ubuntu 在docker中搭建深度学习环境
(刚刚发现csdn跳转目录的话在右上角的栏里面)
ubuntu版本:Ubuntu 20.04.2 LTS \n \l
docker版本:Docker version 20.10.5, build 55c4c88
目录
-
- 零.搭建前的话
- 一.首先把安装docker
- 二.准备驱动程序的安装
- 1.宿主机安装gpu驱动
- 2.宿主机禁用Nouveau驱动
- 三.使用docker
- 1.确认宿主机gpu驱动调用成功:
- 2.通过docker拉取镜像
- 3.查看是否成功拉取镜像
- 4.容器搭建测试
- 5.正式通过镜像创建容器
- 6.docker其他操作命令记录
- 7.其他
零.搭建前的话
在大家搭建之前,强烈建议备份好,ubuntu中的资料到移动硬盘,避免失败后有可能引起的图像界面进不去等等,一堆麻烦的情况
确保已为Linux发行版安装了NVIDIA驱动程序和Docker引擎。请 注意,您无需在主机系统上安装CUDA Toolkit,但需要安装NVIDIA驱动程序
tensorflow 关于docker的官方说明
(这里将引用放在前面,是希望同学们放弃在宿主机不装gpu驱动。而只在docker里面装驱动,就能调用gpu的大胆的想法,经过这几天的折腾测试,表示目前不行)
根据资料显示与本人测试(我用的Docker version 20.10.5版本),目前docker大于19版本的,只需要保证宿主机和docker容器内调用的驱动保持一致,就可以了。 docker版本查看命令 docker --version
19版本以下的呢 参考这个博主的点击进入
———————————————————————————————————————————————————————————————————————————————————————————————
一.首先把安装docker
参考这里博客
(如果添加用户组出现
如果提示get …dial unix /var/run/docker.sock权限不够,则修改/var/run/docker.sock权限
如下行)
sudo chmod a+rw /var/run/docker.sock
不然就只能用root权限才能开启docker
——————————————————————————————
附上doker下载源的国内源(虽然后来科学上网下载但是还是感人,pull镜像是个玄学问题)
#1.和上面连接中博主的一样的
{
"registry-mirrors": [
"https://registry.docker-cn.com"
]
}
#2.中科大的
{
"registry-mirrors":["https://docker.mirrors.ustc.edu.cn/"]
}
#其他不知道什么名字的国内镜像源加速站点
https://registry.docker-cn.com
http://hub-mirror.c.163.com
https://3laho3y3.mirror.aliyuncs.com
http://f1361db2.m.daocloud.io
https://mirror.ccs.tencentyun.com
————————————————
1.使用 sudo vim /etc/docker/daemon.json
或者 sudo gedit /etc/docker/daemon.json
修改源为以上任意连接
2.重新启动 docker
sudo systemctl restart docker
3.检查 Docker Hub 是否生效
在命令行执行 sudo docker info ,如果从结果中看到了如下内容,说明配置成功。
Registry Mirrors:
https://docker.mirrors.ustc.edu.cn/
下载还慢得卡死的可以再参考这个博客的阿里的镜像点
———————————————————————————————————————————————————————————————————————————————————————————————
二.准备驱动程序的安装
首先需要说明的是,这里的驱动程序的准备, 对于宿主机我们只需要准备gpu驱动就可以了,不需要cuda和cudnn,
而对于宿主机内部的docker容器,我们需要准和宿主机相同的gpu驱动和 你的深度学习框架 (tensorflow,paddlepaddle),所需要的cuda和cudnn
1.宿主机安装gpu驱动,这里只说最简单的方法
(如果失败了,参考这个博客单独安装驱动的方法点击进入,和下面手动安装驱动的部分进行安装,
以下为检查cuda版本,gpu型号,gpu驱动,cudnn版本的命令,由于我们只需要在宿主机中安装gpu驱动(英伟达驱动),所以需要保证宿主机gpu能正常被检测到(宿主机上安装有别的cudn与cudnn应该是没有关系的,但需要保证gpu能正常运行)
CUDA版本查看
cat /usr/local/cuda/version.txt
#或
nvcc -V
#或
nvcc --version
..............................................................
# 查看显卡型号
lspci | grep -i nvidia
gpu驱动版本查看
cat /proc/driver/nvidia/version
#或
sudo dpkg --list | grep nvidia-*
卸载显卡驱动(未成功)
sudo apt-get autoremove nvidia*
..................................................................
cudnn版本查看
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
1.宿主机安装gpu驱动
首先查看已安装的gpu驱动
#已安装gpu驱动查看
cat /proc/driver/nvidia/version
#或
sudo dpkg --list | grep nvidia-*
如需卸载已安装驱动:
#卸载
sudo apt-get autoremove nvidia*
自动安装新驱动
一.在docker终端输入
ubuntu-drivers devices
如果提示:
bash: ubutnu-drivers: command not found
则安装:
sudo apt-get install ubuntu-drivers-common
#之后会显示显卡信息我的如下
== /sys/devices/pci0000:00/0000:00:01.3/0000:01:00.2/0000:02:06.0/0000:06:00.0 ==
modalias : pci:v000010DEd00001C03sv00001043sd000085DEbc03sc00i00
vendor : NVIDIA Corporation
model : GP106 [GeForce GTX 1060 6GB]
driver : nvidia-driver-390 - distro non-free
driver : nvidia-driver-450-server - distro non-free
driver : nvidia-driver-410 - third-party non-free
== /sys/devices/pci0000:00/0000:00:03.1/0000:08:00.0 ==
modalias : pci:v000010DEd00001024sv000010DEsd00000983bc03sc02i00
vendor : NVIDIA Corporation
model : GK110BGL [Tesla K40c]
driver : nvidia-340 - distro non-free
driver : xserver-xorg-video-nouveau - distro free builtin
这时,可使用以下命令,结合上面显示带推荐驱动名称挑选安装,`如果你挑选自己安装,那么在doker容器中也需要安装相同的驱动`
#例如
apt-get install nvidia-340
你也可以选择,安装所有推荐的驱动,如下命令(有些驱动和无法和cuda连接,建议全安装,免得哪个驱动抽风)
ubuntu-drivers autoinstall
以上自动安装失败了的话,那就需要我们手动安装了
首先在nvidia官方驱动网站下载自己显卡的对应驱动
驱动程序下载链接(根据自己带显卡型号进行选择)
下载成功后通过sh命令进行安装超作
#例如
sh NVIDIA-Linux-x86_64-410.129-diagnostic.run
安装驱动报错处理:
...................................................................
1.若报错(docker容器内操作):
Unable to find the module utility `modprobe`; please make sure you have the package 'module-init-tools' or 'kmod'
installed. If you do have 'module-init-tools' or 'kmod' installed, then please check that `modprobe` is in your
PATH.
使用命令:
apt-get install module-init-tools kmod
.......................................................................
2.若报错
ERROR: The Nouveau kernel driver is currently in use by your system. This driver is incompatible with the NVIDIA driver, and
must be disabled before proceeding. Please consult the NVIDIA driver README and your Linux distribution's
documentation for details on how to correctly disable the Nouveau kernel driver.
这里我们需要对docker中禁用 Nouveau 驱动:见下一步
2.宿主机禁用Nouveau驱动
在之前安装成功nivida显卡驱动后,在ubuntu的 附件驱动如下图。
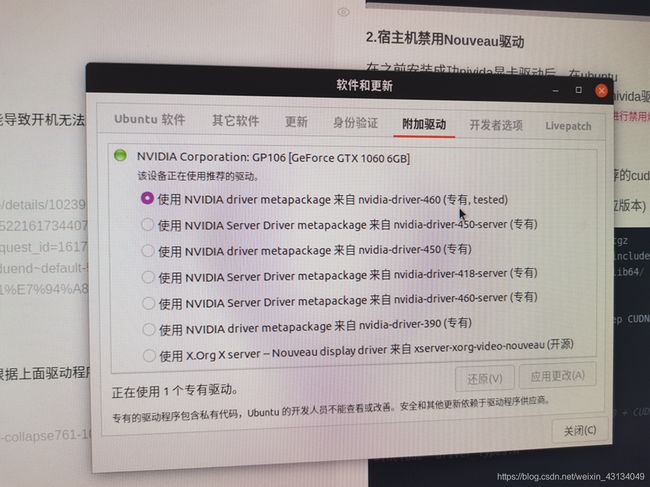
就会显示安装的驱动信息,重启后生效,不过在重启之前我们需要对ubuntu自带的Nouveau驱动进行禁用。
Nouveau驱动会在开机的时候与之前安装的nivida驱动发生冲突,可能导致开机无法显示图像界面,所以请保证nivida驱动安装成功,后才对ubuntu自带的Nouveau进行禁用炒作哈!!!
禁用操作参考这个博主的博客
cuda下载链接 (根据上面驱动程序下载时推荐的cuda toolkit版本进行选择)
cuDNN下载链接(根据cuda的的版本选择对应版本)
tar -xvf cudnn-10.0-linux-x64-v7.6.5.32.tgz
cp cuda/include/cudnn.h /usr/local/cuda/include/
cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
#输入:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
#输出以下说明安装cudnn成功
#define CUDNN_MAJOR 7
#define CUDNN_MINOR 6
#define CUDNN_PATCHLEVEL 5
--
#define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL)
#include "driver_types.h"
******可能用的上的命令
卸载显卡驱动命令
sudo apt-get purge --remove nvidia*
更新软件列表(ubuntu的docker):
apt update
删除目录:
rm -rf nwe1
查看同名名字的进程数量
ps aux|grep kworker|grep -v grep|wc -l
卸载显卡驱动
sudo /usr/bin/nvidia-uninstall
删除cuda
sudo /usr/local/cuda-8.0/bin/uninstall_cuda-8.0.pl
导出镜像为tar
docker save 镜像id(或者镜像名称) > 存储的目标路径/存储的名称.tar
例如:
docker save t1 > home/usr/mysql.tar
导入镜像(注意箭头方向)
docker load < home/usr/mysql.tar
三.使用docker
1.确认宿主机gpu驱动调用成功:
在宿主机下使用以下gup测试命令,成功显示显卡状态信息说明,之前驱动安装工作成功
nvidia-smi
测试失败,可能的原因参考(或在从新做一次步骤二)无法连接NVIDIA驱动:NVIDIA-SMI has failed because it couldn’t communicate with the NVIDIA driver
2.通过docker拉取镜像
注释:拉取速度过慢,可以科学上网,或者参考我在步骤一中给出的软件源连接,多换几个,哪个快用哪个。
官方ubuntu镜像源的介绍连接,大家可以在里面的搜索框中查找自己需要的镜像,然后根据右侧提示的docker pull 镜像的名称,将该镜像加载到宿主机中。
例如以下。tensorflow框架与paddlepaddle框架的镜拉取命令(在宿主机中输入)。
#tensorflow的:
docker pull tensorflow/tensorflow:1.14.0-gpu-py3
#paddlepaddle的:
docker pull paddlepaddle/paddle
3.查看是否成功拉取镜像
当镜像已经拉取(下载)成功了,我们使用 docker images 可以查看到(以下为tensorflow的镜像为例子)
ppx20@hiro:~$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
tensorflow/tensorflow 1.14.0-gpu-py3 a7a1861d2150 21 months ago 3.51GB
其他可能会用上的docker命令
1. 查询已拉取成功的镜像命令:docker images
可以看到所有已经存在的镜像的 ID (IMAGE ID)
2. 查询容器:docker ps -a
可以看到所有容器的 ID (CONTAINER ID)
3. 先删除容器:docker rm 容器ID
4. 再删除镜像:docker rmi 镜像ID
#查看硬盘容量命令 ,可能用的上,如果是硬盘空间不够这个神奇的问题,导致不成功的话就很傻瓜了,请务必好好检查
df -hl
#谐音记忆法: 打飞好了
4.容器搭建测试
在搭建正式的容器前,可先通过以下命令测试镜像(或者docker),能否正确运行,这里还是以tensorflow/tensorflow:1.14.0-gpu-py3的镜像为例子。
成功输出’hello world’,则表明成功。
docker run tensorflow/tensorflow:1.14.0-gpu-py3 echo 'hello world'
docker run 8d7f127d57f5 echo 'hello world'
5.正式通过镜像创建容器
参数说明:构建名为:t3的容器,使用tensorflow/tensorflow:1.14.0-gpu-py3镜像,并运行容器。–restart always 代表如果容器的一号经常死掉,容器会重启,–privileged=true 表示给予容器管理员权限从而有能力调用gpu硬件
以下载的tensorflow镜像创建容器的命令:
sudo docker run --restart always --privileged=true --name t3 -it tensorflow/tensorflow:1.14.0-gpu-py3
当命令成功运行后,系统后自动进入创建的容器内,如下:
ppx20@hiro:~$ sudo docker run --restart always --privileged=true --name t3 -it tensorflow/tensorflow:1.14.0-gpu-py3
[sudo] ppx20 的密码:
________ _______________
___ __/__________________________________ ____/__ /________ __
__ / _ _ \_ __ \_ ___/ __ \_ ___/_ /_ __ /_ __ \_ | /| / /
_ / / __/ / / /(__ )/ /_/ / / _ __/ _ / / /_/ /_ |/ |/ /
/_/ \___//_/ /_//____/ \____//_/ /_/ /_/ \____/____/|__/
WARNING: You are running this container as root, which can cause new files in
mounted volumes to be created as the root user on your host machine.
To avoid this, run the container by specifying your user's userid:
$ docker run -u $(id -u):$(id -g) args...
root@9940e3a2ea9b:/#
6.docker其他操作命令记录
查看已创建的容器命令
docker ps -a
进入容器命令
docker attach 容器名称/或容器id //通过docker ps -a 得到带对应容器的id号
拷贝文件进入docker容器命令
docker cp 文件本地路径 容器长ID:容器路径
(注意容器id后面是,么有空格带, 以下为将home路径下的aa.txt拷贝到容器id为49afc3a516e8的容器,下的new1
目录下,为例):
sudo docker cp home/aa.txt 49afc3a516e8:new1/aa.txt
保存新带镜像命令
docker commit 49afc3a516e8 t3
其中:49afc3a516e8 为对应带容器名称
t3 为新带镜像的名称
镜像打包命令
docker save 镜像名 -o 保存的tar文件名称.tar
例如:
docker save hello -o hello.tar
加载打包的镜像文件命令
docker load < hello.tar
或者
docker load --input hello.tar
7.其他
上传到csdn上的docker官方ubuntu镜像一份
——————————————————————————
可能用的上的cuda安装官方说明命令例子
Installation Instructions:
sudo dpkg -i cuda-repo-ubuntu1804-10-0-local-10.0.130-410.48_1.0-1_amd64.deb
sudo apt-key add /var/cuda-repo-
sudo apt-get update
sudo apt-get install cuda
Other installation options are available in the form of meta-packages. For example, to install all the library packages, replace “cuda” with the “cuda-libraries-10-0” meta package. For more information on all the available meta packages click here.