6个实用的python脚本
文章目录
-
- 前置知识
- 1.监控CPU idle
- 2.监控空闲内存
- 3.监控磁盘用量
- 4.第三方库自动安装脚本
- 5.统计nginx日志访问量前十ip,并用柱状图显示
- 6.爬取网页图片到本地
- 参考
前置知识
- os.popen()方法能够打开管道,获取一条命令的输出信息
1~3都是三个监控脚本,分别监控CPU、内存和磁盘,超过或低于阈值就邮件告警
脚本的思路都是类似的:
- 使用 os.popen()方法获取一条命令的输出信息
- 提取出要检测的值
- if条件判断,和阈值比较,超过或低于就邮件告警;否则pass不执行任何操作
1.监控CPU idle
#!/usr/bin/python3
# coding:utf-8
# CPU idle少于20%,发邮件
import os
f = os.popen('vmstat').readlines()
# vmstat查看进程、内存、CPU、IO等信息
# popen打开管道,获取命令输出;readlines读取文件所有行,以每行为元素生成列表
cpu_idle = str(f).split()[-3]
# 把字符串列表转为一个长字符串;split()方法以默认空格分隔符将其分割为列表;列表倒数第三个元素就是CPU_idle
if int(cpu_idle) < 20:
mail_content = "echo 'ip:192.168.211.140(vmstat)' | mail -s '[Warning!] CPU idle below 20%, please check!' root"
os.popen(mail_content)
else:
pass
# 如果cpu_idle即cpu空闲率低于20%,就给root发邮件告警;否则,pass不采取任何操作
2.监控空闲内存
#!/bin/python3
# coding: utf-8
# 检测空闲内存,低于200M就发邮件
import os
f = os.popen("free -m").readlines()
free_mem = f[1].split()[3]
if int(free_mem) < 200:
mail_cmd = "echo '[Warning!]MEM below 200M, please check!' | mail -s 'alarm message from 100.' root"
os.popen(mail_cmd)
else:
pass
3.监控磁盘用量
#!/bin/python3
# coding:utf-8
# 监控磁盘空间,大于阈值就邮件报警
import os
th = input('输入磁盘用量阈值:')
f = os.popen("df -h").readlines() # popen在这里获取命令输出
ls = f[1:] # 删除第一个元素,即df输出的第一行
for i in ls: # 遍历每一行
perc = i.split()[-2] # 取磁盘用量值,百分数
num = perc[:-1] # 删除%
if int(num) > int(th): # 判断
mail_cmd = "echo 'disk_usage > {}%' | mail -s 'a alarm meseage from python monitor' root".format(th)
os.popen(mail_cmd)
else:
pass
4.第三方库自动安装脚本
使用前先准备一个文本文件:第三方库批量下载配置文件.txt,内容为要下载的第三方库。这里的内容为:numpy, matplotlib, pillow, sklearn, requests, jieba,beautifulsoup4,wheel, networkx, sympy,pyinstaller, django, flask, werobot, pyqt5, pandas,pyopeng1, pypdf2, docopt, pygame
# BatchInstall.py
import os
f = open("E:\\python_file\\第三方库批量下载配置文件.txt", "r")
txtStr = f.read()
libs = txtStr.split(",")
f.close()
try:
for lib in libs:
os.system("pip install " + lib)
print("Successful")
except:
print("Failed Somehow")
5.统计nginx日志访问量前十ip,并用柱状图显示
#!/usr/bin/python3
# 统计nginx访问量前10的ip,并以柱状图显示
import matplotlib.pyplot as plt
nginxFile = '/usr/local/nginx/logs/20210216_access.log'
ip = {} # 创建空字典
with open(nginxFile) as f:
for line in f.readlines():
s = line.strip().split()[0] # 去除每行换行符,取第一个字段即访问ip
length = len(ip.keys())
# 统计每个ip访问量,以字典存储
if s in ip.keys():
ip[s] = ip[s] + 1
else:
ip[s] = 1
# 以ip出现次数排序,返回list
ip = sorted(ip.items(), key=lambda e:e[1], reverse=True) # 让字典中的键值对按值的大小从大到小排序
# 取列表前10,转为字典
ip10 = dict(ip[0:10])
# 绘图
x = []
y = []
for k in ip10:
x.append(k)
y.append(ip10[k])
# 显示每个柱状图的值
for a,b in zip(x,y):
plt.text(a, b, '%.0f' % b, ha='center', va='bottom', fontsize=8)
plt.bar(x,y,label='remote_addr access')
plt.title('Nginx Access Statistics')
plt.xlabel('ip address')
plt.ylabel('PV')
plt.legend()
plt.show()
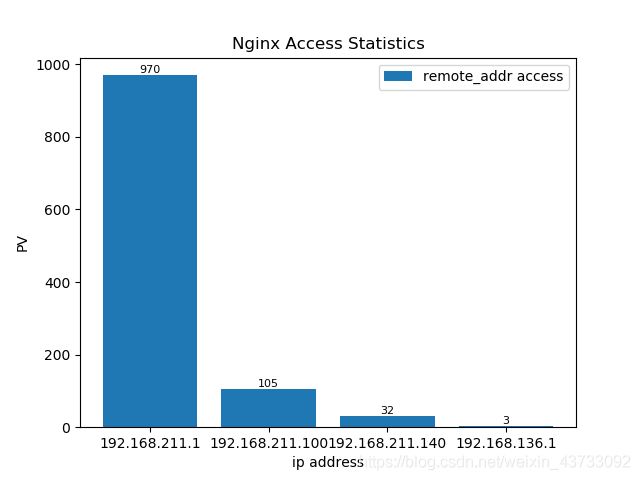
效果
6.爬取网页图片到本地
思路:
- 首先用urllib库模拟浏览器访问网站的行为,由指定url得到对应html源代码;源代码以字符串的形式返回
- 然后用正则表达式re库在源代码中匹配图片链接的小字符串,返回一个图片url列表
- 最后遍历url列表,使用urlretrieve()函数根据图片链接将图片保存到本地
这里以爬取豆瓣电影top250中的电影图片为例:
'''
一个简单的爬取图片程序,使用urllib和re库
'''
import urllib.request
import re
def get_html_code(url): # 传入url,获取url的html源代码
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'
}
# 模拟64位windows的edge浏览器访问
request = urllib.request.Request(url, headers=headers) # Request()函数将url添加到头部
page = urllib.request.urlopen(request).read() # 将url页面的源代码保存成字符串
page = page.decode('UTF-8') # 字符串转码
return page
def get_img(page): # 由html源代码获取图片url,将图片下载到本地
imgList = re.findall(r'http.+\.jpg', page)
# re.findall(pattern,string,flags=0)搜索字符串,以列表返回全部匹配的子串
print(imgList)
x = 0
for imgUrl in imgList: # 遍历url列表
try:
print('正在下载:{}'.format(imgUrl))
# urlretrieve(url,local)方法根据图片url把图片下载到本地
urllib.request.urlretrieve(imgUrl, 'E:/img/%d.png'%x)
x += 1
except:
continue
if __name__ == '__main__':
url = 'https://movie.douban.com/top250' # 豆瓣电影 Top 250的url
page = get_html_code(url)
get_img(page)
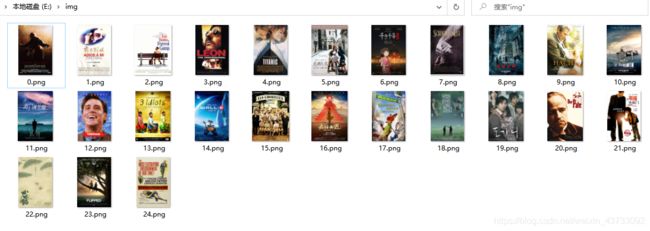
效果
参考
Python爬虫(三):python抓取网页中的图片到本地
re库最全使用教程(正则表达式详解)
Python运维常用的脚本,提高工作效率就靠它了