iterrows(),iteritems(),itertuples()区别
Python函数之iterrows, iteritems, itertuples对dataframe进行遍历
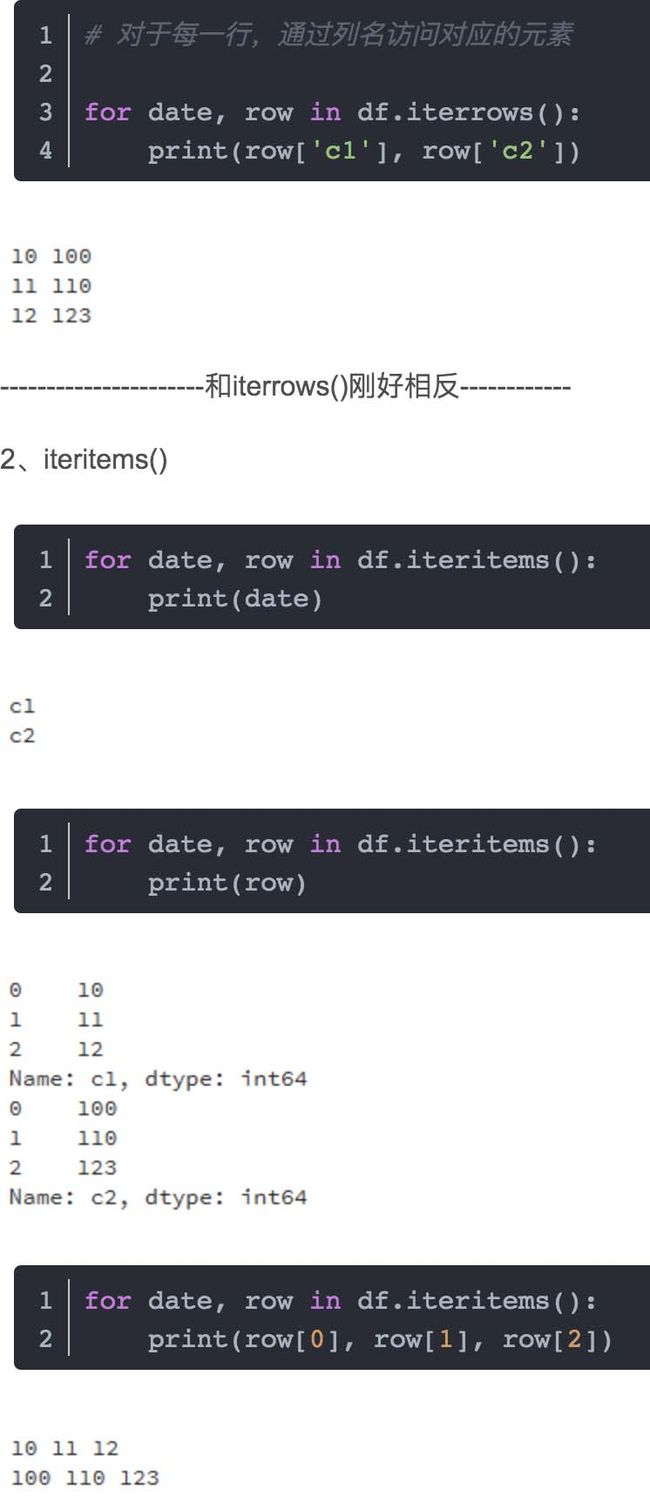
iterrows(): 将DataFrame迭代为(insex, Series)对。iteritems(): 将DataFrame迭代为(列名, Series)对itertuples(): 将DataFrame迭代为元祖。


DataFrame数据遍历方式 iteritems iterrows itertuples
对Pandas对象进行基本迭代的行为取决于类型。在遍历一个Series时,它被视为类似数组,并且基本迭代产生这些值。其他数据结构(如DataFrame和Panel)遵循类似于字典的惯例,即迭代对象的 键 。
总之,基本的迭代产生
Series- 值DataFrame- 列标签Panel- 项目标签
迭代DataFrame
迭代DataFrame会给出列名称。让我们考虑下面的例子来理解相同的情况。
import pandas as pd
import numpy as np
N=20
df = pd.DataFrame({
'A': pd.date_range(start='2021-01-01',periods=N,freq='D'),
'x': np.linspace(0,stop=N-1,num=N),
'y': np.random.rand(N),
'C': np.random.choice(['Low','Medium','High'],N).tolist(),
'D': np.random.normal(100, 10, size=(N)).tolist()
})
for col in df:
print(col)
其 输出 如下
A
C
D
x
y
要迭代DataFrame的行,我们可以使用以下函数 -
iteritems()- 遍历(键,值)对iterrows()- 遍历行(索引,序列)对itertuples()- 遍历 行为namedtuples
iteritems()
将每列作为关键字值进行迭代,并将标签作为键和列值作为Series对象进行迭代。
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(4,3),columns=['col1','col2','col3']) for key,value in df.iteritems(): print(key,value)
其 输出 如下 :
col1 0 0.265778
1 -0.814620
2 -2.384911
3 0.525155
Name: col1, dtype: float64
col2 0 2.580894
1 -0.408090
2 0.641011
3 0.591557
Name: col2, dtype: float64
col3 0 -0.830860
1 0.413565
2 -2.251128
3 -0.392120
Name: col3, dtype: float64
请注意,每个列在Series中作为键值对单独迭代。
iterrows()
iterrows()返回产生每个索引值的迭代器以及包含每行数据的序列。
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(4,3),columns = ['col1','col2','col3']) for row_index,row in df.iterrows(): print(row_index,row)
其 输出 如下
0 col1 -0.536180
col2 -0.422245
col3 -0.049302
Name: 0, dtype: float64
1 col1 -0.577882
col2 0.546570
col3 1.210293
Name: 1, dtype: float64
2 col1 0.593660
col2 0.621967
col3 0.456040
Name: 2, dtype: float64
3 col1 0.874323
col2 0.303070
col3 -0.107727
Name: 3, dtype: float64
注 - 由于 iterrows() 遍历行,因此它不会保留行中的数据类型。0,1,2是行索引,col1,col2,col3是列索引。
itertuples()
itertuples()方法将返回一个迭代器,为DataFrame中的每一行生成一个命名的元组。元组的第一个元素将是行的相应索引值,而其余值是行值。
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(4,3),columns = ['col1','col2','col3']) for row in df.itertuples(): print(row)
其 输出 如下
Pandas(Index=0, col1=-0.4029137277161786, col2=1.3034737750584355, col3=0.8197109653411052)
Pandas(Index=1, col1=-0.43013422882386704, col2=-0.2536252662252256, col3=0.9102527012477817)
Pandas(Index=2, col1=0.25877683462048057, col2=-0.7725072659033637, col3=-0.013946376730006241)
Pandas(Index=3, col1=0.3611368595844501, col2=-0.2777909818571997, col3=0.9396027945103758)
注 : 不要在迭代时尝试修改任何对象。 迭代是为了读取而迭代器返回原始对象(视图)的副本,因此这些更改不会反映到原始对象上。
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(4,3),columns = ['col1','col2','col3']) for index, row in df.iterrows(): row['a'] = 10 print(df)
其 输出 如下
col1 col2 col3
0 0.579118 0.444899 -0.693009
1 0.479294 0.080658 -0.126600
2 0.095121 -1.870492 0.596165
3 1.885483 -0.122502 -1.531169
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。