机器学习/深度学习-学习笔记:概念补充(下)
学习时间:2022.05.12
概念补充(下)
在进行学习机器学习和深度学习的过程中,对于部分概念会比较陌生(可能是因为没有系统深入学习过统计学、运筹学和概率统计的相关知识;也可能是因为看的东西比较偏实践,对理论的了解不是很深入),同时对有些概念的了解仅限于熟悉的或者用过的那几个,甚至有些概念会用但不知道具体的原理,所以想对其中的几个频繁出现的概念做个系统了解。主要包括:
- 上:极大似然估计、贝叶斯、傅里叶、马尔科夫、条件随机场;
- 中:凸集、凸函数与凸优化,优化算法(优化器),过拟合与欠拟合;
- 下:正则化&归一化、标准化,损失函数和伪标签等。
文章目录
- 概念补充(下)
-
- 9. 正则化&归一化、标准化
-
- 9.1 范数 Norm(LP范数)
-
- L0范数
- 9.2 L1范数
- 9.2 L2范数
- 9.3 L1范数和L2范数的区别
-
- 正则化
- 9.4 Dropout
- 9.5 归一化 & 标准化
-
- 9.5.1 归一化 Normalization
- 9.5.2 标准化 Standardization
- 9.5.3 区别
- 10. 损失函数 Loss
-
- 10.1 基于距离度量的损失函数
-
- 1. 平方损失函数
- 2. 绝对损失函数
- 3. 0-1损失函数
- 4. 铰链损失(合页损失)函数
- 5. 中心损失函数
- 6. 余弦损失函数
- 10.2 基于概率分布度量的损失函数
-
- 1. 对数损失函数
- 2. KL散度函数
- 3. 交叉熵损失函数
- 4. Softmax损失函数
- 10.3 其他损失函数
- 10.4 如何选择损失函数
- 11. 伪标签 Pseudo-Label
-
- 11.1 伪标签的应用
- 11.2 伪标签与软标签
9. 正则化&归一化、标准化
本节主要参考内容:正则化方法小结、正则化、正则化 - 知乎、L0,L1,L2范数及其应用。
我们在构造机器学习模型时,最终目的是让模型在面对新数据的时候,可以有很好的表现。当用比较复杂的模型,去拟合数据时,很容易出现过拟合现象,这会导致模型的泛化能力下降,这时候,我们就需要使用正则化,降低模型的复杂度。
因此,正则化是一种为了减小测试误差(注意:是针对于测试误差,对于训练误差可能是增加)的行为。
正则化的本质很简单,就是对某一问题加以先验的限制或约束以达到某种特定目的的一种手段或操作,是一种回归的形式,它将系数估计(coefficient estimate)朝零的方向进行约束、调整或缩小。也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度,从而避免过拟合的危险。
L1、L2正则化(L1、L2Regularization)又叫L1范数、L2范数。目的是对损失函数(cost function)加上一个约束(也可叫惩罚项),减小其解的范围。在正式了解这两种范数之前,我们先看下范数(LP范数)是什么。
9.1 范数 Norm(LP范数)
范数:具有“长度”概念的函数,度量某个向量空间(或矩阵)中的每个向量的长度或大小。LP范数(p-Norm)不是一个范数,而是一组范数(L1、L2是LP中的P=1和2时的情况)。
对于一个向量 x x x,它的 p p p范数定义为( p ∈ [ 1 , ∞ ] p\in[1,∞] p∈[1,∞]):
∣ ∣ x ∣ ∣ p = ( ∑ i n x i p ) 1 p ||x||_p=(\sum^n_ix^p_i)^\frac{1}{p} ∣∣x∣∣p=(i∑nxip)p1
p p p在(0,1)范围内定义的并不是范数,因为违反了三角不等式(范数要满足非负、自反、三角不等式3个条件)。
根据 p p p的变化,范数也有着不同的变化,借用一个经典的有关P范数的变化图如下:

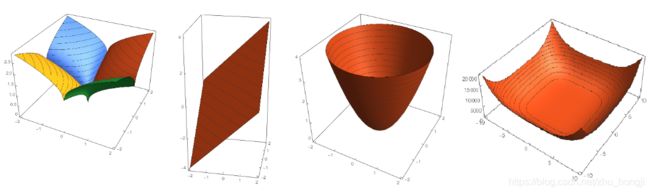
上图表示了p从0到正无穷变化时,单位球(unit ball)的变化情况。在P范数下定义的单位球都是凸集,但是当0≤p<1时,该定义下的单位球不是凸集(这个我们之前提过,当0
L0范数
而当 p = 0 p=0 p=0时,因其不再满足三角不等性,严格的说此时 p p p已不算是范数了,但很多人仍然称之为L0范数。用公式表示如下:
∣ ∣ x ∣ ∣ 0 = # ( i ) w i t h x i ≠ 0 ||x||_0= \# (i)\ with\ x_i≠0 ∣∣x∣∣0=#(i) with xi=0
L0范数表示向量中非零元素的个数。正是L0范数的这个属性,使得其非常适合机器学习中稀疏编码、特征选择的应用。我们可以通过最小化L0范数,来寻找最少最优的稀疏特征项。
但不幸的是,L0范数的最优化(最小化)问题是一个NP hard问题(L0范数同样是非凸的)。因此,在实际应用中我们经常对L0进行凸松弛(relax),变为更高维度的范数问题,如L1范数,L2范数最优化(最小化)问题。理论上有证明,L1范数是L0范数的最优凸近似,因此通常使用L1范数来代替直接优化L0范数。
9.2 L1范数
当 p = 1 p=1 p=1时,我们称之为taxicab Norm,也叫Manhattan Norm。其来源是曼哈顿的出租车司机在四四方方的曼哈顿街道中从一点到另一点所需要走过的距离。也即我们所要讨论的L1范数。
根据LP范数的定义我们可以很轻松的得到L1范数的数学形式:
∣ ∣ x ∣ ∣ 1 = ∑ i n ∣ x i ∣ ||x||_1=\sum^n_i|x_i| ∣∣x∣∣1=i∑n∣xi∣
因此,L1范数就是向量各元素的绝对值之和,也被称为是"稀疏规则算子"(Lasso regularization)。那么问题来了,为什么我们希望稀疏化?稀疏化有很多好处,最直接的两个:特征选择、可解释性。
直观理解L1正则化:
假设有如下带L1正则化的损失函数: J = J 0 + α ∑ w ∣ w ∣ J=J_0+\alpha\sum_w|w| J=J0+α∑w∣w∣,其中 J 0 J_0 J0是原始的损失函数,加号后面的一项是L1正则化项, α \alpha α是正则化系数。注意到L1正则化是权值的绝对值之和, J J J是带有绝对值符号的函数,因此 J J J是不完全可微的。
机器学习的任务就是要通过一些方法(比如梯度下降)求出损失函数的最小值。当我们在原始损失函数 J 0 J_0 J0后添加L1正则化项时,相当于对 J 0 J_0 J0做了一个约束。令 L = α ∑ w ∣ w ∣ L=\alpha\sum_w|w| L=α∑w∣w∣,则 J = J 0 + L J=J_0+L J=J0+L,此时我们的任务变成在 L L L的约束下求出 J 0 J_0 J0取最小值的解。
考虑二维的情况:即只有两个权值 w 1 w^1 w1和 w 2 w^2 w2,此时 L = ∣ w 1 ∣ + ∣ w 2 ∣ L=|w^1|+|w^2| L=∣w1∣+∣w2∣对于梯度下降法,求解 J J J的过程可以画出等值线,同时 L 1 L1 L1正则化的函数 L L L也可以在 w 1 w 2 w^1w^2 w1w2的二维平面上画出来。如下图:
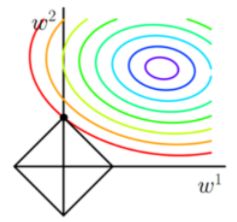
图中等值线是 J 0 J_0 J0的等值线,黑色方形是 L L L函数的图形。在图中,当 J 0 J_0 J0等值线与 L L L图形首次相交的地方就是最优解。上图中 J 0 J_0 J0与 L L L在 L L L的一个顶点处相交,这个顶点就是最优解。
注意到这个顶点的值是 ( w 1 , w 2 ) = ( 0 , w ) (w^1,w^2)=(0,w) (w1,w2)=(0,w)。可以直观想象,因为L函数有很多[突出的角](二维情况下四个,多维情况下更多), J 0 J_0 J0与这些角接触的机率会远大于与 L L L其它部位接触的机率,而在这些角上,会有很多权值等于0(此时 w 1 w^1 w1为0),这就是为什么L1正则化可以产生稀疏模型,进而可以用于特征选择的原因。
而正则化前面的系数 α \alpha α,可以控制 L L L图形的大小。 α \alpha α越小, L L L的图形越大(上图中的黑色方框); α \alpha α越大,L的图形就越小,可以小到黑色方框只超出原点范围一点点,这时最优点的值 ( w 1 , w 2 ) = ( 0 , w ) (w^1,w^2)=(0,w) (w1,w2)=(0,w)中的 w w w就可以取到很小的值。
9.2 L2范数
而当 p = 2 p=2 p=2时,则是我们最为常见的Euclidean norm(欧几里德范数)。也称为Euclidean distance(欧几里得距离)。也即我们要讨论的L2范数。
L2范数是最熟悉的,它的公式如下:
∣ ∣ x ∣ ∣ 2 = ∑ i n ( x i ) 2 ||x||_2=\sqrt{\sum^n_i(x_i)^2} ∣∣x∣∣2=i∑n(xi)2
L2范数有很多名称,有人把它的回归叫“岭回归”(Ridge Regression),也有人叫它“权值衰减”(Weight Decay)。以L2范数作为正则项可以得到稠密解,即每个特征对应的参数w都很小,接近于0但是不为0;此外,L2范数作为正则化项,可以防止模型为了迎合训练集而过于复杂造成过拟合的情况,从而提高模型的泛化能力。
PS:由L2衍生,我们还可以定义无限范数,即L-infinity norm。无限范数是向量x中最大元素的长度。
直观理解L2正则化:
前面与L1正则化相同,其带有L2正则化的损失函数为: J = J 0 + α ∑ w w 2 J=J_0+\alpha\sum_ww^2 J=J0+α∑ww2,同样可以画出他们在二维平面上的图形,如下:

二维平面下L2正则化的函数图形是个圆,与方形相比,被磨去了棱角。因此 J 0 J_0 J0与 L L L相交时使得 w 1 w^1 w1或 w 2 w^2 w2等于零的机率小了许多,这就是为什么L2正则化不具有稀疏性的原因。
9.3 L1范数和L2范数的区别
由于L2范数解范围是圆,所以相切的点有很大可能不在坐标轴上,而由于L1范数是菱形(顶点是凸出来的),其相切的点更可能在坐标轴上,而坐标轴上的点有一个特点,其只有一个坐标分量不为零,其他坐标分量为零,即是稀疏的。所以有如下结论,L1范数可以导致稀疏解,L2范数导致稠密解。
L1最优化问题的解是稀疏性的,其倾向于选择很少的一些非常大的值和很多的insignificant的小值。而L2最优化则更多的非常少的特别大的值,却又很多相对小的值,但其仍然对最优化解有significant的贡献。但从最优化问题解的平滑性来看,L1范数的最优解相对于L2范数要少,但其往往是最优解,而L2的解很多,但更多的倾向于某种局部最优解。
-
L1正则化有一个有趣的性质,它会让权重向量在最优化的过程中变得稀疏(即非常接近0)。也就是说,使用L1正则化的神经元最后使用的是它们最重要的输入数据的稀疏子集,同时对于噪音输入则几乎是不变的了。相较L1正则化,L2正则化中的权重向量大多是分散的小数字。
-
L2正则化可以直观理解为它对于大数值的权重向量进行严厉惩罚,倾向于更加分散的权重向量。由于输入和权重之间的乘法操作,这样就有了一个优良的特性:使网络更倾向于使用所有输入特征,而不是严重依赖输入特征中某些小部分特征。 L2惩罚倾向于更小更分散的权重向量,这就会鼓励分类器最终将所有维度上的特征都用起来,而不是强烈依赖其中少数几个维度。这样做可以提高模型的泛化能力,降低过拟合的风险。
从贝叶斯先验的角度看,当训练一个模型时,仅依靠当前的训练数据集是不够的,为了实现更好的泛化能力,往往需要加入先验项,而加入正则项相当于加入了一种先验。
- L1范数相当于加入了一个Laplacean先验;
- L2范数相当于加入了一个Gaussian先验。
在实践中,如果不是特别关注某些明确的特征选择,一般说来L2正则化都会比L1正则化效果好。
更详细的L1范数和L2范数区别,以及对于L1范数和L2范数的理解,可见:《比较详细的L1和L2正则化解释》。
正则化
在机器学习中正则化是指在损失函数中通过引入一些额外的信息(如上面“直观理解”的例子所示),来防止ill-posed问题或过拟合问题。一般这些额外的信息是用来对模型复杂度进行惩罚(Occam’s razor)。
不同的模型,其损失函数也不同,对于线性回归而言,如果惩罚项选择L1,则是我们所说的Lasso回归,而L2则是Ridge回归。
正则化的影响:
- 正则化后会导致参数稀疏,一个好处是可以简化模型,避免过拟合。因为一个模型中真正重要的参数可能并不多,如果考虑所有的参数起作用,那么可以对训练数据可以预测的很好,但是对测试数据就只能常可能产生过拟合了。
- 另一个好处是参数变少可以使整个模型获得更好的可解释性。且参数越小,模型就会越简单,这是因为越复杂的模型,越是会尝试对所有的样本进行拟合,甚至包括一些异常样本点,这就容易造成在较小的区间里预测值产生较大的波动,这种较大的波动也反映了在这个区间里的导数很大,而只有较大的参数值才能产生较大的导数。因此复杂的模型,其参数值会比较大。
9.4 Dropout
Dropout是深度学习中经常采用的一种正则化方法。它的做法可以简单的理解为在DNNs训练的过程中以概率p丢弃部分神经元,即使得被丢弃的神经元输出为0。Dropout可以实例化的表示为下图:
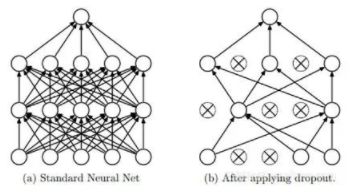
我们可以从两个方面去直观地理解Dropout的正则化效果:
- 在Dropout每一轮训练过程中随机丢失神经元的操作相当于多个DNNs进行取平均,因此用于预测具有vote的效果。
- 减少神经元之间复杂的共适应性。当隐藏层神经元被随机删除之后,使得全连接网络具有了一定的稀疏化,从而有效地减轻了不同特征的协同效应。也就是说,有些特征可能会依赖于固定关系的隐含节点的共同作用,而通过Dropout的话,就有效地组织了某些特征在其他特征存在下才有效果的情况,增加了神经网络的鲁棒性。
9.5 归一化 & 标准化
9.5.1 归一化 Normalization
归一化的目标是找到某种映射关系,将原数据映射到[a,b]区间上。一般a,b会取[-1,1],[0,1]这些组合 。一般有两种应用场景:
- 把数变为(0, 1)之间的小数;
- 把有量纲的数转化为无量纲的数。
常用的归一化方法(参考:[一文搞定深度学习中的规范化BN,LN,IN,GN,CBN](https://zhuanlan.zhihu.com/p/115949091#:~:text=BN LN IN GN都是对神经元状态(输入数据)的规范化,而WN提出对权重进行规范化,其实本质上都是对数据的规范化。,WN是个神奇的操作,但效果上被BN LN IN GN碾压,所以这里只简单提一下有这么个操作。)):
- Min-Max Normalization 最大-最小归一化: x ′ = x − m i n ( x ) m a x ( x ) − m i n ( x ) x' = \frac{x-min(x)}{max(x)-min(x)} x′=max(x)−min(x)x−min(x);
- Batch Normalization(BN)批规范化:严格意义上讲属于归一化手段,主要用于加速网络的收敛,但也具有一定程度的正则化效果。
- 大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如transfer learning/domain adaptation等。而covariate shift就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同。大家细想便会发现,的确,对于神经网络的各层输出,由于它们经过了层内操作作用,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,可是它们所能“指示”的样本标记(label)仍然是不变的,这便符合了covariate shift的定义;
- BN的基本思想其实相当直观,因为神经网络在做非线性变换前的激活输入值(X = WU + B,U是输入),随着网络深度加深,其分布逐渐发生偏移或者变动(即上述的covariate shift)。之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值(X = WU + B)是大的负值和正值。所以这导致后向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因。而 BN 就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,避免因为激活函数导致的梯度弥散问题。所以与其说BN的作用是缓解covariate shift,倒不如说BN可缓解梯度弥散问题。
- Layer Normalization(LN)层规范化:
- BN操作的效果受batchsize影响很大,如果batchsize较小,每次训练计算的均值方差不具有代表性且不稳定,甚至使模型效果恶化;而且BN很难用在RNN这种序列模型中,且效果不好;
- LN是对当前隐藏层整层的神经元进行规范化,这样LN就与batchsize无关了,小的batchsize也可以进行归一化训练,LN也可以很轻松地用到RNN中。
- Instance Normalization(IN):
- BN注重对batchsize数据归一化,但是在图像风格化任务中,生成的风格结果主要依赖于某个图像实例,所以对整个batchsize数据进行归一化是不合适的,因而提出了IN只对H、W维度进行归一化;因此,在图像风格化任务中,更合适使用IN来做规范化。
- Group Normalization(GN):
- BN依赖大batchsize,LN虽然不依赖batchsize,但是在CNN中直接对当前层所有通道数据进行规范化也不太好;
- GN先对通道进行分组,每个组内的所有C_i,W,H维度求均值方差进行规范化,也与batchsize无关。
- Weight Normalization(WN):
- BN、LN、IN、GN都是对神经元状态(输入数据)的规范化,而WN提出对权重进行规范化,其实本质上都是对数据的规范化;
- WN是个神奇的操作,但效果上被BN、LN、IN、GN碾压。
- Ada BN:
- AdaBN也不算是对BN的改进,只是在迁移学习中,由于输入数据的源domain不同,BN层参数无法直接用(毕竟是从训练数据中求出来的),这时使用一种策略来缓解这个问题,就是所谓的AdaBN;
- 实现方法如下:把模式设置为训练模式(torch.is_grad_enabled=True),但是在“训练”过程中不更新模型参数,而是在每一次iteration中只更新global mean和global variance,相当于是在新的数据集上“假装训练一遍”,得到在新数据集上的均值和方差,这样就可以用于新数据集上的推理了(当然可能模型参数并不一定适用于新数据,可能需要finetune甚至重新训练,但至少BN参数是在新数据集上自适应adaptive了)。
- Cross-Iteration BN(CBN):
- 将前几次iteration的BN参数保存起来,当前iteration的BN参数由当前batch数据求出的BN参数和保存的前几次的BN参数共同推算得出(顾名思义 Cross-Interation BN);训练前期BN参数记忆长度短一些,后期训练稳定了可以保存更长时间的BN参数来参与推算,效果更好;
- 可以将CBN粗糙地总结为 “前几次训练的BN(LN/GN应该都可以)参数” + 当前batch数据计算的BN(LN/GN)参数 来计算得出当前次训练iteration真正的CBN参数。
总的来说,BN是最传统的,如果batchsize允许够大的话,用在CNN中的效果依然是最好的;LN适合RNN;IN适合图像风格化任务;GN更适合小batchsize的CNN训练。
9.5.2 标准化 Standardization
用大数定理将数据变换为均值为0,标准差为1的分布(切记,并非一定是正态的),标准化公式为: x ′ = x − μ σ x' = \frac{x-μ}{σ} x′=σx−μ。
中心化:另外,还有一种处理叫做中心化,也叫零均值处理,就是将每个原始数据减去这些数据的均值。
9.5.3 区别
归一化的缩放是“拍扁”统一到某个固定区间(仅由极值决定),而标准化的缩放是更加“弹性”和“动态”的,和整体样本的分布有很大的关系(改变分布,但不改变分布的类型)。
- 归一化:缩放仅仅跟最大、最小值的差别有关;
- 标准化:缩放和每个点都有关系,通过方差(variance)体现出来。与归一化对比,标准化中所有数据点都有贡献(通过均值和标准差造成影响)。
为什么要标准化和归一化?
- 提升模型精度:归一化后,不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性;
- 加速模型收敛:标准化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
10. 损失函数 Loss
本节主要参考内容:监督学习中的损失函数及应用研究、深度学习常用损失函数的基本形式、原理及特点、损失函数(Loss Function)、深度学习损失函数小结。
损失函数(loss function)就是用来度量模型的预测值f(x)与真实值Y的差异程度的运算函数,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。
损失函数使用主要是在模型的训练阶段,每个批次的训练数据送入模型后,通过前向传播输出预测值,然后损失函数会计算出预测值和真实值之间的差异值,也就是损失值。得到损失值之后,模型通过反向传播去更新各个参数,来降低真实值与预测值之间的损失,使得模型生成的预测值往真实值方向靠拢,从而达到学习的目的。
在正文开始之前,先说下关于 Loss Function、Cost Function 和 Objective Function 的区别和联系。在机器学习的语境下这三个术语经常被交叉使用。
- 损失函数 Loss Function 通常是针对单个训练样本而言,给定一个模型输出 y ^ \hat{y} y^和一个真实 y y y,损失函数输出一个实值损失 L = f ( y i , y ^ i ) L=f(y_i,\hat{y}_i) L=f(yi,y^i);
- 代价函数 Cost Function 通常是针对整个训练集(或者在使用 mini-batch gradient descent 时一个 mini-batch)的总损失 J = ∑ i = 1 n f ( y i , y ^ i ) J=\sum ^n_{i=1}f(y_i,\hat{y}_i) J=∑i=1nf(yi,y^i);
- 目标函数 Objective Function 是一个更通用的术语,表示任意希望被优化的函数,用于机器学习领域和非机器学习领域(比如运筹优化)。
一句话总结三者的关系就是:A loss function is a part of a cost function which is a type of an objective function。由于损失函数和代价函数只是在针对样本集上有区别,因此在本文中统一使用了损失函数这个术语,但下文的相关公式实际上采用的是代价函数 Cost Function 的形式。
注意本节对于损失函数只做大概地列举,不会详细拓展。对于相对重要的损失函数会标粗表示,对于PyTorch中封装了的损失函数会添加相关链接,并加上图标。
10.1 基于距离度量的损失函数
基于距离度量的损失函数通常将输入数据映射到基于距离度量的特征空间上,如欧氏空间、汉明空间等,将映射后的样本看作空间上的点,采用合适的损失函数度量特征空间上样本真实值和模型预测值之间的距离。特征空间上两个点的距离越小,模型的预测性能越好。常用的基于距离度量的损失函数如下:
1. 平方损失函数
平方损失 (squared loss)函数最早是从天文学和地理测量学领域发展起来的,后来,由于欧氏距离在各个领域的广泛使用,平方损失函数日益受到研究人员的关注。在回归问题中,平方损失用于度量样本点到回归曲线的距离,通过最小化平方损失使样本点可以更好地拟合回归曲线。在机器学习的经典算法(反向传播算法、循环神经网络、流形学习、随机森林和图神经网络)中,常选用平方损失及其演化形式作为模型对误检测样本进行惩罚的依据。标准形式如下:
( Y − f ( x ) ) 2 (Y-f(x))^2 (Y−f(x))2
由于平方损失函数具有计算方便、逻辑清晰、评估误差较准确以及可求得全局最优解等优点,一直受到研究人员的广泛关注,其演化形式也越来越多。基于平方损失演化的损失函数有:
- 加权平方损失函数: λ ( Y − f ( x ) ) 2 λ(Y-f(x))^2 λ(Y−f(x))2;
- 加权平方损失函数通过加权修改样本真实值与预测值之间的误差,使样本到拟合曲线的距离尽可能小,即找到最优拟合曲线。
- 和方误差(sum squared error,SSE)函数: ∑ i = 1 n ( Y i − f ( x ) ) 2 \sum^n_{i=1}(Y_i-f(x))^2 ∑i=1n(Yi−f(x))2;
- 在正负样本比例相差很大时,SSE通过计算拟合数据和原始数据对应点的误差平方和,使正样本点更加靠近拟合曲线,与MSE相比,SSE可以更好地表达误差。
- 均方误差(mean squared error,[MSE](https://pytorch.org/docs/stable/generated/torch.nn.MSELoss.html?highlight=sum squared error))函数: 1 n ∑ i = 1 n ( Y i − f ( x ) ) 2 \frac{1}{n}\sum^n_{i=1}(Y_i-f(x))^2 n1∑i=1n(Yi−f(x))2;
- MSE的思想是使各个训练样本点到最优拟合曲线的距离最小,常用于评价数据的变化程度。MSE的值越小,表示预测模型描述的样本数据具有越好的精确度。由于无参数、计算成本低和具有明确物理意义等优点,MSE已成为一种优秀的距离度量方法。尽管MSE在图像和语音处理方面表现较弱,但它仍是评价信号质量的标准,在回归问题中,MSE常被作为模型的经验损失或算法的性能指标。
- L2损失(L2 loss)函数: ∑ i = 1 n ( Y i − f ( x ) ) 2 \sqrt{\sum^n_{i=1}(Y_i-f(x))^2} ∑i=1n(Yi−f(x))2;
- L2损失又被称为欧氏距离,是一种常用的距离度量方法,通常用于度量数据点之间的相似度。由于L2损失具有凸性和可微性,且在独立、同分布的高斯噪声情况下,它能提供最大似然估计,使得它成为回归问题、模式识别、图像处理中最常使用的损失函数。
- 均方根误差(root mean squared error,RMSE)函数: 1 n ∑ i = 1 n ( Y i − f ( x ) ) 2 \sqrt{\frac{1}{n}\sum^n_{i=1}(Y_i-f(x))^2} n1∑i=1n(Yi−f(x))2;
- RMSE直观地揭示了模型的输出预测值与样本真实值的离散程度,常被作为回归算法的性能度量指标。尽管与平均绝对误差(MAE)相比,RMSE计算更复杂且易偏向更高的误差,但由于其是平滑可微的函数,且更容易进行运算,目前仍是许多模型默认的度量标准。
- x2检验(chi-square test)函数: 1 2 ∑ i = 0 n − 1 ( A i − B i ) 2 A i + B i \frac{1}{2}\sum^{n-1}_{i=0}\frac{(A_i-B_i)^2}{A_i+B_i} 21∑i=0n−1Ai+Bi(Ai−Bi)2;
- x2检验也被称为x2统计,常用于计算图像直方图之间的距离。
- **Triple损失函数**: ∑ i N ( ∣ ∣ f ( x i a ) − f ( x i p ) ∣ ∣ 2 2 − ∣ ∣ f ( x i a ) − f ( x i n ) ∣ ∣ 2 2 + a ) \sum^N_i(||f(x^a_i)-f(x^p_i)||^2_2-||f(x^a_i)-f(x^n_i)||^2_2+a) ∑iN(∣∣f(xia)−f(xip)∣∣22−∣∣f(xia)−f(xin)∣∣22+a);
- triple损失函数是一个三元损失函数,使用时需设计样本本身、相似的正样本和不相似的负样本三方数据,既耗时又对性能敏感。triple损失函数不能对每一个单独的样本进行约束,由于其具有类间距离大于类内距离的特性,首次出现在基于卷积神经网络(convolutional neural network,CNN)的人脸识别任务中便取得了令人满意的效果。
- 对比损失(contrastive loss)函数: 1 2 n ∑ i = 1 N y d 2 + ( 1 − y ) m a x ( m a r g i n − d , 0 ) 2 \frac{1}{2n}\sum^N_{i=1}yd^2+(1-y)max(margin-d,0)^2 2n1∑i=1Nyd2+(1−y)max(margin−d,0)2。
- 对比损失函数是一个成对损失函数,在使用时除需样本本身外,还需一个对比数据,可见,它也不能对每一个单独的样本进行约束。对比损失函数不仅能降维,而且降维后成对样本的相似性保持不变,可以很好地表达成对样本的匹配程度,另外,它能扩大类间距离,缩小类内距离,在人脸验证算法中,常被作为人脸判断的依据。
2. 绝对损失函数
绝对损失( absolute loss)函数是最常见的一种损失函数,它不仅形式简单,而且能很好地表达真实值和预测值之间的距离。其标准形式如下:
∣ Y − f ( x ) ∣ |Y-f(x)| ∣Y−f(x)∣
绝对损失对离群点有很好的鲁棒性,但它在残差为零处却不可导。绝对损失的另一个缺点是更新的梯度始终相同,也就是说,即使很小的损失值,梯度也很大,这样不利于模型的收敛。针对它的收敛问题,一般的解决办法是在优化算法中使用变化的学习率,在损失接近最小值时降低学习率。尽管绝对损失本身的缺陷限制了它的应用范围,但基于绝对损失的演化形式却受到了更多的关注。
基于绝对损失的演化损失函数包括:
- 平均绝对误差(MAE)函数: 1 n ∑ i = 1 n ∣ Y − f ( x ) ∣ \frac{1}{n}\sum^n_{i=1}|Y-f(x)| n1∑i=1n∣Y−f(x)∣;
- MAE表达预测误差的实际情况,只衡量预测误差的平均模长,不考虑方向,一般作为回归算法的性能指标。
- 平均相对误差(mean relative error,MRE)函数: 1 n ∑ i = 1 n ∣ Y − f ( x ) ∣ Y i \frac{1}{n}\sum^n_{i=1}\frac{|Y-f(x)|}{Y_i} n1∑i=1nYi∣Y−f(x)∣;
- MRE既指明误差的大小,又指明其正负方向。一般来说,与MAE相比,它更能反映评估的可信程度。
- L1损失(L1 loss)函数: ∑ i = 1 n ∣ Y − f ( x ) ∣ \sum^n_{i=1}|Y-f(x)| ∑i=1n∣Y−f(x)∣;
- L1损失又称为曼哈顿距离,表示残差的绝对值之和。
- Chebyshev损失函数: m a x i = 1 n ( Y − f ( x ) ) max^n_{i=1}(Y-f(x)) maxi=1n(Y−f(x));
- Chebyshev损失也称切比雪夫距离或L∞度量,是向量空间中的一种度量方法。
- Minkowski损失函数: ( ∑ i = 1 n ∣ Y − f ( x ) ∣ p ) 1 p (\sum^n_{i=1}|Y-f(x)|^p)^{\frac{1}{p}} (∑i=1n∣Y−f(x)∣p)p1;
- Minkowski损失也被称为闵氏距离或闵可夫斯基距离,是欧氏空间中的一种度量方法,常被看作欧氏距离和曼哈顿距离的一种推广。
- **Smooth L1损失函数**: { 1 2 ( Y − f ( x ) ) 2 , ∣ Y − f ( x ) ∣ < 1 ∣ Y − f ( x ) ∣ − 1 2 , ∣ Y − f ( x ) ∣ ≥ 1 \begin{cases}\frac{1}{2}(Y-f(x))^2,&|Y-f(x)|<1\\|Y-f(x)|-\frac{1}{2},&|Y-f(x)|≥1\end{cases} {21(Y−f(x))2,∣Y−f(x)∣−21,∣Y−f(x)∣<1∣Y−f(x)∣≥1;
- smooth L1损失是由Girshick R在Fast R-CNN中提出的,主要用在目标检测中防止梯度爆炸。
- **Huber损失函数**: { 1 2 ( Y − f ( x ) ) 2 , ∣ Y − f ( x ) ∣ < δ δ ∣ Y − f ( x ) ∣ − 1 2 δ 2 , ∣ Y − f ( x ) ∣ ≥ δ \begin{cases}\frac{1}{2}(Y-f(x))^2,&|Y-f(x)|<δ\\δ|Y-f(x)|-\frac{1}{2}δ^2,&|Y-f(x)|≥δ\end{cases} {21(Y−f(x))2,δ∣Y−f(x)∣−21δ2,∣Y−f(x)∣<δ∣Y−f(x)∣≥δ;
- huber损失是平方损失和绝对损失的综合,它克服了平方损失和绝对损失的缺点,不仅使损失函数具有连续的导数,而且利用MSE梯度随误差减小的特性,可取得更精确的最小值。尽管huber损失对异常点具有更好的鲁棒性,但是,它不仅引入了额外的参数,而且选择合适的参数比较困难,这也增加了训练和调试的工作量。
- 分位数损失(quantile loss)函数: ∑ i ; y i < f ( x i ) ( 1 − γ ) ∣ Y i − f ( x i ) ∣ + ∑ i ; y i ≥ f ( x i ) γ ∣ Y i − f ( x i ) ∣ \sum_{i;y_i
- 分位数损失的思想是通过分位数γ惩罚高估和低估的预测值,使其更接近目标值的区间范围,当设置多个γ值时,将得到多个预测模型,当γ=0.5时,分位数损失相当于MAE。分位数损失易构建能够预测输出值范围的模型,与MAE相比,它可减少数据预处理的工作量。基于分位数损失的回归学习,不仅适用于正态分布的残差预测问题,而且对于具有变化方差或非正态分布残差的预测问题,也能给出合理的预测区间。在神经网络模型、梯度提升回归器和基于树模型的区间预测问题中,选取分位数损失评估模型的性能往往会取得更好的预测结果。
- 分位数损失函数选取合适的分位数比较困难,一般情况下,分位值的选取取决于求解问题对正误差和反误差的重视程度,应根据实验结果进行反复实验后再选取。另外,分位数损失值在0附近的区间内存在导数不连续的问题。
3. 0-1损失函数
0-1损失(zero-one loss)函数是一种较为简单的损失函数,常用于分类问题。它不考虑预测值和真实值的误差程度,是一种绝对分类方法。其思想是以分隔线为标准,将样本集中的数据严格区分为0或1。其标准形式如下:
L ( Y , f ( x ) ) = { 1 , Y ≠ f ( x ) 0 , Y = f ( x ) L(Y,f(x))=\begin{cases}1,&Y≠f(x)\\0,&Y=f(x)\end{cases} L(Y,f(x))={1,0,Y=f(x)Y=f(x)
由于没有考虑噪声对现实世界数据的影响因素,对每个误分类样本都施以相同的惩罚,预测效果不佳,甚至出现严重误分类情况,这在很大程度上限制了0-1损失函数的应用范围。另外,0-1损失函数是一种不连续、非凸且不可导函数,优化困难,这进一步限制了它的应用范围。
基于0-1损失的分类思想,出现了最常见的分类模型——K最近邻(K nearest neighbor,KNN)。虽然0-1损失很少出现在监督学习算法中,但它的分类思想为之后出现的其他分类算法奠定了基础。
由于0-1损失函数直观简单,也易理解,研究人员在0-1损失的基础上引入参数,进一步放宽分类标准,将其演化为感知机损失(perceptron loss)。
感知机损失是0-1损失改进后的结果,它采用参数克服了0-1损失分类的绝对性。与0-1损失相比,它的分类结果更可靠。感知机损失被广泛应用于图像风格化、图像复原等问题中,通过使用预训练的深度网络对图像进行多层语义分解,在相关问题上取得了较好的效果,其形式为: L ( Y , f ( x ) ) = { 1 , ∣ Y − f ( x ) ∣ > t 0 , ∣ Y − f ( x ) ∣ ≤ t L(Y,f(x))=\begin{cases}1,&|Y-f(x)|>t\\0,&|Y-f(x)|≤t\end{cases} L(Y,f(x))={1,0,∣Y−f(x)∣>t∣Y−f(x)∣≤t,其中,t为参数,在感知机算法中t=0.5。
总之,尽管0-1损失函数存在误分类的情况,但是,当所有样本完全远离分隔线时,0-1损失函数可能是最好的选择,也就是说,0-1损失函数在对称或均匀噪声的数据集上具有较好的鲁棒性。
4. 铰链损失(合页损失)函数
**铰链损失(Hinge loss)**也被称为合页损失,它最初用于求解最大间隔的二分类问题。铰链损失函数是一个分段连续函数,当Y和f(x)的符号相同时,预测结果正确;当Y和f(x)的符号相反时,铰链损失随着f(x)的增大线性增大。其标准形式如下:
m a x ( 0 , 1 − Y ⋅ f ( x ) ) , Y ∈ { − 1 , 1 } max(0,1-Y·f(x)),\ Y\in \{-1,1\} max(0,1−Y⋅f(x)), Y∈{−1,1}
铰链损失函数最著名的应用是作为支持向量机(support vector machine,SVM)的目标函数,其性质决定了SVM具有稀疏性,也就是说,分类正确但概率不足1和分类错误的样本被识别为支持向量,用于划分决策边界,其余分类完全正确的样本没有参与模型求解。
铰链损失函数是一个凸函数,因此,铰链损失函数可应用于机器学习领域的很多凸优化方法中。基于铰链损失的演化损失函数包括:
- 边界铰链损失函数: m a x ( 0 , m a r g i n − ( f ( x ) − Y ) max(0,margin-(f(x)-Y) max(0,margin−(f(x)−Y);
- 边界铰链损失表示期望正确预测的得分高于错误预测的得分,且高出边界值margin,它主要用于训练两个样本之间的相似关系,而非样本的类别得分。
- 坡道损失(ramp loss)函数: 1 n ∑ i = 1 n ( m a x ( 0 , 1 − h y i ) − m a x ( 0 , s − h y i ) ) \frac{1}{n}\sum^n_{i=1}(max(0,1-h_{y_i})-max(0,s-h_{y_i})) n1∑i=1n(max(0,1−hyi)−max(0,s−hyi));
- 在坡道损失函数中,s为截断点的位置,一般情况下,s的值取决于类别个数c,它在x=1和x=s两处不可导。
- Crammerand铰链损失函数: m a x ( 0 , 1 + m a x Y ≠ f ( x ) w Y x − w f ( x ) x ) max(0,1+max_{Y≠f(x)}w_Yx-w_{f(x)}x) max(0,1+maxY=f(x)wYx−wf(x)x);
- Crammerand铰链损失函数是由Crammerand Singer提出的一种针对线性分类器的损失函数。
- Weston铰链损失函数: ∑ Y ≠ f ( x ) m a x ( 0 , 1 + w Y x − w f ( x ) x ) \sum_{Y≠f(x)}max(0,1+w_Yx-w_{f(x)}x) ∑Y=f(x)max(0,1+wYx−wf(x)x);
- Weston铰链损失函数是由Weston和Watkins提出的一种损失函数。
- 二分类支持向量机损失函数: 1 2 ∣ ∣ w ∣ ∣ 2 + c ∑ i = 1 n m a x ( 0 , 1 − Y ⋅ f ( x ) ) \frac12||w||^2+c\sum^n_{i=1}max(0,1-Y·f(x)) 21∣∣w∣∣2+c∑i=1nmax(0,1−Y⋅f(x));
- 二分类支持向量机损失函数可看作L2正则化与铰链损失之和。多分类支持向量机损失函数只考虑在正确值附近的那些值,其他的均作为0处理,即只关注那些可能造成影响的点(或支持向量),因此,具有较好的鲁棒性。
- 多分类支持向量机损失函数: ∑ Y ≠ Y i m a x ( 0 , s j − s Y i + 1 ) \sum_{Y≠Y_i} max(0,s_j-s_{Y_i}+1) ∑Y=Yimax(0,sj−sYi+1);
- 多分类支持向量机平方损失函数: ∑ Y ≠ Y i m a x ( 0 , s j − s Y i + 1 ) 2 \sum_{Y≠Y_i} max(0,s_j-s_{Y_i}+1)^2 ∑Y=Yimax(0,sj−sYi+1)2;
- 与多分类支持向量机损失函数相比,多分类支持向量机平方损失函数的惩罚更强烈。
- top-k铰链损失函数: C ∑ i = 1 n ( m a x ( 1 − y i ( w T x i + b ) , 0 ) ) C\sum^n_{i=1} (max(1-y_i(w^Tx_i+b),0)) C∑i=1n(max(1−yi(wTxi+b),0))。
- top-k铰链损失函数在k个测试样本预测为正的约束下,使所有训练实例的铰链损失最小化。
5. 中心损失函数
中心损失(center loss)函数采用了欧氏距离思想,为每个类的深层特征学习一个中心(一个与特征维数相同的向量),但在全部样本集上计算类中心相当困难,常用的做法是把整个训练集划分成若干个小的训练集(mini-batch),并在mini-batch样本范围内进行类中心计算。另外,在更新类中心时常增加一个类似学习率的参数α,用于处理采样太少或者有离群点的情况。其标准形式如下:
1 2 ∑ i = 1 n D ( f ( x i ) , c y i ) \frac12\sum^n_{i=1}D(f(x^i),c_{y_i}) 21i=1∑nD(f(xi),cyi)
中心损失函数主要用于减小类内距离,表面上只是减少了类内距离,但实际上间接增大了类间距离,它一般不单独使用,常与softmax损失函数搭配使用,其分类效果比只用softmax损失函数更好。
基于中心损失的演化损失函数有三元中心损失(triplet-center loss, TCL)函数,TCL函数使样本与其对应的中心之间的距离比样本与其最近的负中心之间的距离更近。
总之,中心损失函数常用于神经网络模型中,实现类内相聚、类间分离。在特征学习时,当期望特征不仅可分,而且必须差异大时,通常使用中心损失函数减小类内变化,增加不同类特征的可分离性。在实际应用中,由于中心损失函数本身考虑类内差异,因此中心损失函数应与主要考虑类间的损失函数搭配使用,如softmax损失、交叉熵损失等。
6. 余弦损失函数
**余弦损失(Cosine loss)**也被称为余弦相似度,它用向量空间中两个向量夹角的余弦值衡量两个样本的差异。与欧氏距离相比,余弦距离对具体数值的绝对值不敏感,而更加注重两个向量在方向上的差异。其标准形式如下:
Y f ( x ) ∣ ∣ Y ∣ ∣ ⋅ ∣ ∣ f ( x ∣ ∣ \frac{Yf(x)}{||Y||·||f(x||} ∣∣Y∣∣⋅∣∣f(x∣∣Yf(x)
在监督学习中,余弦相似度常用于计算文本或标签的相似度。它常与词频逆向文件频率(term frequency-inverse document frequency,TF-IDF)算法结合使用,用于文本挖掘中的文件比较。在数据挖掘领域,余弦损失常用于度量集群内部的凝聚力。
基于余弦损失的演化损失函数有改进的余弦距离核函数,它是由李为等人在与文本相关的说话人确认技术中提出的,用来区分说话人身份及文本内容的差异。
10.2 基于概率分布度量的损失函数
基于概率分布度量的损失函数是将样本间的相似性转化为随机事件出现的可能性,即通过度量样本的真实分布与它估计的分布之间的距离,判断两者的相似度,一般用于涉及概率分布或预测类别出现的概率的应用问题中,在分类问题中尤为常用。监督学习算法中,常用的基于概率分布度量的损失函如下:
1. 对数损失函数
**对数损失(Logarithm loss)**也被称为对数似然损失,它使用极大似然估计的思想,表示样本x在类别y的情形下,使概率P(y|x)达到最大值。因为概率的取值范围为[0,1],使得log(P(y|x))取值为((−∞,0)),为保证损失为非负,对数损失的形式为对数的负值。其标准形式如下:
− l o g P ( Y ∣ X ) -log^{P(Y|X)} −logP(Y∣X)
对数损失函数是逻辑回归、神经网络以及一些期望极大估计的模型经常使用的损失函数,它通过惩罚错误的分类,实现对分类器的精确度量化和模型参数估计,对数损失函数常用于度量真实条件概率分布与假定条件概率分布之间的差异。基于对数损失函数的演化形式包括:
- 逻辑回归损失(logistic regression loss)函数: L ( y , P ( Y = y ∣ x ) ) = { l o g 1 + e x p ( − f ( x ) ) , y = 1 l o g 1 + e x p ( f ( x ) ) , y = 0 L(y,P(Y=y|x))=\begin{cases}log^{1+exp(-f(x))},&y=1\\log^{1+exp(f(x))},&y=0\end{cases} L(y,P(Y=y∣x))={log1+exp(−f(x)),log1+exp(f(x)),y=1y=0;
- 逻辑回归损失函数假设样本服从伯努利分布,利用极大似然估计的思想求得极值,它常作为分类问题的损失函数。加权对数损失函数主要应用在类别样本数目差距非常大的分类问题中,如边缘检测问题(边缘像素的重要性比非边缘像素大,可针对性地对样本进行加权)。
- 加权对数损失函数: − ∑ k = 0 C W C Y C l o g f ( x ) -\sum^C_{k=0}W_CY_Clog^{f(x)} −∑k=0CWCYClogf(x);
- 对数双曲余弦损失(log cosh loss)函数: ∑ i = 1 n l o g c o s h ( f ( x i ) − Y i ) \sum^n_{i=1}log^{cosh(f(x_i)-Y_i)} ∑i=1nlogcosh(f(xi)−Yi);
- 对数双曲余弦损失函数基本上等价于MSE函数,但又不易受到异常点的影响,是更加平滑的损失函数,它具有huber损失函数的所有优点,且二阶处处可导。
- softmax损失函数: − Y ⋅ l o g s o f t m a x ( Y , f ( x ) ) -Y·log^{softmax(Y,f(x))} −Y⋅logsoftmax(Y,f(x));
- softmax损失函数是卷积神经网络处理分类问题时常用的损失函数。
- 二分类对数损失函数: − 1 n ∑ i = 1 n ( y i l o g p i + ( 1 − y i ) l o g 1 − p i ) -\frac1n\sum^n_{i=1}(y_ilog^{p_i}+(1-y_i)log^{1-p_i}) −n1∑i=1n(yilogpi+(1−yi)log1−pi);
- 巴氏距离(Bhattacharyya distance)函数: − l n B C ( p , q ) -ln^{BC(p,q)} −lnBC(p,q)。
- 巴氏距离函数用于度量两个连续或离散概率分布的相似度,它与衡量两个统计样本或种群之间的重叠量的巴氏系数密切相关。在直方图相似度计算中,选用巴氏距离函数会获得很好的效果,但它的计算很复杂。
2. KL散度函数
KL散度( Kullback-Leibler divergence)也被称为相对熵,是一种非对称度量方法,常用于度量两个概率分布之间的距离。KL散度也可以衡量两个随机分布之间的距离,两个随机分布的相似度越高的,它们的KL散度越小,当两个随机分布的差别增大时,它们的KL散度也会增大,因此KL散度可以用于比较文本标签或图像的相似性。其标准形式如下:
∑ i = 1 n P ( x i ) × l o g P ( x i ) Q ( x i ) \sum^n_{i=1}P(x_i)×log^{\frac{P(x_i)}{Q(x_i)}} i=1∑nP(xi)×logQ(xi)P(xi)
基于KL散度的演化损失函数有JS散度函数。JS散度也称JS距离,用于衡量两个概率分布之间的相似度,它是基于KL散度的一种变形,消除了KL散度非对称的问题,与KL散度相比,它使得相似度判别更加准确。
KL 散度及其演化损失主要用于衡量两个概率分布之间的相似度,常作为图像低层特征和文本标签相似度的度量标准。KL散度在成像分析、流体动力学、心电图等临床实验室检测、生物应用的网络分析、细胞生物学等领域有广泛的应用。
3. 交叉熵损失函数
**交叉熵(CrossEntropy Loss)**是信息论中的一个概念,最初用于估算平均编码长度,引入机器学习后,用于评估当前训练得到的概率分布与真实分布的差异情况。其标准形式如下:
− ∑ i = 1 N ∑ j = 1 C P i j l o g q i j -\sum^N_{i=1}\sum^C_{j=1}P_{ij}log^{q_{ij}} −i=1∑Nj=1∑CPijlogqij
为了使神经网络的每一层输出从线性组合转为非线性逼近,以提高模型的预测精度,在以交叉熵为损失函数的神经网络模型中一般选用tanh、sigmoid、softmax或ReLU作为激活函数。
基于交叉熵损失的演化损失函数包括:
- 平均交叉熵损失函数: − 1 n ∑ i = 1 n Y i l n a i -\frac1n\sum^n_{i=1}Y_iln^{a_i} −n1∑i=1nYilnai;
- 二分类交叉熵损失函数(BCE Loss): − 1 n ∑ i = 1 n [ Y i l n a i + ( 1 − Y i ) l n 1 − a i ] -\frac1n\sum^n_{i=1}[Y_iln^{a_i}+(1-Y_i)ln^{1-a_i}] −n1∑i=1n[Yilnai+(1−Yi)ln1−ai];
- 二分类交叉熵损失函数对于正样本而言,输出概率越大,损失越小;对于负样本而言,输出概率越小,损失越小。
- 二分类平衡交叉熵损失函数: − 1 n ∑ i = 1 n [ β ⋅ Y i l n a i + ( 1 − β ) ( 1 − Y i ) l n 1 − a i ] -\frac1n\sum^n_{i=1}[\beta·Y_iln^{a_i}+(1-\beta)(1-Y_i)ln^{1-a_i}] −n1∑i=1n[β⋅Yilnai+(1−β)(1−Yi)ln1−ai];
- 二分类平衡交叉熵损失函数与二分类交叉熵损失函数相比,它的优势在于引入了平衡参数β∈[0,1],可实现正负样本均衡,使预测值更接近于真实值。
- 多分类交叉熵损失函数: − 1 n ∑ i = 1 n ∑ j = 1 k Y i , j l o g a i , j -\frac1n\sum^n_{i=1}\sum^k_{j=1}Y_{i,j}log^{a_{i,j}} −n1∑i=1n∑j=1kYi,jlogai,j;
- Focal损失函数: − 1 n ∑ i = 1 n Y i δ i ( 1 − a i ) γ l o g a i -\frac1n\sum^n_{i=1}Y_iδ_i(1-a_i)^γlog^{a_i} −n1∑i=1nYiδi(1−ai)γlogai。
交叉熵损失函数刻画了实际输出概率与期望输出概率之间的相似度,也就是交叉熵的值越小,两个概率分布就越接近,特别是在正负样本不均衡的分类问题中,常用交叉熵作为损失函数。目前,交叉熵损失函数是卷积神经网络中最常使用的分类损失函数,它可以有效避免梯度消散。
4. Softmax损失函数
从标准形式上看,softmax损失函数应归到对数损失的范畴,在监督学习中,由于它被广泛使用,所以单独形成一个类别。softmax损失函数本质上是逻辑回归模型在多分类任务上的一种延伸,常作为CNN模型的损失函数。softmax损失函数的本质是将一个k维的任意实数向量x映射成另一个k维的实数向量,其中,输出向量中的每个元素的取值范围都是(0,1),即softmax损失函数输出每个类别的预测概率。其标准形式如下:
− 1 n ∑ i = 1 n l o g ( e f Y i ∑ j = 1 c e f Y i ) -\frac1n \sum^n_{i=1}log(\frac{e^{fY_i}}{\sum^c_{j=1}e^{fY_i}}) −n1i=1∑nlog(∑j=1cefYiefYi)
由于softmax损失函数具有类间可分性,被广泛用于分类、分割、人脸识别、图像自动标注和人脸验证等问题中,其特点是类间距离的优化效果非常好,但类内距离的优化效果比较差。基于softmax损失函数的演化损失函数包括:

softer softmax 损失函数是Hinton G等人为了解决模型给误分类标签分配的概率被softmax损失忽略的问题而提出的。NSL损失函数利用两个特征向量之间的余弦相似度评估两个样本之间的相似性,使后验概率只依赖于角度的余弦值,由此产生的模型学习了角空间中可分离的特征,提高了特征学习能力。与传统的欧几里得边距相比,角的余弦值与softmax具有内在的一致性,基于此思想,在原始softmax基础上选用角边距度量两个样本的相似性, Liu W等人提出了L-softmax损失函数。受L-softmax损失函数启发,在它的基础上,Liu W等人增加了条件 ∣ ∣ w ∣ ∣ = 1 ||w||=1 ∣∣w∣∣=1,B=0和cos(mθ1)>cos(θ2),使得预测仅取决于W和x之间的角度θ,提出了A-softmax损失函数。受L-softmax损失函数的启发, Wang F等人提出了AM-softmax损失函数,它使前后向传播变得更加简单。正则化softmax损失函数加入刻画模型的复杂度指标的正则化,可以有效地避免过拟合问题。
10.3 其他损失函数
其他损失函数主要包括指数损失( exponential loss)函数、汉明距离函数、dice损失函数、余弦损失+softmax函数和softmax+LDloss函数,见下图:

与主要损失函数相比,其他损失函数在监督学习中使用的频次比较低,其中指数损失函数是AdaBoost算法中常用的损失函数。它与铰链损失函数和交叉熵损失函数相比,对错误分类施加的惩罚更大,这使得它的误差梯度也较大,因此在使用梯度下降算法优化时,在极小值处求解速度也较快。汉明距离用于计算两个向量的相似度,即通过比较两个向量的每一位是否相同来计算汉明距离。dice损失函数是一种集合相似性度量函数,通常用于计算两个样本的相似性,常作为文本比较或图像分割类问题的损失函数,尤其适用于处理图像的前景区域和背景区域相差较大的图像分割问题。余弦损失+softmax函数是利用余弦和softmax的特性组合而成的,见之前的LMCL损失函数。softmax+LDloss函数是黄旭等人在融合判别式深度特征学习的图像识别算法中引入线性判别分析(linear discriminant analysis,LDA)思想构建的损失函数,该算法使softmax+LDloss参与卷积神经网络的训练,实现尽可能最小化类内特征距离和最大化类间特征距离的目标,以提高特征的鉴别能力,进而改善图像的识别性能。
此外,Torch中也会有一些这里没有涉及到的损失函数,具体可见:PyTorch 1.11.0 documentation。
10.4 如何选择损失函数
| 损失函数 | 名称 | 适用场景 |
|---|---|---|
| torch.nn.MSELoss() | 均方误差损失 | 回归 |
| torch.nn.L1Loss() | 平均绝对值误差损失 | 回归 |
| torch.nn.KLDivLoss() | KL散度损失 | 回归 |
| torch.nn.SmoothL1Loss() | 平滑的L1损失 | 回归 |
| torch.nn.BCELoss() | 二分类交叉熵损失 | 二分类 |
| torch.nn.NLLLoss() | 负对数似然函数损失 | 多分类 |
| torch.nn.CrossEntropyLoss() | 交叉熵损失 | 多分类 |
| torch.nn.SoftMarginLoss() | 多标签二分类问题的损失 | 多标签二分类 |
| torch.nn.MultiLabelMarginLoss() | 多标签分类的损失 | 多标签分类 |
| torch.nn.NLLLoss2d() | 图片负对数似然函数损失 | 图像分割 |
| torch.nn.MarginRankingLoss() | 评价相似度的损失 | 排序 |
通常情况下,损失函数的选取应从以下方面考虑:
- 选择最能表达数据的主要特征构建基于距离或基于概率分布度量的特征空间;
- 选择合理的特征归一化方法,使特征向量转换后仍能保持原来数据的核心内容;
- 选取合理的损失函数,在实验的基础上,依据损失不断调整模型的参数,使其尽可能实现类别区分;
- 合理组合不同的损失函数,发挥每个损失函数的优点,使它们能更好地度量样本间的相似性;
- 将数据的主要特征嵌入损失函数,提升基于特定任务的模型预测精确度。
11. 伪标签 Pseudo-Label
本节主要来源:伪标签(Pseudo-Labelling)、伪标签:是什么,为什么,怎么用、。
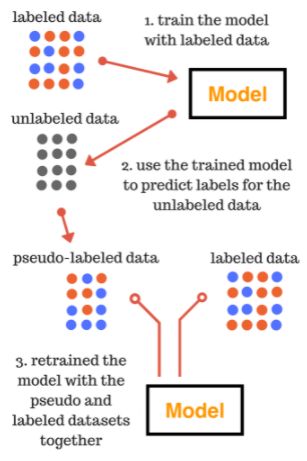
伪标签 PL的定义来自于半监督学习,半监督学习的核心思想是通过借助无标签的数据来提升有监督过程中的模型性能。粗略来讲,伪标签技术就是利用在已标注数据所训练的模型在未标注的数据上进行预测,根据预测结果筛选高置信度的样本,然后再把两者结合起来再次输入模型中进行训练的一个过程。因为是无标注数据而且我们模型准确不可能是百分之百,从而导致预测的这个标签我们并不清楚是不是精准,所以我们称之为"伪标签"。
筛选高置信度样本:有些伪标签是明显标记错误的就丢弃,大概率预测正确的(高置信区间内)标签留下作为训练数据。
但实际上,伪标签技术在具体应用的细节上,远没有说的如此简单。伪标签技术的使用自由度非常高,对于某些特殊场景,可能有更花哨的方法,这里只做简单的介绍。
伪标签为何能够用于半监督模型:
-
半监督学习的目的是为了使用无标签数据增强模型的泛化性。而cluster assumption表明,决策边界位于低密度区域(low-density regions)能够提高模型的泛化性。而高密度区域的结果应该具有相似的输出结果。而伪标签就是取最高概率的作为伪标签;
-
熵最小化思想:熵正则通过最小化未标记数据的类概率的条件熵,促进了类之间的低密度分离,而无需对密度进行任何建模,通过熵正则化与伪标签具有相同的作用效果,都是希望利用未标签数据的分布的重叠程度的信息。
11.1 伪标签的应用
具体步骤如下:
-
使用有标签数据训练监督模型 M M M;
-
使用监督模型 M M M对无标签数据进行预测,得出预测概率 P P P;
-
通过预测概率 P P P筛选高置信度的样本,此时这些样本根据概率 P P P得到的标签就是伪标签;
-
使用有标签数据和伪标签数据训练新模型 M ′ M' M′,此时模型的损失函数为:
L = 1 n ∑ m = 1 n ∑ i = 1 C L ( y i m , f i m ) + α ( t ) 1 n ′ ∑ m = 1 n ′ ∑ i = 1 C L ( y ′ i m , f ′ i m ) L = \frac1n \sum^n_{m=1}\sum^C_{i=1}L(y_i^m,f_i^m) + \alpha(t)\frac{1}{n'}\sum^{n'}_{m=1}\sum^C_{i=1}L({y'}_i^m,{f'}_i^m) L=n1m=1∑ni=1∑CL(yim,fim)+α(t)n′1m=1∑n′i=1∑CL(y′im,f′im)-
公式的前半部分针对的是有标签数据的损失函数;后半部分是针对伪标签数据的损失函数;
-
n ′ n' n′是标签的类别数目、 C C C是数据中伪标签数据的大小、 y ′ i m {y'}_i^m y′im是无标注数据的伪标签、 f ′ i m {f'}_i^m f′im是无标注数据的输出、 α ( t ) \alpha(t) α(t)是伪标签/未标注数据的权重,其更新如下:
α ( t ) = { 0 , t < T 1 t − T 1 T 2 − T 1 α f , T 1 ≤ t < T 2 α f , T 2 ≤ t \alpha(t) = \begin{cases} 0,&t
-
-
可选:将 M M M替换为 M ′ M' M′,重复以上步骤直至模型效果不出现提升。
11.2 伪标签与软标签
伪标签与软标签名字上比较类似,两者很容易弄混淆:
-
伪标签(Pseudo Label)对未标注数据进行预测,进行二次训练;
-
一般来说我们的标签数据都是硬标签(Hard Label),非0即1,如one-hot或multi-one-hot;
-
软标签(Soft Label)是对标签分布转为离散值(类似概率的形式),进行二次训练;
eg:硬标签 [ 0 , 0 , 1 ] [0,0,1] [0,0,1],可以转换成软标签 [ 0.1 , 0.2 , 0.7 ] [0.1,0.2,0.7] [0.1,0.2,0.7]。
软标签一般使用在模型蒸馏和某些数据集的训练中,可以让模型学习到样本整体类别分布。同时软标签与硬标签(Hard Label)相比,软标签可以防止模型过拟合,也可以配合mix up一起进行使用。
当然也可以将软标签与伪标签同时使用,如下图的思路。
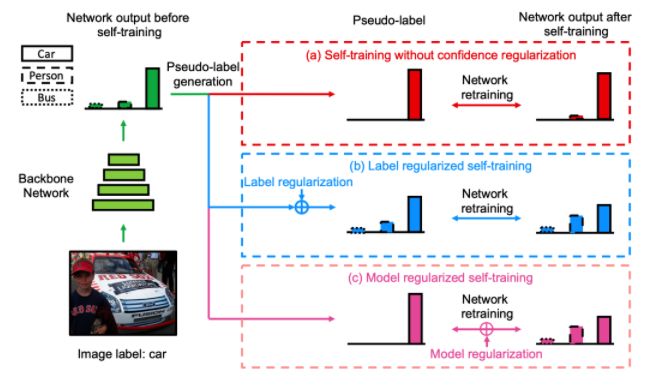
最后,要注意:在竞赛中伪标签不是万能的,一般情况下伪标签适用于:
- 非结构化数据,使用深度学习的常见下;
- 模型的精度较高的情况下,加入的伪标签才精确;
- 在竞赛中如果没有其他涨分的方法,再建议尝试伪标签,否则不建议尝试。