什么是Mask R-CNN
来看看很厉害的Mask R-CNN实例分割的原理吧,还是挺有意思的呢!

Mask R-CNN是He Kaiming大神2017年的力作,其在进行目标检测的同时进行实例分割,取得了出色的效果。
其网络的设计也比较简单,在Faster R-CNN基础上,在原本的两个分支上(分类+坐标回归)增加了一个分支进行语义分割,
源码下载
Mask R-CNN实现思路
一、预测部分
1、主干网络介绍
Mask-RCNN使用Resnet101作为主干特征提取网络,对应着图像中的CNN部分,其对输入进来的图片有尺寸要求,需要可以整除2的6次方。在进行特征提取后,利用长宽压缩了两次、三次、四次、五次的特征层来进行特征金字塔结构的构造。
ResNet101有两个基本的块,分别名为Conv Block和Identity Block,其中Conv Block输入和输出的维度是不一样的,所以不能连续串联,它的作用是改变网络的维度;Identity Block输入维度和输出维度相同,可以串联,用于加深网络的。
Conv Block的结构如下:

Identity Block的结构如下:
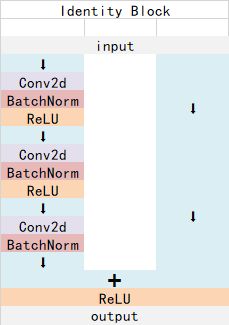
这两个都是残差网络结构。
以官方使用的coco数据集输入的shape为例,输入的shape为1024x1024,shape变化如下:

我们取出长宽压缩了两次、三次、四次、五次的结果来进行特征金字塔结构的构造。
实现代码:
from keras.layers import ZeroPadding2D,Conv2D,MaxPooling2D,BatchNormalization,Activation,Add
def identity_block(input_tensor, kernel_size, filters, stage, block,
use_bias=True, train_bn=True):
nb_filter1, nb_filter2, nb_filter3 = filters
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
x = Conv2D(nb_filter1, (1, 1), name=conv_name_base + '2a',
use_bias=use_bias)(input_tensor)
x = BatchNormalization(name=bn_name_base + '2a')(x, training=train_bn)
x = Activation('relu')(x)
x = Conv2D(nb_filter2, (kernel_size, kernel_size), padding='same',
name=conv_name_base + '2b', use_bias=use_bias)(x)
x = BatchNormalization(name=bn_name_base + '2b')(x, training=train_bn)
x = Activation('relu')(x)
x = Conv2D(nb_filter3, (1, 1), name=conv_name_base + '2c',
use_bias=use_bias)(x)
x = BatchNormalization(name=bn_name_base + '2c')(x, training=train_bn)
x = Add()([x, input_tensor])
x = Activation('relu', name='res' + str(stage) + block + '_out')(x)
return x
def conv_block(input_tensor, kernel_size, filters, stage, block,
strides=(2, 2), use_bias=True, train_bn=True):
nb_filter1, nb_filter2, nb_filter3 = filters
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
x = Conv2D(nb_filter1, (1, 1), strides=strides,
name=conv_name_base + '2a', use_bias=use_bias)(input_tensor)
x = BatchNormalization(name=bn_name_base + '2a')(x, training=train_bn)
x = Activation('relu')(x)
x = Conv2D(nb_filter2, (kernel_size, kernel_size), padding='same',
name=conv_name_base + '2b', use_bias=use_bias)(x)
x = BatchNormalization(name=bn_name_base + '2b')(x, training=train_bn)
x = Activation('relu')(x)
x = Conv2D(nb_filter3, (1, 1), name=conv_name_base +
'2c', use_bias=use_bias)(x)
x = BatchNormalization(name=bn_name_base + '2c')(x, training=train_bn)
shortcut = Conv2D(nb_filter3, (1, 1), strides=strides,
name=conv_name_base + '1', use_bias=use_bias)(input_tensor)
shortcut = BatchNormalization(name=bn_name_base + '1')(shortcut, training=train_bn)
x = Add()([x, shortcut])
x = Activation('relu', name='res' + str(stage) + block + '_out')(x)
return x
def get_resnet(input_image,stage5=False, train_bn=True):
# Stage 1
x = ZeroPadding2D((3, 3))(input_image)
x = Conv2D(64, (7, 7), strides=(2, 2), name='conv1', use_bias=True)(x)
x = BatchNormalization(name='bn_conv1')(x, training=train_bn)
x = Activation('relu')(x)
# Height/4,Width/4,64
C1 = x = MaxPooling2D((3, 3), strides=(2, 2), padding="same")(x)
# Stage 2
x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1), train_bn=train_bn)
x = identity_block(x, 3, [64, 64, 256], stage=2, block='b', train_bn=train_bn)
# Height/4,Width/4,256
C2 = x = identity_block(x, 3, [64, 64, 256], stage=2, block='c', train_bn=train_bn)
# Stage 3
x = conv_block(x, 3, [128, 128, 512], stage=3, block='a', train_bn=train_bn)
x = identity_block(x, 3, [128, 128, 512], stage=3, block='b', train_bn=train_bn)
x = identity_block(x, 3, [128, 128, 512], stage=3, block='c', train_bn=train_bn)
# Height/8,Width/8,512
C3 = x = identity_block(x, 3, [128, 128, 512], stage=3, block='d', train_bn=train_bn)
# Stage 4
x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a', train_bn=train_bn)
block_count = 22
for i in range(block_count):
x = identity_block(x, 3, [256, 256, 1024], stage=4, block=chr(98 + i), train_bn=train_bn)
# Height/16,Width/16,1024
C4 = x
# Stage 5
if stage5:
x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a', train_bn=train_bn)
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='b', train_bn=train_bn)
# Height/32,Width/32,2048
C5 = x = identity_block(x, 3, [512, 512, 2048], stage=5, block='c', train_bn=train_bn)
else:
C5 = None
return [C1, C2, C3, C4, C5]
2、特征金字塔FPN的构建

特征金字塔FPN的构建是为了实现特征多尺度的融合,在Mask R-CNN当中,我们取出在主干特征提取网络中长宽压缩了两次C2、三次C3、四次C4、五次C5的结果来进行特征金字塔结构的构造。

提取到的P2、P3、P4、P5、P6可以作为RPN网络的有效特征层,利用RPN建议框网络对有效特征层进行下一步的操作,对先验框进行解码获得建议框。
提取到的P2、P3、P4、P5可以作为Classifier和Mask网络的有效特征层,利用Classifier预测框网络对有效特征层进行下一步的操作,对建议框解码获得最终预测框;利用Mask语义分割网络对有效特征层进行下一步的操作,获得每一个预测框内部的语义分割结果。
实现代码如下:
# 获得Resnet里的压缩程度不同的一些层
_, C2, C3, C4, C5 = get_resnet(input_image, stage5=True, train_bn=config.TRAIN_BN)
# 组合成特征金字塔的结构
# P5长宽共压缩了5次
# Height/32,Width/32,256
P5 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c5p5')(C5)
# P4长宽共压缩了4次
# Height/16,Width/16,256
P4 = Add(name="fpn_p4add")([
UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5),
Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c4p4')(C4)])
# P4长宽共压缩了3次
# Height/8,Width/8,256
P3 = Add(name="fpn_p3add")([
UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4),
Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c3p3')(C3)])
# P4长宽共压缩了2次
# Height/4,Width/4,256
P2 = Add(name="fpn_p2add")([
UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3),
Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c2p2')(C2)])
# 各自进行一次256通道的卷积,此时P2、P3、P4、P5通道数相同
# Height/4,Width/4,256
P2 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p2")(P2)
# Height/8,Width/8,256
P3 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p3")(P3)
# Height/16,Width/16,256
P4 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p4")(P4)
# Height/32,Width/32,256
P5 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p5")(P5)
# 在建议框网络里面还有一个P6用于获取建议框
# Height/64,Width/64,256
P6 = MaxPooling2D(pool_size=(1, 1), strides=2, name="fpn_p6")(P5)
# P2, P3, P4, P5, P6可以用于获取建议框
rpn_feature_maps = [P2, P3, P4, P5, P6]
# P2, P3, P4, P5用于获取mask信息
mrcnn_feature_maps = [P2, P3, P4, P5]
3、获得Proposal建议框
由上一步获得的有效特征层在图像中就是Feature Map,其有两个应用,一个是和ROIAsign结合使用、另一个是进入到Region Proposal Network进行建议框的获取。
在进行建议框获取的时候,我们使用的有效特征层是P2、P3、P4、P5、P6,它们使用同一个RPN建议框网络获取先验框调整参数,还有先验框内部是否包含物体。
在Mask R-cnn中,RPN建议框网络的结构和Faster RCNN中的RPN建议框网络类似。
首先进行一次3x3的通道数为512的卷积。
然后再分别进行一次anchors_per_location x 4的卷积 和一次anchors_per_location x 2的卷积。
anchors_per_location x 4的卷积 用于预测 公用特征层上 每一个网格点上 每一个先验框的变化情况。(为什么说是变化情况呢,这是因为Faster-RCNN的预测结果需要结合先验框获得预测框,预测结果就是先验框的变化情况。)
anchors_per_location x 2的卷积 用于预测 公用特征层上 每一个网格点上 每一个预测框内部是否包含了物体。
当我们输入的图片的shape是1024x1024x3的时候,公用特征层的shape就是256x256x256、128x128x256、64x64x256、32x32x256、16x16x256,相当于把输入进来的图像分割成不同大小的网格,然后每个网格默认存在3(anchors_per_location )个先验框,这些先验框有不同的大小,在图像上密密麻麻。
anchors_per_location x 4的卷积的结果会对这些先验框进行调整,获得一个新的框。
anchors_per_location x 2的卷积会判断上述获得的新框是否包含物体。
到这里我们可以获得了一些有用的框,这些框会利用anchors_per_location x 2的卷积判断是否存在物体。
到此位置还只是粗略的一个框的获取,也就是一个建议框。然后我们会在建议框里面继续找东西。
实现代码为:
#------------------------------------#
# 五个不同大小的特征层会传入到
# RPN当中,获得建议框
#------------------------------------#
def rpn_graph(feature_map, anchors_per_location):
shared = Conv2D(512, (3, 3), padding='same', activation='relu',
name='rpn_conv_shared')(feature_map)
x = Conv2D(2 * anchors_per_location, (1, 1), padding='valid',
activation='linear', name='rpn_class_raw')(shared)
# batch_size,num_anchors,2
# 代表这个先验框对应的类
rpn_class_logits = Reshape([-1,2])(x)
rpn_probs = Activation(
"softmax", name="rpn_class_xxx")(rpn_class_logits)
x = Conv2D(anchors_per_location * 4, (1, 1), padding="valid",
activation='linear', name='rpn_bbox_pred')(shared)
# batch_size,num_anchors,4
# 这个先验框的调整参数
rpn_bbox = Reshape([-1,4])(x)
return [rpn_class_logits, rpn_probs, rpn_bbox]
#------------------------------------#
# 建立建议框网络模型
# RPN模型
#------------------------------------#
def build_rpn_model(anchors_per_location, depth):
input_feature_map = Input(shape=[None, None, depth],
name="input_rpn_feature_map")
outputs = rpn_graph(input_feature_map, anchors_per_location)
return Model([input_feature_map], outputs, name="rpn_model")
4、Proposal建议框的解码
通过第二步我们获得了许多个先验框的预测结果。预测结果包含两部分。
anchors_per_location x 4的卷积 用于预测 有效特征层上 每一个网格点上 每一个先验框的变化情况。**
anchors_per_location x 1的卷积 用于预测 有效特征层上 每一个网格点上 每一个预测框内部是否包含了物体。
相当于就是将整个图像分成若干个网格;然后从每个网格中心建立3个先验框,当输入的图像是1024,1024,3的时候,总共先验框数量为196608+49152+12288+3072+768 = 261,888
当输入图像shape不同时,先验框的数量也会发生改变。
先验框虽然可以代表一定的框的位置信息与框的大小信息,但是其是有限的,无法表示任意情况,因此还需要调整。
anchors_per_location x 4中的anchors_per_location 表示了这个网格点所包含的先验框数量,其中的4表示了框的中心与长宽的调整情况。
实现代码如下:
#----------------------------------------------------------#
# Proposal Layer
# 该部分代码用于将先验框转化成建议框
#----------------------------------------------------------#
def apply_box_deltas_graph(boxes, deltas):
# 计算先验框的中心和宽高
height = boxes[:, 2] - boxes[:, 0]
width = boxes[:, 3] - boxes[:, 1]
center_y = boxes[:, 0] + 0.5 * height
center_x = boxes[:, 1] + 0.5 * width
# 计算出调整后的先验框的中心和宽高
center_y += deltas[:, 0] * height
center_x += deltas[:, 1] * width
height *= tf.exp(deltas[:, 2])
width *= tf.exp(deltas[:, 3])
# 计算左上角和右下角的点的坐标
y1 = center_y - 0.5 * height
x1 = center_x - 0.5 * width
y2 = y1 + height
x2 = x1 + width
result = tf.stack([y1, x1, y2, x2], axis=1, name="apply_box_deltas_out")
return result
def clip_boxes_graph(boxes, window):
"""
boxes: [N, (y1, x1, y2, x2)]
window: [4] in the form y1, x1, y2, x2
"""
# Split
wy1, wx1, wy2, wx2 = tf.split(window, 4)
y1, x1, y2, x2 = tf.split(boxes, 4, axis=1)
# Clip
y1 = tf.maximum(tf.minimum(y1, wy2), wy1)
x1 = tf.maximum(tf.minimum(x1, wx2), wx1)
y2 = tf.maximum(tf.minimum(y2, wy2), wy1)
x2 = tf.maximum(tf.minimum(x2, wx2), wx1)
clipped = tf.concat([y1, x1, y2, x2], axis=1, name="clipped_boxes")
clipped.set_shape((clipped.shape[0], 4))
return clipped
class ProposalLayer(Layer):
def __init__(self, proposal_count, nms_threshold, config=None, **kwargs):
super(ProposalLayer, self).__init__(**kwargs)
self.config = config
self.proposal_count = proposal_count
self.nms_threshold = nms_threshold
# [rpn_class, rpn_bbox, anchors]
def call(self, inputs):
# 代表这个先验框内部是否有物体[batch, num_rois, 1]
scores = inputs[0][:, :, 1]
# 代表这个先验框的调整参数[batch, num_rois, 4]
deltas = inputs[1]
# [0.1 0.1 0.2 0.2],改变数量级
deltas = deltas * np.reshape(self.config.RPN_BBOX_STD_DEV, [1, 1, 4])
# Anchors
anchors = inputs[2]
# 筛选出得分前6000个的框
pre_nms_limit = tf.minimum(self.config.PRE_NMS_LIMIT, tf.shape(anchors)[1])
# 获得这些框的索引
ix = tf.nn.top_k(scores, pre_nms_limit, sorted=True,
name="top_anchors").indices
# 获得这些框的得分
scores = utils.batch_slice([scores, ix], lambda x, y: tf.gather(x, y),
self.config.IMAGES_PER_GPU)
# 获得这些框的调整参数
deltas = utils.batch_slice([deltas, ix], lambda x, y: tf.gather(x, y),
self.config.IMAGES_PER_GPU)
# 获得这些框对应的先验框
pre_nms_anchors = utils.batch_slice([anchors, ix], lambda a, x: tf.gather(a, x),
self.config.IMAGES_PER_GPU,
names=["pre_nms_anchors"])
# [batch, N, (y1, x1, y2, x2)]
# 对先验框进行解码
boxes = utils.batch_slice([pre_nms_anchors, deltas],
lambda x, y: apply_box_deltas_graph(x, y),
self.config.IMAGES_PER_GPU,
names=["refined_anchors"])
# [batch, N, (y1, x1, y2, x2)]
# 防止超出图片范围
window = np.array([0, 0, 1, 1], dtype=np.float32)
boxes = utils.batch_slice(boxes,
lambda x: clip_boxes_graph(x, window),
self.config.IMAGES_PER_GPU,
names=["refined_anchors_clipped"])
# 非极大抑制
def nms(boxes, scores):
indices = tf.image.non_max_suppression(
boxes, scores, self.proposal_count,
self.nms_threshold, name="rpn_non_max_suppression")
proposals = tf.gather(boxes, indices)
# 如果数量达不到设置的建议框数量的话
# 就padding
padding = tf.maximum(self.proposal_count - tf.shape(proposals)[0], 0)
proposals = tf.pad(proposals, [(0, padding), (0, 0)])
return proposals
proposals = utils.batch_slice([boxes, scores], nms,
self.config.IMAGES_PER_GPU)
return proposals
def compute_output_shape(self, input_shape):
return (None, self.proposal_count, 4)
5、对Proposal建议框加以利用(Roi Align)
让我们对建议框有一个整体的理解:
事实上建议框就是对图片哪一个区域有物体存在进行初步筛选。
实际上,Mask R-CNN到这里的操作是,通过主干特征提取网络,我们可以获得多个公用特征层,然后建议框会对这些公用特征层进行截取。
其实公用特征层里的每一个点相当于原图片上某个区域内部所有特征的浓缩。
建议框会对其对应的公用特征层进行截取,然后将截取的结果进行resize,在classifier模型里,截取后的内容会resize到7x7x256的大小。在mask模型里,截取后的内容会resize到14x14x256的大小。

在利用建议框对公用特征层进行截取的时候要注意,要找到建议框属于那个特征层,这个要从建议框的大小进行判断。
在classifier模型里,其会利用一次通道数为1024的7x7的卷积和一次通道数为1024的1x1的卷积对ROIAlign获得的7x7x256的区域进行卷积,两次通道数为1024卷积用于模拟两次1024的全连接,然后再分别全连接到num_classes和num_classes * 4上,分别代表这个建议框内的物体,以及这个建议框的调整参数。
在mask模型里,其首先会对resize后的局部特征层进行四次3x3的256通道的卷积,再进行一次反卷积,再进行一次通道数为num_classes的卷积,最终结果代表每一个像素点分的类。最终的shape为28x28xnum_classes,代表每个像素点的类别。
#------------------------------------#
# 五个不同大小的特征层会传入到
# RPN当中,获得建议框
#------------------------------------#
def rpn_graph(feature_map, anchors_per_location):
shared = Conv2D(512, (3, 3), padding='same', activation='relu',
name='rpn_conv_shared')(feature_map)
x = Conv2D(2 * anchors_per_location, (1, 1), padding='valid',
activation='linear', name='rpn_class_raw')(shared)
# batch_size,num_anchors,2
# 代表这个先验框对应的类
rpn_class_logits = Reshape([-1,2])(x)
rpn_probs = Activation(
"softmax", name="rpn_class_xxx")(rpn_class_logits)
x = Conv2D(anchors_per_location * 4, (1, 1), padding="valid",
activation='linear', name='rpn_bbox_pred')(shared)
# batch_size,num_anchors,4
# 这个先验框的调整参数
rpn_bbox = Reshape([-1,4])(x)
return [rpn_class_logits, rpn_probs, rpn_bbox]
#------------------------------------#
# 建立建议框网络模型
# RPN模型
#------------------------------------#
def build_rpn_model(anchors_per_location, depth):
input_feature_map = Input(shape=[None, None, depth],
name="input_rpn_feature_map")
outputs = rpn_graph(input_feature_map, anchors_per_location)
return Model([input_feature_map], outputs, name="rpn_model")
#------------------------------------#
# 建立classifier模型
# 这个模型的预测结果会调整建议框
# 获得最终的预测框
#------------------------------------#
def fpn_classifier_graph(rois, feature_maps, image_meta,
pool_size, num_classes, train_bn=True,
fc_layers_size=1024):
# ROI Pooling,利用建议框在特征层上进行截取
# Shape: [batch, num_rois, POOL_SIZE, POOL_SIZE, channels]
x = PyramidROIAlign([pool_size, pool_size],
name="roi_align_classifier")([rois, image_meta] + feature_maps)
# Shape: [batch, num_rois, 1, 1, fc_layers_size],相当于两次全连接
x = TimeDistributed(Conv2D(fc_layers_size, (pool_size, pool_size), padding="valid"),
name="mrcnn_class_conv1")(x)
x = TimeDistributed(BatchNormalization(), name='mrcnn_class_bn1')(x, training=train_bn)
x = Activation('relu')(x)
# Shape: [batch, num_rois, 1, 1, fc_layers_size]
x = TimeDistributed(Conv2D(fc_layers_size, (1, 1)),
name="mrcnn_class_conv2")(x)
x = TimeDistributed(BatchNormalization(), name='mrcnn_class_bn2')(x, training=train_bn)
x = Activation('relu')(x)
# Shape: [batch, num_rois, fc_layers_size]
shared = Lambda(lambda x: K.squeeze(K.squeeze(x, 3), 2),
name="pool_squeeze")(x)
# Classifier head
# 这个的预测结果代表这个先验框内部的物体的种类
mrcnn_class_logits = TimeDistributed(Dense(num_classes),
name='mrcnn_class_logits')(shared)
mrcnn_probs = TimeDistributed(Activation("softmax"),
name="mrcnn_class")(mrcnn_class_logits)
# BBox head
# 这个的预测结果会对先验框进行调整
# [batch, num_rois, NUM_CLASSES * (dy, dx, log(dh), log(dw))]
x = TimeDistributed(Dense(num_classes * 4, activation='linear'),
name='mrcnn_bbox_fc')(shared)
# Reshape to [batch, num_rois, NUM_CLASSES, (dy, dx, log(dh), log(dw))]
mrcnn_bbox = Reshape((-1, num_classes, 4), name="mrcnn_bbox")(x)
return mrcnn_class_logits, mrcnn_probs, mrcnn_bbox
def build_fpn_mask_graph(rois, feature_maps, image_meta,
pool_size, num_classes, train_bn=True):
# ROI Pooling,利用建议框在特征层上进行截取
# Shape: [batch, num_rois, MASK_POOL_SIZE, MASK_POOL_SIZE, channels]
x = PyramidROIAlign([pool_size, pool_size],
name="roi_align_mask")([rois, image_meta] + feature_maps)
# Shape: [batch, num_rois, MASK_POOL_SIZE, MASK_POOL_SIZE, channels]
x = TimeDistributed(Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv1")(x)
x = TimeDistributed(BatchNormalization(),
name='mrcnn_mask_bn1')(x, training=train_bn)
x = Activation('relu')(x)
# Shape: [batch, num_rois, MASK_POOL_SIZE, MASK_POOL_SIZE, channels]
x = TimeDistributed(Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv2")(x)
x = TimeDistributed(BatchNormalization(),
name='mrcnn_mask_bn2')(x, training=train_bn)
x = Activation('relu')(x)
# Shape: [batch, num_rois, MASK_POOL_SIZE, MASK_POOL_SIZE, channels]
x = TimeDistributed(Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv3")(x)
x = TimeDistributed(BatchNormalization(),
name='mrcnn_mask_bn3')(x, training=train_bn)
x = Activation('relu')(x)
# Shape: [batch, num_rois, MASK_POOL_SIZE, MASK_POOL_SIZE, channels]
x = TimeDistributed(Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv4")(x)
x = TimeDistributed(BatchNormalization(),
name='mrcnn_mask_bn4')(x, training=train_bn)
x = Activation('relu')(x)
# Shape: [batch, num_rois, 2xMASK_POOL_SIZE, 2xMASK_POOL_SIZE, channels]
x = TimeDistributed(Conv2DTranspose(256, (2, 2), strides=2, activation="relu"),
name="mrcnn_mask_deconv")(x)
# 反卷积后再次进行一个1x1卷积调整通道,使其最终数量为numclasses,代表分的类
x = TimeDistributed(Conv2D(num_classes, (1, 1), strides=1, activation="sigmoid"),
name="mrcnn_mask")(x)
return x
#----------------------------------------------------------#
# ROIAlign Layer
# 利用建议框在特征层上截取内容
#----------------------------------------------------------#
def log2_graph(x):
return tf.log(x) / tf.log(2.0)
def parse_image_meta_graph(meta):
"""
将meta里面的参数进行分割
"""
image_id = meta[:, 0]
original_image_shape = meta[:, 1:4]
image_shape = meta[:, 4:7]
window = meta[:, 7:11] # (y1, x1, y2, x2) window of image in in pixels
scale = meta[:, 11]
active_class_ids = meta[:, 12:]
return {
"image_id": image_id,
"original_image_shape": original_image_shape,
"image_shape": image_shape,
"window": window,
"scale": scale,
"active_class_ids": active_class_ids,
}
class PyramidROIAlign(Layer):
def __init__(self, pool_shape, **kwargs):
super(PyramidROIAlign, self).__init__(**kwargs)
self.pool_shape = tuple(pool_shape)
def call(self, inputs):
# 建议框的位置
boxes = inputs[0]
# image_meta包含了一些必要的图片信息
image_meta = inputs[1]
# 取出所有的特征层[batch, height, width, channels]
feature_maps = inputs[2:]
y1, x1, y2, x2 = tf.split(boxes, 4, axis=2)
h = y2 - y1
w = x2 - x1
# 获得输入进来的图像的大小
image_shape = parse_image_meta_graph(image_meta)['image_shape'][0]
# 通过建议框的大小找到这个建议框属于哪个特征层
image_area = tf.cast(image_shape[0] * image_shape[1], tf.float32)
roi_level = log2_graph(tf.sqrt(h * w) / (224.0 / tf.sqrt(image_area)))
roi_level = tf.minimum(5, tf.maximum(
2, 4 + tf.cast(tf.round(roi_level), tf.int32)))
# batch_size, box_num
roi_level = tf.squeeze(roi_level, 2)
# Loop through levels and apply ROI pooling to each. P2 to P5.
pooled = []
box_to_level = []
# 分别在P2-P5中进行截取
for i, level in enumerate(range(2, 6)):
# 找到每个特征层对应box
ix = tf.where(tf.equal(roi_level, level))
level_boxes = tf.gather_nd(boxes, ix)
box_to_level.append(ix)
# 获得这些box所属的图片
box_indices = tf.cast(ix[:, 0], tf.int32)
# 停止梯度下降
level_boxes = tf.stop_gradient(level_boxes)
box_indices = tf.stop_gradient(box_indices)
# Result: [batch * num_boxes, pool_height, pool_width, channels]
pooled.append(tf.image.crop_and_resize(
feature_maps[i], level_boxes, box_indices, self.pool_shape,
method="bilinear"))
pooled = tf.concat(pooled, axis=0)
# 将顺序和所属的图片进行堆叠
box_to_level = tf.concat(box_to_level, axis=0)
box_range = tf.expand_dims(tf.range(tf.shape(box_to_level)[0]), 1)
box_to_level = tf.concat([tf.cast(box_to_level, tf.int32), box_range],
axis=1)
# box_to_level[:, 0]表示第几张图
# box_to_level[:, 1]表示第几张图里的第几个框
sorting_tensor = box_to_level[:, 0] * 100000 + box_to_level[:, 1]
# 进行排序,将同一张图里的某一些聚集在一起
ix = tf.nn.top_k(sorting_tensor, k=tf.shape(
box_to_level)[0]).indices[::-1]
# 按顺序获得图片的索引
ix = tf.gather(box_to_level[:, 2], ix)
pooled = tf.gather(pooled, ix)
# 重新reshape为原来的格式
# 也就是
# Shape: [batch, num_rois, POOL_SIZE, POOL_SIZE, channels]
shape = tf.concat([tf.shape(boxes)[:2], tf.shape(pooled)[1:]], axis=0)
pooled = tf.reshape(pooled, shape)
return pooled
def compute_output_shape(self, input_shape):
return input_shape[0][:2] + self.pool_shape + (input_shape[2][-1], )
6、预测框的解码
在第四部分获得的建议框也代表了图片上的某一些区域,它在后面的在classifier模型里也起到了先验框的作用。
也就是classifier模型的预测结果,代表了建议框内部物体的种类和调整参数。
建议框调整后的结果,也就是最终的预测结果,这个预测结果就可以在图片上进行绘制了。
预测框的解码过程包括了如下几个步骤:
1、取出不属于背景,并且得分大于config.DETECTION_MIN_CONFIDENCE的建议框。
2、然后利用建议框和classifier模型的预测结果进行解码,获得最终预测框的位置。
3、利用得分和最终预测框的位置进行非极大抑制,防止重复检测。
建议框解码过程的代码如下:
#----------------------------------------------------------#
# Detection Layer
#----------------------------------------------------------#
def refine_detections_graph(rois, probs, deltas, window, config):
"""细化分类建议并过滤重叠部分并返回最终结果探测。
Inputs:
rois: [N, (y1, x1, y2, x2)] in normalized coordinates
probs: [N, num_classes]. Class probabilities.
deltas: [N, num_classes, (dy, dx, log(dh), log(dw))]. Class-specific
bounding box deltas.
window: (y1, x1, y2, x2) in normalized coordinates. The part of the image
that contains the image excluding the padding.
Returns detections shaped: [num_detections, (y1, x1, y2, x2, class_id, score)] where
coordinates are normalized.
"""
# 找到得分最高的类
class_ids = tf.argmax(probs, axis=1, output_type=tf.int32)
# 序号+类
indices = tf.stack([tf.range(probs.shape[0]), class_ids], axis=1)
# 取出成绩
class_scores = tf.gather_nd(probs, indices)
# 还有框的调整参数
deltas_specific = tf.gather_nd(deltas, indices)
# 进行解码
# Shape: [boxes, (y1, x1, y2, x2)] in normalized coordinates
refined_rois = apply_box_deltas_graph(
rois, deltas_specific * config.BBOX_STD_DEV)
# 防止超出0-1
refined_rois = clip_boxes_graph(refined_rois, window)
# 去除背景
keep = tf.where(class_ids > 0)[:, 0]
# 去除背景和得分小的区域
if config.DETECTION_MIN_CONFIDENCE:
conf_keep = tf.where(class_scores >= config.DETECTION_MIN_CONFIDENCE)[:, 0]
keep = tf.sets.set_intersection(tf.expand_dims(keep, 0),
tf.expand_dims(conf_keep, 0))
keep = tf.sparse_tensor_to_dense(keep)[0]
# 获得除去背景并且得分较高的框还有种类与得分
# 1. Prepare variables
pre_nms_class_ids = tf.gather(class_ids, keep)
pre_nms_scores = tf.gather(class_scores, keep)
pre_nms_rois = tf.gather(refined_rois, keep)
unique_pre_nms_class_ids = tf.unique(pre_nms_class_ids)[0]
def nms_keep_map(class_id):
ixs = tf.where(tf.equal(pre_nms_class_ids, class_id))[:, 0]
class_keep = tf.image.non_max_suppression(
tf.gather(pre_nms_rois, ixs),
tf.gather(pre_nms_scores, ixs),
max_output_size=config.DETECTION_MAX_INSTANCES,
iou_threshold=config.DETECTION_NMS_THRESHOLD)
class_keep = tf.gather(keep, tf.gather(ixs, class_keep))
gap = config.DETECTION_MAX_INSTANCES - tf.shape(class_keep)[0]
class_keep = tf.pad(class_keep, [(0, gap)],
mode='CONSTANT', constant_values=-1)
class_keep.set_shape([config.DETECTION_MAX_INSTANCES])
return class_keep
# 2. 进行非极大抑制
nms_keep = tf.map_fn(nms_keep_map, unique_pre_nms_class_ids,
dtype=tf.int64)
# 3. 找到符合要求的需要被保留的建议框
nms_keep = tf.reshape(nms_keep, [-1])
nms_keep = tf.gather(nms_keep, tf.where(nms_keep > -1)[:, 0])
# 4. Compute intersection between keep and nms_keep
keep = tf.sets.set_intersection(tf.expand_dims(keep, 0),
tf.expand_dims(nms_keep, 0))
keep = tf.sparse_tensor_to_dense(keep)[0]
# 寻找得分最高的num_keep个框
roi_count = config.DETECTION_MAX_INSTANCES
class_scores_keep = tf.gather(class_scores, keep)
num_keep = tf.minimum(tf.shape(class_scores_keep)[0], roi_count)
top_ids = tf.nn.top_k(class_scores_keep, k=num_keep, sorted=True)[1]
keep = tf.gather(keep, top_ids)
# Arrange output as [N, (y1, x1, y2, x2, class_id, score)]
detections = tf.concat([
tf.gather(refined_rois, keep),
tf.to_float(tf.gather(class_ids, keep))[..., tf.newaxis],
tf.gather(class_scores, keep)[..., tf.newaxis]
], axis=1)
# 如果达不到数量的话就padding
gap = config.DETECTION_MAX_INSTANCES - tf.shape(detections)[0]
detections = tf.pad(detections, [(0, gap), (0, 0)], "CONSTANT")
return detections
def norm_boxes_graph(boxes, shape):
h, w = tf.split(tf.cast(shape, tf.float32), 2)
scale = tf.concat([h, w, h, w], axis=-1) - tf.constant(1.0)
shift = tf.constant([0., 0., 1., 1.])
return tf.divide(boxes - shift, scale)
class DetectionLayer(Layer):
def __init__(self, config=None, **kwargs):
super(DetectionLayer, self).__init__(**kwargs)
self.config = config
def call(self, inputs):
rois = inputs[0]
mrcnn_class = inputs[1]
mrcnn_bbox = inputs[2]
image_meta = inputs[3]
# 找到window的小数形式
m = parse_image_meta_graph(image_meta)
image_shape = m['image_shape'][0]
window = norm_boxes_graph(m['window'], image_shape[:2])
# Run detection refinement graph on each item in the batch
detections_batch = utils.batch_slice(
[rois, mrcnn_class, mrcnn_bbox, window],
lambda x, y, w, z: refine_detections_graph(x, y, w, z, self.config),
self.config.IMAGES_PER_GPU)
# Reshape output
# [batch, num_detections, (y1, x1, y2, x2, class_id, class_score)] in
# normalized coordinates
return tf.reshape(
detections_batch,
[self.config.BATCH_SIZE, self.config.DETECTION_MAX_INSTANCES, 6])
def compute_output_shape(self, input_shape):
return (None, self.config.DETECTION_MAX_INSTANCES, 6)
7、mask语义分割信息的获取
在第六步中,我们获得了最终的预测框,这个预测框相比于之前获得的建议框更加准确,因此我们把这个预测框作为mask模型的区域截取部分,利用这个预测框对mask模型中用到的公用特征层进行截取。
截取后,利用mask模型再对像素点进行分类,获得语义分割结果。
二、训练部分
Faster-RCNN训练所用的损失函数由几个部分组成,一部分是建议框网络的损失函数,一部分是classifier网络的损失函数,另一部分是mask网络的损失函数。
1、建议框网络的训练
公用特征层如果要获得建议框的预测结果,需要再进行一次3x3的卷积后,进行一个anchors_per_location x 1通道的1x1卷积,还有一个anchors_per_location x 4通道的1x1卷积。
在Mask R-CNN中,anchors_per_location 也就是先验框的数量默认情况下是3,所以两个1x1卷积的结果实际上也就是:
anchors_per_location x 4的卷积 用于预测 有效特征层上 每一个网格点上 每一个先验框的变化情况。**
anchors_per_location x 1的卷积 用于预测 有效特征层上 每一个网格点上 每一个建议框内部是否包含了物体。
也就是说,我们直接利用Mask R-CNN建议框网络预测到的结果,并不是建议框在图片上的真实位置,需要解码才能得到真实位置。
而在训练的时候,我们需要计算loss函数,这个loss函数是相对于Mask R-CNN建议框网络的预测结果的。我们需要把图片输入到当前的Mask R-CNN建议框的网络中,得到建议框的结果;同时还需要进行编码,这个编码是把真实框的位置信息格式转化为Mask R-CNN建议框预测结果的格式信息。
也就是,我们需要找到 每一张用于训练的图片的每一个真实框对应的先验框,并求出如果想要得到这样一个真实框,我们的建议框预测结果应该是怎么样的。
从建议框预测结果获得真实框的过程被称作解码,而从真实框获得建议框预测结果的过程就是编码的过程。
因此我们只需要将解码过程逆过来就是编码过程了。
实现代码如下:
def build_rpn_targets(image_shape, anchors, gt_class_ids, gt_boxes, config):
# 1代表正样本
# -1代表负样本
# 0代表忽略
rpn_match = np.zeros([anchors.shape[0]], dtype=np.int32)
# 创建该部分内容利用先验框和真实框进行编码
rpn_bbox = np.zeros((config.RPN_TRAIN_ANCHORS_PER_IMAGE, 4))
'''
iscrowd=0的时候,表示这是一个单独的物体,轮廓用Polygon(多边形的点)表示,
iscrowd=1的时候表示两个没有分开的物体,轮廓用RLE编码表示,比如说一张图片里面有三个人,
一个人单独站一边,另外两个搂在一起(标注的时候距离太近分不开了),这个时候,
单独的那个人的注释里面的iscrowing=0,segmentation用Polygon表示,
而另外两个用放在同一个anatation的数组里面用一个segmention的RLE编码形式表示
'''
crowd_ix = np.where(gt_class_ids < 0)[0]
if crowd_ix.shape[0] > 0:
non_crowd_ix = np.where(gt_class_ids > 0)[0]
crowd_boxes = gt_boxes[crowd_ix]
gt_class_ids = gt_class_ids[non_crowd_ix]
gt_boxes = gt_boxes[non_crowd_ix]
crowd_overlaps = utils.compute_overlaps(anchors, crowd_boxes)
crowd_iou_max = np.amax(crowd_overlaps, axis=1)
no_crowd_bool = (crowd_iou_max < 0.001)
else:
no_crowd_bool = np.ones([anchors.shape[0]], dtype=bool)
# 计算先验框和真实框的重合程度 [num_anchors, num_gt_boxes]
overlaps = utils.compute_overlaps(anchors, gt_boxes)
# 1. 重合程度小于0.3则代表为负样本
anchor_iou_argmax = np.argmax(overlaps, axis=1)
anchor_iou_max = overlaps[np.arange(overlaps.shape[0]), anchor_iou_argmax]
rpn_match[(anchor_iou_max < 0.3) & (no_crowd_bool)] = -1
# 2. 每个真实框重合度最大的先验框是正样本
gt_iou_argmax = np.argwhere(overlaps == np.max(overlaps, axis=0))[:,0]
rpn_match[gt_iou_argmax] = 1
# 3. 重合度大于0.7则代表为正样本
rpn_match[anchor_iou_max >= 0.7] = 1
# 正负样本平衡
# 找到正样本的索引
ids = np.where(rpn_match == 1)[0]
# 如果大于(config.RPN_TRAIN_ANCHORS_PER_IMAGE // 2)则删掉一些
extra = len(ids) - (config.RPN_TRAIN_ANCHORS_PER_IMAGE // 2)
if extra > 0:
ids = np.random.choice(ids, extra, replace=False)
rpn_match[ids] = 0
# 找到负样本的索引
ids = np.where(rpn_match == -1)[0]
# 使得总数为config.RPN_TRAIN_ANCHORS_PER_IMAGE
extra = len(ids) - (config.RPN_TRAIN_ANCHORS_PER_IMAGE -
np.sum(rpn_match == 1))
if extra > 0:
# Rest the extra ones to neutral
ids = np.random.choice(ids, extra, replace=False)
rpn_match[ids] = 0
# 找到内部真实存在物体的先验框,进行编码
ids = np.where(rpn_match == 1)[0]
ix = 0
for i, a in zip(ids, anchors[ids]):
gt = gt_boxes[anchor_iou_argmax[i]]
# 计算真实框的中心,高宽
gt_h = gt[2] - gt[0]
gt_w = gt[3] - gt[1]
gt_center_y = gt[0] + 0.5 * gt_h
gt_center_x = gt[1] + 0.5 * gt_w
# 计算先验框中心,高宽
a_h = a[2] - a[0]
a_w = a[3] - a[1]
a_center_y = a[0] + 0.5 * a_h
a_center_x = a[1] + 0.5 * a_w
# 编码运算
rpn_bbox[ix] = [
(gt_center_y - a_center_y) / a_h,
(gt_center_x - a_center_x) / a_w,
np.log(gt_h / a_h),
np.log(gt_w / a_w),
]
# 改变数量级
rpn_bbox[ix] /= config.RPN_BBOX_STD_DEV
ix += 1
return rpn_match, rpn_bbox
利用上述代码我们可以获得,真实框对应的所有的iou较大先验框,并计算了真实框对应的所有iou较大的先验框应该有的预测结果。
Mask R-CNN会忽略一些重合度相对较高但是不是非常高的先验框,一般将重合度在0.3-0.7之间的先验框进行忽略。
利用建议框网络应该有的预测结果和实际上的预测结果进行对比就可以获得建议框网络的loss。
2、Classiffier模型的训练
上一部分提供了RPN网络的loss,在Mask R-CNN的模型中,我们还需要对建议框进行调整获得最终的预测框。在classiffier模型中,建议框相当于是先验框。
因此,我们需要计算所有建议框和真实框的重合程度,并进行筛选,如果某个真实框和建议框的重合程度大于0.5则认为该建议框为正样本,如果重合程度小于0.5则认为该建议框为负样本
因此我们可以对真实框进行编码,这个编码是相对于建议框的,也就是,当我们存在这些建议框的时候,我们的Classiffier模型需要有什么样的预测结果才能将这些建议框调整成真实框。
实现代码如下:
#----------------------------------------------------------#
# Detection Target Layer
# 该部分代码会输入建议框
# 判断建议框和真实框的重合情况
# 筛选出内部包含物体的建议框
# 利用建议框和真实框编码
# 调整mask的格式使得其和预测格式相同
#----------------------------------------------------------#
def overlaps_graph(boxes1, boxes2):
"""
用于计算boxes1和boxes2的重合程度
boxes1, boxes2: [N, (y1, x1, y2, x2)].
返回 [len(boxes1), len(boxes2)]
"""
b1 = tf.reshape(tf.tile(tf.expand_dims(boxes1, 1),
[1, 1, tf.shape(boxes2)[0]]), [-1, 4])
b2 = tf.tile(boxes2, [tf.shape(boxes1)[0], 1])
b1_y1, b1_x1, b1_y2, b1_x2 = tf.split(b1, 4, axis=1)
b2_y1, b2_x1, b2_y2, b2_x2 = tf.split(b2, 4, axis=1)
y1 = tf.maximum(b1_y1, b2_y1)
x1 = tf.maximum(b1_x1, b2_x1)
y2 = tf.minimum(b1_y2, b2_y2)
x2 = tf.minimum(b1_x2, b2_x2)
intersection = tf.maximum(x2 - x1, 0) * tf.maximum(y2 - y1, 0)
b1_area = (b1_y2 - b1_y1) * (b1_x2 - b1_x1)
b2_area = (b2_y2 - b2_y1) * (b2_x2 - b2_x1)
union = b1_area + b2_area - intersection
iou = intersection / union
overlaps = tf.reshape(iou, [tf.shape(boxes1)[0], tf.shape(boxes2)[0]])
return overlaps
def detection_targets_graph(proposals, gt_class_ids, gt_boxes, gt_masks, config):
asserts = [
tf.Assert(tf.greater(tf.shape(proposals)[0], 0), [proposals],
name="roi_assertion"),
]
with tf.control_dependencies(asserts):
proposals = tf.identity(proposals)
# 移除之前获得的padding的部分
proposals, _ = trim_zeros_graph(proposals, name="trim_proposals")
gt_boxes, non_zeros = trim_zeros_graph(gt_boxes, name="trim_gt_boxes")
gt_class_ids = tf.boolean_mask(gt_class_ids, non_zeros,
name="trim_gt_class_ids")
gt_masks = tf.gather(gt_masks, tf.where(non_zeros)[:, 0], axis=2,
name="trim_gt_masks")
# Handle COCO crowds
# A crowd box in COCO is a bounding box around several instances. Exclude
# them from training. A crowd box is given a negative class ID.
crowd_ix = tf.where(gt_class_ids < 0)[:, 0]
non_crowd_ix = tf.where(gt_class_ids > 0)[:, 0]
crowd_boxes = tf.gather(gt_boxes, crowd_ix)
gt_class_ids = tf.gather(gt_class_ids, non_crowd_ix)
gt_boxes = tf.gather(gt_boxes, non_crowd_ix)
gt_masks = tf.gather(gt_masks, non_crowd_ix, axis=2)
# 计算建议框和所有真实框的重合程度 [proposals, gt_boxes]
overlaps = overlaps_graph(proposals, gt_boxes)
# 计算和 crowd boxes 的重合程度 [proposals, crowd_boxes]
crowd_overlaps = overlaps_graph(proposals, crowd_boxes)
crowd_iou_max = tf.reduce_max(crowd_overlaps, axis=1)
no_crowd_bool = (crowd_iou_max < 0.001)
# Determine positive and negative ROIs
roi_iou_max = tf.reduce_max(overlaps, axis=1)
# 1. 正样本建议框和真实框的重合程度大于0.5
positive_roi_bool = (roi_iou_max >= 0.5)
positive_indices = tf.where(positive_roi_bool)[:, 0]
# 2. 负样本建议框和真实框的重合程度小于0.5,Skip crowds.
negative_indices = tf.where(tf.logical_and(roi_iou_max < 0.5, no_crowd_bool))[:, 0]
# Subsample ROIs. Aim for 33% positive
# 进行正负样本的平衡
# 取出最大33%的正样本
positive_count = int(config.TRAIN_ROIS_PER_IMAGE *
config.ROI_POSITIVE_RATIO)
positive_indices = tf.random_shuffle(positive_indices)[:positive_count]
positive_count = tf.shape(positive_indices)[0]
# 保持正负样本比例
r = 1.0 / config.ROI_POSITIVE_RATIO
negative_count = tf.cast(r * tf.cast(positive_count, tf.float32), tf.int32) - positive_count
negative_indices = tf.random_shuffle(negative_indices)[:negative_count]
# 获得正样本和负样本
positive_rois = tf.gather(proposals, positive_indices)
negative_rois = tf.gather(proposals, negative_indices)
# 获取建议框和真实框重合程度
positive_overlaps = tf.gather(overlaps, positive_indices)
# 判断是否有真实框
roi_gt_box_assignment = tf.cond(
tf.greater(tf.shape(positive_overlaps)[1], 0),
true_fn = lambda: tf.argmax(positive_overlaps, axis=1),
false_fn = lambda: tf.cast(tf.constant([]),tf.int64)
)
# 找到每一个建议框对应的真实框和种类
roi_gt_boxes = tf.gather(gt_boxes, roi_gt_box_assignment)
roi_gt_class_ids = tf.gather(gt_class_ids, roi_gt_box_assignment)
# 解码获得网络应该有得预测结果
deltas = utils.box_refinement_graph(positive_rois, roi_gt_boxes)
deltas /= config.BBOX_STD_DEV
# 切换mask的形式[N, height, width, 1]
transposed_masks = tf.expand_dims(tf.transpose(gt_masks, [2, 0, 1]), -1)
# 取出对应的层
roi_masks = tf.gather(transposed_masks, roi_gt_box_assignment)
# Compute mask targets
boxes = positive_rois
if config.USE_MINI_MASK:
# Transform ROI coordinates from normalized image space
# to normalized mini-mask space.
y1, x1, y2, x2 = tf.split(positive_rois, 4, axis=1)
gt_y1, gt_x1, gt_y2, gt_x2 = tf.split(roi_gt_boxes, 4, axis=1)
gt_h = gt_y2 - gt_y1
gt_w = gt_x2 - gt_x1
y1 = (y1 - gt_y1) / gt_h
x1 = (x1 - gt_x1) / gt_w
y2 = (y2 - gt_y1) / gt_h
x2 = (x2 - gt_x1) / gt_w
boxes = tf.concat([y1, x1, y2, x2], 1)
box_ids = tf.range(0, tf.shape(roi_masks)[0])
masks = tf.image.crop_and_resize(tf.cast(roi_masks, tf.float32), boxes,
box_ids,
config.MASK_SHAPE)
# Remove the extra dimension from masks.
masks = tf.squeeze(masks, axis=3)
# 防止resize后的结果不是1或者0
masks = tf.round(masks)
# 一般传入config.TRAIN_ROIS_PER_IMAGE个建议框进行训练,
# 如果数量不够则padding
rois = tf.concat([positive_rois, negative_rois], axis=0)
N = tf.shape(negative_rois)[0]
P = tf.maximum(config.TRAIN_ROIS_PER_IMAGE - tf.shape(rois)[0], 0)
rois = tf.pad(rois, [(0, P), (0, 0)])
roi_gt_boxes = tf.pad(roi_gt_boxes, [(0, N + P), (0, 0)])
roi_gt_class_ids = tf.pad(roi_gt_class_ids, [(0, N + P)])
deltas = tf.pad(deltas, [(0, N + P), (0, 0)])
masks = tf.pad(masks, [[0, N + P], (0, 0), (0, 0)])
return rois, roi_gt_class_ids, deltas, masks
def trim_zeros_graph(boxes, name='trim_zeros'):
"""
如果前一步没有满POST_NMS_ROIS_TRAINING个建议框,会有padding
要去掉padding
"""
non_zeros = tf.cast(tf.reduce_sum(tf.abs(boxes), axis=1), tf.bool)
boxes = tf.boolean_mask(boxes, non_zeros, name=name)
return boxes, non_zeros
class DetectionTargetLayer(Layer):
"""找到建议框的ground_truth
Inputs:
proposals: [batch, N, (y1, x1, y2, x2)]建议框
gt_class_ids: [batch, MAX_GT_INSTANCES]每个真实框对应的类
gt_boxes: [batch, MAX_GT_INSTANCES, (y1, x1, y2, x2)]真实框的位置
gt_masks: [batch, height, width, MAX_GT_INSTANCES]真实框的语义分割情况
Returns:
rois: [batch, TRAIN_ROIS_PER_IMAGE, (y1, x1, y2, x2)]内部真实存在目标的建议框
target_class_ids: [batch, TRAIN_ROIS_PER_IMAGE]每个建议框对应的类
target_deltas: [batch, TRAIN_ROIS_PER_IMAGE, (dy, dx, log(dh), log(dw)]每个建议框应该有的调整参数
target_mask: [batch, TRAIN_ROIS_PER_IMAGE, height, width]每个建议框语义分割情况
"""
def __init__(self, config, **kwargs):
super(DetectionTargetLayer, self).__init__(**kwargs)
self.config = config
def call(self, inputs):
proposals = inputs[0]
gt_class_ids = inputs[1]
gt_boxes = inputs[2]
gt_masks = inputs[3]
# 对真实框进行编码
names = ["rois", "target_class_ids", "target_bbox", "target_mask"]
outputs = utils.batch_slice(
[proposals, gt_class_ids, gt_boxes, gt_masks],
lambda w, x, y, z: detection_targets_graph(
w, x, y, z, self.config),
self.config.IMAGES_PER_GPU, names=names)
return outputs
def compute_output_shape(self, input_shape):
return [
(None, self.config.TRAIN_ROIS_PER_IMAGE, 4), # rois
(None, self.config.TRAIN_ROIS_PER_IMAGE), # class_ids
(None, self.config.TRAIN_ROIS_PER_IMAGE, 4), # deltas
(None, self.config.TRAIN_ROIS_PER_IMAGE, self.config.MASK_SHAPE[0],
self.config.MASK_SHAPE[1]) # masks
]
def compute_mask(self, inputs, mask=None):
return [None, None, None, None]
3、mask模型的训练
mask模型在训练的时候要注意,当我们利用建议框网络在mask模型需要用到的公用特征层进行截取的时候,截取的情况和真实框截下来的不一样,因此还需要算出来我们用于截取的框相对于真实框的位置,获得正确的语义分割信息。
使用代码如下,中间一大部分用于计算真实框相对于建议框的位置。计算完成后利用这个相对位置可以对语义分割信息进行截取,获得正确的语义信息
# Compute mask targets
boxes = positive_rois
if config.USE_MINI_MASK:
# Transform ROI coordinates from normalized image space
# to normalized mini-mask space.
y1, x1, y2, x2 = tf.split(positive_rois, 4, axis=1)
gt_y1, gt_x1, gt_y2, gt_x2 = tf.split(roi_gt_boxes, 4, axis=1)
gt_h = gt_y2 - gt_y1
gt_w = gt_x2 - gt_x1
y1 = (y1 - gt_y1) / gt_h
x1 = (x1 - gt_x1) / gt_w
y2 = (y2 - gt_y1) / gt_h
x2 = (x2 - gt_x1) / gt_w
boxes = tf.concat([y1, x1, y2, x2], 1)
box_ids = tf.range(0, tf.shape(roi_masks)[0])
masks = tf.image.crop_and_resize(tf.cast(roi_masks, tf.float32), boxes,
box_ids,
config.MASK_SHAPE)
这样的话,就可以通过上述获得的mask和模型的预测结果进行结合训练模型了。
训练自己的Mask-RCNN模型
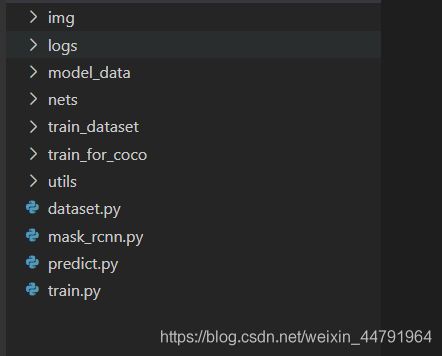
Mask-RCNN整体的文件夹构架如下:
1、数据集准备
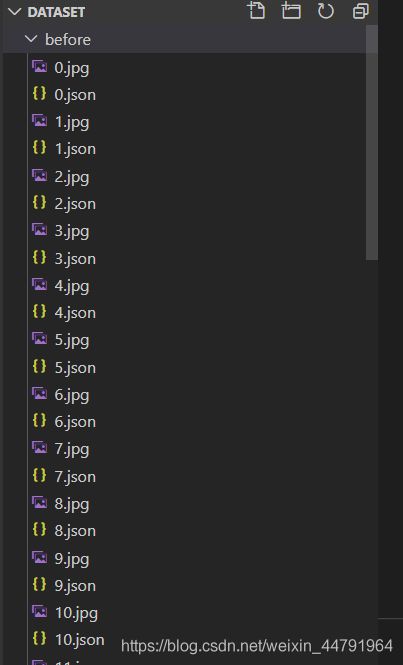
本文适合训练自己的数据集的同学使用。首先利用labelme标注数据。

将其放在before文件夹里:
本文写了一个labelme到数据集的转换代码,在before外部运行即可。
运行后会生成train_dataset,这个train_dataset放到Mask-RCNN模型的根目录即可
生成代码如下:
import argparse
import json
import os
import os.path as osp
import warnings
import PIL.Image
import yaml
from labelme import utils
import base64
def main():
count = os.listdir("./before/")
index = 0
for i in range(0, len(count)):
path = os.path.join("./before", count[i])
if os.path.isfile(path) and path.endswith('json'):
data = json.load(open(path))
if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(path), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
# label_values must be dense
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
assert label_values == list(range(len(label_values)))
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
captions = ['{}: {}'.format(lv, ln)
for ln, lv in label_name_to_value.items()]
lbl_viz = utils.draw_label(lbl, img, captions)
if not os.path.exists("train_dataset"):
os.mkdir("train_dataset")
label_path = "train_dataset/mask"
if not os.path.exists(label_path):
os.mkdir(label_path)
img_path = "train_dataset/imgs"
if not os.path.exists(img_path):
os.mkdir(img_path)
yaml_path = "train_dataset/yaml"
if not os.path.exists(yaml_path):
os.mkdir(yaml_path)
label_viz_path = "train_dataset/label_viz"
if not os.path.exists(label_viz_path):
os.mkdir(label_viz_path)
PIL.Image.fromarray(img).save(osp.join(img_path, str(index)+'.jpg'))
utils.lblsave(osp.join(label_path, str(index)+'.png'), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(label_viz_path, str(index)+'.png'))
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=label_names)
with open(osp.join(yaml_path, str(index)+'.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
index = index+1
print('Saved : %s' % str(index))
if __name__ == '__main__':
main()
2、参数修改
在数据集生成好之后,根据要求修改train.py文件夹下的参数即可训练。Num_classes的数量是分类的总个数+1。
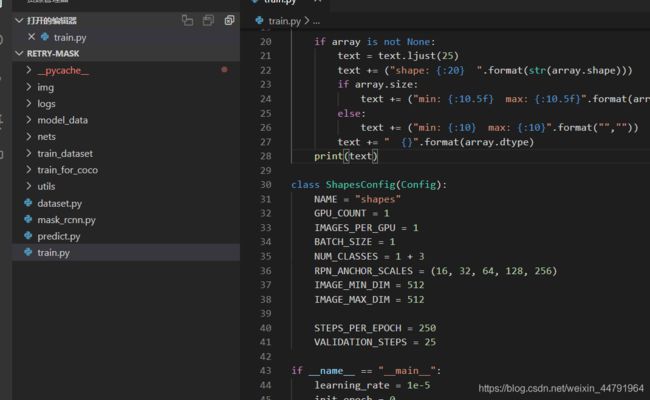
dataset.py内修改自己要分的类,分别是load_shapes函数和load_mask函数内和类有关的内容,即将原有的circle、square等修改成自己要分的类。
在train文件夹下面修改ShapesConfig(Config)的内容,NUM_CLASS等于自己要分的类的数量+1。
IMAGE_MAX_DIM、IMAGE_MIN_DIM、BATCH_SIZE和IMAGES_PER_GPU根据自己的显存情况修改。RPN_ANCHOR_SCALES根据IMAGE_MAX_DIM和IMAGE_MIN_DIM进行修改。
STEPS_PER_EPOCH代表每个世代训练多少次。
3、模型训练
全部修改完成后就可以运行train.py训练了。
以上就是Keras搭建Mask R-CNN实例分割平台实现源码的详细内容,更多关于Keras搭建Mask R-CNN实例分割的资料请关注脚本之家其它相关文章!