T2I论文阅读笔记——TivGAN 文本生成视频
TivGAN Text to Image to VIdeo Generation with Step by Step Evolutionary Generator论文阅读笔记
论文源地址:https://arxiv.org/pdf/2009.02018.pdf
出版于2020.8.19 发表在IEEE Access
本人的话:一些翻译不来的词会直接写英文原文。没有网络整体的细节,不建议复现。
摘要
本论文提出了一个全新的框架——Text-to-Image-to-Video GAN(TiVGAN),希望实现从文本生成视频。原理主要是逐帧生成最后成为一段完整的视频。在第一阶段,我们专注于通过学习文本与图片的关系生成一个高质量的单个视频帧,然后再将模型用于更多的连续帧上面。
关键词:计算机视觉,深度学习,GAN,视频生成,文本生成视频;
介绍
近来,变分自编码器(Variational Auto Encoders, VAEs)和GANs代表了最前沿的生成领域的研究。
图片生成只关心单个帧的完整性,而视频生成还需要考虑到帧与帧之间的联系。此外,所有公开的视频数据集很diverse和unaligned,使得视频生成任务更加地复杂。
关于text-to-video的研究很稀少,并且相比于T2I,分辨率低。
本研究针对生成与给定文本相匹配的视频的问题,提出了一个新的网络,它建立在视频的连续帧具有很大连续性的基本概念上。如果我们创建了一个高质量的视频帧,那么会很容易地在创建一个相关的连续帧。

相关工作
“Generating videos with scene dynamics”这篇论文通过对每个场景进行2D空间卷积和3D时空卷积分离了场景的背景与前景。
TGAN使用两个不同的generator来实现时间向量采样和基于已获得向量的多个帧的创建。
MoCoGAN建议通过对动作和内容空间的分离来生成有效的视频。他们使用了一个RNN来从动作子空间采样,然后再和内容向量concat生成连续帧。
“Video generation from text”这篇论文使用条件VAE来生成一个要点‘gist’,gist指视频背景颜色和object layer,然后视频内容和动作基于gist和文本生成。
“To create what you tell: Generating videos from captions”介绍了一个全新的框架,它使用了3D卷积和不同类型的loss。
"Conditional gan with discriminative filter generation for text-to-video synthesis"使用了multi-scale text conditioning scheme with GANs.
方法
我们将训练过程分为:Text-to-Image Generation和Evolutionary Generation。如下图:

我们首先学习文本生成单张图片,然后逐步增加生成的图片,重复直到达到预期的视频长度。
文本生成图片
目标:一段视频VF = (I1, I2, I2^n),它与给定文本描述t相匹配。t到VF的转化使用一个recurrent unit——R和generator——G,n∈N。
在这一步骤,我们不考虑图片序列的关系。所以,这一阶段我们的目标就是从t生成一个真实的图片I1。
首先使用一个预训练的skip-thoughts vector network(来自论文Skip-thought vectors)将文本t编码到一个4800维的向量。由于生成的是一个高维向量,我们再使用主成分分析PCA来降维,最后得到词嵌入向量Φt。Φt∈R60.
然后,我们使用一个简单的GRU单元——R和generator G来创建一个帧。
![]()
根据上式,将词嵌入向量通过R,计算得到v1,其中z0和z1为从N(0, 1)中采样的随机噪声(高斯分布)。
然后根据I1=G(v1),得到与真实帧相同大小的图片。
在训练图片discriminator——DI时,真实图片Xi是从2n个帧中随机选取的。因此,它可以它可以更加匹配给定视频训练集的图片分布。
Evolutionary Generation
第一阶段训练完成后,第二阶段分为n个步骤,并且每个步骤的目标是逐步生成2m个连续帧,m∈{1, 2, ……, n}。
例如,当m=1时,我们将v1作为隐藏状态,z2为从N(0, 1)随机采样的噪声,令v2=R(v1, (Φt, z2)), 然后将v2送入G得到另一张图片I2。
对每一个步骤m:添加了第m个step-discriminator DSm来鉴别2m个帧的顺序。输入生成视频(I1, I2, I2^m, Φt)和真实视频(X1, X2, X2^m, Φt)到DSm,其中(X1, X2, X2^m)是从真实视频VR中随机选择的连续帧,保证生成视频具有正确的时间信息。
Step-Discriminator Initialization
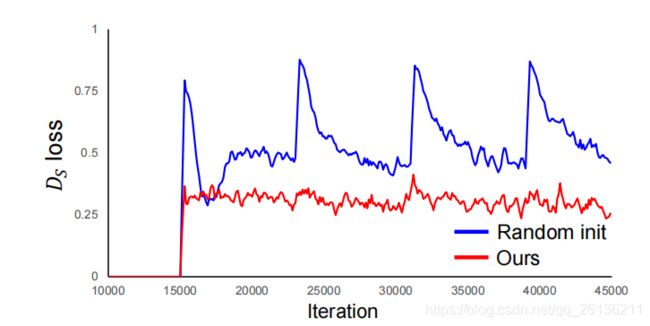
对于DSm,它在第m步被初始化。但图片discriminator——DI,它是在所有step被训练的,因此二者存在不平衡。所以需要对DSm使用更好的初始化方案,也就是使用上一步的DSm-1的权重来进行初始化。DS1的初始化值为DI。所有的step-discriminator具有相同的结构,除了第一层的输入通道数。令Fml,k表示DSm的第l层的第k个输入通道,定义如下:

Independent Samples Pairing
训练GAN中出现的最大问题是模式崩溃(mode collapse)。为了缓和这个现象,使用了独立样本配对(Independent Samples Pairing, ISP)。我们的模型在生成第k帧时,输出两个图片Ika和Ikb,其中输入文本t和高斯分布的噪声zka和zkb。这两个独立生成的图片在通道维度上被concat到一起。为了生成多样的视频,我们训练了一个discriminator来区分(Ika, Ikb, Φt)和(Xa, Xb, Φt),其中Xa, Xb是和文本描述相关联的两个不相似的图片。也就是说,如果Ika, Ikb过于相似,那么discriminator就会判断它是fake,所以generator需要根据相同的t生成两个不同的图片来骗过discriminator。
ISP仅用于图片discriminator DI.
训练过程
不同于传统的GAN,我们在StackGAN的基础上对discriminator(有两个分支)做了略微改动。
首先,discriminator通过几个卷积层来取得高质量的特征图。然后,一个分支concat Φt来计算文本和图片的匹配损失,另一个分支进行patch discrimination。这两个分支确保图片质量以及图片与文本的匹配度。
loss定义如下:其中有real pair(X,Φt), fake pair(I, Φt)和wrong pair(X, Φ^t)。

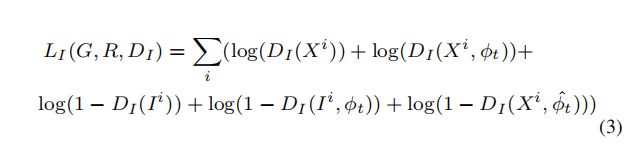
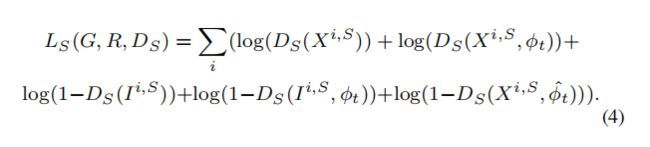
训练过程的伪代码如下:

实验
数据集:KTH Action,MUG和Kinetics。
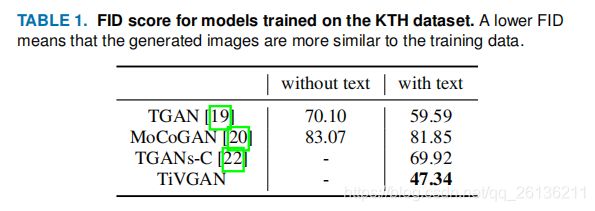
通过与其他网络的对比可以看到TiVGAN的清晰度有明显的的提示。

对于所有实验,总共4个步骤,即生成16帧的视频。训练text-to-image时,共30k个迭代,对于evolutionary generation,共15k个迭代。对于PCA,我们将维度减少到了60维,即Φt∈R60.
KTH ACTION数据集
KTH Action数据集包含6种人类动作:走、慢跑、跑、拳击、挥手、鼓掌。我们使用了慢跑这一类。在 每一段视频,都有一个人在两个背景下从左到右慢跑或从右到左。我们从每个视频里提取了16帧并且reshape到128x128。训练过程中,使用了共200个视频(3200帧)。
我们使用了frechet inception distance,FID评估生成图片的质量,即测量两个图片集的分布相似度。
MUG Facial Expression
MUG是一个人类面部表情数据集,包含数十人,每人都表达了happy、 disgust、sad、neutral、surprise、fear和anger。将其reshape到128x128大小,然后使用1030段视频进行训练。
使用Inception Score进行评估,提高diversity。由于数据集的类太少,所以没有使用Inception-v3,而是使用了一个简单的5层3D卷积神经网络。


Kinetics
Kinetics是一个大型的从Youtube上来的以人为中心的视频数据集,由包含600个人类动作种类的数千个视频URLs组成。与以往的研究相同,我们使用了其中的6类:snow bike,swimming, sailing, golf, kite surfing, water ski。reshape到128x128大小,训练共3032个视频。
同MUG,使用Inception Score进行评估,

Ablation Study
Nearest Neighbors

Step-by-Step Generation

Step-discriminator Initialization
Independent Samples Pairing
