pandas的简单使用(查询)
pandas的简单使用(查询)
- head() 和 tail() 函数
- loc 函数
-
- 双索引的loc使用
- 使用演示
- iloc 函数
- 条件查询
-
- 简单逻辑查询
- 模糊查询
-
- startswith() 按开头字符串进行查找
- endswith() 按结尾字符串进行查找
- contains() 模糊查询
- 不常用的骚操作
- 关联查询 Merge
-
- merge的语法
- merge 数量的对齐关系
-
- 一对一
- 一对多
- 多对多
- 理解left join、right join、inner join、outer join的区别
-
- inner join 默认
- left join
- right join
- outer join
- 非Key的字段重名
pandas用户指南:https://pandas.pydata.org/pandas-docs/stable/user_guide/index.html
df['列名'] 与 df.列名
输出结果是一致的。哪怕列名是中文也可以
但两个都只能输出一列,如果要输出多列 df[['列1','列2','列3']]
head() 和 tail() 函数
# 查看前5行
df.head()
# 查看前100行
df.head(100)
# 查看最后5行
df.tail()
# 查看最后100行
df.tail(100)
loc 函数
语法是df.loc[行名,列名]。有的时候会省略loc,直接这么写df[行名,列名]
# 查看索引为3的那一行的数据,如果df的索引不是数字而是abcd这种字符串时,要这么写df.loc[d,:]
df.loc[3,:]
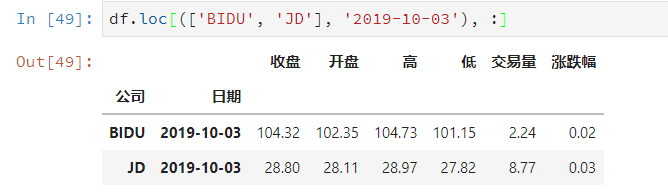
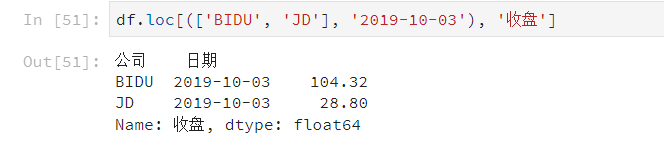
# 查看指定索引,指定列
df.loc['索引1', '列3']
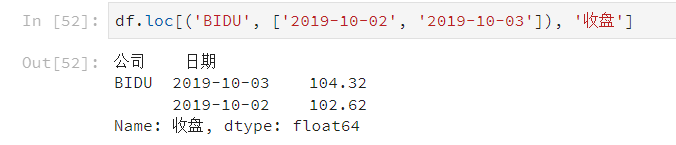
# 行和列都按区间查询
df.loc[['索引1','索引2'], ['列1','列2','列3']]
df.loc['索引1':'索引n', '列1':'列n']]
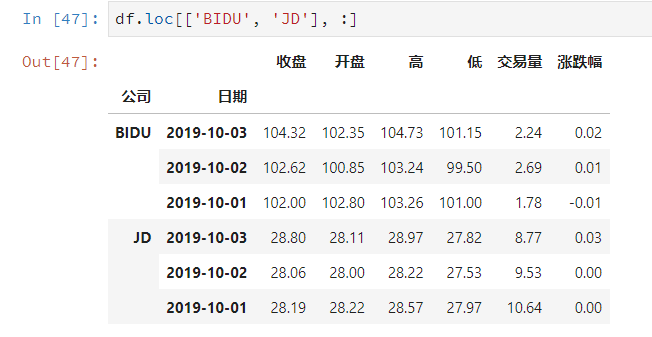
# 选择指定行或指定列(若参数只有索引,列位置的冒号可省略)
df.loc[['索引1', '索引2', '索引3', '索引4']]
df.loc[:,['列1','列2','列3']]
# 若省略loc,那么参数只能是列名
df[['列1','列2','列3']]
双索引的loc使用
import pandas as pd
df = pd.read_excel('F:\Temp\datas\stocks\互联网公司股票.xlsx')
'''
print(df.index)
RangeIndex(start=0, stop=12, step=1)
'''
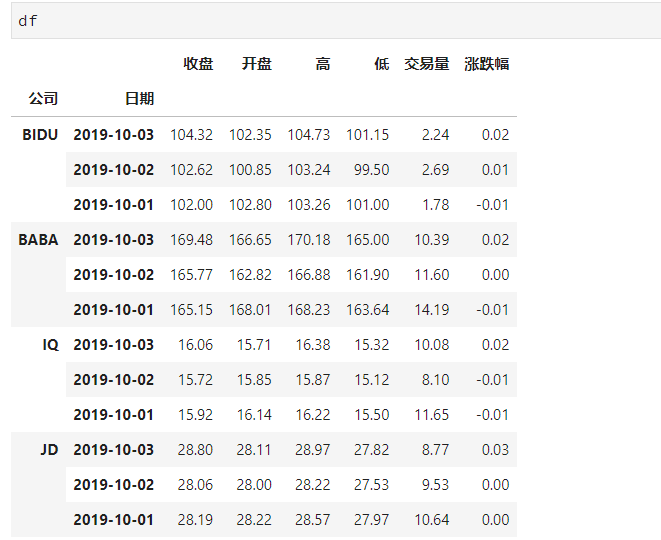
df.set_index(['公司', '日期'], inplace=True)
| df修改索引前 | df修改索引后 | df的索引(双索引是元组形式的) |
|---|---|---|
 |
 |
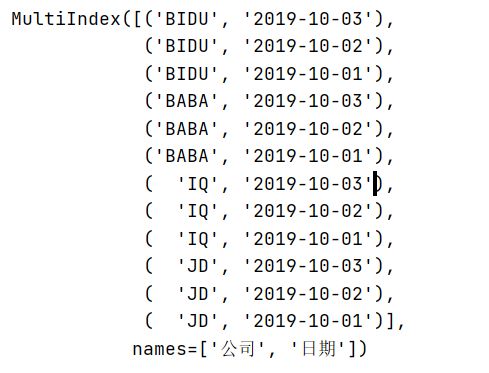 |
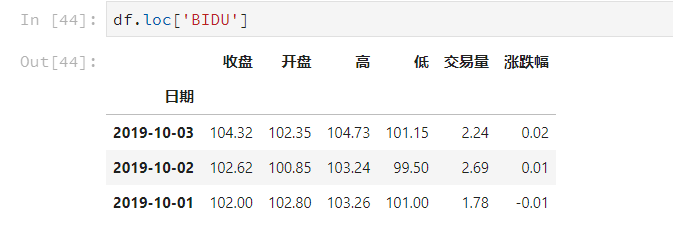
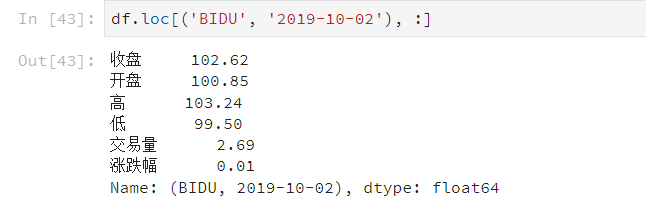
- 元组(key1,key2)代表筛选多层索引,其中key1是索引第一级,key2是第二级,比如key1=JD, key2=2019-10-02
- 列表[key1,key2]代表同一层的多个KEY,其中key1和key2是并列的同级索引,比如key1=JD, key2=BIDU
使用演示
 |
 |
 |
 |
 |
 |
 |
 |
iloc 函数
语法是df.iloc[行号,列号]。 无论行列,都是从0开始数
# 查看顺序数第4行的数据。 这个值索引无关,iloc只接收数字,并且从0开始计数
df.iloc[3,:]
# 查看指定行,指定列(以人的思维来数,就是第三行,第七列)
df.iloc[2,6]
# 指定行 (与字符串截取类似)
df.iloc[3:] # 以人的思维来数,从第4行开始直到结束,所有列
df.iloc[0:10] # 前十行,所有列 等价于 df[:10]
df.iloc[::-1] # 从倒数第一行开始,倒着输出(tail函数只是输出倒数几行,但顺序还是正的)
# 指定列 (与字符串截取类似)
df.iloc[5, 3:] # 以人的思维来数,只显示第6行的数据,从第4列开始
df.iloc[:, :5] # 显示所有行,但只有前5列
# 以人的思维来数,2到8行(8不包含),1到4列(4不包含)
df.iloc[2:8, 1:4]
# iloc与loc的混合使用(下面两个结果一样)
df.iloc[::-1].loc[:,['学会','姓名','年龄']]
df[::-1][['学会','姓名','年龄']]
条件查询
# 输出所有列
xxx = df[(条件1) & (条件2) & (条件3)]
xxx = df.loc[(条件1) | (条件2) | (条件3)]
xxx = df.loc[(条件1) | (条件2) | (条件3),:]
# 输出指定列
xxx = df[条件].iloc[:,列范围]
xxx = df.loc[(条件), ['列1','列2']]
xxx = df.loc[ 条件 ].iloc[:,列范围]
对于下面的那些代码。loc都是可省略的,还有条件后面的逗号和冒号
简单逻辑查询
# 月收入小于6千且年龄小于30的(注意括号)
df[(df['MonthlyIncome']<6000) & (df['age']<30)]
# 月收入等于3千的
df.loc[df['MonthlyIncome']==3000,:]
# 月收入在3千到1万之间的(注意括号)
df.loc[(df['MonthlyIncome']<=10000) & (df['MonthlyIncome']>=3000),:]
df[df['MonthlyIncome'].between(3000,10000)]
# 上面几个都可以用query函数来表示 例如
df.query("MonthlyIncome=<6000 & age<30")
# 月收入等于3千,5千,7千,9千其中之一的
df.loc[df['MonthlyIncome'].isin([3000,5000,7000,9000]),:]
# 取反
df[~df['MonthlyIncome'].isin([3000,5000,7000,9000])]
# 查询部门这一列值是空的
df[pd.isnull(df['部门'])]
df[df['部门'].isnull()]
# 筛选数据中 存在空值的行
df[df.isnull().T.any()]
df[pd.isnull(df).T.any()]
# 筛选数据中 整行数据都非空的行
df[df.notnull().T.all()]
df[pd.notnull(df).T.all()]
模糊查询
startswith() 按开头字符串进行查找
# 查询姓张
df.loc[df.名字.str.startswith('张')]
# 查询学校名称开头是 四川 的
df.loc[df.school.str.startswith('四川')]
endswith() 按结尾字符串进行查找
# 查询名字以 博 结尾的
df.loc[df.名字.str.endswith('博')]
# 查询学校名称结尾是 校区 的
df.loc[df.school.str.endswith('校区')]
contains() 模糊查询
# 查询名字里有 熊 这个字的
df.query('名字.str.contains("熊")',engine='python')
df.loc[df.名字.str.contains('熊')]
# 查询 实验 学校
df.loc[df.school.str.contains('实验')]
df.loc[df['school'].str.contains('实验')]
对于正则表达式的查询,写了几个语法,但跟预想的效果完全不一样
df.loc[df.school.str.contains(‘北京’ and ‘大学’)]
df.loc[df.school.str.contains(‘北京’ or ‘大学’)]
df.loc[df.school.str.contains(‘北京&大学’)]
df.loc[df.school.str.contains(‘北京|大学’)]
不常用的骚操作
import numpy as np
# 查询 实验 学校
df.loc[np.char.find(df['school'].values.astype(str), '实验')>-1]
df.loc[['实验' in x for x in df['场景名称']]]
关联查询 Merge
此部分资料来源于B站up主:https://www.bilibili.com/video/BV1UJ411A7Fs?p=13
Merge官网:https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html#merge
Pandas的Merge,相当于SQL的join,将不同的表按key关联到一个表
merge的语法
pd.merge(left='left_df', right='right_df', how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=('_x','_y'), copy=True, indicator=False, validate=None)
- left,right:要merge的DataFrame或者有name的Serier
- how:join类型, “left”,“right”,“outer”,“inner”
- on:join的key,left和right都有需要有这个key
- left_on:left的DataFrame或者Serier的key
- right_on:right的DataFrame或者Serier的key
- left_index,right_index:使用index而不是普通的column做join
- suffixes:两个元素的后缀,如果列有重名,自动添加后缀,默认是(’_x’,’_y’)
import pandas as pd
pd.set_option('display.max_rows', 80)
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 1000)
ratings = pd.read_csv('F:\\data\\ratings.dat', sep='::', engine='python', names=['UserID','MovieId','Rating','Times'])
users = pd.read_csv('F:\\data\\users.dat', sep='::', engine='python', names=['UserID','Gendes','Age','Occupation','Zip-code'])
movies = pd.read_csv('F:\\data\\movies.dat', sep='::', engine='python', names=['MovieId','Title','Gendes'])
# 两个表关联
# select * from ratings,user where ratings.UserID==user.UserID
df_ratings_users = pd.merge(ratings, users, left_on='UserID', right_on='UserID', how='inner')
# 多表关联(多表关联需要多些几次)
# select * from ratings,user,movies where ratings.UserID==user.UserID and ratings.MovieId==movies.MovieId
ratings_users = pd.merge(ratings, users, left_on='UserID', right_on='UserID', how='inner')
df_ratings_users_movies = pd.merge(ratings_users, movies, left_on='MovieId', right_on='MovieId', how='inner')
merge 数量的对齐关系
一对一
- one-to-one: 一对一关系,关联的key都是唯一
比如 (学号,姓名) merge(学号,年龄)
结果条数为:1*1
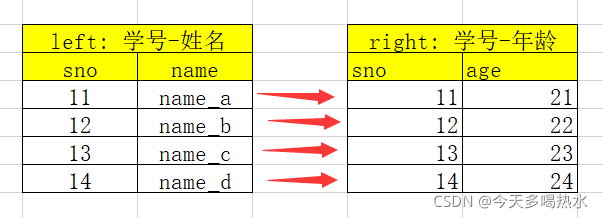
import pandas as pd
left = pd.DataFrame({'sno': [11, 12, 13, 14],
'name': ['name_a', 'name_b', 'name_c', 'name_d']
})
right = pd.DataFrame({'sno': [11, 12, 13, 14],
'age': ['21', '22', '23', '24']
})
# 一对一关系,结果中有4条
print(pd.merge(left, right, on='sno'))
'''
sno name age
0 11 name_a 21
1 12 name_b 22
2 13 name_c 23
3 14 name_d 24
'''
一对多
- one-to-many: 一对多关系,左边唯一key,右边不唯一key
比如 (学号,姓名) merge(学号,[语文成绩、数学成绩、英语成绩])
结果条数为:1*N
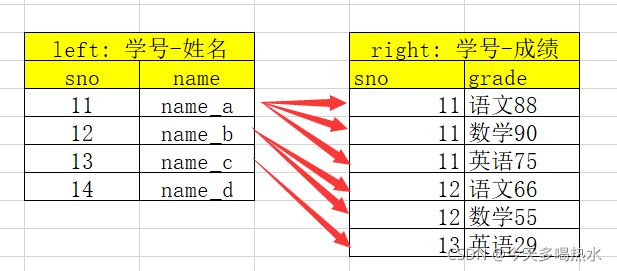
import pandas as pd
left = pd.DataFrame({'sno': [11, 12, 13, 14],
'name': ['name_a', 'name_b', 'name_c', 'name_d']
})
right = pd.DataFrame({'sno': [11, 11, 11, 12, 12, 13],
'grade': ['语文88', '数学90', '英语75','语文66', '数学55', '英语29']
})
# 数目以多的一边为准(可以看到数据被复制了)
print(pd.merge(left, right, on='sno'))
'''
sno name grade
0 11 name_a 语文88
1 11 name_a 数学90
2 11 name_a 英语75
3 12 name_b 语文66
4 12 name_b 数学55
5 13 name_c 英语29
'''
多对多
- many-to-many: 多对多关系,左边右边都不是唯一的
比如(学号,[语文成绩、数学成绩、英语成绩]) merge (学号,[篮球、足球、乒乓球])
结果条数为:M*N

import pandas as pd
left = pd.DataFrame({'sno': [11, 11, 12, 12,12],
'爱好': ['篮球', '羽毛球', '乒乓球', '篮球', "足球"]
})
right = pd.DataFrame({'sno': [11, 11, 11, 12, 12, 13],
'grade': ['语文88', '数学90', '英语75','语文66', '数学55', '英语29']
})
# 数量出现了乘法
print(pd.merge(left, right, on='sno'))
'''
sno 爱好 grade
0 11 篮球 语文88
1 11 篮球 数学90
2 11 篮球 英语75
3 11 羽毛球 语文88
4 11 羽毛球 数学90
5 11 羽毛球 英语75
6 12 乒乓球 语文66
7 12 乒乓球 数学55
8 12 篮球 语文66
9 12 篮球 数学55
10 12 足球 语文66
11 12 足球 数学55
'''
理解left join、right join、inner join、outer join的区别

import pandas as pd
left_df = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right_df = pd.DataFrame({'key': ['K0', 'K1', 'K4', 'K5'],
'C': ['C0', 'C1', 'C4', 'C5'],
'D': ['D0', 'D1', 'D4', 'D5']})
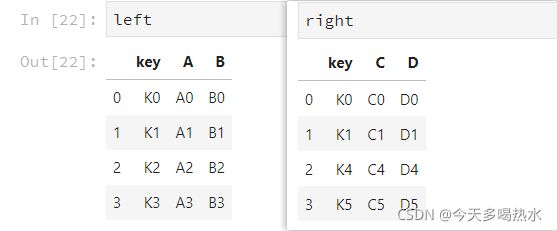
inner join 默认
左边和右边的key都有,才会出现在结果里
df = pd.merge(left_df, right_df, how='inner')
print(df)
'''
key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
'''
left join
左边的都会出现在结果里,右边的如果无法匹配则为Null
df = pd.merge(left_df, right_df, how='left')
print(df)
'''
key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 NaN NaN
3 K3 A3 B3 NaN NaN
'''
right join
右边的都会出现在结果里,左边的如果无法匹配则为Null
df = pd.merge(left_df, right_df, how='right')
print(df)
'''
key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K4 NaN NaN C4 D4
3 K5 NaN NaN C5 D5
'''
outer join
左边、右边的都会出现在结果里,如果无法匹配则为Null
key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 NaN NaN
3 K3 A3 B3 NaN NaN
4 K4 NaN NaN C4 D4
5 K5 NaN NaN C5 D5
非Key的字段重名
import pandas as pd
left_df = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right_df = pd.DataFrame({'key': ['K0', 'K1', 'K4', 'K5'],
'A': ['A10', 'A11', 'A12', 'A13'],
'D': ['D0', 'D1', 'D4', 'D5']})

默认情况
df = pd.merge(left_df, right_df, on='key')
print(df)
'''
key A_x B A_y D
0 K0 A0 B0 A10 D0
1 K1 A1 B1 A11 D1
'''
自己添加后缀
df = pd.merge(left_df, right_df, on='key', suffixes=('_left', '_right'))
print(df)
'''
key A_left B A_right D
0 K0 A0 B0 A10 D0
1 K1 A1 B1 A11 D1
'''