Inception-v4,Inception-ResNet论文笔记
论文:Christian Szegedy,Sergey Ioffe,Vincent Vanhoucke,Alex Alemi.Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
摘要
非常深的卷积神经网络已经称为最近几年CV任务中的核心,比如Inception架构可以低计算代价实现高精度的特征抽取。本文在Inception-v3的基础上提出了Inception-v4,并将Inception架构和残差网络结合,提出Inception-ResNet-v1和Inception-ResNet-v2网络,这些网络在ILSVRC 2012分类任务上获得SOTA。还进一步证明了适当的激活值尺度可以稳定Inception-ResNet网络的训练。实现表明使用3个残差网络和1个Inception-v4集成的模型在ImageNet分类任务上达到了3.08%的top-5误差。
引言
自2012年AlexNet赢得ImageNet比赛的冠军后,已经成功被应用在各种计算机视觉任务上,比如:目标检测、图像分割、人体关键点检测、视频分类、目标跟踪、超分辨率技术。本文结合两种最新的技术(2016年):残差连接和Inception。残差连接对训练非常深网络非常重要,而Inception网络倾向于非常深,因此在Inception中加入残差连接是非常自然的思路。这可以使得Inception在保持计算效率的同时获得残差网络的优点。
除了简单的将残差连接和Inception进行简单集成,本文还研究了Inception网络是否可以通过将其加深和加宽来提高性能:在Inception-v3的基础上,通过简化架构并加入更多的Inception模块来构造Inception-v4模型。Inception-v3使用DistBelief进行分布式训练,现在模型训练迁移到Tensorflow后可对Inception进行简化。此外本文通过将Inception与残差连接结合,构造了Inception-ResNet模型。
本文比较了Inception-v3、Inception-v4、Inception-ResNet-v1、Inception-ResNet-v2这四个模型,最后的实验表明本文提出的Inception-v4和Inception-ResNet-v2在ImageNet上获得了SOTA精度。虽然单模型性能提高无法对集成模型产生一样多的提高,但是仍然达到了3.1% top-5错误率,达到SOTA。
相关工作
自AlexNet被提出后,CNNs在大规模图像识别任务上非常流行。后面出现了一些里程碑式的CNNs:NIN、VGG-net、GoogLeNet等。接着何凯明等人提出了ResNet,他们认为残差连接是训练非常深网络的必要结构。本文的观点似乎与这有些不同,实验发现在没有残差连接的情况下训练深的CNNs也是可行的,不过残差连接的加入提高了模型的训练速度。Inception模块在2014年被提出,整个网络称为GoogLeNet或Inception-v1,接着通过加入BN得到Inception-v2,然后又改进提出了Inception-v3。
下面是何凯明等人提出的残差连接:

下面是优化的残差连接模块:

架构设计
本文提出了3个模型Inception-v4、Inception-ResNet-v1、Inception-ResNet-v2。
Inception-v4
之前的Inception模型使用DistBelief进行分布式训练,Inception的设计受到了限制。为了优化训练速度,通常通过调整卷积层的大小用于平衡模型的计算量。然而,由于Tensorflow的引入,Inception的设计限制消失了。之前在改变模型架构的选择上相对保守,并将实验限制在不同的孤立的模型组件上,同时保持网络的其他部分稳定,这导致Inception模型过于复杂。本文提出Inception-v4摆脱将这些限制。
下面的图片展示Inception-v4的架构细节,其中没有”V”的卷积表示same-padded,即输入特征图的分辨率与输出一致;带”V”的卷积表示valid padded,即卷积的时候不padding。
下图是Inception-v4和Inception-ResNet-v2的stem网络:

下图是Inception-v4网络中的Inception-A模块:

下图是Inception-v4网络中的Inception-B模块:

下图是Inception-v4网络中的Inception-C模块:

下图是Inception-v4、Inception-ResNet-v1、Inception-ResNet-v2中用于将35x35xC特征图进行下采样所用到的模块Redution-A:
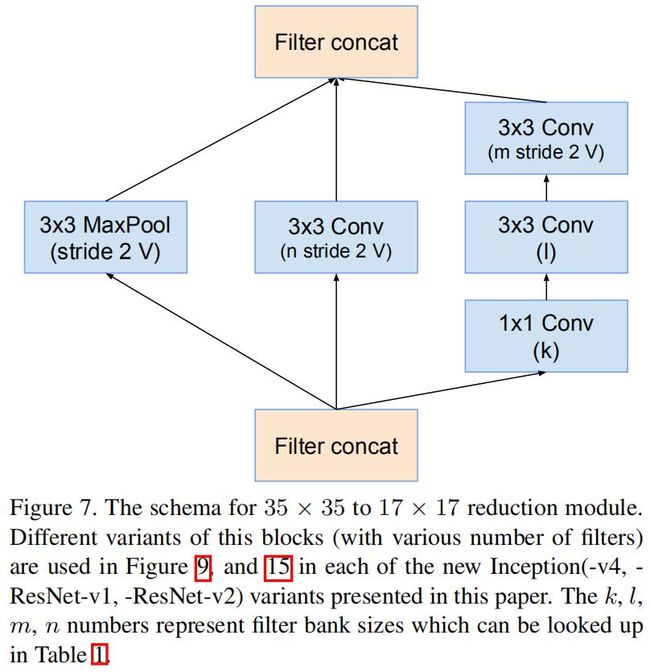
下图是Inception-v4中用于将17x17xC特征图进行下采样所用到的模块:

本文提出的Inception-v4网络:

Inception-ResNet网络
对于带残差的Inception网络使用更简化的Inception模块。每个Inception模块后跟着一个滤波器拓展层(即不带激活函数的1x1卷积层),用于放大输出滤波器的维度以便与“shortcut”相加。
带残差的Inception和原始Inception之间的一个不同之处在于仅在Inception里面加BN,而在相加层不加BN。这里为了更方便训练,具有大激活大小的层占用了很大的GPU内存。通过去掉这些BN层,可以增加更多的Inception模块。
本文尝试了多个残差版本的Inception,这里主要介绍两个Inception-ResNet-v1和Inception-ResNet-v2。前者的计算量与Inception-v3差不多,后者与Inception-v4差不多。图15是这两个网络的架构。
Inception-ResNet-v1网络中用到的Inception-ResNet-A模块:

Inception-ResNet-v1网络中用到的Inception-ResNet-B模块:

Inception-ResNet-v1网络中用到的Reduction-B模块:

Inception-ResNet-v1网络中用到的Inception-ResNet-C模块:

下图是Inception-ResNet-v1网络的stem部分:

下图是Inception-ResNet-v1和Inception-ResNet-v2的网络架构,两个网络中的模块的实现不同:

Inception-ResNet-v2网络中用到的Inception-ResNet-A模块:

Inception-ResNet-v2网络中用到的Inception-ResNet-B模块:

Inception-ResNet-v1网络中用到的Reduction-B模块:

Inception-ResNet-v2网络中用到的Inception-ResNet-C模块:

本文提出的各模型的参数量如下:

残差的尺度
本文发现若卷积滤波器的数量超过1000,则残差版本的Inception模型就会出现不稳定的状态,网络就“死”了,仅仅训练几千次迭代后AVG层输出的都为0了。而且这难以修正,既不是因为低学习率,也不是因为BN。
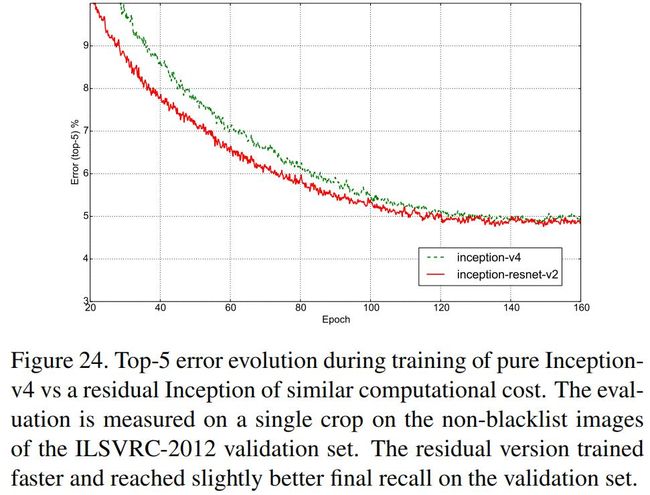
本文发现在残差相加之前缩小激活值可以将训练稳定下来,通常使用的缩小系数为0.1-0.3,如下图所示:

在ResNet的论文中也出现了类似的不稳定性,他们首先以低学习率来“warm-up”,然后再以高学习率,来解决这个问题。本文发现如果卷积滤波器的数量太多,即使学习率很低(0.00001)也无法将网络训练起来。而缩小残差的激活尺度可以解决这个问题,而这个尺度系数不影响最终的精度,但是可以稳定精度。
训练方法
本文的模型在Tensorflow上进行分布式训练,使用RMSprop,衰减系数为0.9,ε=1.0。初始学习率为0.045,每两轮的衰减系数为0.94。
实验结果
首先观察Inception-v3、Inception-ResNet-v1、Inception-v4、Inception-ResNet-v2这四个模型在ImageNet上的top-1和top-5错误率:





下表展示了各模型的单模型、单输入裁剪的top-1和top-1错误率的比较:

下表展示了各模型的单模型、多输入裁剪的top-1和top-1错误率的比较:
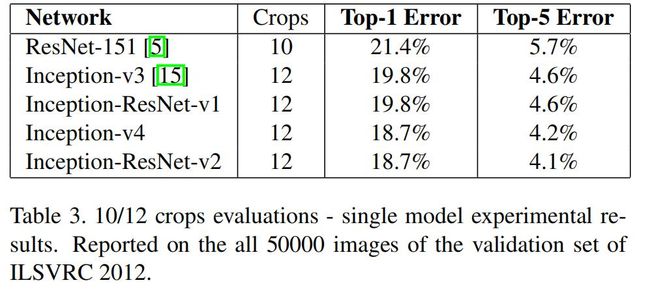
下表展示了各模型的单模型、144输入裁剪的top-1和top-1错误率的比较:

下表展示了各模型的多模型、多输入裁剪的top-1和top-1错误率的比较:
