【机器学习】Reinforcement Learning-强化学习学习笔记
一、强化学习的定义
1.1 什么是强化学习?
首先,强化学习并不是某一种特定的算法,而是一类算法的统称。
解决序列决策问题的一类方法,通过寻求最优策略,获取最大回报。
强化学习就是智能体从环境到动作映射的学习,以使回报信号(激励信号)函数值最大。
引用下百度百科下强化学习的定义:强化学习(Reinforcement Learning, RL),又称增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题 。
强化学习的常见模型是标准的。按给定条件,强化学习可分为基于模式的强化学习(model-based RL)和无模式强化学习(model-free RL) ,以及主动强化学习(active RL)和被动(passive RL)。
1.2 机器学习的几种方法
强化学习是和监督学习,非监督学习并列的第三种机器学习方法。
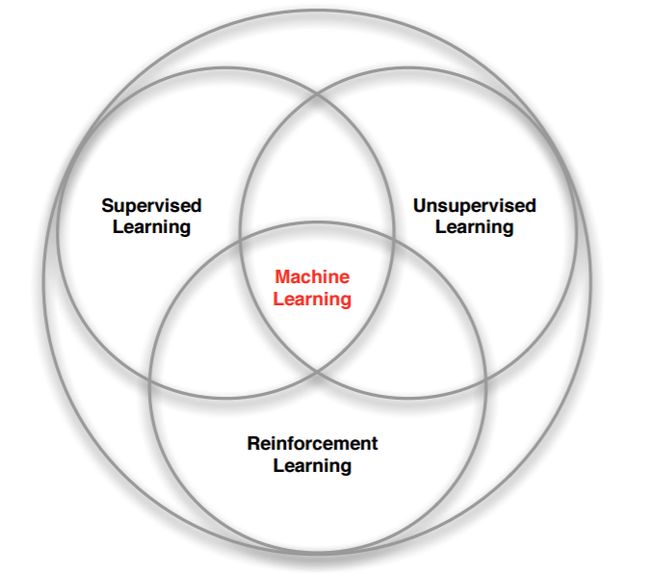
机器学习下的几种方法的对比:
- 监督学习:标签数据:需要,直接反馈,应用场景:预测输出。
- 无监督学习:标签数据:不需要,无反馈,应用场景:发掘隐藏结构。
- 强化学习:标签数据:不需要,延迟反馈,应用场景:决策过程。

强化学习和监督学习、无监督学习最大的不同就是不需要大量的“数据喂养”,而是通过自己不停的尝试来学会某些技能。也就是说,强化学习是让计算机实现从一开始完全随机的进行操作,通过不断地尝试,从错误中学习,最后找到规律,学会了达到目的的方法。智能体(Agent)以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使智能体获得最大的奖赏。
1.3 强化学习基本思路
算法执行个体(Agent)来做决策,即选择一个合适的动作(Action)。选择了动作后,环境的状态(State)会发生改变,变为为+1,同时也可以得到采取动作的延时奖励(Reward)+1。然后个体可以继续选择下一个合适的动作,然后环境的状态又会发生改变,又有新的奖励值。
1.4 强化学习的一些特点
- 强化学习没有监督标签,只会对当前状态进行奖惩和打分,其本身并不知道什么样的动作才是最好的。
- 强化学习的评价有延迟,往往需要过一段时间,已经走了很多步后才知道当时选择是好是坏。有时候需要牺牲一部分当前利益以最优化未来奖励。
- 强化学习有一定的时间顺序性,每次行为都不是独立的数据,每一步都会影响下一步。目标也是如何优化一系列的动作序列以得到更好的结果,即应用场景往往是连续决策问题。
二、强化学习术语
2.1 强化学习基本术语
- 智能体-Agent:强化学习中的Agent可以理解为是采取行动的智能个体。
- 动作-Action:Action是智能体可以采取的动作的集合。一个动作(action)几乎是一目了然的,但是应该注意的是智能体是在从可能的行动列表中进行选择。
- 环境-Environment:指的就是智能体行走于其中的世界。这个环境将智能体当前的状态和行动作为输入,输出是智能体的奖励和下一步的状态。
- 状态-State:一个状态就是智能体所处的具体即时状态;也就是说,一个具体的地方和时刻,这是一个具体的即时配置,它能够将智能体和其他重要的失事物关联起来,例如工具、敌人和或者奖励。它是由环境返回的当前形势。
- 奖励-Reward:奖励是我们衡量某个智能体的行动成败的反馈,通常是一个标量。面对任何既定的状态,智能体要以行动的形式向环境输出,然后环境会返回这个智能体的一个新状态(这个新状态会受到基于之前状态的行动的影响)和奖励(如果有任何奖励的话)。奖励可能是即时的,也可能是迟滞的。它们可以有效地评估该智能体的行动。
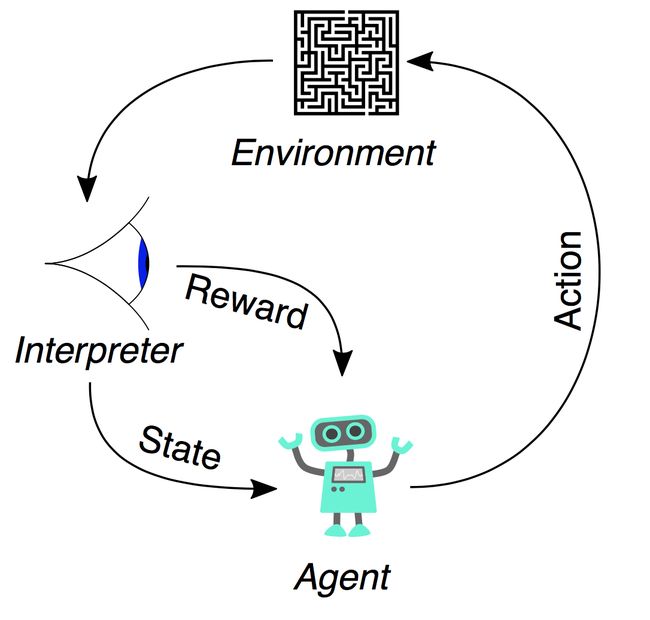
强化学习的基本流程图:

强化学习动作者主体的构成:
策略-Policy:动作者的行为函数,策略是动作者的行为决策来源。
值函数-Value Function:评价每一步的状态或者动作,值函数是对未来累计奖励的预测。
模型-Model:动作者对环境的建模表示,预测环境接下来要发生什么。
强化学习基本要素:
- 环境状态, t时刻环境的状态是它的环境状态集中某一个状态。
- 个体的动作, t时刻个体采取的动作是它的动作集中某一个动作。
- 环境的奖励,t时刻个体在状态采取的动作对应的奖励+1会在t+1时刻得到。
-
个体的策略(policy),它代表个体采取动作的依据,即个体会依据策略来选择动作。最常见的策略表达方式是一个条件概率分布(|),即在状态时采取动作的概率。即(|)=(=|=),此时概率大的动作被个体选择的概率较高。
-
个体在策略和状态时,采取行动后的价值(value),一般用()表示。这个价值一般是一个期望函数。虽然当前动作会给一个延时奖励+1,但是光看这个延时奖励是不行的,因为当前的延时奖励高,不代表到了t+1,t+2,...时刻的后续奖励也高。比如下象棋,我们可以某个动作可以吃掉对方的车,这个延时奖励是很高,但是接着后面我们输棋了。此时吃车的动作奖励值高但是价值并不高。因此我们的价值要综合考虑当前的延时奖励和后续的延时奖励。价值函数()一般可以表示为下式(为衰减因子):
![]()
-
环境的状态转化模型,可以理解为一个概率状态机,它可以表示为一个概率模型,即在状态下采取动作,转到下一个状态′的概率,表示为′。
-
探索率,这个比率主要用在强化学习训练迭代过程中,由于我们一般会选择使当前轮迭代价值最大的动作,但是这会导致一些较好的但我们没有执行过的动作被错过。因此我们在训练选择最优动作时,会有一定的概率不选择使当前轮迭代价值最大的动作,而选择其他的动作。
2.2 马尔可夫决策过程(Markov Decision Process)
马氏状态:未来仅与当前状态有关,与过去无关。(MDP策略完全取决于当前状态)
MDP简单说就是一个智能体(Agent)采取行动(Action)从而改变自己的状态(State)获得奖励(Reward)与环境(Environment)发生交互的循环过程。马尔可夫过程是一种无记忆性的随机过程,具备马尔可夫性。
马尔可夫决策过程:一个四元组。
![]()

补充:R是回报函数。
MDP的动态过程如下:某个智能体(agent)的初始状态为s0,然后从A中挑选一个动作a0执行,执行后,agent 按Ps,a概率随机转移到了下一个状态s1,s1∈ Ts0a0。然后再执行一个动作a1,就转移到了状态s2,接下来再执行a2…
强化学习在马尔可夫决策过程环境中主要使用的技术是动态规划(Dynamic Programming)。流行的强化学习方法包括自适应动态规划(ADP)、时间差分(TD)学习、状态-动作-回报-状态-动作(SARSA)算法、Q 学习、深度强化学习(DQN)。
2.3 贝尔曼方程
![]()
三、一些强化学习算法
强化学习算法的2大分类。这2个分类的重要差异是:智能体是否能完整了解或学习到所在环境的模型。有模型学习(Model-Based)对环境有提前的认知,可以提前考虑规划,但是缺点是如果模型跟真实世界不一致,那么在实际使用场景下会表现的不好。免模型学习(Model-Free)放弃了模型学习,在效率上不如前者,但是这种方式更加容易实现,也容易在真实场景下调整到很好的状态。所以免模型学习方法更受欢迎,得到更加广泛的开发和测试。

采用时序差分法的强化学习可以分为两类,一类是在线控制(On-policy Learning),即一直使用一个策略来更新价值函数和选择新的动作,代表方法就是Sarsa。而另一类是离线控制(Off-policy Learning),会使用两个控制策略,一个策略用于选择新的动作,另一个策略用于更新价值函数,代表方法就是Q-Learning。
3.1、Q-Learning
QLearning是强化学习算法中基于价值(value-based)的学习算法。Q即为Q(s,a),就是在某一时刻的s状态下采取动作a动作能够获得收益的期望,环境会根据agent的动作反馈相应的回报reward,所以算法的主要思想就是将State与Action构建成一张Q-table来存储Q值,然后根据Q值来选取能够获得最大的收益的动作。
QLearning的核心是Q-table,Q-table只是一个简单查找表的奇特名称。Q-table的行和列分别表示state和action的值(行=状态,列=动作),Q-table的值Q(s,a)衡量当前state采取action到底有多好。每个Q-table的得分将是机器人在该状态下采取该行动时将获得的最大预期未来奖励。这是一个迭代过程,因为我们需要在每次迭代时改进Q-Table。Q-Learning算法可以学习出Q表的每个值。
在实际的训练过程中,通常实验贝尔曼方程来更新Q-table:

Q(s,a)表示成当前状态s采取动作a后的即时奖励r,加上折价γ后的最大reward max(Q(s′,a′)。
Qlearning使用了时间差分法TD(融合了蒙特卡洛和动态规划)能够进行离线学习, 使用bellman方程可以对马尔科夫过程求解最优策略。
QLearning的两个重要术语:状态-state、行为-action。QLearning的目标是达到reward值最大的state。
QLearning算法的转移规则:
![]()

其中,(s,a)表示当前的状态和行为,(![]() ,
,![]() )表示s的下一个状态及行为,学习参数
)表示s的下一个状态及行为,学习参数 为0-1之间的常数。这里,趋向0表示agent主要考虑“眼前奖励”,趋向1表示agent主要考虑“记忆中的奖励”。Q为待构建的矩阵,表示agent已经学到的知识,R是reward矩阵,行表示状态,列表示行为。Q与R矩阵同阶。
为0-1之间的常数。这里,趋向0表示agent主要考虑“眼前奖励”,趋向1表示agent主要考虑“记忆中的奖励”。Q为待构建的矩阵,表示agent已经学到的知识,R是reward矩阵,行表示状态,列表示行为。Q与R矩阵同阶。
将agent的每一次探索称为一个episode,在每一个episode中,agent从任意初始状态到达目标状态,当agent到达目标状态后,一个episode结束,进入下一个episode。
Q-learning算法流程:

Agent通过上述Q-learning算法在经验中学习,每个episode相当于一个training session。在一个training session中,agent探索外界环境,并接收外界环境的reward,直到达到目标状态。训练的目标是要强化Q矩阵,训练的越多,Q矩阵被优化的越好。(Q被初始化为一个全0矩阵)
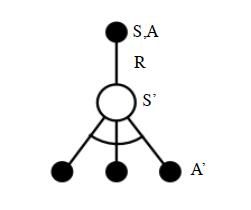
Q-Learnig的思想就是,如上图从上到下,先基于当前状态S,使用ϵ−贪婪法按一定概率选择动作A,然后得到奖励R,并更新进入新状态S′。此时,如果是SARSA,会继续基于状态S′,用−贪婪法选择A′,然后来更新价值函数。对于Q-Learning,基于状态S′,没有使用−贪婪法选择A′,直接使用贪婪法从所有的动作中选择最优的A′(即离线选择,不是用同样的ϵ−贪婪)。而是使用贪婪法选择A′,也就是说,选择使(′,)最大的a作为A′来更新价值函数。

Q学习算法流程:

建立一个Q Table来保存状态s和将会采取的所有动作a,Q(s,a)。在每个回合中,先随机初始化第一个状态,再对回合中的每一步都先从Q Table中使用ϵ−贪婪基于当前状态 s (如果Q表没有该状态就创建s-a的行,且初始为全0)选择动作 a,执行a,然后得到新的状态s’和当前奖励r,同时更新表中Q(s,a)的值,继续循环到终点。整个算法就是一直不断更新 Q table 里的值,再根据更新值来判断要在某个 state 采取怎样的 action最好。
Q-learning参考文献:
- 强化学习(七)时序差分离线控制算法Q-Learning - 刘建平Pinard - 博客园在强化学习(六)时序差分在线控制算法SARSA中我们讨论了时序差分的在线控制算法SARSA,而另一类时序差分的离线控制算法还没有讨论,因此本文我们关注于时序差分离线控制算法,主要是经典的Q-Learnhttps://www.cnblogs.com/pinard/p/9669263.html
- An introduction to Q-Learning: reinforcement learningby ADL An introduction to Q-Learning: reinforcement learning Photo by Daniel Cheung [https://unsplash.com/@danielkcheung?utm_source=medium&utm_medium=referral] on Unsplash [https://unsplash.com?utm_source=medium&utm_medium=referral].This article is the second part of my “Deep reinforcement learning” series. The complete series shall be available both on Medium [https://medium.com/@alamba093] and in videos on my YouTube channel [https://www.youtube.com/channel/UCRkxhh51YKqpn2gaUI3MXjg]. In thehttps://www.freecodecamp.org/news/an-introduction-to-q-learning-reinforcement-learning-14ac0b4493cc/
- A Painless Q-learning Tutorial (一个 Q-learning 算法的简明教程)_peghoty-CSDN博客本文是对 http://mnemstudio.org/path-finding-q-learning-tutorial.htm 的翻译,共分两部分,第一部分为中文翻译,第二部分为英文原文。翻译时为方便读者理解,有些地方采用了意译的方式,此外,原文中有几处笔误,在翻译时已进行了更正。这篇教程通俗易懂,是学习理解 Q-learning 算法工作原理的绝佳入门材料。https://blog.csdn.net/itplus/article/details/9361915
- 【强化学习】Q-Learning算法详解_shura的技术空间-CSDN博客_q-learningQLearning是强化学习算法中值迭代的算法,Q即为Q(s,a)就是在某一时刻的 s 状态下(s∈S),采取 a (a∈A)动作能够获得收益的期望,环境会根据agent的动作反馈相应的回报reward r,所以算法的主要思想就是将State与Action构建成一张Q-table来存储Q值,然后根据Q值来选取动作获得较大的收益。https://blog.csdn.net/qq_30615903/article/details/80739243?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~Rate-2.pc_relevant_paycolumn_v3&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~Rate-2.pc_relevant_paycolumn_v3&utm_relevant_index=5
- 强化学习(Q-Learning,Sarsa)_nakaizura-CSDN博客_强化学习Reinforcement Learning监督学习–>非监督学习–>强化学习。监督学习:拥有“标签”可监督算法不断调整模型,得到输入与输出的映射函数。非监督学习:无“标签”,通过分析数据本身进行建模,发掘底层信息和隐藏结构。但是1.标签需要花大量的代价进行收集,在有些情况如子任务的组合数特别巨大寻找监督项是不切实际的。2.如何更好的理解数据,学习到具体的映射而不仅仅是数据的底...https://blog.csdn.net/qq_39388410/article/details/88795124
3.2、Sarsa
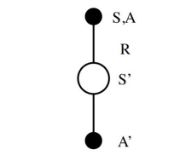
Sarsa的思想和Q-Learning类似。如上图从上到下,先基于当前状态S,使用ϵ−贪婪法按一定概率选择动作A,然后得到奖励R,并更新进入新状态S′,基于状态S′,使用ϵ−贪婪法选择A′(即在线选择,仍然使用同样的ϵ−贪婪)。
价值函数的更新公式如下(是衰减因子,是迭代步长一般随着迭代逐渐变小):


算法流程:

同样建立一个Q Table来保存状态s和将会采取的所有动作a,Q(s,a)。在每个回合中,先随机初始化第一个状态,再对回合中的每一步都先从Q Table中使用ϵ−贪婪基于当前状态 s (如果Q表没有该状态就创建s-a的行,且初始为全0)选择动作 a,执行a,然后得到新的状态s’和当前奖励r,同时再使用ϵ−贪婪得到在s’时的a’,直接利用a’更新表中Q(s,a)的值,继续循环到终点。
相比之下,Q-Learning是贪婪的,在更新Q时会先不执行动作只更新,然后再每次都会选max的动作,而sarsa选了什么动作来更新Q就一定执行相应的动作。这就使它不贪心一昧求最大,而是会稍稍专注不走坑,所以sarsa相对来说十分的胆小,掉进坑里面下次争取会避免它(而Q不管,每次都直接向着最小的反向学习。)不管因为Sarsa太害怕坑,而容易陷入一个小角落出不来。
SARSA参考文献:
强化学习(六)时序差分在线控制算法SARSA - 刘建平Pinard - 博客园在强化学习(五)用时序差分法(TD)求解中,我们讨论了用时序差分来求解强化学习预测问题的方法,但是对控制算法的求解过程没有深入,本文我们就对时序差分的在线控制算法SARSA做详细的讨论。 SARSA这https://www.cnblogs.com/pinard/p/9614290.html
3.3、DQN-Deep Q Network
DQN其实就是Deep Q-Learning算法,其算法的基本思路来源于Q-Learning(Q-Learning+神经网络)。但是和Q-Learning不同的地方在于,它的Q值的计算不是直接通过状态值s和动作来计算,而是通过一个Q网络来计算的,这个Q网络是一个神经网络。即,DQN使用神经网络来代替Q表。
DQN的输入是我们的状态s对应的状态向量(), 输出是所有动作在该状态下的动作价值函数Q。Q网络可以是DNN,CNN或者RNN,没有具体的网络结构要求。

DQN参考文献:
- 强化学习(八)价值函数的近似表示与Deep Q-Learning - 刘建平Pinard - 博客园在强化学习系列的前七篇里,我们主要讨论的都是规模比较小的强化学习问题求解算法。今天开始我们步入深度强化学习。这一篇关注于价值函数的近似表示和Deep Q-Learning算法。 Deep Qhttps://www.cnblogs.com/pinard/p/9714655.html
3.4、Double DQN
在DDQN之前,基本上所有的目标Q值都是通过贪婪法直接得到的,无论是Q-Learning, DQN还是Nature DQN。DDQN有一样的两个Q网络结构。

3.5、Dueling DQN
在Dueling DQN中,我们尝试通过优化神经网络的结构来优化算法。Dueling DQN考虑将Q网络分成两部分,第一部分是仅仅与状态S有关,与具体要采用的动作A无关,这部分我们叫做价值函数部分,记做(,,),第二部分同时与状态状态S和动作A有关,这部分叫做优势函数(Advantage Function)部分,记为(,,,),那么最终我们的价值函数可以重新表示为:
![]()
Dueling DQN参考文献:
- https://arxiv.org/pdf/1511.06581.pdf
 https://arxiv.org/pdf/1511.06581.pdf
https://arxiv.org/pdf/1511.06581.pdf
4、参考博客
强化学习 (Reinforcement Learning) | 莫烦Python
一文看懂什么是强化学习?(基本概念+应用场景+主流算法)
强化学习(一)模型基础 - 刘建平Pinard - 博客园