re模块用于对python的正则表达式的操作
字符:
.匹配除换行符以外的任意字符
\w匹配字母或数字或下划线或汉字
\s匹配任意空白符
\b匹配单词的开始或结束
^匹配字符串的开始
$匹配字符串的结束
次数
*重复零次或多次
+重复一次或多次
?重复零次或者一次
{n}重复n次
{n,}重复n次或更多次
{n,m}重复n到m次
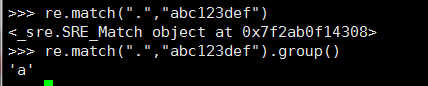
出现一串类似于这样的字符代表匹配上了 使用group()把匹配的字符打印出来
match是从字符串开头开始匹配所以匹配到了第一个字符a
搜索整个字符串匹配第一个数字
![]()
匹配第一个一串数字 加了+号

后面加了一串字符串也是匹配第一个
![]()
匹配所有的使用另外一个方法findall 这里后面不用group


取出所有非数字的字符

使用数字作为分隔符分割

替换所有匹配字符串

替换一次

匹配IP地址
1,匹配一个数字只匹配到1
2,匹配多个数字配置到10
3,匹配多个数字1-4次匹配到10 因为ip地址之间使用.分割
4,使用\d+.表示匹配数字加. 后面{1,4}代表匹配1-4次


PS:这里的.代表匹配任意一个字符这里刚刚好任意一个字符是.需要指定匹配.则在前面加\
假如这个字符串里面还有其他数字怎么来匹配到IP地址呢
re.search("[0-2]{0,3}[0-9]{0,3}[0-9]{0,3}\.[0-2]{0,3}[0-9]{0,3}[0-9]{0,3}\.[0-2]{0,3}[0-9]{0,3}[0-9]{0,3}\.[0-2]{0,3}[0-9]{0,3}[0-9]{0,3}",t).group()
'10.8.45.27'
更加严谨一点的表达式
re.search("(\d{1,2}|1\d\d|2[0-4]\d|25[0-5])\.(\d{1,2}|1\d\d|2[0-4]\d|25[0-5])\.(\d{1,2}|1\d\d|2[0-4]\d|25[0-5])\.(\d{1,2}|1\d\d|2[0-4]\d|25[0-5])",t).group()
以取IP第一位为例
re.search("(\d{1,2}|1\d\d|2[0-4]\d\25[0-5])\.",t).group()
(\d{1,2}|1\d\d|2[0-4]\d\25[0-5])\.
第一位要不就是一个两位数 要不就是以1开头的三位数 要不就是以2开头第二位是0-4之一第三位是一个数字 要不就是25开头第三位为0-5(严格来说应该是0-4) 最后匹配一个.号 最后一位数不带.号
使用groups生成元祖
name = "liu yueming"
re.search("(\w+) (\w+)",name).groups()
('liu', 'yueming')
>>> res = re.search("\w+",name)
>>> res = re.search("(?P
>>> res.group("name")
'liu'
>>> res.group("last_name")
'yueming'
取到名和姓 用的少
使用正则表达式实现计算器功能