阅读笔记2: 深度学习可解释性学习:不要做事后解释
选择可解释性高的机器学习模型,
而不是解释决策风险高的黑匣子模型
(原论文名:Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and use Interpretable Models Instead)
作者:
Adrian Colyer,
Venture Partner,
Accel
论文下载地址:https://www.nature.com/articles/s42256-019-0048-x
(看到nature官网是不是有点小激动? 嘿嘿嘿)
大牛简介
先对这个实验室的鲁丁教授做个简单的介绍先,后面也会讲到她参与的实验与论文。
附上杜克大学官网对她的介绍篇:
https://ece.duke.edu/faculty/cynthia-rudin

内容概括
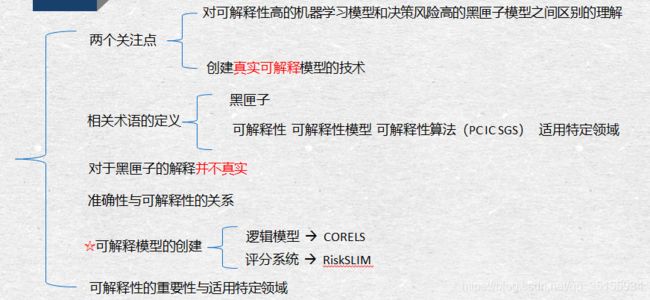
这里的重点 就是对可解释性与准确性的区分与关联 以及 可解释模型的创建方法。
一、研究背景
1.目前AI算法的风险:不可解释性与不稳定性
(这里参考了https://zhuanlan.zhihu.com/p/110255422 中浙江大学助理教授况琨对当下深度学习算法缺陷的介绍)
目前的AI算法大多数都是一个black box,存在不可解释性的问题,并且算法的预测特别不稳定 以一个简单的图片识别问题为例:识别一张图片中是否有狗。
在很多预测问题中,我们拿到的数据集往往都是有偏向性的,比如我们拿到的数据中有80%的图片中狗都在草地上,这样就导致在训练集中草地这一特征会和图片中是否有狗这个label十分相关。基于这样的有偏数据集学习一个预测模型,无论是LR,还是Deep Model,都很有可能会将草地这一特征学习成很重要的预测特征。
这样的预测模型,首先是不可解释的,其次,对于未来的测试数据集,如果和训练集一样也是狗在草地上,则模型可以得到正确的预测结果,当然测试数据集也可能是狗在沙滩上,但是背景中有一些树木或者绿植,这时模型也许能识别出来。但是对于狗在水里的图片,基于我们的训练集学习出来的模型肯定会识别不准。这样就导致了对于所有未知的测试数据集,模型的预测特别不稳定。
不可解释性与不稳定性产生的原因
不稳定性的产生首先可能是数据的问题。现有的大部分机器学习方法都需要IID假设,训练数据和测试数据应当是独立同分布的。在现实问题中,我们无法控制测试数据的产生,也就无法保证这一假设的成立。
换个角度,我们认为这是模型的问题。现有大部分机器学习模型主要是关联(Correlation)驱动的。关联主要有三个来源:Causation,Confounding,Selection Bias。
其中Causation(因果)是不会随着环境的变化而变化的(比如下雨会导致地面湿,这在任何城市和国家都是成立的),是稳定且可解释的。
而Selection Bias(偏向性选择)描述的就如上述草地和狗的相关性现象,我们通过样本选择,使得草地和狗十分相关;同样也可以使得沙滩等其它背景与狗十分相关。这种关联会随着数据集和环境变化而变化。
Confounding 描述的是由于忽略某些混淆变量导致的关联。
通过Confounding和Selection Bias产生的相关性是不稳定且不可解释的,我们称这两种相关性为Spurious Correlation即虚假相关。
传统方法预测不稳定且不可解释的主要原因就在于其没有区分因果关联与虚假关联,笼统地将所有关联都用于指导模型学习和预测。
机器学习(ML)现已广泛应用于对人类生活产生深远影响的高风险预测应用程序中。
但是由于许多ML模型都是黑匣子,无法在人类可以理解的范围内解释其预测。
缺乏透明性和可预测性的模型难以理解与解释,从而可能导致严重后果。
可解释学习的方法主要分成三类:(之前的博文:高阶项在深度学习可解释领域应用 最后也补充介绍了)
建模前解释;建立可解释模型;建模后解释。
本文主要针对建立可解释模型与建模后解释进行对比。
2.特定术语

可解释性是特定于域的概念,因此不能有通用的定义。但是,通常可解释的机器学习模型以模型形式受限,因此它对某人有用,或者服从领域的结构知识,例如单调性、可加性、因果关系等约束。
可解释模型是用于预测的模型,可以自己直接检验和人类专家解释。
可解释算法也是研究的目标。传统因果学习算法如PC IC SGS stable PC等等。
3.对于黑匣子的解释并不真实
事后解释:
对于为黑匣子模型的输出提供解释已经有了很多研究(常见的可视化 参数分析等等)
作者提出:
事后解释只是对黑匣子模型所做的事情的“猜测”,解释一定是错误的。他们不能对原始模型具有完美的忠诚度。如果解释完全忠实于原始模型的计算结果,则该解释将等于原始模型,并且首先不需要解释的就是原始模型。
实验验证:
COMPAS(替代性制裁的更正罪犯管理概况)à 种族预测 à 以近似值作为对黑匣子的解释 ×

显著性图可以展示出网络学习的着重点,但是并不能解释为什么将这一块当作着重点。
4.准确性与可解释性

作者引用了另外一篇论文中的实验,得到定性的一个结论:
在一定条件下,模型的准确性和可解释性存在一个此消彼长的关系(反比例关系说起来太绝对了)
但是作者在后面又针对这个结论,提出自己的见解,并用了一个独创的可解释算法证明了:
在准确性与可解释性之间存在一个平衡点,既保证了模型的精确度,又使得模型本身可解释(ProtoPNet模型)
5.创建可解释模型
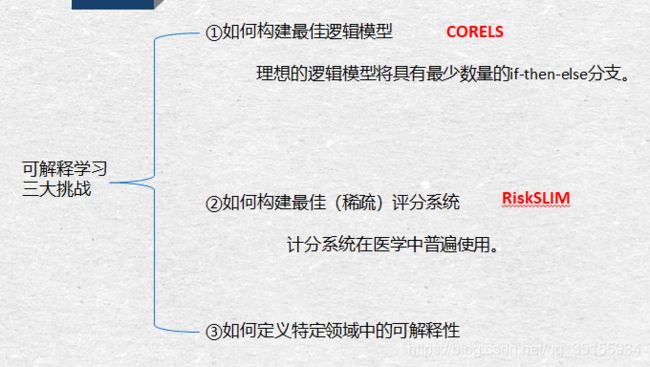
针对特定领域中的可解释性,作者“顺带”拿出了自己的私货——ProtoPNet,这个模型在19年貌似引起了不小的轰动,对深度学习可解释性学习领域的影响还是比较大的。
6.可解释模型的重要性
CDA数据分析师认为应重视机器学习模型的可解释性的主要原因如下:
①判别并减轻偏差(Identify and mitigate bias)
可解释性与准确性的权衡问题
②考虑问题的上下文(Accounting for the context of the problem)
使得上下文相关,符合实际情况
③改进泛化能力和性能(Improving generalisation and performance)
一个模型的好坏不仅仅取决于对当前问题的解决能力,还要分析该方法、思想的适用范围
④道德和法律原因(Ethical and legal reasons)
需要符合法律与道德规范,并且在科学领域仍高速发展的时代下,应提前发现问题制定规定
7.在特定领域设计可解释性

文章中的这部分内容,涉及到了下一篇论文,这里就藏点小宝贝了。
(另 热腾腾的PPT啥的 已经上传啦,可供参考
https://download.csdn.net/download/qq_35155934/12758269)