python:变量和字符串
变量(variable)
Python中什么是变量
1、在Python中,变量的概念基本上和初中代数的方程变量是一致的
⑴例如,对于方程式 y=x*x ,x就是变量。当x=2时,计算结果是4,当x=5时,计算结果是25
⑵只是在计算机程序中,变量不仅可以是数字,还可以是任意数据类型
2、变量代表某个值的名字,是指向各种类型值的名字,以后用到这个值时,直接引用名字即可,不用再写具体的值
创建变量
1、每个变量在使用前都必须赋值(否则会报错),变量赋值以后,该变量才会被创建:变量名 = 值
⑴等号"=":赋值操作符,用来给变量赋值,左边是变量名,右边是指,不能写反了
⑵"="左边:是变量名(最好能做到见名知意)
⑶"="右边:是变量所指向的值
⑷变量定义之后,后续就可以直接使用了
例1:
a = 3 #定义一个变量a,并给其赋值为3注:
1、在Python中,一切都是对象,一切都是对象的引用
2、上面例子中,python将执行三个步骤来完成a = 3的赋值操作
⑴创建也变量a
⑵创建一个对象(分配一块内存),来存储值3
⑶将变量与对象,通过指针连接起来,从变量到对象的连接称之为引用(变量引用对象)
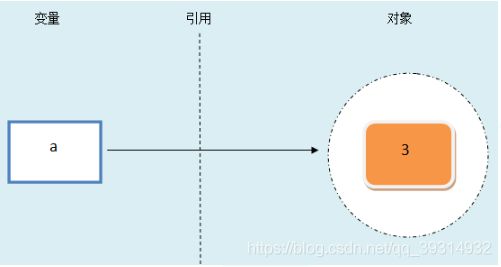
2、在Python中,定义变量是不需要指定数据类型的
⑴变量类型是在运行过程中根据对象的类型自动决定的
⑵但Python本身是有数据类型的,它的数据类型可分为数字型和非数字型
①数字型:整型int、浮点型float、布尔bool、复数型complex(bool:布尔类型中用True和False表示真和假(非零即真))
②非数字型:字符串、列表、元组、字典、集合
2.1、在Python 2.x版本中,根据保存数值的长度整型还分为整型(int)和长整型(long),而在Python 3.x版本中整型并没有区分整型(int)和长整型(long)
例2:
a = 4 #定义一个数字型的变量
b = "hello,world" #定义一个字符串型的变量
c = [1,2,3,4] #定义一个列表型变量
d = {"a":1} #定义一个字典型变量
print(type(a))
print(type(b))
print(type(c))
print(type(d))
"""
注:可以看到,在Python中定义变量时,直接使用赋值语句来定义就可以了
不需要指定变量的类型:变量类型由值的类型决定(变量名是没有类型的,值才有类型)
""" 3、在Python中,等号"="是赋值语句,可以把任意数据类型赋值给变量,同一个变量可以反复赋值,而且可以是不同类型的变量
⑴一个变量在多次赋值后,会后面的值会覆盖前面的值
例3:
a = 4 #定义一个数字型的变量
print(a)
print(type(a))
a = "hello,world" #定义一个字符串型的变量
print(a)
print(type(a))
a = [1,2,3,4] #定义一个列表型变量
print(a)
print(type(a))
"""
4
hello,world
[1, 2, 3, 4]
""" 注:
1、这种变量本身类型不固定的语言称之为动态语言(Python等),与之对应的是静态语言(JAVA等)
⑴静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错。例如Java是静态语言,赋值语句如下(// 表示注释)
⑵int a = 123; // a是整数类型变量
⑶a = "mooc"; // 错误:不能把字符串赋给整型变量
⑷和静态语言相比,动态语言更灵活,就是这个原因
2、在上面的例子中,a开始是一个整数,然后变成一个字符串,最后变成一个列表
⑴看起来,a的类型发生了三次改变,实上,在python中,变量没有类型,类型是属于对象的:即,值的类型决定了变量的类型
⑵就像前面所说,a = 4,是变量a引用了对象4,而以上三条语句,实际上是变量a引用了不同类型的对象
⑶当变量a重新赋值给字符串'hello,world'时,它的上一个引用对象4马上被回收了,对象的空间自动放入自由内存空间池,等待后来的对象使用(具体的垃圾回收就有点多了,就不介绍了)
3、不要把赋值语句的等号等同于数学的等号
例4:
x = 10 #"="表示赋值
x = x + 2
print(x)
y = 11
print(x==y) #"=="判断是否相等
"""
12
False
"""注:
1、如果从数学上理解x = x + 2那无论如何是不成立的,在程序中,赋值语句先计算右侧的表达式x + 2,得到结果12,再赋给变量x。由于x之前的值是10,重新赋值后,x的值变成12
2、最后,理解变量在计算机内存中的表示也非常重要。当我们写:a = 'ABC'时,Python解释器干了两件事情:
⑴在内存中创建了一个'ABC'的字符串
⑵在内存中创建了一个名为a的变量,并把它指向'ABC'
⑶也可以把一个变量a赋值给另一个变量b,这个操作实际上是把变量b指向变量a所指向的数据,例如下面的代码
例4_1:
a = 1
b = 2
c = a + b
print(a)
print(b)
print(c)
"""
1
2
3
"""注:
1、变量是指向各种类型值的名字,代表某个值的名字
2、在python中等号"="是赋值语句,在python中可以把任意数据类型赋值给一个变量
3、上面例子中,a,b,c都是我们创建的变量名,=是赋值语句,1,2,a+b(1+2)是变量值。第一句话的意思就是,创建变量名a,并将其赋值为1
例5:
a = 'ABC'
b = a #先对b赋值,然后才改变的变量a值
a = 'XYZ'
print(a)
print(b)
"""
XYZ
ABC
"""注:
变量的命名
1、 标识符:标识符就是在程序中定义的变量名和函数名
⑴标识符可以由字母、下划线和数字组成
⑵标识符不能以数字开头
⑶标识符不能与关键字重名
⑷标识符区分大小写
2、关键字:关键字就是在Python内部已经使用的标识符
⑴查看Python关键字
例6:
import keyword
print(keyword.kwlist)
变量的命名规则
1、官方的命名规则
⑴规定命名规则的目的是为了增加代码的识别性和可读性,并非绝对与强制
⑵定义变量时,建议在=的左右两边各保留一个空格。
⑶变量名由两个或多个单词组成时,每个单词都应使用小写字母,并且单词与单词之间用下划线连接。如:first_name
2、驼峰命名法
⑴变量名由两个或多个单词组成时,还可以使用驼峰命名法来命名
⑵小驼峰式命名法:第一个单词以小写字母开始,后续单词的首字母大写。如:firstName
⑶大驼峰式命名法:每一个单词的首字母都大写。如:FirstName。
不同类型变量之间的计算
1、数字型变量之间的计算
⑴在Python中,数字型变量之间是可以直接计算的
⑵布尔类型(bool)变量在计算时True的值为1,False的值为0
2、字符串变量之间的计算
⑴在Python中,字符串变量之间可以用"+"进行拼接,生成新的字符串(字符串拼接)
⑵在Python中,字符串变量和整型变量之间可以用*进行计算,表示重复拼接相同的字符串。除此之外,数字型变量和字符串之间不能进行其他计算
例7:数字变量之间的加法
a = 1
b = 2
a = a + 1
b = a + b
print(a)
print(b)
"""
2
4
"""例7_1:字符串变量之间的加、乘法
a = "hello"
b = " world"
b = a + b #两个字符串拼接
a = a * 2
print(a)
print(b)
"""
hellohello
hello world
"""例7_2:
a = "1"
b = "2"
b = a + b #字符串型的数字进行拼接
print(b)
"""
12
"""注:
1、字符串必须以引号标记开始,并以引号标记结束
2、只要使用双引号、单引号、三引号括起来的值,都属于字符串(当然三引号还用于多行注释,区别在于作为注释时,无赋值操作)
3、当数字为字符串时,在进行加法"+"计算时,表示的是字符串拼接,而不是数学上的加法
4、要告诉Python你在创建一个字符串,就要在字符两边加上引号,可以是单引号或双引号,Python表示在这一点上不挑剔。但必须成对,不能一边用单引号,另一边却用双引号
原始字符串
前面我们说到,在Python中创建一个字符串时,只需要在字符两边加上引号就可以了。那如果字符串内容中需要出现单引号或双引号,该怎么办?
例8:
print('Let's go')
#SyntaxError: invalid syntax注:
1、如果在字符串中必须用到引号(如:'let's go'),如果直接这样写的话,python就会误会,报错:invalid syntax
⑴因为字符中存在多个相同的引号,Python无法区分哪个是字符串自带的,哪个是用来表示字符串的
⑵认为'Let'是一个字符串,而sgo'是另一个不完整的字符串,因此就报错了
2、有两种方法来改进
⑴使用转义符号"\":对字符串中的引号进行转义,这样Python就知道这个引号是要直接输出的
⑵使用用单引号、双引号、三引号来区分
例8_1:
print('Let\'s go')
#Let's go
#使用反斜杠来进行转义例8_2:
print("Let's go")
print("""Let's go""")
"""
因为字符串本身中用的是单引号,因此外部就可以使用双引号或者三引号来区分
Let's go
Let's go
"""3、另外在变成语言中还有跟多的特殊的符号来表示特殊的一些操作。如:\n表示换行等
例9:
print("C:\now")
"""
C:
ow
"""注:
1、在这个例子中我们实际想打印的是文件的目录字符串,但是由于字符串中"\n"刚好构成换行符,因此造成了实际输出与我们预期的不一致
2、解决这类问题的办法有两个
⑴使用双转义:"C:\\now"
⑵在使用原始字符串时,在字符串前面加字母"r":表明字符串为原始字符串(在后面的正则表达式中就会经常用到r来表示原始字符串)
例9_1:
print("C:\\now")
print(r"C:\now")
"""
C:\now
C:\now
""" 注:
1、在使用字符串时需要注意的一点是:无论是否为原始字符串,都不能以反斜杠作为结尾
2、反斜杠放在字符串的末尾表示该字符串还没有结束,换行继续的意思
长字符串
在打印一长串字符串时,我们有可能就会遇到使用很多换行符,这样就显得很是麻烦
例10:
print("从明天起做一个幸福的人\n喂马,砍柴,周游世界\n从明天起,关心粮食和蔬菜\n我有一所房子,面朝大海,春暖花开")
"""
从明天起做一个幸福的人
喂马,砍柴,周游世界
从明天起,关心粮食和蔬菜
我有一所房子,面朝大海,春暖花开
"""注:
1、可以看到,如果字符串是一个长字符串,当要换行输出时,就需要使用很多换行符,这样就显得很麻烦了
2、如果需要写非常长的字符串,它需要跨多行,那么可以使用三个引号代替普通引号
3、python为我们提供了简单的方法:使用三重引号字符串"""内容"""
例9_1:
a = """从明天起做一个幸福的人
喂马,砍柴,周游世界
从明天起,关心粮食和蔬菜
我有一所房子,面朝大海,春暖花开
"""
print(a)
"""
从明天起做一个幸福的人
喂马,砍柴,周游世界
从明天起,关心粮食和蔬菜
我有一所房子,面朝大海,春暖花开
"""注:
1、因为这种与众不同的引用方式,你可以在字符串之间同时使用单引号和双引号,而不需要使用反斜线进行转义
2、普通字符串也可以跨行。如果一行之中最后一个字符是反斜线,那么换行符本身"转义"了,也就是被忽略了
例9_2:
a = """从明天起做一个幸福的人
'喂马,砍柴,周游世界'
"从明天起,关心粮食和蔬菜"
我有一所房子,面朝大海,春暖花开
"""#在三引号中使用单引号和双引号:不需要转义
print(a)
b = "从明天起做一个" \
"幸福的人"
print(b)
"""
从明天起做一个幸福的人
'喂马,砍柴,周游世界'
"从明天起,关心粮食和蔬菜"
我有一所房子,面朝大海,春暖花开
从明天起做一个幸福的人
"""注:编程中使用的标点符号都是英文的
拓展
字节
1、计算机中储存的信息都是用二进制(字节:byte)数表示的:字节是计算机信息技术用于计量存储容量的一种计量单位
⑴字节是二进制数据的单位
⑵Byte是从0-255的无符号类型,所以不能表示负数
2、通常8个二进制位构成1个"字节(Byte)":1个字节可以储存1个英文字母或者半个汉字,换句话说,1个汉字占据2个字节的存储空间
3、我们在屏幕上看到的英文、汉字等字符是二进制数转换之后的结果
⑴通俗的说,按照何种规则将字符存储在计算机中,如'a'用什么表示,称为"编码"
⑵反之,将存储在计算机中的二进制数解析显示出来,称为"解码"
⑶如同密码学中的加密和解密。在解码过程中,如果使用了错误的解码规则,则导致'a'解析成'b'或者乱码
字符编码
1、在计算机中,所有的东西都是以字节形式储存的,但是字节对于我们来说是没有具体意义的,因此我们需要把二进制字节转换成人们能够理解的字符
2、二进制字节与人们能够理解的字符之间的相互转换称为编码(解码)。如何进行编码(解码)就必须要有一种规则来约束,肯定不能10个人有10中编码(解码)方式
3、最早的是使用ASCII码将字符对应到二进制字节上
ASCII
1、美国人搞了个ASCII码表,把123abcABC%$#等(数字、字母、特殊符号) ,全部用10进制的数字表示
2、例如数字65,代表着“A” ,ASCII码表一共255个数字,基本代表米国常用英文和符号(其实127以后都不是太常用的了)
GB2312
1、中国汉字那么多,255个数字显然不够表示。所以中国人发明了GB2312(6千个常用简体汉字),后来又搞了GBK(2万多汉字,并且包含中日韩中的汉字),再后来又搞了一个GB18030(2.7万汉字,包含中国的少数民族语言)
Unicode
1、每个国家不同语言,都需要有自己的编码表,很麻烦。比如
⑴如果日本的软件出口到中国,中国电脑一打开就会乱码(因为没装日本的编码表,软件内文字会乱码)
⑵如果一个文件中包含日语、中文、英文,那打开后就乱码了
2、于是,Unicode国际统一码(2-4个字节)诞生了:至少用16个2进制表示:11111111 11111111 (2个bytes)
3、Unicode其实是一张很大的对应关系表:对应着1个字符,以及这个字符在ascii码中的位置。所以,无论你使用何种编码,都能转换成unicode码,而unicode码又能转换成任何其他编码
⑴可以理解unicode左手牵着你编码的字符,右手牵着其他国家的各种编码
⑵这样的话,无论你使用GBK、ASCII、或者其他国家对字符进行编码,都能通过这张大表,找到对应其他编码的位置
⑶unicode是一种编码标准,具体的实现标准可能是utf-8,utf-16,gbk...
UTF-8
1、使用unicode全球人民都很高兴,终于不再出现乱码了,但是美国、英国人不高兴了
2、因为以前他们都使用ASCII码,存一个电影1个GB,现在用Unicode变成了2个GB了
⑴因为ASCII码一共255个数字就可以表示美国人使用的常用字符,255转换成二进制:1111 1111(十进制转二进制),是1个bytes
⑵而Unicode至少2个bytes,所有使用unicode编码的文件,就会比ascii码多一倍大小
3、于是乎,为了优化unicode,节省字节。又搞出了UTF-8
⑴英文继续用1个字节,欧洲用2个字节,东南亚用3个字节
⑵注意:使用unicode的时候中文是2个字节,现在使用UTF8变成了3个字节表示了
Python字符串编码
目前Python有Python2和Python3两个常用的版本;这两个版本其实还是有挺多差距的,比如:字符串编码
Python2中的字符串
1、Python2中有两种字符串类型:str类型和unicode类型
⑴str:存储着字节(bytes:二进制流),str并不是完全意义上的字符串,其实是由unicode经过编码(编码格式如UTF-8、GBK等)后的字节组成的字节字符串
⑵unicode:存储为16位unicode字符串,这样能够表示更多的字符集。使用的语法是在字符串前面加上前缀u,unicode则是真正意义上的字符串,由字符组成
2、Python2中定义字符串的时候,字符串的类型是str(不特殊处理、直接定义),也就是具有某种编码格式的字符串(编码格式如UTF-8、GBK等)
⑴这个字符串的编码格式取决于你第一行代码声明的编码格式,注意第一行声明的编码格式需要与.py文件的编码格式相同。比如使用# coding:utf-8来声明编码格式为UTF-8
⑵也就是说在Python2中定义一个字符串时,必须在PY文件第一行中声明编码格式(针对中文)
3、如果需要定义一个unicode类型的字符串的话,需要在字符串前加u或使用unicode()方法强制转换
3、Python2默认的编码格式(默认字符集)是ASCII
例1:查看编码格式
import sys
print sys.getdefaultencoding()
"""
# 可以看到Python2默认的编码格式(默认字符集)是ASCII
ascii
"""例2:
# 未声明编码格式
string = "你好,世界"
print string
"""
SyntaxError: Non-ASCII character '\xe4'
原因:
1、Python2默认的编码格式(默认字符集)是ASCII,但ASCII编码是不支持中文的
2、可以看到未声明编码格式,python2是不能直接输出中文字符串的:ASCII编码是不支持中文的
"""例3:指定编码格式,str类型
# coding:utf-8
string = "你好,世界"
print string
print type(string)
print len(string)
"""
你好,世界
15
""" 例4:指定编码格式,unicode类型
# coding:utf-8
string = u"你好,世界"
print string
print type(string)
print len(string)
new_string = unicode("你好,世界",encoding="utf-8")
print new_string
"""
你好,世界
5
你好,世界
""" 注:
1、第一行代码是声明本模块的编码格式,当不写这一行的时候,在Pythcam中的字符串是没办法输入汉字的,写上这一行以后
⑴例3、例4都是以utf-8编码的字符串
⑵例3:为str(字节)类型的字符串,输出的是它本身,长度为15(utf-8中一个汉字、一个中文符号占三个字节)
⑶例4:是一个unicode类型的字符串,输出也为它本身,长度为5(一个汉字、一个中文符号占1个Unicode)
2、上面例子中分别使用str格式和unicode格式输出一个中文,虽然最终输出的结果是一样的,但是内部是有很大区别的(字符串类型、格式有很大的区别)
⑴之所以都输出了"你好,世界",感觉可能是print方法处理过了
⑵如果在python交互模式下,就能很清楚的看到两者的差别了
例5:
Python 2.7.15 (v2.7.15:ca079a3ea3, Apr 30 2018, 16:30:26) [MSC v.1500 64 bit (AMD64)] on win32
Type "copyright", "credits" or "license()" for more information.
>>> s1 = "你好"
>>> s1
'\xc4\xe3\xba\xc3'
>>> print s1
你好
>>> s2 = u"你好"
>>> s2
u'\u4f60\u597d'
>>> print s2
你好
>>>
Python2中unicode类型和str类型相互转换
1、unicode类型和str类型相互转换其实就是:对一个内容进行编码和解码的一个过程
2、Python以Unicode编码为转换中介,进行字符串的转码
⑴python在内部使用两个字节来存储一个unicode,使用unicode对象而不是str的好处,就是unicode方便于跨平台
3、Python中解码、解码
⑴解码:就是把某种编码格式(如UTF-8)的"内容"(二进制序列、字节码)解码成Unicode(其实也是一种二进制序列,只是不便于传输)
⑵编码:就是将Unicode编码成某种编码格式的"内容"(二进制序列、字节码)
4、Python中可以使用encode()方法和decode()方法来进行编码和解码
⑴decode(self, encoding=None, errors=None):解码
⑵encode(self, encoding=None, errors=None):编码
例6:解码
# coding:utf-8
string = "你好,世界"
print string
print type(string)
new_string = string.decode(encoding="utf-8") #以utf-8编码方式解码,解码为unicode类型
# 参数必须与第一行的声明相同,解码为unicode类型的字符串
"""
这里必须传入encoding参数,不然会报错
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
原因:
1、因为默认情况下,Python2采用的是ascii编码方式,如果不指定的话就会按照ascii格式来解码
2、而Python2在进行编码方式之间的转换时,会将unicode作为“中间编码”,但unicode最大只有128那么长,
3、所以这里当尝试将ascii编码字符串转换成"中间编码" unicode 时由于超出了其范围,就报出了如上错误
"""
print new_string
print type(new_string)
"""
你好,世界
你好,世界
""" 例7:编码
# coding:utf-8
string = u"你好,世界"
print string
print type(string)
# unicode字符串编码为utf8的str类型的字符串
new_string = string.encode(encoding="utf-8")
print new_string
print type(new_string)
# unicode字符串编码为gbk的str类型的字符串
new_string1 = string.encode(encoding="GBK")
print new_string1
print type(new_string1)
"""
你好,世界
你好,世界
���,����
""" 例8:在交互模式下解码
>>> string = "你好,世界"
>>> string
'\xc4\xe3\xba\xc3,\xca\xc0\xbd\xe7'
>>> print type(string)
>>> new_string = string.decode(encoding="utf-8")
Traceback (most recent call last):
File "", line 1, in
new_string = string.decode(encoding="utf-8")
File "C:\Python27\lib\encodings\utf_8.py", line 16, in decode
return codecs.utf_8_decode(input, errors, True)
UnicodeDecodeError: 'utf8' codec can't decode byte 0xc4 in position 0: invalid continuation byte
>>> new_string = string.decode(encoding="gbk")
>>> new_string
u'\u4f60\u597d,\u4e16\u754c'
>>> 例8_1:在交互模式下编码
>>> string = u"你好,世界"
>>> new_string = string.encode(encoding="utf-8")
>>> new_string
'\xe4\xbd\xa0\xe5\xa5\xbd,\xe4\xb8\x96\xe7\x95\x8c'注:
1、可以看到在交互模式下使用utf-8来解码时报错了,但是当改为gbk时就能正常解码了
⑴这是因为在Pycharm中时使用"# coding:utf-8"来指定了字符串的编码格式:按照utf-8来编码。此时按照utf-8来解码肯定是可以的
⑵但是在交互模式下,我们没有指定字符串的编码格式:此时就不一定是按照utf-8来编码,可能是其他编码格式,因此按照utf-8来解码就可能不对了
2、因此:
⑴如果python中所要处理的字符串中包含中文,那么最好要搞懂所用字符的编码,是gbk/gb2312/gb18030,还是utf-8,否则容易出现乱码,以及此处的语法错误
⑵以哪种方式编码,就要以哪种方式解码
⑶在读取字符串、打开文件(txt等文件)一定要指定文件内容以哪种编码打开,不然可能会出问题。最好是以UTF-8编码方式打开
3、注意:在解码、编码过程中一定要对应字符串类型是正确的
⑴解码(decode方法):str类型(utf8等编码)字符串--->Unicode类型(Unicode编码)字符串
⑵编码(encode方法):Unicode类型(Unicode编码)字符串--->str类型(utf8等编码)字符串
⑶不能对一个str类型(字节)字符串进行编码;也不能对一个Unicode类型字符串进行解码
例8_2:
# coding:utf-8
string = u"你好,世界"
print string
print type(string)
# 对一个unicode字符串继续解码
new_string = string.decode(encoding="utf-8")
"""
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
解码是将其他编码格式的内容转为unicode编码,string值本来就是unicode类型的了,再继续解码就违背了解码decode方法的用法了,因此肯定会报错
反之,也不能对一个str类型的字符串进行编码
"""
Python3中的字符串
1、Python3中:字符串有str类型和bytes类型两种
2、Python3中的str类型字符串:
⑴存储为16位unicode字符串,元素是字符
⑵Python3中直接定义的字符串就是str类型的:被单引号、双引号、三引号括起来的来字符串就已经是unicode类型的字符串了
⑶Python3的字符串默认为Unicode编码的字符串(str类型)
3、Python3中的bytes类型字符串:
⑴字节序列(字节码:二进制流)。经过编码(编码格式如UTF-8、GBK等)后的字节组成的字节字符串,元素是字节
⑵普通字符串前加上字母b作为前缀,就表示bytes类型字符串了
4、python3中默认使用的编码方式为UTF-8
⑴因此在Python3中定义字符串时,就不需要在PY文件中第一行声明编码方式了(# coding:utf8)
例9:定义一个str类型字符串
string = "你好,世界"
print(string)
print(type(string))
print(len(string))
"""
你好,世界
5
""" 例9_1:定义一个bytes类型字符串
string = b'\xe4\xbd\xa0\xe5\xa5\xbd,\xe4\xb8\x96\xe7\x95\x8c'
print(string)
print(type(string))
print(len(string))
"""
b'\xe4\xbd\xa0\xe5\xa5\xbd,\xe4\xb8\x96\xe7\x95\x8c'
13 #utf8中一个汉字三个字节
""" 注:
1、Python2中str类型和Unicode类型输出都是可见的字符串,Python3中str类型(Unicode编码)为可见字符串,bytes类型为字节序列,输出看不懂
2、Python3的字符串默认为Unicode编码的字符串(str类型),当你定义一个带中文的字符串的时候,需要在第一行声明文本类型(# coding:utf8),如果不声明第一行的话,默认为utf8。也就是说这时候,需要.py文件的编码为utf8,否则会出错
⑴python3中默认使用的编码方式为UTF-8,当定义一个字符串时,Python会自动使用UTF-8格式去解码成unicode类型。因此可以说Python3的字符串默认为Unicode编码的字符串(str类型)
3、因为:当你定义一个字符串的时候,你的文本是以另一个编码格式编码成的(非UTF-8)。而Python3的str类型是Unicode编码的,会自动以你这一个编码(不声明的话,默认为UTF8)去解码成Unicode,当你文本格式不是UTF8并且没有声明编码格式的话,就会解码错误
⑴在PY文件中定义了一个字符串,该PY文件不是以UTF-8编码的,但是Python3默认的编码方式为UTF-8,因此在自动解码这个字符串时也会默认使用UTF-8,这样编码方式和解码方式就不一样了,因此会报错
4、Pycharm设置文件编码格式方法如下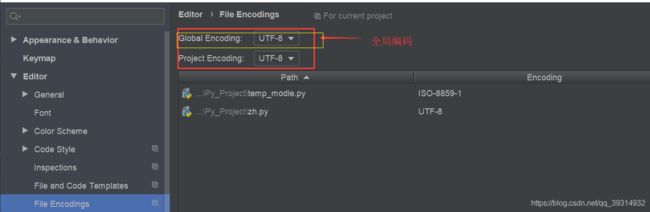
Python3中str类型与bytes类型相互转换
1、str类型与bytes类型相互转换其实就是:对一个内容进行编码和解码的一个过程
2、Python中解码、解码
⑴解码:就是把某种编码格式(如UTF-8)的"内容"(二进制序列)解码成Unicode(其实也是一种二进制序列,只是不便于传输)
⑵编码:就是将Unicode编码成某种编码格式的"内容"(二进制序列)
3、Python中可以使用encode()方法和decode()方法来进行编码和解码
⑴decode(self, encoding=None, errors=None):解码
⑵encode(self, encoding=None, errors=None):编码
4、Python2和Python3编码、解码的定义是一样的,所以使用的方法也是一样的
⑴Python2和Python3只是对字符串的分类定义有一点差距
⑵Python2的str相当于Python3的bytes,Python2的unicode相当于Python3的str
5、另外在Python3中str类型与bytes类型之间的转换还可以使用str()和bytes()方法
例10:bytes()编码
string = "你好,世界"
print(string)
print(type(string))
new_string = bytes(string,encoding="utf-8") #必须指定编码格式
print(new_string)
print(type(new_string))
"""
你好,世界
b'\xe4\xbd\xa0\xe5\xa5\xbd,\xe4\xb8\x96\xe7\x95\x8c'
注:在使用内置函数bytes()的时候,必须明确encoding的参数(意思是按什么编码方式编成存储的二进制),不可省略
""" 例10_1:encode()编码
string = "你好,世界"
print(string)
print(type(string))
# 指定编码格式为GBK,不指定默认为UTF-8
new_string = string.encode(encoding="GBK")
print(new_string)
print(type(new_string))
print(string.encode())
"""
你好,世界
b'\xc4\xe3\xba\xc3,\xca\xc0\xbd\xe7'
b'\xe4\xbd\xa0\xe5\xa5\xbd,\xe4\xb8\x96\xe7\x95\x8c' #编码不同,导致了长度不同
""" 例11:str()解码
string = b'\xe4\xbd\xa0\xe5\xa5\xbd,\xe4\xb8\x96\xe7\x95\x8c'
print(string)
print(type(string))
# 可以不指定解码格式,默认为UTF-8
new_string = str(string,encoding="utf-8")
print(new_string)
print(type(new_string))
"""
b'\xe4\xbd\xa0\xe5\xa5\xbd,\xe4\xb8\x96\xe7\x95\x8c'
你好,世界
""" 例11:decode()解码
string = b'\xe4\xbd\xa0\xe5\xa5\xbd,\xe4\xb8\x96\xe7\x95\x8c'
print(string)
print(type(string))
new_string = string.decode(encoding="utf-8")
print(new_string)
print(type(new_string))
print(b'\xc4\xe3\xba\xc3,\xca\xc0\xbd\xe7'.decode(encoding="GBK"))
"""
b'\xe4\xbd\xa0\xe5\xa5\xbd,\xe4\xb8\x96\xe7\x95\x8c'
你好,世界
你好,世界
""" 注:
1、Python3中:字符串有str类型(Unicode编码)和bytes类型(字节序列)两种
2、编码:encode()方法或bytes()方法
⑴str类型(Unicode编码)字符串-->bytes类型字节序列
3、解码:decode()方法或str()方法
⑴bytes类型字节序列-->str类型(Unicode编码)字符串
4、编码、解码方式一定要一一对应
⑴不能说,使用UTF-8编码,但是用GBK来解码,这样的话肯定会报错的
5、不能对一个已经编码了的字符串继续编码,也不能对一个已经解码了字符串继续解码
6、不管是Python2还是Python3都是以"Unicode为转换中介"的
⑴只能字节序列解码成Unicode;Unicode编码成字节序列
⑵比如不能对格式为utf-8的字符串编码成GBK格式,只能先转为unicode格式才能继续编码;反之解码也是
7、在Python3中读取字符串、打开文件(txt等文件)一定要指定文件内容以哪种编码打开,不然可能会出问题。最好是以UTF-8编码方式打开
Python2与python3字符串差异比较
| 版本 | 字节码 | 字符串 | 默认编码 |
| Python2 | str | unicode | ascii |
| Python3 | bytes | str | utf-8 |
注:
总的来说,Python3中对于中文的处理方式就很简单明了了
⑴默认编码方式为utf-8:一般情况下不需要指定编码格式
⑵从字面意义上就能很清楚的分清str类型和bytes类型:在理解上很友好
⑶严格区分了str类型和bytes类型:两者不能进行拼接