LDA主题模型的原理及使用教程
这是一个NLP参赛项目的主题分析环节的代码,总体的工程代码已经上传至github,可以直接下载使用。
https://github.com/stay-leave/weibo-public-opinion-analysis
现在将思路分享给大家。
一、原理介绍
LDA主题模型是Blei等人于2003年提出的一种文档主题生成模型,包括文档、主题和词项3个层级结构。LDA常被用于识别语料中潜在的主题信息。
LDA认为第m篇文档的生成方式如下:
1.对每个主题k∈[1,K],生成“主题-词项”分布 φ⃗ k∼Dir(β⃗ );
2.生成文档m的“文档-主题”分布ϑ⃗ m∼Dir(α⃗ );
3.生成文档m的长度Nm∼Poiss(ξ);
4.对文档m中的每个词n∈[1,Nm],生成当前位置的所属主题 zm,n∼Mult(ϑ⃗ m);
5.根据之前生成的主题分布,生成当前位置的词的相应词项 wm,n∼Mult(φ⃗ zm,n)。
因此,我们的工作是要进行逆推导,从若干词项中找出文档的能够代表文档主题的。

二、代码实现
使用Python的开源第三方库Gensim对热搜博文进行LDA主题分析。
1.对文本进行清洗及分词
微博数据的清洗异常复杂,清洗代码如下:
def clean(line):
"""对一个文件的数据进行清洗"""
rep=['【】','【','】','','',
'','','','','❤️','………','','...、、',',,','..','','',
'⚕️','','','','','','','','','','✧٩(ˊωˋ*)و✧','','????','//','','','','',
'(ღ˘⌣˘ღ)','✧\٩(눈౪눈)و//✧','','','',
'','','','','','(ง•̀_•́)ง!','️','',
'','⊙∀⊙!','','【?','+1','','','','','',
'','!!!!','','\(^▽^)/','','','',
'','','','','0371-12345','☕️','','','','','','\U0001f92e\U0001f92e','','+1','','','','➕1',
'','::','','√','x','!!!','','♂️','','','o(^o^)o','mei\u2006sha\u2006shi','','','',
'','关注','……','(((╹д╹;)))','⚠️','Ծ‸Ծ','⛽️','','',
'️','','…','','[]','[',']','→_→','','','"','','ฅ۶•ﻌ•♡','','️',
'','','(ง•̀_•́)ง','','✊','','','','',':','','(*^▽^)/★*☆','','','','','(✪▽✪)','(❁´ω`❁)','1⃣3⃣','(^_^)/','☀️',
'','','','','→_→','','✨','❄️','•','','','','','','⊙∀⊙!','','✌(̿▀̿\u2009̿Ĺ̯̿̿▀̿̿)✌',
'','','','','','','','','♡♪..•͈ᴗ•͈✩‧₊˚','','','','','','','','(✪▽✪)','','','','♂️','','✌️','',' ̄ ̄)σ',
'','','','','✊','','','','','✔️','','','','❤','','','','丨','✅','','ノ','☀','5⃣⏺1⃣0⃣','','','','',
'',
]
pattern_0=re.compile('#.*?#')#在用户名处匹配话题名称
pattern_1=re.compile('【.*?】')#在用户名处匹配话题名称
pattern_2=re.compile('肺炎@([\u4e00-\u9fa5\w\-]+)')#匹配@
pattern_3=re.compile('@([\u4e00-\u9fa5\w\-]+)')#匹配@
#肺炎@环球时报
pattern_4=re.compile(u'[\U00010000-\U0010ffff\uD800-\uDBFF\uDC00-\uDFFF]')#匹配表情
pattern_5=re.compile('(.*?)')#匹配一部分颜文字
pattern_7=re.compile('L.*?的微博视频')
pattern_8=re.compile('(.*?)')
#pattern_9=re.compile(u"\|[\u4e00-\u9fa5]*\|")#匹配中文
line=line.replace('O网页链接','')
line=line.replace('-----','')
line=line.replace('①','')
line=line.replace('②','')
line=line.replace('③','')
line=line.replace('④','')
line=line.replace('>>','')
line=re.sub(pattern_0, '', line,0) #去除话题
line=re.sub(pattern_1, '', line,0) #去除【】
line=re.sub(pattern_2, '', line,0) #去除@
line=re.sub(pattern_3, '', line,0) #去除@
line=re.sub(pattern_4, '', line,0) #去除表情
line=re.sub(pattern_5, '', line,0) #去除一部分颜文字
line=re.sub(pattern_7, '', line,0)
line=re.sub(pattern_8, '', line,0)
line=re.sub(r'\[\S+\]', '', line,0) #去除表情符号
for i in rep:
line=line.replace(i,'')
return line
清洗完了之后,进行文本分词,代码如下:
def seg_sentence(sentence):
sentence = re.sub(u'[0-9\.]+', u'', sentence)
jieba.load_userdict('自建词表.txt')#加载自建词表
#suggest_freq((), tune=True) #修改词频,使其能分出来
#jieba.add_word('知识集成') # 这里是加入用户自定义的词来补充jieba词典
sentence_seged =jieba.cut(sentence.strip(),cut_all=False,use_paddle=10)#默认精确模式
#sentence_seged =jieba.cut_for_search(sentence.strip(),HMM=True)#搜索引擎模式
#keywords =jieba.analyse.extract_tags(sentence, topK=30, withWeight=True, allowPOS=('n', 'v','nr', 'ns'))#关键词模式
#sentence_seged=[item[0] for item in keywords]
stopwords = stopwordslist('停用词表.txt') # 这里加载停用词的路径
synwords=synwordslist('近义词表.txt')#这里加载近义词的路径
outstr = ''
for word in sentence_seged:
if word not in stopwords and word.__len__()>1:
if word != '\t':#判断出不是停用词
if word in synwords.keys():#如果是同义词
word = synwords[word]
outstr += word
outstr += " "
else:
outstr += word
outstr += " "
return outstr
2.加载分词文件,构建词典及向量空间
导入分词文件:
def infile(fliepath):
#输入分词好的TXT,返回train
'''
all=[]
with open(fliepath,'r',encoding='utf-8')as f:
all_1=list(f.readlines())#列表
for i in all_1:#一句
i=i.strip()#去除占位符
if i:
all=all+i.split(' ')
#字典统计词频
dic={}
for key in all:
dic[key]=dic.get(key,0)+1
#print(dic)
#清除词频低的词
all_2=[]#低词频列表
for key,value in dic.items():
if value<=5:
all_2.append(key)
'''
train = []
fp = open(fliepath,'r',encoding='utf8')
for line in fp:
new_line=[]
if len(line)>1:
line = line.strip().split(' ')
for w in line:
w.encode(encoding='utf-8')
new_line.append(w)
if len(new_line)>1:
train.append(new_line)
return train
构建词典及向量空间:
def deal(train):
#输入train,输出词典,texts和向量
id2word = corpora.Dictionary(train) # Create Dictionary
texts = train # Create Corpus
corpus = [id2word.doc2bow(text) for text in texts] # Term Document Frequency
#使用tfidf
tfidf = models.TfidfModel(corpus)
corpus = tfidf[corpus]
id2word.save('tmp/deerwester.dict') #保存词典
corpora.MmCorpus.serialize('tmp/deerwester.mm', corpus)#保存corpus
return id2word,texts,corpus
3.进行LDA分析
这里使用主题一致性指数和困惑度指数来确定合理的主题数目。
def run(corpus_1,id2word_1,num,texts):
#标准LDA算法
lda_model = LdaModel(corpus=corpus_1,
id2word=id2word_1,
num_topics=num,
passes=60,
alpha=(50/num),
eta=0.01,
random_state=42)
# num_topics:主题数目
# passes:训练伦次
# num:每个主题下输出的term的数目
#输出主题
#topic_list = lda_model.print_topics()
#for topic in topic_list:
#print(topic)
# 困惑度
perplex=lda_model.log_perplexity(corpus_1) # a measure of how good the model is. lower the better.
# 一致性
coherence_model_lda = CoherenceModel(model=lda_model, texts=texts, dictionary=id2word_1, coherence='c_v')
coherence_lda = coherence_model_lda.get_coherence()
#print('\n一致性指数: ', coherence_lda) # 越高越好
return lda_model,coherence_lda,perplex
4.输出为可视化格式
def save_visual(lda,corpus,id2word,name):
#保存为HTML
d=pyLDAvis.gensim.prepare(lda, corpus, id2word)
pyLDAvis.save_html(d, name+'.html')#可视化
5.使用暴力搜索来确定合适的主题模型
对于一篇文档,我们使用上面的LDA只能是一次确定一个主题数的模型,无法选择若干主题数间最佳的主题,这里使用暴力搜索,确定最佳模型。
def compute_coherence_values(dictionary, corpus, texts,start, limit, step):
"""
Compute c_v coherence for various number of topics
Parameters:
----------
dictionary : Gensim dictionary
corpus : Gensim corpus
texts : List of input texts
limit : Max num of topics
Returns:
-------
model_list : List of LDA topic models
coherence_values : Coherence values corresponding to the LDA model with respective number of topics
"""
coherence_values = []
perplexs=[]
model_list = []
for num_topic in range(start, limit, step):
#模型
lda_model,coherence_lda,perplex=run(corpus,dictionary,num_topic,texts)
#lda_model = LdaModel(corpus=corpus,num_topics=num_topic,id2word=dictionary,passes=50)
model_list.append(lda_model)
perplexs.append(perplex)#困惑度
#一致性
#coherence_model_lda = CoherenceModel(model=lda_model, texts=texts, dictionary=dictionary, coherence='c_v')
#coherence_lda = coherence_model_lda.get_coherence()
coherence_values.append(coherence_lda)
return model_list, coherence_values,perplexs
展示每个模型的结果:
def show_1(dictionary,corpus,texts,start,limit,step):
#从 5 个主题到 30 个主题,步长为 5 逐次计算一致性,识别最佳主题数
model_list, coherence_values,perplexs = compute_coherence_values(dictionary, corpus,texts, start, limit, step)
#输出一致性结果
n=0
for m, cv in zip(perplexs, coherence_values):
print("主题模型序号数",n,"主题数目",(n+4),"困惑度", round(m, 4), " 主题一致性", round(cv, 4))
n=n+1
#打印折线图
x = list(range(start, limit, step))
#困惑度
plt.plot(x, perplexs)
plt.xlabel("Num Topics")
plt.ylabel("perplex score")
plt.legend(("perplexs"), loc='best')
plt.show()
#一致性
plt.plot(x, coherence_values)
plt.xlabel("Num Topics")
plt.ylabel("Coherence score")
plt.legend(("coherence_values"), loc='best')
plt.show()
return model_list
三、成果展示
主题可视化效果:
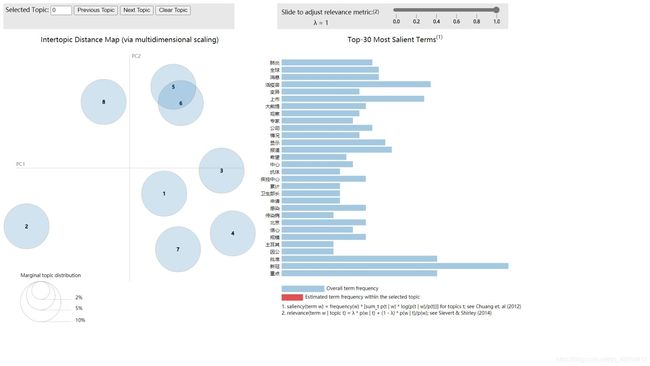 主题关键词输出:
主题关键词输出:
0 0.023*“产能” + 0.017*“适合” + 0.016*“电子” + 0.015*“程序” + 0.015*“调度” + 0.014*“变异” + 0.014*“认购” + 0.013*“佩戴” + 0.013*“产业化” + 0.013*“收入”
1 0.023*“肺炎” + 0.019*“人群” + 0.018*“重点” + 0.018*“冷链” + 0.017*“物品” + 0.016*“社区” + 0.015*“装卸” + 0.015*“北京市” + 0.015*“视频” + 0.015*“工作者”
2 0.024*“几针” + 0.018*“新冠病毒” + 0.017*“疫苗接种” + 0.017*“医疗” + 0.016*“科兴” + 0.015*“上海” + 0.014*“上市” + 0.014*“科主任” + 0.013*“探访” + 0.012*“中上”
3 0.019*“抗体” + 0.019*“感染” + 0.015*“全球” + 0.014*“药物” + 0.014*“介绍” + 0.014*“显示” + 0.014*“联合” + 0.014*“距离” + 0.013*“观察” + 0.013*“民众”
4 0.018*“计划” + 0.016*“包括” + 0.015*“国药” + 0.015*“总统” + 0.015*“英国” + 0.015*“整体” + 0.012*“全市” + 0.012*“时间” + 0.012*“新冠疫苗” + 0.011*“累计”
5 0.026*“临床试验” + 0.023*“免疫” + 0.022*“孕妇” + 0.022*“间隔” + 0.022*“糖尿病” + 0.021*“高血压” + 0.021*“年龄段” + 0.021*“新冠病毒” + 0.021*“妇女” + 0.019*“适合”