什么是Protocol Buffers?
Protocol Buffers(协议缓冲区)是一种支持多语言、跨平台、可扩展的机制,用于序列化结构数据格式。相比于XML, JSON, YAML, CSV等一些序列化工具,Protocol Buffers更简单、更快、更轻量。
我们只需按照我们的意愿定义一次数据的结构(message),就可以使用特殊生成的代码(可以通过命令行,可以通过Maven插件),轻松地在各种数据流和各种语言之间写入和读取我们的结构化数据。
Protocol Buffers解决了什么问题?
Protocol Buffers为大小高达几M字节的结构化数据包提供序列化格式。
通过将 结构化的数据 进行 串行化(序列化),从而实现 数据存储 / RPC 数据交换的功能。
Protocol Buffers可以使用新信息进行扩展,而不会使现有数据无效或要求更新代码。
序列化: 将 数据结构或对象 转换成 二进制串 的过程
反序列化:将在序列化过程中所生成的二进制串 转换成 数据结构或者对象 的过程
Protocol Buffers是 Google 最常用的数据格式。通过.proto后缀的文件,来编写Protocol Buffers消息以及服务。
下面显示了一个示例消息:
message Person {
optional string name = 1;
optional int32 id = 2;
optional string email = 3;
}proto 编译器在 .proto 文件构建时被调用,以生成各种编程语言的代码来操作相应的Protocol Buffers。
每个生成的类都包含每个字段的简单访问器和方法,用于将整个结构序列化和解析为原始字节。下面展示了一个使用这些生成方法的示例:
Person john = Person.newBuilder()
.setId(1234)
.setName("John Doe")
.setEmail("[email protected]")
.build();
output = new FileOutputStream(args[0]);
john.writeTo(output);Protocol Buffers的优点
Protocol Buffers非常适合任何需要以与语言无关、与平台无关、可扩展的方式进行序列化结构化数据的情况。它们通常用于定义通信协议(与gRPC一起)和数据存储。
跨语言的兼容性
目前Google官方支持C++、C#、Java、Kotlin、PHP、Python、Ruby等,其他的可以在github上找到,支持插件的方式。
跨项目支持
通过在.proto文件中自定义message,我们可以跨项目使用Protocol Buffers,同时可以将文件放置在项目的代码库之外,比如可以和Java文件夹同目录。
如果我们期望定义将在直接团队之外广泛使用的消息类型或枚举时,我们可以将它们放在自己的文件中,而不依赖它们。
支持不更新代码的情况下更新Proto定义
Protocol Buffers不适用的场景
Protocol Buffers 倾向于将消息一次性的加载内存中,并且不会比对象图大。当我们数据达到数M字节的时候,需要考虑其他方案,因为在处理较大的数据时,由于序列化副本的原因,最终我们会得到数据的多个副本,会导致内存使用量激增,因为建议最好不要超过1M。
对象图(Object graph)可以简单理解为对象之间存在引用关系而组成的关系网。在Java中,垃圾收集器基本上使用对象图来确定内存中哪些实例仍然链接到某个对象,并且程序可能需要这些实例,哪些实例不再可访问,因此可以删除。- 当Protocol Buffers序列化时,相同的数据可以有许多不同的二进制序列化。如果不完全解析两条消息,就无法比较它们是否相等。
- 消息不会被压缩。
- 对于涉及大型多维浮点数数组的许多科学和工程应用,Protocol Buffers消息在大小和速度上都没有达到最大效率。对于这些应用程序,FITS和类似格式的开销更小。
- Protocol Buffers消息本身并不自我描述其数据的能力,但它们具有完全反射的模式,您可以使用它来实现自我描述。也就是说,如果不访问其相应的 .proto 文件,您将无法完全解释它。
总结成图: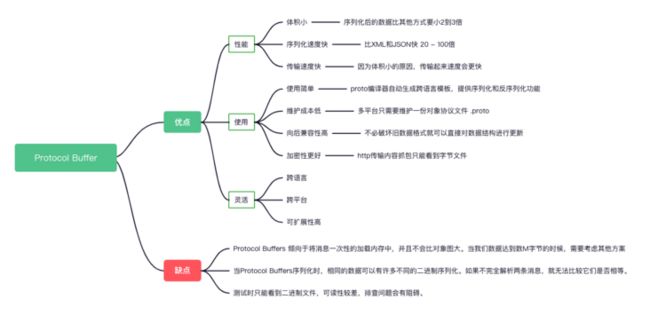
Protocol Buffers如何工作?
下图显示了如何使用协议缓冲区处理数据。

序列化速度快
- 编码 / 解码 方式简单,通过为位运算来完成。
- 采用PB自身的框架代码和编译器共同完成
序列化体积小
- 采用了独特的编码方式,如Varint、Zigzag编码方式等等
- 采用T - L - V 的数据存储方式:减少了分隔符的使用 & 数据存储得紧凑