CycleGAN论文学习
CycleGAN论文学习 – 潘登同学的对抗神经网络笔记
文章目录
-
- CycleGAN论文学习 -- 潘登同学的对抗神经网络笔记
- CycleGAN介绍
-
- CycleGAN核心思想
- 过往方法
- 论文探究
-
- 模式崩溃问题
- Loss函数
-
- 回顾GAN的Loss
- Cycle-consistency loss
- 总体损失函数
- Baseline
-
- 选择pix2pix的目的
- 照片转油画改进
- Limitations
论文网站 https://junyanz.github.io/CycleGAN/

CycleGAN介绍
在上一节GAN开山之作中,只是将一组噪音随机数转为特定的图片,或者将特定的图片进行风格迁移,其实说只是将两个图片进行融合,而不是能将某一位画家的风格进行迁移,而且最终的图像到底还是不是原图还不一定;
而CycleGAN是Image Translation(图像转译)领域的经典深度学习算法,巧妙实现了两个非配对图像域的相互迁移,可以将两种图像域之间的图像进行互相转化,而转化后的图片是保留的原图,而画风用了不同的风格,也可以将某种风格画家的画去掉其风格;

CycleGAN核心思想
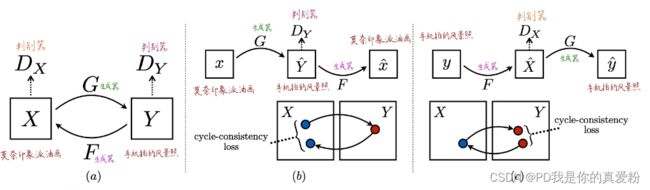
- 先将莫奈画的印象派油画扔到图像域X中,再把手机拍的风景照扔到图像域Y中;
- 然后训练两个生成器 ( G 、 F ) (G、F) (G、F),两个判别器 ( D X , D Y ) (D_X,D_Y) (DX,DY),执行GAN中的那一套
- 这里有一个非常重要的loss函数,cycle-consistency loss虽然Y经过生成器之后真的很像X,但是Y已经失去了自己,不再是自己了,那么实现的就不是风格迁移的任务,所以要对生成的X与Y本身再做一个Loss来保证只是迁移了风格,物体本身还是存在的;
过往方法
image-to-image translation图像转译是计算机图形领域的问题,要学习的任务就是从输入到输出的一一映射,这就要求图像像素级别的一一对齐,但是这样的数据是极度缺乏的;
所以该篇论文就是解决这种问题,只需要两组图像域的图片,不需要一一对应,甚至不需要图片张上的一一对应;
论文探究
模式崩溃问题
模式崩溃问题是指: 生成器产生单个或有限的模式(无论输入什么,输出结果都不变)
目前的深度神经网络只能够逼近连续映射,而传输映射是具有间断点的非连续映射,换言之,GAN训练过程中,目标映射不在DNN的可表示泛函空间之中,这一显而易见的矛盾导致了收敛困难;如果目标概率测度的支集具有多个联通分支,GAN训练得到的又是连续映射,则有可能连续映射的值域集中在某一个连通分支上,这就是模式崩溃(mode collapse);如果强行用一个连续映射来覆盖所有的连通分支,那么这一连续映射的值域必然会覆盖640?wx_fmt=gif之外的一些区域,即GAN会生成一些没有现实意义的图片。这给出了GAN模式崩溃的直接解释。
Loss函数
回顾GAN的Loss
min G ∣ max D Y V ( D Y , G ) = E x ∼ P d a t a ( x ) [ log D Y ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D Y ( G ( z ) ) ) ] \min_G|\max_{D_Y} V(D_Y,G) = E_{x\sim P_{data}(x)}[\log D_Y(x)] + E_{z\sim p_z(z)}[\log(1-D_Y(G(z)))] Gmin∣DYmaxV(DY,G)=Ex∼Pdata(x)[logDY(x)]+Ez∼pz(z)[log(1−DY(G(z)))]
Cycle-consistency loss
Cycle-consistency loss的作用
- 使得transfer过去的图像仍保留原始图像的信息
- 间接实现了pix2pix的paired image translation功能
- 防止了模式崩溃,总生成相同的图像


L c y c ( G , F ) = E x ∼ p d a t a ( x ) [ ∣ ∣ F ( G ( x ) ) − x ∣ ∣ 1 ] + E y ∼ p d a t a ( y ) [ ∣ ∣ G ( F ( y ) ) − y ∣ ∣ 1 ] L_{cyc}(G,F) = E_{x\sim p_{data}(x)}[||F(G(x))-x||_1] + E_{y\sim p_{data}(y)}[||G(F(y))-y||_1] Lcyc(G,F)=Ex∼pdata(x)[∣∣F(G(x))−x∣∣1]+Ey∼pdata(y)[∣∣G(F(y))−y∣∣1]
总体损失函数
L ( G , F , D X , D Y ) = L G A N ( G , D Y , X , Y ) + L G A N ( F , D X , Y , X ) + λ L c y c ( G , F ) L(G,F,D_X,D_Y) = L_{GAN}(G,D_Y,X,Y) + L_{GAN}(F,D_X,Y,X) + \lambda L_{cyc}(G,F) L(G,F,DX,DY)=LGAN(G,DY,X,Y)+LGAN(F,DX,Y,X)+λLcyc(G,F)
优化目标
G ∗ , F ∗ = arg min G , F max D X , D Y L ( G , F , D X , D Y ) G^*,F^* = \argmin_{G,F} \max_{D_X,D_Y} L(G,F,D_X,D_Y) G∗,F∗=G,FargminDX,DYmaxL(G,F,DX,DY)
Baseline
CycleGAN将pix2pix的模型作为baseline,有两类主流的任务: 语义信息转照片, 航拍图转地图;
会将不同模型生成的结果与原图一起给AMT众包平台上的志愿者进行打分(图灵测试), 而同一批志愿者对相同图片的打分结果如下

各模型生成的效果图如下:
- 语义信息转图像(CycleGAN还是比不过pix2pix)

- 航拍图转地图
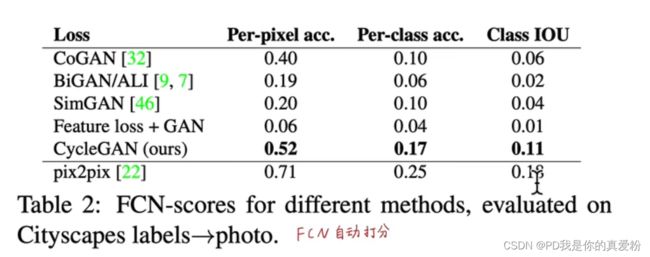
除了人工打分外,还有没有别的方法判断CycleGAN的好坏呢,论文给出了如下方法:
将语义标签输入给CycleGAN,生成图片,再将图片输入给FCN生成语义标签,如果最后FCN得到的标签与输入一致,那就说明CycleGAN表现的很好,进而能有很多的衡量指标,如IOU,acc等;
下图是比较结果
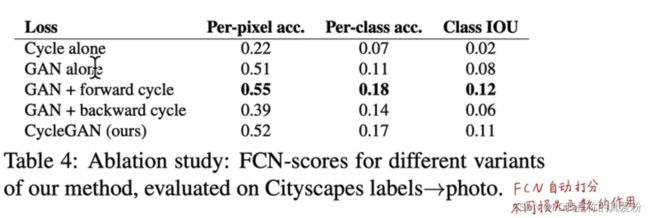
作者还评估了不同Loss函数的得分,在label转照片的时候,GAN+forward表现最好(因为只是第一阶段),而photo转labels的时候,总体损失函数(上面的三项加和)表现最好,因为照片转语义之后还要像照片才行,所以backward就必须考虑在内了;
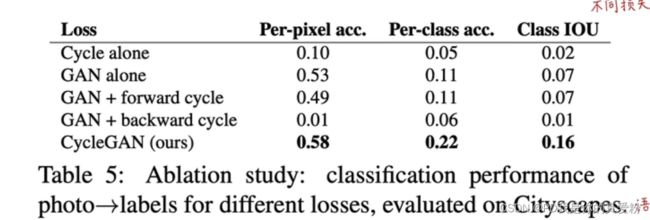
选择pix2pix的目的
首先是pix2pix也是作者自己的论文,其次pix2pix用的是像素级别的配对样本,是CycleGAN能达到的上界; 所以AI还是数据>算法>调参…
照片转油画改进
对于油画转照片,照片转油画任务,颜色问题总是会有,因为CycleGAN的目标是骗过判别器即可,但是人是很关注颜色问题的;所以可以在Loss出增加一个颜色的Loss函数 L i d e n t i t y L_{identity} Lidentity,目的是使得转换前后的图片颜色改变越小越好

Limitations
尽管CycleGAN能生成一些令人拍案叫绝的图片,但是他不是万能的,还是有失败案例的
- CycleGAN擅长改变颜色和纹理
- 不擅长改变几何形状(苹果转橘子,没有把苹果的柄去掉)
- 没有理解高级语义
- 没有先验知识和三维信息
- 没有条件输入信息(斑马和树林纹理都要学)
- 没有区分前景和背景


解决方案(作者留的坑): 引入弱监督或者半监督的语义标签
