学术前沿 | Texar-PyTorch:在PyTorch里重现TensorFlow的最佳特性
点上方蓝字计算机视觉联盟获取更多干货
在右上方 ··· 设为星标 ★,与你不见不散
编辑:Sophia
计算机视觉联盟 报道 | 公众号 CVLianMeng
转载于 :https://github.com/asyml/texar-pytorch
推荐文章【点击下面可直接跳转】:
OpenCV测量物体的尺寸技能
AI博士笔记系列推荐:
博士笔记 | 周志华《机器学习》手推笔记思维导图
博士笔记 | 周志华《机器学习》手推笔记“模型评估”
博士笔记 | 周志华《机器学习》手推笔记“线性模型”
博士笔记 | 周志华《机器学习》手推笔记“决策树”
博士笔记 | 周志华《机器学习》手推笔记“神经网络”
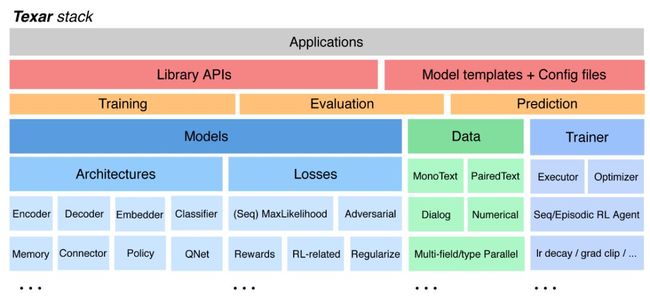
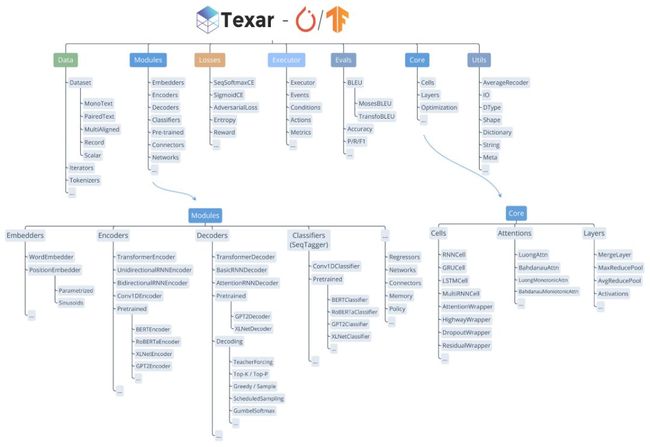
Texar-PyTorch是一个工具包旨在支持广泛的机器学习,尤其是自然语言处理和文本生成任务。 Texar图书馆提供了一个易于使用的ML模块和功能组合模型和算法。 这个工具是专为快速原型和实验的研究者和实践者都。
Texar-PyTorch集成TensorFlow进入PyTorch许多最好的特性,提供高度可用和可定制的模块优于PyTorch原生的。
Key Features
Two Versions, (Mostly) Same Interfaces. Texar-PyTorch (this repo) and Texar-TF have mostly the same interfaces. Both further combine the best design of TF and PyTorch:
-
Interfaces and variable sharing in PyTorch convention
Excellent factorization and rich functionalities in TF convention.
Versatile to support broad needs:
-
data processing, model architectures, loss functions, training and inference algorithms, evaluation, ...
encoder(s) to decoder(s), sequential- and self-attentions, memory, hierarchical models, classifiers, ...
maximum likelihood learning, reinforcement learning, adversarial learning, probabilistic modeling, ...
Fully Customizable at multiple abstraction level -- both novice-friendly and expert-friendly.
-
Free to plug in whatever external modules, since Texar is fully compatible with the native PyTorch APIs.
Modularized for maximal re-use and clean APIs, based on principled decomposition of Learning-Inference-Model Architecture.
Rich Pre-trained Models, Rich Usage with Uniform Interfaces. BERT, GPT2, XLNet, etc, for encoding, classification, generation, and composing complex models with other Texar components!
Clean, detailed documentation and rich examples.
import texar.torch as tx
from texar.torch.run import *
# (1) Modeling
class ConditionalGPT2Model(nn.Module):
"""An encoder-decoder model with GPT-2 as the decoder."""
def __init__(self, vocab_size):
super().__init__()
# Use hyperparameter dict for model configuration
self.embedder = tx.modules.WordEmbedder(vocab_size, hparams=emb_hparams)
self.encoder = tx.modules.TransformerEncoder(hparams=enc_hparams)
self.decoder = tx.modules.GPT2Decoder("gpt2-small") # With pre-trained weights
def _get_decoder_output(self, batch, train=True):
"""Perform model inference, i.e., decoding."""
enc_states = self.encoder(inputs=self.embedder(batch['source_text_ids']),
sequence_length=batch['source_length'])
if train: # Teacher-forcing decoding at training time
return self.decoder(
inputs=batch['target_text_ids'], sequence_length=batch['target_length'] - 1,
memory=enc_states, memory_sequence_length=batch['source_length'])
else: # Beam search decoding at prediction time
start_tokens = torch.full_like(batch['source_text_ids'][:, 0], BOS)
return self.decoder(
beam_width=5, start_tokens=start_tokens,
memory=enc_states, memory_sequence_length=batch['source_length'])
def forward(self, batch):
"""Compute training loss."""
outputs = self._get_decoder_output(batch)
loss = tx.losses.sequence_sparse_softmax_cross_entropy( # Sequence loss
labels=batch['target_text_ids'][:, 1:], logits=outputs.logits,
sequence_length=batch['target_length'] - 1) # Automatic masking
return {"loss": loss}
def predict(self, batch):
"""Compute model predictions."""
sequence, _ = self._get_decoder_output(batch, train=False)
return {"gen_text_ids": sequence}
# (2) Data
# Create dataset splits using built-in data loaders
datasets = {split: tx.data.PairedTextData(hparams=data_hparams[split])
for split in ["train", "valid", "test"]}
model = ConditionalGPT2Model(datasets["train"].target_vocab.size)
# (3) Training
# Manage the train-eval loop with the Executor API
executor = Executor(
model=model, datasets=datasets,
optimizer={"type": torch.optim.Adam, "kwargs": {"lr": 5e-4}},
stop_training_on=cond.epoch(20),
log_every=cond.iteration(100),
validate_every=cond.epoch(1),
train_metric=("loss", metric.RunningAverage(10, pred_name="loss")),
valid_metric=metric.BLEU(pred_name="gen_text_ids", label_name="target_text_ids"),
save_every=cond.validation(better=True),
checkpoint_dir="outputs/saved_models/")
executor.train()
executor.test(datasets["test"])
END
声明:本文来源于Github
如有侵权,联系删除
联盟学术交流群
扫码添加联盟小编,可与相关学者研究人员共同交流学习:目前开设有人工智能、机器学习、计算机视觉、自动驾驶(含SLAM)、Python、求职面经、综合交流群扫描添加CV联盟微信拉你进群,备注:CV联盟

最新热文荐读
GitHub | 计算机视觉最全资料集锦(含实验室、算法及AI会议)
Github | 标星1W+清华大学计算机系课程攻略!
GitHub | Facebook重磅开源目标检测工具!标星超2万+
Github | 吴恩达新书《Machine Learning Yearning》完整中文版开源
收藏 | 2020年AI、CV、NLP顶会最全时间表!
收藏 | 博士大佬总结的Pycharm 常用快捷键思维导图!
收藏 | 最全深度学习视觉目标检测技术综述!
内推 | 4399小游戏
内推 | 无人驾驶~小马智行Pony.ai 2020
内推 | 虎牙直播2020校招
内推 | 字节跳动内推
前沿 | 阿里达摩院发布2019十大科技趋势!未来无限可期!

点个在看支持一下吧