paper reading:《Mask Encoding for Single Shot Instance Segmentation》

CVPR 2020
论文链接:
https://arxiv.org/abs/2003.11712.
代码链接:
https://github.com/aim-uofa/AdelaiDet.
文章目录
- 1 Background and Motivation
- 2 Related Work
- 3 Advantages/Contributions
- 4 Method
-
- 4.1.Network Architecture
- 4.2.Mask Encoding
- 3.3.Correlation Between Boxes and Masks
- 5 Experiments
-
- 5.1.Ablation Study
- 5.2.Comparison with State-of-the-art Methods
- 5.3.Advantages and Limitations
- 6 Conclusion
1 Background and Motivation
Instance segmentation (实例分割)能够实现多种计算机视觉应用,比如autonomous driving(自动驾驶)和robot navigation(机器人导航)。Instance segmentation将目标检测和为像素分配类别标签结合起来,因此是计算机视觉中最具有挑战性的任务之一。
深度卷积神经网络(CNN)的最新进展已在实例分割方面取得了巨大进展,比如 《Mask RCNN》.、《Mask scoring R-CNN》.、《Fully convolutional instance-aware semantic segmentation》.、《Path aggregation network for instance segmentation》.。迄今为止,实例分割主流方法是由Mask R-CNN率先采用的two-stage方法,几乎所有具有挑战性的COCO benchmark上排名最高的方法都是基于Mask R-CNN。 相比之下,one-stage方法无法与Mask R-CNN竞争,这主要是由于紧凑地Mask 表示的难度,使得one-stage方法的设计非常具有挑战性。但是two-stage的解决方案效率不高,因为它们在运行时受到图像中发中实例数量的限制。而one-stage的模型直接处理整个图像,无论存在多少对象,速度都稳定。
一些工作尝试把Mask prediction合并到FCNs中,从而形成一阶段实例分割框架,这些算法的共同点是使用一组轮廓系数来对 object shape 进行编码。比如ESE-Seg 为每个实例设计了一个““inner-center radius”形状特征,并用切比雪夫多项式进行拟合。 PolarMask使用质心与轮廓之间的密集距离进行回归。 这些基于轮廓的方法具有易于优化和快速推断的优点。这些方法的主要问题是,预测的Mask可能不可避免地表现出“hollow decay”,因为它们只能描绘具有单个轮廓的实例,如下图所示。”

总结来说,就是没有很好的把物体内轮廓分割出来,上图中Contour-Based的方法中矩形框也就是背景也和前景分割到一起了,相比之下Mask-Based的方法要好一些。
对于mask prediction来说,non-parametric mask representation是更加自然。由于natural object masks 不是随机的并且类似于 natural images,因此instance mask的固有尺寸远低于像素空间的固有尺寸。所以作者想是否可以在固定的低维空间去预测 object mask ,并且仍然能实现好的accuracy?因此作者提出了mask encoding based instance segmentation (MEInst),即通过一个learned dictionary 来对instance mask进行编码,以便只需要几个scalar coefficients 便可以表示每个mask。这个学习框架可以通过在one-stage检测器增加一个可以预测fixed-dimensional mask coefficients的分支来进行扩展,作者使用的是FCOS检测器,因为它比较简单,检测性能比较好。
2 Related Work
- Two-stage Instance Segmentation :detect-then-segment,先检测,再分割! eg:Mask R-CNN 、 Mask Scoring R-CNN
- One-stage Instance Segmentation : generating pixel-wise classification maps firstly and then clustering them into instances,先生成逐像素分类图,再聚成实例! eg: InstanceCut
Dense object segmentation 一直没有很大的进展,最近有一些工作填补了这个上面的空白,展示出了一些惊人的效果!eg: TensorMask 、YOLACT、 BlendMask 、 PolarMask 、 SOLO、SOLOv2
3 Advantages/Contributions
- 提出了将二维实例mask编码成一个 compact representation vector,压缩的向量充分利用了 original mask 中的的 redundancy ,并证明了重建的有效性和效率。编码可以使用一些字典学习方法来完成,包括PCA,稀疏编码和自动编码器。 本文中即使是最简单的PCA也已经可以进行mask编码。
- 通过在FCOS上扩展进行mask系数回归的mask分支,提出了MEInst one-stage 实例分割新框架,在ResNeXt-101-FPN主干网络和 MS-COCO数据集上达到36.9%的mask AP 。提出的mask编码完全独立于检测器,因此它可以很容易地合并到其他检测器中。
- 提出的MEInst简单灵活,最好的模型在 COCO test-dev实现了38.2%的mask AP,对精度和速度实现了很好的均衡。
4 Method
4.1.Network Architecture
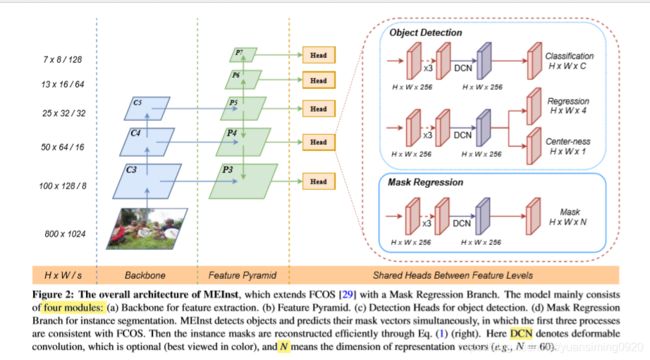
模型主要是在 FCOS上进行扩展 Mask Regression Branch,模型主要包括四个模块:
- 特征提取的主干网络
- 特征金字塔
- 目标检测模块: classification, box regression and center-ness
- 实例分割的Mask回归分支: predicting encoded mask coefficients
目标检测和预测Mask向量是同时进行的
4.2.Mask Encoding
现有的Mask表示包含冗余信息,并且可以高度压缩而损失可忽略不计。
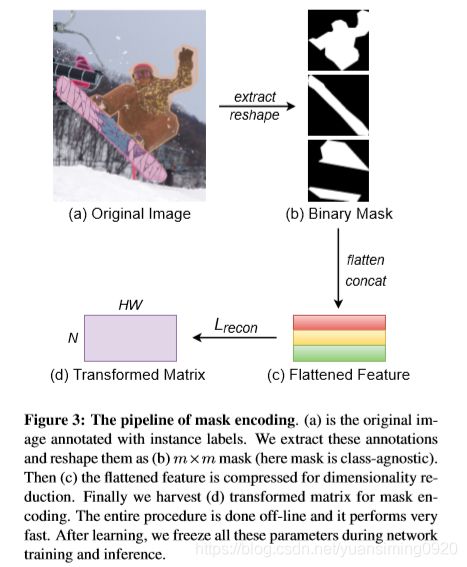
- Compact Representation : M ′ ∈ R H × W M^{'}\in R^{H\times W} M′∈RH×W表示 ground truth mask ; v ∈ R N v\in R^{N} v∈RN表示 compressed vector,其中 H 、 W 和 N H、W和N H、W和N分别表示 two dimensional mask 的高度和宽度、压缩的表示向量的维度。因为 M ′ M^{'} M′是类未知的,所以所有的类别都被编码成 binary-class encoding,即 M ′ ∈ { 0 , 1 } H × W M^{'}\in \left \{ 0,1 \right \}^{H\times W} M′∈{0,1}H×W;为了便于计算,mask被拉平成一个向量即 u ∈ R H W u\in R^{HW} u∈RHW。为了把 u u u压缩成 v v v,作者寻求某种准则下的变换,以最大程度地减小 u u u和 v v v之间的重构误差。虽然很多方法可以使用,但是在本文中作者发现直接使用线性也可以实现很好的性能,因此有:
v = T u ; u ~ = W v v=Tu;\tilde{u}=Wv v=Tu;u~=Wv- M ′ ∈ R H × W M^{'}\in R^{H\times W} M′∈RH×W表示 ground truth mask
- v ∈ R N v\in R^{N} v∈RN表示 compressed vector, N N N表示the dimension of compact representation vector
- u ∈ R H W u\in R^{HW} u∈RHW,the mask is flattened to be a vector for ease of calculation,
- T ∈ R N × H W T\in R^{N\times HW} T∈RN×HW,表示 project matrix,用来压缩 u u u到 v v v
- W ∈ R H W × N W\in R^{HW\times N} W∈RHW×N,表示 reconstruction matrix,用来把 v v v重构成 u u u
最后,作者通过在训练集上最小化 u u u和 u ~ \tilde{u} u~之间的 reconstruction error来得到矩阵 T T T和 R R R,数学表达式如下:
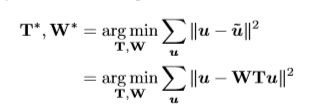
作者遵循DUpsampling中的策略,并通过使用主成分分析(PCA)来优化此目标。
- Mask Reconstruction :知道 predicted representation vector v ^ ∈ R N \hat{v}\in R^{N} v^∈RN,可以根据 u ~ = W v \tilde{u}=Wv u~=Wv来进行重建二维Mask M ′ M^{'} M′
- Loss Function :Mask损失函数如下:
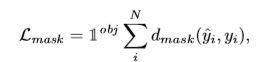
- I o b j \mathbb{I}^{obj} Iobj是indicator function(指示函数),当obj为正样本时为1,当obj为负样本时为0
- y ^ i \hat{y}_{i} y^i为预测的vectors的第 i i i个元素
- y i {y}_{i} yi为ground-truth vectors的第 i i i个元素
- 实验中的 d m a s k ( . , . ) d_{mask}\left ( . , . \right ) dmask(.,.)为 l 2 l_{2} l2损失
总体损失为:
![]()
- £ d e t \pounds_{det} £det是检测损失
- £ c l s \pounds_{cls} £cls是分类损失,使用focal loss
- £ r e g \pounds_{reg} £reg是回归损失,和FCOS中一样是 GIoU loss
- £ c e n \pounds_{cen} £cen是center-ness分支的损失,使用 binary cross entropy (BCE) loss
实验中, £ d e t \pounds_{det} £det中的所有balance weights 都为1, λ d d e t = λ m a s k = 1 \lambda _{ddet}=\lambda _{mask}=1 λddet=λmask=1。
3.3.Correlation Between Boxes and Masks
通常,实例分割和目标检测是密不可分的,作者认为更好的bounding box可改善Mask分支的整体性能,下面就是做的实验来证明这个想法。
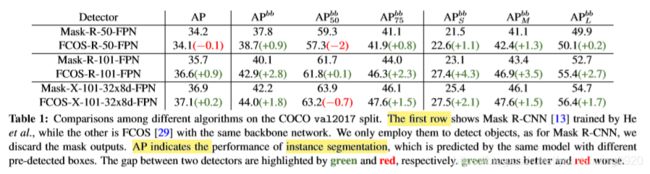
以 A P b b AP^{bb} APbb为度量标准,与Mask-RCNN相比,FCOS实现更好的目标检测性能。但是对应的分割结果没有得到很大的提升(表中第一列 A P AP AP)。此外,我们还观察到,除 A P 50 b b AP_{50}^{bb} AP50bb以外,FCOS在所有常规指标下的效果都更好,这表明FCOS预测的框是准确的位置,但假阳性(FP)较多。

图(a)展示了box和mask的correlation,可以看到FCOS整体的检测结果要比Mask-RCNN好,但是实例分割结果与Mask-RCNN相同或者甚至更差。
图(b)使用不同模型预测的bounding boxes的平均数量,可以看到FCOS预测的数量明显要比Mask-RCNN的多,这是因为Mask-RCNN是two-stage方法,即 first proposes candidates and then refines the boxes,先提取候选框,然后再精炼bound ing boxes,这样可以有效过滤掉不需要的框框;而FCOS是one-stage方法,它会直接生成结果,导致很多 redundant boxes,大多数的one-stage方法都会存在这种问题。作者提出 larger receptive field可以缓解这个问题,理论感受野要比实际感受野小,因为CNN趋向于捕获中心区域的信息,ERF不足可能导致许多假阳性(FP)框,因为网络无法“看到”物体,所以作者在 multi-head branches 的 last vanilla convolutional layer 分别使用了deformable convolution 来增大感受野,具体的效果可以看实验部分。
5 Experiments
-
Dataset:
- COCO数据集
- 所有模型在COCO train2017 split (∼118k images) 被训练
- 所有模型在val2017 (5kimages)被评估
- 最后的结果被记录在test-dev (20k images)
- 实验采用1×训练策略,single scale 训练和测试
-
Training Details :
- 主干网络使用ResNet-50 ,所有 hyper-parameters 和FCOS保持一致
- 使用stochastic gradient descent (SGD) 来优化
- weight decay 0.0001, momentum 0.9 with 90K iterations in all
- 初始learing rate=0.01,并分别在迭代60k和80k时除以10
- 使用16个图像的 mini-batch ,所有模型训练都有8个GPU
- 主干网络初始化使用 ImageNet 的预训练权重,其它新增加层的权重初始化参考《Focal loss for dense object detection》
-
Inference Details:inference process和FCOS一样,为了避免不必要的计算,在进行NMS(the highest scoring 100 samples)之后执行mask reconstruction
5.1.Ablation Study
-
Analysis of Upper Bound

reconstruction error 随着the number of components(N)的增大而而持续减小,甚至在N=100时降低到2.5%。 -
Dimension of Encoding Representation
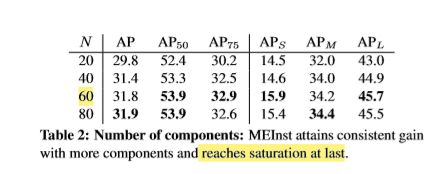
随着N的增大,性能会变好,当N=60达到饱和,实验中N设置为60。 -
Learning without Explicit Encoding
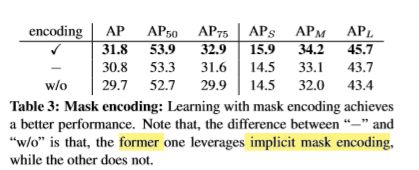
Learning with mask encoding实现更好的性能。 -
Loss Function:

l 2 l_{2} l2 loss的效果比较好,实验中采用的是 l 2 l_{2} l2 loss -
Large Receptive Field

DC(deformableconvolution )的效果比LK( large kernel)好,大的感受野会提升性能。
-
Learning Masks boosts Object Detection

实例mask预测的学习能够提升one-stage detectors的性能。 -
Mask-Based vs. Contour-Based
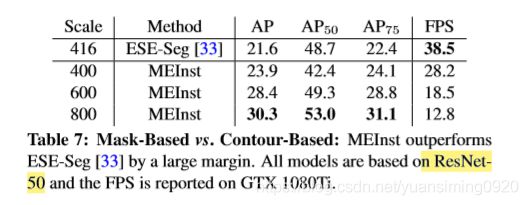

Mask-Based 的方法比Contour-Based 好
5.2.Comparison with State-of-the-art Methods
 结果比大多数one-stage方法好,但是没有TensorMask好,原因有两个:(1) Tensormask使用很长的训练时间(2)使用bipyramid和 aligned representation
结果比大多数one-stage方法好,但是没有TensorMask好,原因有两个:(1) Tensormask使用很长的训练时间(2)使用bipyramid和 aligned representation
这些在本实验中都没有使用。
5.3.Advantages and Limitations

MEInst能更好地处理“ disjointed ”物体。
MEInst检测小物体的效果要比MaskR-CNN好,但是大物体来说效果相对较差,作者分析主要原因如下:
(1)对于小物体来说,single feature vector 在本文工作中是没有问题的,但是 Mask R-CNN要求 mask prediction head 去label每个像素,当物体非常大时就比较困难。
(2)对于大物体来说,compact representation vector表示难以表示mask的所有细节,这种情况下非参数像素标记表现得就比较好。
6 Conclusion
- 提出了一个简单的实例分割框架MEInst,用固定维数和紧凑的向量来表示Mask,并将任务转为回归任务。
- 通过在 one-stage object detectors中添加一个平行的Mask regression分支,解决了一些比较有挑战性的问题。
- 提出的框架在one-stage paradigms中达到了竞争性的精度和速度,在更简单更灵活的情况下达到了和Mask-RCNN相似的性能
- 将来可以探讨使用其它 dictionary learning methods for encoding instance masks的可能性,和and the possibility of applying this idea to other instance recognition tasks.