标准I/O库
标准 I/O 库则是标准 C 库中用于文件 I/O 操作,通常标准 I/O 库函数相关的函数定义都在头文件
标准 I/O 库函数是构建于文件 I/O(open()、 read()、 write()、 lseek()、 close())这些系统调用之上的,标准 I/O 库函数 fopen()就利用系统调用 open()来执行打开文件的操作、 fread()利用系统调用 read()来执行读文件操作、 fwrite()则利用系统调用 write()来执行写文件操作。
一、FILE指针
当使用标准 I/O 库函数打开或创建一个文件时,会返回一个指向 FILE 类型对象的指针(FILE *) ,使用该 FILE 指针与被打开或创建的文件相关联,然后该 FILE 指针就用于后续的标准 I/O 操作,所以由此可知,FILE 指针的作用相当于文件描述符,FILE 指针用于标准 I/O 库函数中、而文件描述符则用于文件I/O 系统调用中。
FILE 是一个结构体数据类型,它包含了标准 I/O 库函数为管理文件所需要的所有信息,包括用于实际I/O 的文件描述符、指向文件缓冲区的指针、缓冲区的长度、当前缓冲区中的字节数以及出错标志等。 FILE数据结构定义在标准 I/O 库函数头文件 stdio.h 中。
二、文件操作
我们知道标准输入设备指的就是计算机系统的标准的输入设备,通常指的是计算机所连接的键盘;而标准输出设备指的是计算机系统中用于输出标准信息的设备,通常指的是计算机所连接的显示器;标准错误设备则指的是计算机系统中用于显示错误信息的设备,通常也指的是显示器设备。
用户通过标准输入设备与系统进行交互, 进程将从标准输入(stdin)文件中得到输入数据,将正常输出数据(程序中 printf 打印输出的字符串) 输出到标准输出(stdout) 文件,而将错误信(函数调用报错打印的信息)输出到标准错误(stderr) 文件。
每个进程启动之后都会默认打开标准输入、标准输出以及标准错误, 得到三个文件描述符, 即 0、 1、2, 其中 0 代表标准输入、 1 代表标准输出、 2 代表标准错误;在 unistd.h 头文件:
/* Standard file descriptors. */
#define STDIN_FILENO 0 /* Standard input. */
#define STDOUT_FILENO1 /* Standard output. */
#define STDERR_FILENO2 /* Standard error output. */0、 1、 2 这三个是文件描述符,只能用于文件 I/O(read()、 write()等)。那么在标准 I/O 中,自然是无法使用文件描述符来对文件进行 I/O 操作的,它们需要围绕 FILE 类型指针来进行。
在 stdio.h 头文件中:
/* Standard streams. */
extern struct _IO_FILE *stdin; /* Standard input stream. */
extern struct _IO_FILE *stdout; /* Standard output stream. */
extern struct _IO_FILE *stderr; /* Standard error output stream. */
/* C89/C99 say they're macros. Make them happy. */
#define stdin stdin
#define stdout stdout
#define stderr stderrstruct _IO_FILE 结构体就是 FILE 结构体,使用了 typedef 进行了重命名。在标准 I/O 中,可以使用 stdin、 stdout、 stderr 来表示标准输入、标准输出和标准错误。
1.fopen()
使用库函数fopen()打开或创建文件
#include
FILE *fopen(const char *path, const char *mode); path: 参数 path 指向文件路径,可以是绝对路径、相对路径
mode: 参数 mode 指定了对该文件的读写权限返回值: 调用成功返回一个指向 FILE 类型对象的指针(FILE *),该指针与打开或创建的文件相关联,后续的标准 I/O 操作将围绕 FILE 指针进行。 如果失败则返回 NULL,并设置 errno 以指示错误原因
mode字符串
| mode | 说明 | 对应文件I/O:flags |
| r | 以只读方式打开文件 |
O_RDONLY |
| r+ |
以可读、可写方式打开文件 |
O_RDWR |
| w | 以只写方式打开文件,如果参数 path 指定的文件存在,将文件长度截断为 0;如果指定文件不存在 则创建该文件 |
O_WRONLY | O_CREAT | O_TRUNC |
| w+ | 以可读、可写方式打开文件,如果参数 path 指定的文件存在,将文件长度截断为 0;如果指定文件不存在则创建该文件 |
O_RDWR | O_CREAT | O_TRUNC |
| a | 以只写方式打开文件,打开以进行追加内容(在文件末尾写入),如果文件不存在则创建该文件 |
O_WRONLY | O_CREAT | O_APPEND |
| a+ | 以可读、可写方式打开文件,以追加方式写入 (在文件末尾写入),如果文件不存在则创建该文件 |
O_RDWR | O_CREAT | O_APPEND |
注意:在文件I/O中,新建文件需要传入第三个参数:文件权限。但是这里当参数 mode 取为"w"、 "w+"、 "a"、 "a+"之一时,如果参数 path 指定的文件不存在,则会创建该文件,那么新的文件的权限是默认的:
S_IRUSR | S_IWUSR | S_IRGRP | S_IWGRP | S_IROTH | S_IWOTH (0666)
2.fclose()
调用 fclose()库函数可以关闭一个由 fopen()打开的文件
#include
int fclose(FILE *stream); 参数 stream 为 FILE 类型指针,调用成功返回 0;失败将返回 EOF,并且会设置 errno 来指示错误原因
3.fread() / fwrite()
使用 fread()和 fwrite()库函数对文件进行读、写操作
#include
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream); 读:
ptr: 将读取到的数据存放在参数 ptr 指向的缓冲区中
size:从文件读取 nmemb 个数据项,每一个数据项的大小为 size 个字节,所以总共读取的数据大小为 nmemb * size 个字节
nmemb: 参数 nmemb 指定了读取数据项的个数
stream: FILE 指针
返回值: 调用成功时返回读取到的数据项的数目
写:
ptr:指向的缓冲区中的数据写入到文件中
size: 指定了每个数据项的字节大小
nmemb: 参数 nmemb 指定了写入的数据项个数
stream: FILE 指针返回值: 调用成功时返回写入的数据项的数目
注意:库函数 fread()、 fwrite()中指定读取或写入数据大小的方式与系统调用 read()、 write()不同,前者通过 nmemb(数据项个数) *size(每个数据项的大小)的方式来指定数据大小,而后者则直接通过一个 size 参数指定数据大小。
将一个 struct mystr 结构体数据写入到文件中:
1:fwrite(buf, sizeof(struct mystr), 1, file);
2:fwrite(buf, 1, sizeof(struct mystr), file);
4.fseek()
设置文件读写位置偏移量, lseek()用于文件 I/O,而库函数 fseek()则用于标准 I/O
#include
int fseek(FILE *stream, long offset, int whence); stream: FILE指针
offset: 偏移量,以字节为单位
whence: 用于定义参数 offset 偏移量对应的参考值,如下:1.SEEK_SET:读写偏移量将指向 offset 字节位置处(从文件头部开始算)
2.SEEK_CUR:读写偏移量将指向当前位置偏移量 + offset 字节位置处,
3.SEEK_END:读写偏移量将指向 文件末尾 + offset 字节位置处
返回值:成功返回0
将文件的读写位置移动到文件开头处:
fseek(file, 0, SEEK_SET);
将文件的读写位置移动到文件末尾:
fseek(file, 0, SEEK_END);
将文件的读写位置移动距离文件末尾4个字节:fseek(file, -4, SEEK_END);
将文件的读写位置移动到 100 个字节偏移量处
fseek(file, 100, SEEK_SET);
5.ftell()
库函数 ftell()可用于获取文件当前的读写位置偏移量
#include
long ftell(FILE *stream); 6.feof()
调用 fread()读取数据时,如果返回值小于参数 nmemb 所指定的值,表示发生了错误或者已经到了文件末尾(文件结束 end-of-file),但 fread()无法具体确定是哪一种情况; 在这种情况下,可以通过判断错误标志或 end-of-file 标志来确定具体的情况。
库函数 feof()用于测试参数 stream 所指文件的 end-of-file 标志,如果 end-of-file 标志被设置,则调用feof()函数将返回一个非零值,如果 end-of-file 标志没有被设置,则返回 0。
#include
int feof(FILE *stream); 当文件的读写位置移动到了文件末尾时, end-of-file 标志将会被设置。
使用示例:
if (feof(file))
{
/* 到达文件末尾 */
}
else
{
/* 未到达文件末尾 */
}
7.ferror()
库函数 ferror()用于测试参数 stream 所指文件的错误标志,如果错误标志被设置,则调用 ferror()函数将返回一个非零值,如果错误标志没有被设置,则返回 0
#include
int ferror(FILE *stream); 当对文件的 I/O 操作发生错误时,错误标志将会被设置
if (ferror(file))
{
/* 发生错误 */
}
else
{
/* 未发生错误 */
}8.clearerr()
库函数 clearerr()用于清除 end-of-file 标志和错误标志,当调用 feof()或 ferror()校验这些标志后,通常需要清除这些标志,避免下次校验时使用到的是上一次设置的值,此时可以手动调用clearerr()函数清除标志
#include
void clearerr(FILE *stream);
三、格式化I/O
在C语言中,我们知道printf()函数可将格式化数据写入到标准输出,所以通常称为格式化输出。除了 printf()之外,格式化输出还包括: fprintf()、dprintf()、 sprintf()、 snprintf()这 4 个库函数。
对应的也有格式化输入,从标准输入中获取格式化数据,格式化输入包括: scanf()、fscanf()、 sscanf()这三个库函数。
1.格式化输出
C 库函数提供了 5 个格式化输出函数,包括: printf()、 fprintf()、 dprintf()、 sprintf()、snprintf()。
#include
int printf(const char *format, ...);
int fprintf(FILE *stream, const char *format, ...);
int dprintf(int fd, const char *format, ...);
int sprintf(char *buf, const char *format, ...);
int snprintf(char *buf, size_t size, const char *format, ...); 5 个函数都是可变参函数,它们都有参数 format,这是一个字符串,称为格式控制字符串,用于指定后续的参数如何进行格式转换。
printf()函数用于将格式化数据写入到标准输出,即显示终端
fprintf()函数用于将格式化数据写入到指定的文件中,使用 FILE 指针指定对应的文件
dprintf()函数用于将格式化数据写入到指定的文件中,使用文件描述符 fd 指定对应的文件
sprintf()、 snprintf()函数可将格式化的数据存储在用户指定的缓冲区 buf 中。
sprintf()函数可能会发生缓冲区溢出的问题,存在安全隐患。 snprintf()函数使用参数 size 显式的指定缓冲区的大小,如果写入到缓冲区的字节数大于参数 size 指定的大小,超出的部分将会被弃,如果缓冲区空间足够大, snprintf()函数就会返回写入到缓冲区的字符数。两者会在字符串末尾自动添加终止字符'\0'。
格式控制字符串 format:格式控制字符串由两部分组成:普通字符(非%字符) 和转换说明。
普通字符会进行原样输出,每个转换说明都会对应后续的一个参数,通常有几个转换说明就需要提供几个参数(除固定参数之外的参数)。
每个转换说明都是以%字符开头:%[flags][width][.precision][length]type
flags: 标志,可包含 0 个或多个标志;
width: 输出最小宽度,表示转换后输出字符串的最小宽度;
precision: 精度,前面有一个点号" . ";
length: 长度修饰符;
type: 转换类型,指定待转换数据的类型:d, f, lf, ld, x,s
注:%和 type 字段是必须的
2.格式化输入
C 库函数提供了 3 个格式化输入函数,包括: scanf()、 fscanf()、 sscanf()
#include
int scanf(const char *format, ...);
int fscanf(FILE *stream, const char *format, ...);
int sscanf(const char *str, const char *format, ...); scanf()函数可将用户输入(标准输入)的数据进行格式化转换
fscanf()函数从 FILE 指针指定文件中读取数据,并将数据进行格式化转换
sscanf()函数从参数 str 所指向的字符串中读取数据,并将数据进行格式化转换
格式控制字符串 format: format 字符串包含一个或多个转换说明,每一个转换说明都是以百分号"%"或者"%n$"开头。
以%百分号开头的转换说明一般格式:
%[*][width][length]type
%[m][width][length]type
%后面可选择性添加星号*或字母 m,如果添加了星号*,格式化输入函数会按照转换说明的指示读取输入,但是丢弃输入,不需要对转换后的结果进行存储,所以也就不需要提供相应的指针参数。
如果添加了 m,它只能与%s、 %c 以及%[一起使用,调用者无需分配相应的缓冲区来保存格式转换后的数据,原因在于添加了 m,这些格式化输入函数内部会自动分配足够大小的缓冲区,并将缓冲区的地址值通过与该格式转换相对应的指针参数返回出来,该指针参数应该是指向 char *变量的指针。
四、I/O缓冲
出于速度和效率的考虑,系统 I/O 调用(即文件 I/O, open、 read、 write )和标准 C 语言库 I/O 函数(即标准 I/O 函数)在操作磁盘文件时会对数据进行缓冲。
1.内核缓冲
read()和 write()系统调用在进行文件读写操作并不会直接访问磁盘设备,而是仅仅在用户空间缓冲区和内核缓冲区(kernel buffer cache)之间复制数据。
调用 write()函数将 5 个字节数据从用户空间内存拷贝到内核空间的缓冲区中
write(fd, "Hello", 5); //写入 5 个字节数据
调用 write()只是将这 5 个字节数据拷贝到内核空间的缓冲区中,拷贝完成后函数就返回。然后在后面的某个时刻,内核会将其缓冲区中的数据写入(刷新)到磁盘设备中,系统调用 write()与磁盘操作并不是同步的, write()函数并不会等待数据真正写入到磁盘之后再返回。注意这个时刻我们无法确定,由内核根据相应的存储算法自动判断。
如果在此期间, 其它进程调用 read()函数读取该文件的这几个字节数据,那么内核将自动从缓冲区中读取这几个字节数据返回给应用程序。
对于读文件,内核会从磁盘设备中读取文件的数据并存储到内核的缓冲区中,当调用 read()函数读取数据时, read()调用将从内核缓冲区中读取数据,直至把缓冲区中的数据读完。内核会将文件的下一段内容读入到内核缓冲区中进行缓存。
优点:为了提高文件 I/O 的速度和效率,使得系统调用 read()、 write()的操作更为快速,不需要等待磁盘操作,磁盘操作通常是比较缓慢的。
由于文件I/O内核缓冲区的数据写入到磁盘的时间我们无法确定,有时需要强制写入磁盘。当在 Ubuntu 系统下拷贝文件到 U 盘时,文件拷贝完成之后,通常在拔掉 U 盘之前,需要执行 sync 命令进行同步操作,这个同步操作就是将文件 I/O 内核缓冲区中的数据更新到 U 盘硬件设备,所以如果在没有执行 sync 命令时拔掉 U 盘,很可能就会导致拷贝到 U 盘中的文件遭到破坏。
2.文件I/O内核缓冲系统调用
Linux 中提供了一些系统调用可用于控制文件 I/O 内核缓冲,包括系统调用 sync()、 syncfs()、 fsync()以及 fdatasync()。
2.1 fsync()
系统调用 fsync()将参数 fd 所指文件的内容数据和元数据写入磁盘, 只有在对磁盘设备的写入操作完成之后, fsync()函数才会返回。
#include
int fsync(int fd); 注意:元数据并不是文件内容本身的数据,而是一些用于记录文件属性相关的数据信息,如文件大小、时间戳、权限。
2.2 fdatasync()
统调用 fdatasync()与 fsync()类似,不同之处在于 fdatasync()仅将参数 fd 所指文件的内容数据写入磁盘,并不包括文件的元数据;只有在对磁盘设备的写入操作完成之后, fdatasync()函数才会返回。
#include
int fdatasync(int fd); 2.3 sync
系统调用 sync()会将所有文件 I/O 内核缓冲区中的文件内容数据和元数据全部更新到磁盘设备中,该函数没有参数、也无返回值.它不是对某一个指定的文件进行数据更新,而是刷新所有文件 I/O 内核缓冲区。
#include
void sync(void); 在 Linux实现中,调用 sync()函数在所有数据已经写入到磁盘设备之后才会返回;然后在其它系统中,sync()实现只是简单调度一下 I/O 传递,在动作未完成之后即可返回。
控制文件 I/O 内核缓冲的标志
O_DSYNC 标志 :在每个 write()调用之后调用 fdatasync()函数进行数据同步
O_SYNC 标志: 每个 write()调用都会自动将文件内容数据和元数据刷新到磁盘设备中,其效果类似于在每个 write()调用之后调用 fsync()函数进行数据同步
fd = open(filepath, O_WRONLY | O_DSYNC);fd = open(filepath, O_WRONLY | O_SYNC);
3.直接I/O:越过内核缓冲
从 Linux 内核 2.4 版本开始, Linux 允许应用程序在执行文件 I/O 操作时绕过内核缓冲区,从用户空间直接将数据传递到文件或磁盘设备,把这种操作也称为直接 I/O(direct I/O)或裸 I/O(raw I/O)。
对某一文件或块设备执行直接 I/O,只需要在调用 open()函数打开文件时,指定O_DIRECT 标志
fd = open(filepath, O_WRONLY | O_DIRECT);
直接 I/O 的对齐限制
(1)应用程序中用于存放数据的缓冲区,其内存起始地址必须以块大小的整数倍进行对齐(2)写文件时,文件的位置偏移量必须是块大小的整数倍
(3)写入到文件的数据大小必须是块大小的整数倍
定义一个用于存放数据的 buf,起始地址以 4096 字节进行对齐:
static char buf[8192] __attribute((aligned (4096)));
__attribute 是 gcc 支持的一种机制(也可以写成__attribute__),可用于设置函数属性、变量属性以及类型属性
如果不满足以上任何一个要求,调用 write()均为以错误返回 Invalid argument。块大小指的是磁盘设备的物理块大小(block size) ,常见的块大小包括 512 字节、 1024 字节、 2048 以及 4096 字节。
命令查看根文件系统所挂载的磁盘分区:df -h
磁盘分区的块大小:tune2fs -l /dev/sda1 | grep "Block size"
直接 I/O 方式每次 write()调用均是直接对磁盘发起了写操作,而普通方式只是将用户空间下的数据拷贝到了文件 I/O 内核缓冲区中,并没直接操作硬件,所以消耗的时间短,硬件操作占用的时间远比内存复制占用的时间大得多直接 I/O 方式效率、性能比较低,绝大部分应用程序不会使用直接 I/O 方式对文件进行 I/O 操作,通常只在一些特殊的应用场合下才可能会使用。
4.stdio缓冲
标准 I/O(fopen、 fread、 fwrite、 fclose、 fseek 等)是 C 语言标准库函数, 而文件 I/O(open、 read、 write、close、 lseek 等)是系统调用,虽然标准 I/O 是在文件 I/O 基础上进行封装而实现, 但在效率、性能上标准 I/O 要优于文件 I/O,其原因在于标准 I/O 实现维护了自己的缓冲区, 即 stdio 缓冲区。
文件 I/O 内核缓冲,由内核维护的缓冲区,而标准 I/O 所维护的 stdio 缓冲是用户空间的缓冲区,当应用程序中通过标准 I/O 操作磁盘文件时,为了减少调用系统调用的次数,标准 I/O 函数会将用户写入或读取文件的数据缓存在 stdio 缓冲区,然后再一次性将 stdio 缓冲区中缓存的数据通过调用系统调用 I/O(文件 I/O)写入到文件 I/O 内核缓冲区或者拷贝到应用程序的 buf 中。通过这样的优化操作,当操作磁盘文件时,在用户空间缓存大块数据以减少调用系统调用的次数,使得效率、性能得到优化。
4.1 setvbuf()
调用 setvbuf()库函数可以对文件的 stdio 缓冲区进行设置,如缓冲区的缓冲模式、 缓冲区的大小、起始地址。
#include
int setvbuf(FILE *stream, char *buf, int mode, size_t size); stream: FILE 指针,用于指定对应的文件, 每一个文件都可以设置它对应的 stdio 缓冲区
buf: 如果参数 buf 不为 NULL, buf 指向 size 大小的内存区域将作为该文件的 stdio 缓冲区;如果 buf 等于 NULL, stdio 库会自动分配一块空间作为该文件的 stdio 缓冲区(除非参数 mode 配置为非缓冲模式)
mode: 用于指定缓冲区的缓冲类型
(1)IONBF: 不对 I/O 进行缓冲(无缓冲)
(2)_IOLBF: 采用行缓冲 I/O,当在输入或输出中遇到换行符"\n"时,标准 I/O 才会执行文件 I/O 操作
(3)_IOFBF: 采用全缓冲 I/O,在填满 stdio 缓冲区后才进行文件 I/O 操作
size: 指定缓冲区的大小
注:当 stdio 缓冲区中的数据被刷入到内核缓冲区或被读取之后,数据就不会存在于缓冲区中,数据被刷入内核缓冲区或被读走。
4.2 setbuf()
#include
void setbuf(FILE *stream, char *buf); setbuf()函数和 setvbuf()一样,setbuf()调用除了不返回函数结果,就相当于
setvbuf(stream, buf, buf ? _IOFBF : _IONBF, BUFSIZ);
要么将 buf 设置为 NULL 以表示无缓冲,要么指向由调用者分配的 BUFSIZ 个字节大小的缓冲区
(BUFSIZ 定义于头文件
4.3 setbuffer()
setbuffer()函数类似于 setbuf(),但允许调用者指定 buf 缓冲区的大小。
#include
void setbuffer(FILE *stream, char *buf, size_t size); 4.4 fflush()
在任何时候都可以使用库函数 fflush()来强制刷新(将输出到 stdio 缓冲区中的数据写入到内核缓冲区,通过 write()函数) stdio 缓冲区。
#include
int fflush(FILE *stream)
5.文件描述符与 FILE 指针互转
在应用程序中,在同一个文件上执行 I/O 操作时,还可以将文件 I/O(系统调用 I/O)与标准 I/O 混合使用。将文件描述符和 FILE 指针对象之间进行转换,此时可以借助于库函数 fdopen()、fileno()来完成。
#include
int fileno(FILE *stream);
FILE *fdopen(int fd, const char *mode); 库函数 fileno()可以将标准 I/O 中使用的 FILE 指针转换为文件 I/O 中所使用的文件描述符;fdopen()则将文件I/O的文件描述符转化为FILE指针。
总结
标准 I/O 和文件 I/O 的区别:
(1)标准 I/O 和文件 I/O 都是 C 语言函数,但标准 I/O 是标准 C 库函数,而文件 I/O 是 Linux
系统调用(2)标准 I/O 是由文件 I/O 封装而来,标准 I/O 内部是调用文件 I/O 来完成操作
(3)可移植性:标准 I/O 相比于文件 I/O 具有更好的可移植性
(4)性能、效率: 标准 I/O 库在用户空间维护了stdio 缓冲区, 标准 I/O 是带有缓存的,而
文件 I/O 在用户空间是不带有缓存的,所以在性能、效率上,标准 I/O 要优于文件 I/O
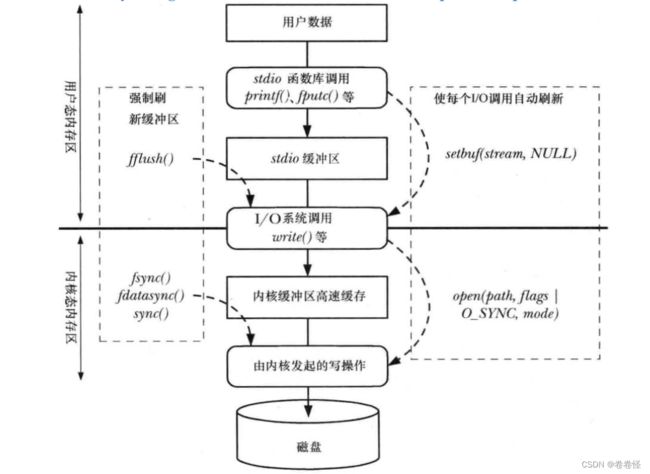
(1)首先应用程序调用标准 I/O 库函数将用户数据写入到 stdio 缓冲区中, stdio 缓冲区是由 stdio 库所维护的用户空间缓冲区。
(2)针对不同的缓冲模式,当满足条件时, stdio 库会调用文件 I/O(系统调用 I/O)将 stdio 缓冲区中缓存的数据写入到内核缓冲区中,内核缓冲区位于内核空间。
(3)最终由内核向磁盘设备发起读写操作,将内核缓冲区中的数据写入到磁盘(或者从磁盘设备读取数据到内核缓冲区)
应用程序调用库函数可以对 stdio 缓冲区进行相应的设置,设置缓冲区缓冲模式、缓冲区大小以及由调用者指定一块空间作为 stdio 缓冲区,并且可以强制调用 fflush()函数刷新缓冲区
而对于内核缓冲区来说,应用程序可以调用相关系统调用对内核缓冲区进行控制,如调用fsync()、 fdatasync()或 sync()来刷新内核缓冲区(或通过 open 指定 O_SYNC 或 O_DSYNC 标志),或者使用直接 I/O 绕过内核缓冲区(open 函数指定 O_DIRECT 标志)