mu + ", " + sigma + ")";
}// Of toString
}// Of GaussianParamters2.计算\(\mu_{ij}\)与\(\sigma_{ij}\)
/**
********************
* Calculate the conditional probabilities with Laplacian smooth.
********************
*/
public void calculateGausssianParameters() {
gaussianParameters = new GaussianParamters[numClasses][numConditions];
double[] tempValuesArray = new double[numInstances];
int tempNumValues = 0;
double tempSum = 0;
for (int i = 0; i < numClasses; i++) {
for (int j = 0; j < numConditions; j++) {
tempSum = 0;
// Obtain values for this class.
tempNumValues = 0;
for (int k = 0; k < numInstances; k++) {
if ((int) dataset.instance(k).classValue() != i) {
continue;
} // Of if
tempValuesArray[tempNumValues] = dataset.instance(k).value(j);
tempSum += tempValuesArray[tempNumValues];
tempNumValues++;
} // Of for k
// Obtain parameters.
double tempMu = tempSum / tempNumValues;
double tempSigma = 0;
for (int k = 0; k < tempNumValues; k++) {
tempSigma += (tempValuesArray[k] - tempMu) * (tempValuesArray[k] - tempMu);
} // Of for k
tempSigma /= tempNumValues;
tempSigma = Math.sqrt(tempSigma);
gaussianParameters[i][j] = new GaussianParamters(tempMu, tempSigma);
} // Of for j
} // Of for i
System.out.println(Arrays.deepToString(gaussianParameters));
}// Of calculateGausssianParameters
3.计算\(d(\mathbf{x})\)
/**
********************
* Classify an instances with numerical data.
********************
*/
public int classifyNumerical(Instance paraInstance) {
// Find the biggest one
double tempBiggest = -10000;
int resultBestIndex = 0;
for (int i = 0; i < numClasses; i++) {
double tempClassProbabilityLaplacian = Math.log(classDistributionLaplacian[i]);
double tempPseudoProbability = tempClassProbabilityLaplacian;
for (int j = 0; j < numConditions; j++) {
double tempAttributeValue = paraInstance.value(j);
double tempSigma = gaussianParameters[i][j].sigma;
double tempMu = gaussianParameters[i][j].mu;
tempPseudoProbability += -Math.log(tempSigma) - (tempAttributeValue - tempMu)
* (tempAttributeValue - tempMu) / (2 * tempSigma * tempSigma);
} // Of for j
if (tempBiggest < tempPseudoProbability) {
tempBiggest = tempPseudoProbability;
resultBestIndex = i;
} // Of if
} // Of for i
return resultBestIndex;
}// Of classifyNumerical
4.外部执行框架
/**
********************
* Classify all instances, the results are stored in predicts[].
********************
*/
public void classify() {
predicts = new int[numInstances];
for (int i = 0; i < numInstances; i++) {
predicts[i] = classify(dataset.instance(i));
} // Of for i
}// Of classify
/**
********************
* Classify an instances.
********************
*/
public int classify(Instance paraInstance) {
if (dataType == NOMINAL) {
return classifyNominal(paraInstance);
} else if (dataType == NUMERICAL) {
return classifyNumerical(paraInstance);
} // Of if
return -1;
}// Of classify
/**
********************
* Compute accuracy.
********************
*/
public double computeAccuracy() {
double tempCorrect = 0;
for (int i = 0; i < numInstances; i++) {
if (predicts[i] == (int) dataset.instance(i).classValue()) {
tempCorrect++;
} // Of if
} // Of for i
double resultAccuracy = tempCorrect / numInstances;
return resultAccuracy;
}// Of computeAccuracy
/**
*************************
* Test numerical data.
*************************
*/
public static void testNumerical() {
System.out.println(
"Hello, Naive Bayes. I only want to test the numerical data with Gaussian assumption.");
// String tempFilename = "D:/data/iris.arff";
String tempFilename = "D:/Java DataSet/iris-imbalance.arff";
NaiveBayes tempLearner = new NaiveBayes(tempFilename);
tempLearner.setDataType(NUMERICAL);
tempLearner.calculateClassDistribution();
tempLearner.calculateGausssianParameters();
tempLearner.classify();
System.out.println("The accuracy is: " + tempLearner.computeAccuracy());
}// Of testNominal
/**
*************************
* Test this class.
*
* @param args
* Not used now.
*************************
*/
public static void main(String[] args) {
testNumerical();
}// Of main四、运行效果测试与同KNN比对

@RELATION iris
@ATTRIBUTE sepallength REAL
@ATTRIBUTE sepalwidth REAL
@ATTRIBUTE petallength REAL
@ATTRIBUTE petalwidth REAL
@ATTRIBUTE class {Iris-setosa,Iris-versicolor,Iris-virginica}
@DATA
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
5.0,3.6,1.4,0.2,Iris-setosa
5.4,3.9,1.7,0.4,Iris-setosa
4.6,3.4,1.4,0.3,Iris-setosa
...