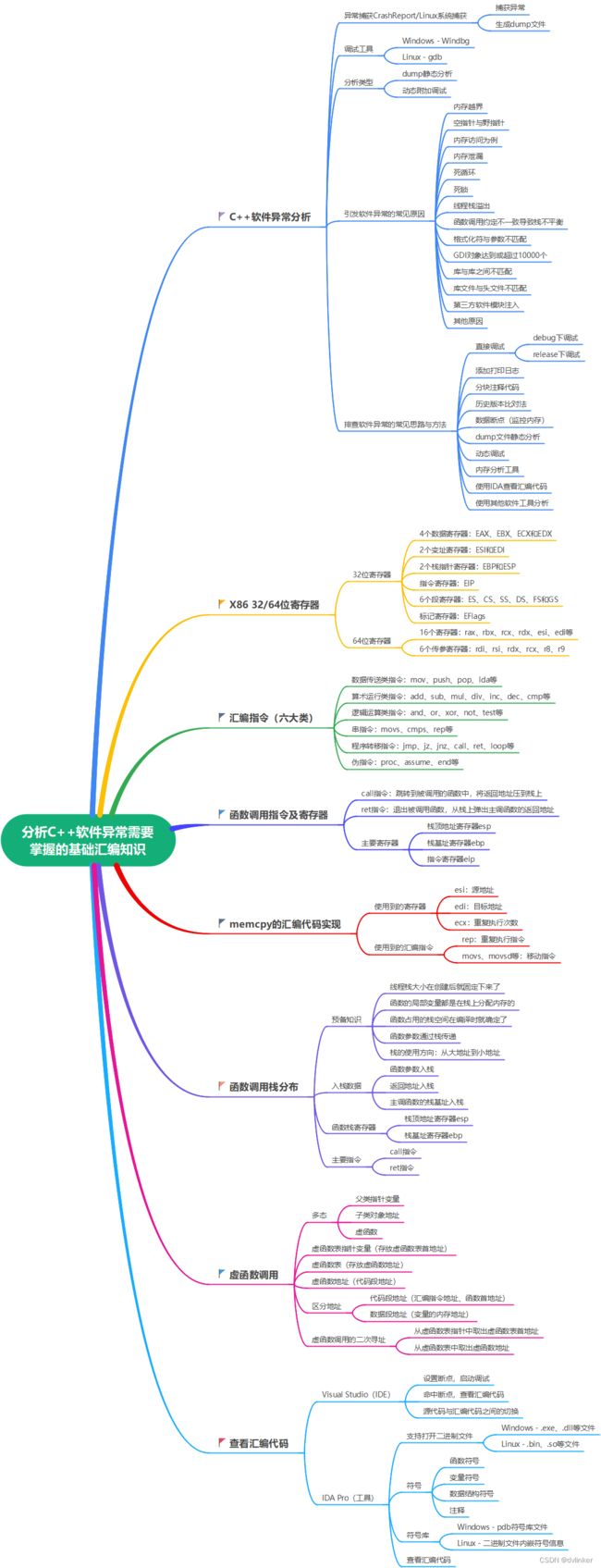
分析C++软件异常需要掌握的汇编知识汇总(实战经验分享)
目录
1、概述
1.1、异常捕获库CrashReport和调试器
1.2、有时需要查看汇编代码去定位问题
2、CPU架构
2.1、当前主流的CPU架构
2.2、国产CPU介绍
2.3、X86架构与ARM架构下的汇编代码的差异示例
3、常用寄存器
3.1、EAX寄存器
3.2、ECX寄存器
3.3、ESI和EDI寄存器
3.4、ESP和EBP寄存器
3.5、EIP寄存器
3.6、段寄存器
3.7、标志寄存器EFlags
4、汇编指令
4.1、汇编指令概述
4.2、call指令和ret指令
5、memcpy函数的汇编代码实现
6、C++函数调用时的栈分布
6.1、函数调用的预备知识
6.2、函数调用栈分布图
6.3、利用汇编代码详解函数调用时的栈分布
7、C++虚函数调用的汇编实现
7.1、虚函数调用过程中的两次寻址
7.2、虚函数调用的汇编代码走读
8、IDA反汇编工具
9、总结
在给开发部门的同事们做软件异常排查的技术分享时,我经常说这样一句话,我们在排查软件异常时,不仅要具备扎实的开发语言功底和业务能力,我们还要会使用多个软件工具来辅助问题的定位与排查,甚至还需要具备一定的汇编代码阅读与分析能力。软件异常最终是发生在某条汇编指令上,汇编代码才能最直观、最本真地反映出问题的本质所在。
作为高级语言的开发人员,大多数人对底层的汇编语言缺乏了解,很多人对汇编的认知还停留在大学教材上,很难将高级语言编写出来的代码与汇编指令对应起来。很多同事都觉得汇编比较难学,平时也很少接触到。同事们经常会问,汇编语言到底要学到什么程度,具体需要掌握哪些汇编领域的基本知识,才能地应对日常开发维护过程中遇到的多种软件异常问题。今天就来大概地给大家梳理一下排查C++软件异常所要了解和掌握的一些汇编方面的基本知识与要点。
1、概述
为了捕获到C++软件运行过程中的各种异常,我们需要给软件添加异常捕获模块以获取异常发生时的异常上下文信息并保存到dump文件中。在分析C++软件异常的过程中,可能需要去查看异常所在模块的汇编代码。
1.1、异常捕获库CrashReport和调试器

在Windows系统中,各大厂商主要使用google的开源库CrashReport来捕获异常,在很多知名软件的安装目录中都能看到CrashReport库的身影。在Linux系统中,则只要稍加配置就可以让系统捕获异常并生成dump文件。
拿到dump文件后,我们就可以使用调试工具打开dump文件进行分析了。在Windows系统中使用微软提供的强大调试工具Windbg,在Linux系统中则使用gcc套件中的gdb调试器。使用这些调试工具打开dump文件后,可以查看到发生异常的那条汇编指令,以及异常时的函数调用堆栈等信息。在拿到函数调用堆栈中相关库的符号库文件后,还可以看到具体的函数接口名及行号等详细信息,可以借助这些信息去对异常问题进行定位。
1.2、有时需要查看汇编代码去定位问题

有的崩溃仅凭上述信息难以定位问题,可能就需要去查看对应二进制文件的汇编代码上下文了。
一般我们使用交互式反汇编工具IDA Pro来打开二进制文件,去查看二进制文件中的汇编代码。IDA Pro既支持打开Windows下的.exe、.dll等二进制文件,也可以打开Linux下的.bin、.so等二进制文件。
那该如何查看汇编代码的上下文呢?一般我们不会直接去逐句地阅读IDA Pro解析出来的汇编代码,汇编代码比较晦涩难懂,通篇阅读汇编代码是需要很深的功底的。很多时候我们只需要对照着C++源代码,去看发生异常的那条汇编指令附件的上下文。但C++代码编译时,编译器会对代码进行大量的优化,我们最终看到的是经过优化后的二进制代码,所以有时很难一字一句地将汇编代码和C++代码对应起来,两者可能是有些出入的。
对于编译器的优化,比如在C++源码中有个函数调用,但在汇编代码中可能都没有函数调用(没有call函数的指令),直接使用几条汇编代码就代替了函数的调用,这样就节省了函数调用的开销(开销包括函数参数入栈出栈、寄存器的保护线程与恢复现场等),有效地提高了代码的运行速度与效率。
我们在排查问题时,主要依托汇编代码与C++源码的对应关系,快速地在C++源码中定位到出问题的点。我们平时主要是通过汇编代码上下文中的注释,并了解一些常用的汇编指令及常用寄存器的使用,熟悉函数调用时的参数入栈及参数寻址,了解虚函数调用的二次寻址的过程,去啃与异常紧密相关的若干条汇编代码,下面我们会详细地讲述这些需要掌握的汇编相关内容。
2、CPU架构
说到汇编指令,就不得不说与之紧密相关的CPU架构,不同架构有着不同的指令集。不同架构的汇编指令会有很大的差别,不仅在指令名称上有差别,寄存器名称上也有较大的不同。
2.1、当前主流的CPU架构
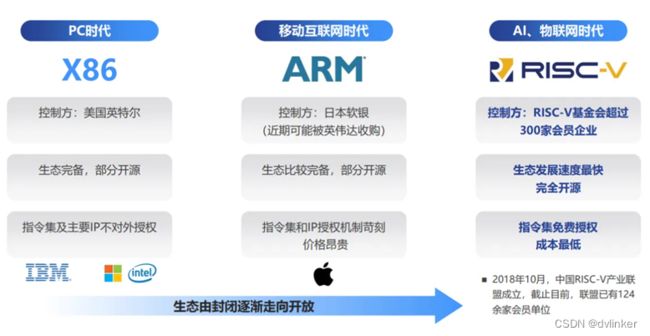
目前比较权威的CPU架构有AMD和Intel的X86架构,华为海思广泛采用的ARM架构,MIPS架构,开源RISC-V架构,还有国产的龙芯LoogArch架构等。
X86架构主要占据全球PC桌面和服务器领域大部分市场,PC桌面领域被Intel和AMD的CPU瓜分,服务器领域则大规模使用Intel的i系列高性能CPU和至强服务器专用CPU。
ARM公司的ARM架构则牢牢称霸移动处理器市场,主流的手机CPU厂商高通、华为、三星、联发科等均使用ARM架构。
已经终止开源的MIPS架构,已不复当年之勇,越来越多厂商都选择拥抱更加开放的开源RISC-V架构,甚至连X86架构巨头Intel和AMD都有介入。

龙芯中科的国产龙芯LoogArch架构,具有完全自主产权,采用龙芯架构的龙芯CPU取得了长足的进步,逐步缩短与顶级厂商Intel和AMD的差距。纯国产龙芯CPU的研制成功,实现了复兴号高铁100%国产化,让国产重型歼击机歼20的雷达和北斗导航卫星都装上了中国芯!
2.2、国产CPU介绍
既然说到CPU架构,我们顺便来看看国产CPU的发展情况。目前比较知名的国产CPU有龙芯、兆芯、华为鲲鹏、海光、申威和飞腾。
龙芯CPU早期采用MIPS架构,后来自研了LoogArch架构,目前最强的一款是龙芯3A5000系列,12nm工艺,早期由意法半导体代工,后来12nm的交给台积电代工。
兆芯CPU采用X86架构,目前最强的是KX-U6780A 处理器,16nm工艺,由台积电代工。
海光CPU采用X86架构,主要用于服务器方面,最新的是海光7000系列,14nm工艺,代工方是三星、格芯。
华为鲲鹏CPU采用ARM架构,主要也用于服务器方面,最新型号是鲲鹏920,7nm工艺,由台积电代工。
飞腾CPU采用ARM架构,有桌面版,也有服务器版,最新桌面版型号是D2000系列,采用16nm工艺,由台积电代工。
申威CPU采用Alpha架构,后面又自研了SW指令集,目前最新的是申威SW26010系列,采用28nm工艺,主要用于超级计算机,由中芯国际代工。
我们用的国产化桌面系统主要使用飞腾和龙芯的CPU,国产化操作系统方面则使用中标麒麟系统、银河麒麟系统和UOS通信系统。国产化服务器则主要使用海光的CPU。
2.3、X86架构与ARM架构下的汇编代码的差异示例
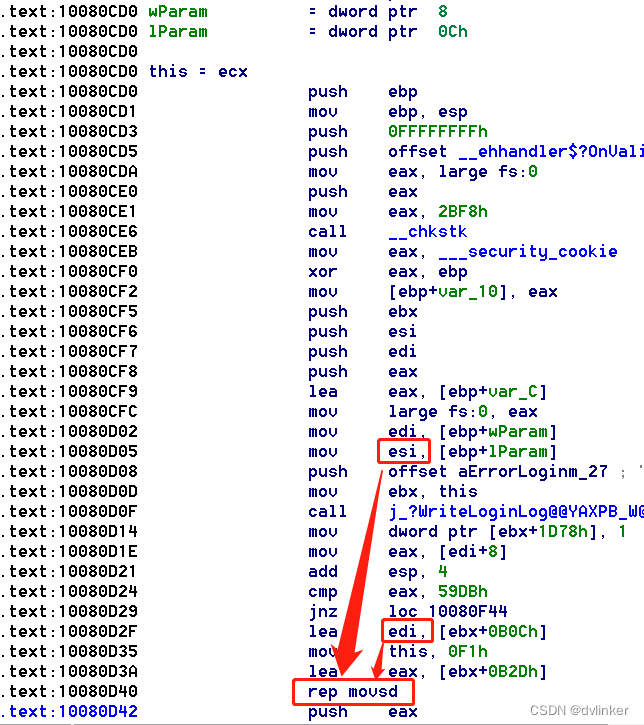
我们可以来看一下X86架构下的汇编代码与ARM架构下的汇编代码在细节上的区别。比如我们的客户端程序是运行在Intel X86架构上的软件,在该架构上编译出来的汇编代码片如下:
我们的部分业务服务器使用的是华为海思的CPU芯片(ARM架构),在该架构上编译出来的汇编代码片如下:
无论在汇编指令名称上,还是在寄存器名称上,两种架构下都有很大的差别。很多人可能对X86架构下的汇编指令比较熟悉,看到ARM架构下的汇编代码会觉得很不适应,更加的晦涩难懂。
本文涉及到汇编语言相关的内容,都是拿X86下的汇编指令来讲述的。
3、常用寄存器
最初X86中主要使用32位寄存器,后来AMD公司率先搞出了64位的X86寄存器。X86 32位寄存器主要有以下几类:
4个数据寄存器:EAX、EBX、ECX和EDX;
2个变址和指针寄存器:ESI和EDI;
2个指针寄存器:ESP和EBP;
1个指令指针寄存器:EIP;
6个段寄存器:ES、CS、SS、DS、FS和GS;
1个标志寄存器:EFlags。
在X86-64寄存器中,所有寄存器都是64位,相对32位的x86寄存器来说,标识符发生了变化,比如从原来的ebp变成了rbp。为了保持兼容性,32位寄存器都可以继续使用,比如ebp寄存器,不过指向了rbp的低32位。X86-64的64位寄存器主要有以下几类
64位下有16个寄存器:rax、rbx、rcx、rdx、esi、edi、rbp、rsp、r8、r9、r10、r11、r12、r13、r14、r15。
6个传参寄存器:依次为:rdi、rsi、rdx、rcx、r8、r9
因为32寄存器比较多见,本文讲解的问题中使用的都是32位寄存器,下面我们主要介绍一下32寄存器在C++汇编代码中的一些用途,了解这些寄存器的常用用途之后,对于阅读汇编代码很重要。
有些人可能会有疑问,讲X86 32位寄存器是不是没什么意义了,现在用的应该都是64位寄存器了吧?在Windows系统中,C++编写的应用程序为了兼容32位操作系统,还是使用32位编译器编译的,所以用的还是32位寄存器,所以介绍32寄存器还是有用的!
3.1、EAX寄存器
在X86汇编指令中,EAX主要用于存放函数调用的返回值,比如返回一个C++类指针地址的函数GetContainerPtr:
IContainerUI* GetContainerPtr()
{
// ......
}在call这个函数指令执行完成后,返回的类对象地址就保存到EAX寄存器中了。
将返回值保存到EAX寄存器中,其实是被调用函数中的ret指令实现的。执行ret指令时,会将适合4个字节的任意类型的返回值,比如32位C++程序中的类对象地址、int型变量的值,保存到EAX寄存器中的。这个细节在阅读汇编代码时比较重要。
3.2、ECX寄存器
在C++类的成员函数中都掩藏一个保存当前C++对象地址的this指针,成员函数中访问所属C++对象的成员变量时,都是通过this指针访问对应C++对象的成员变量的。
在C++汇编代码中,在调用C++成员函数时会使用ECX寄存器用来传递C++对象地址,即C++对象中的this指针。
在汇编代码中,在call一个类的成员函数之前,需要把对应的C++对象的地址先存入到ECX寄存器中。比如我们定义了COperateNum类,类中有个成员函数AddNum,我们使用COperateNum类定义了一个对象,然后通过该对象去调用类的成员函数AddNum,C++源代码如下所示:
class COperateNum
{
public:
int AddNum( int a, int b )
{
int nSum = a + b;
return nSum;
}
};
// 定义一个类对象,然后通过该对象去调用类的成员函数
COperateNum oeprateNum;
int nNum1 = 3, nNum2 = 5;
oeprateNum.AddNum( nNum1, nNum2 );我们使用的是微软的Visual Studio开发环境,可以在调试状态下查看C++代码对应的汇编代码,这段C++代码对应的汇编代码如下:

在调用COperateNum类的成员函数AddNum时,会先将要传入的参数压到栈上(通过栈传递参数的值),然后将COperateNum对象的地址保存到ECX中,即通过ECX传递COperateNum类对象的地址,然后再去call COperateNum::AddNum函数。
此外,ECX除了传递C++对象地址(this指针),还常用来存放循环执行的次数,下面在讲到memcpy的汇编代码实现时会详细说到这一点。
3.3、ESI和EDI寄存器
这两个是变址寄存器,ESI是源地址寄存器,EDI是目的地址寄存器,主要用于内存拷贝的串操作指令中,比如memcpy的汇编实现中。它们也可以作为通用寄存器来使用。
3.4、ESP和EBP寄存器
ESP是栈顶地址寄存器,EBP是栈基址寄存器,主要用来存放当前运行到的函数的栈起始地址(栈基址)和栈顶地址。
下图是A函数调用B函数的栈分布图,可以看到B函数的栈基址和栈顶地址,当代码运行到B函数中时,B函数的栈基址就保存到EBP中,B函数的栈顶地址就保存在ESP寄存器中:
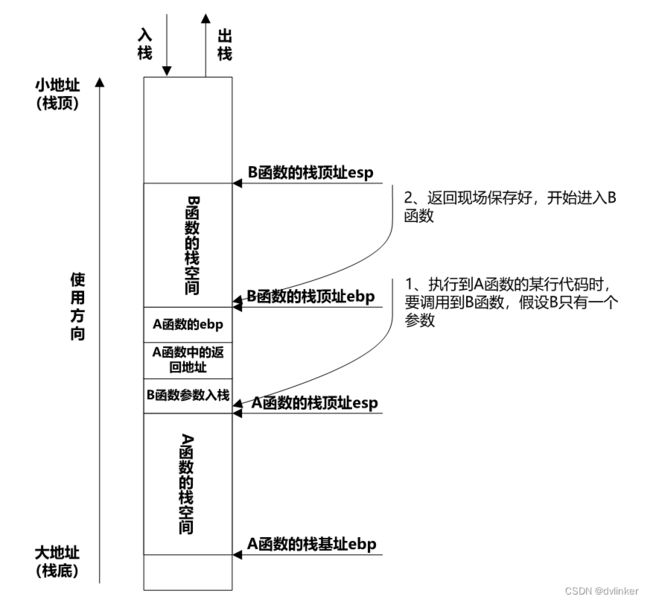
该图是函数调用时的大体栈分布图,这个图后面我们会详细说明,此处就不详细展开了。
EBP和ESP这两个寄存器很重要,函数中的局部变量都是在函数所占用的栈空间地址范围中分配的,在函数的汇编代码中,函数的局部变量要么通过EBP来寻址,要么是通过ESP来寻址。此外,函数调用堆栈的栈回溯正是通过EBP寄存器来实现的。对于栈回溯的原理,感兴趣的可以看看这篇文章:
C++栈回溯原理我们在使用VS调试源代码或使用Windbg调试exe程序时,遇到异常,调试器就会中断下来,然后就能查看到此刻的函数调用堆栈。软件是执行到某一句机器代码产生了异常,可以看成执行了某一句汇编代码产生了异常,通过一句汇编代码,是如何将所在线程此刻完整的函数调用堆栈给回溯进来的呢?下面我们就来讲讲栈回溯的原理。 要搞清楚栈回溯的原理,需要对照着函数调用时的栈分布情况来看:1、函数入口处的汇编代码 对照着上图,看一下函数入口的ebp和esp寄存器操作。...https://blog.csdn.net/chenlycly/article/details/121002139
3.5、EIP寄存器
EIP寄存器是用来存放即将要执行的汇编指令地址的。这里讲的汇编地址,是代码段的地址,和我们平时说的变量占用的内存(数据段地址)是两个概念,要注意区分一下,不要混淆。
当CPU从EIP寄存器中将汇编指令地址载入到CPU中时,EIP寄存器中的地址会自动累加,累加的值正好就是被取走的那条汇编指令的长度,这样EIP寄存器中的地址就是即将要执行的下一条汇编指令的地址了。
后面在讲到call指令和ret指令时,也会讲到EIP寄存器。
3.6、段寄存器
常用的段寄存器有CS、SS、DS、ES、FS和GS,这里我们简单讲述一下这些段寄存器的用途。
代码段寄存器CS(Code Segment)
存放当前正在运行的程序代码所在段的段基址,表示当前使用的指令代码可以从该段寄存器指定的存储器段中取得,相应的偏移量则由EIP寄存器提供。
数据段寄存器DS(Data Segment)
指出当前程序使用的数据所存放段的最低地址,即存放数据段的段基址。
堆栈段寄存器SS(Stack Segment)
指出当前堆栈的底部地址,即存放堆栈段的段基址。
附加段寄存器ES(Extra Segment)
指出当前程序使用附加数据段的段基址,该段是串操作指令中目的串所在的段。
FS和GS辅助段寄存器
FS和GS是80386起增加的两个辅助段寄存器。FS段寄存器Windows用来存储一些进程信息,FS段的首地址是存储这些进程信息的首地址,在内核态FS指向GDT表的0x30地址,在用户态FS等于0x3B。也就是说,当切换到用户态时,操作系统会把进程下正在执行的线程的某些信息写入到0X3B为起始地址的空间里。内核态时候也一样,操作系统也会写入一些关于内核程序的相关信息到0x30里。GS通常用作指向线程本地存储(TLS)的指针。
这些段寄存器我们只需要了解一下即可,不需要去深入追溯,汇编代码中会自动去维护这些段寄存器。
3.7、标志寄存器EFlags
标记寄存器主要是用来存放条件码标志,条件码标记则用来记录程序中运行结果的状态信息,它们是根据有关指令的运行结果由(CPU)自动设置的。由于这些状态信息往往作为后续条件转移指令的转移控制条件,所以称为条件码。
常见的标记位有:
进位标志CF(Carry Flag),记录运算时最高有效位产生的进位值。
符号标志SF(Sign Flag),记录运算结果的符号。结果为负时置1,否则置0。
零标志ZF(Zero Flag),运算结果为0时ZF位置1,否则置0。
溢出标志OF(Overflow Flag),在运算过程中,如操作数超出了机器可表示数的范围称为溢出。溢出时OF位置1,否则置0。
辅助进位标志AF(Auxliliary Carry Flag),记录运算时第3位(半个字节)产生的进位值。
奇偶标志PF(Parity Flag),用来为机器中传送信息时可能产生的代码出错情况提供检验条件。当结果操作数中1的个数为偶数时置1,否则置0。
4、汇编指令
4.1、汇编指令概述
X86汇编指令包括通用数据传送类指令、算术运算类指令、逻辑运算类指令、串指令、程序转移类指令和伪指令等几大类。
常见的数据传送类指令有mov、push、pop、lda等。
常用的算术运行类指令有add、sub、mul、div、inc、dec、cmp等。
常用的逻辑运算类指令有and、or、xor、not、test等。
常见的串指令则有movs、cmps、rep等。
常见的程序转移指令有jmp、jz、jnz、call、ret、loop等。
常见的伪指令有proc、assume、end等。
这些指令大概知道就行了,在阅读汇编代码时遇到不懂的或者不确定的,可以到网上查一下对应汇编指令的详细说明,比如这篇文章中就有对具体指令的详细说明:
汇编指令速查表有时我们需要查看汇编代码去分析软件问题,汇编代码才能最直观地反映出软件的问题。为了方便大家理解并记忆汇编指令,读懂汇编代码的上下文,此处列出常用汇编指令的使用说明,以供参考。https://blog.csdn.net/chenlycly/article/details/52235043 为了辅助记忆,也可以到下文中去查看一下常用汇编指令的英文全称:
汇编指令英文全称有时我们需要查看汇编代码去分析软件问题,汇编代码才能最直观地反映出软件的问题。为了方便大家理解并记忆汇编指令,此处列出常用汇编指令的英文全称,以供参考。https://blog.csdn.net/chenlycly/article/details/52240792
4.2、call指令和ret指令
call指令和ret指令对理解一些关键汇编代码很重要,所以这个地方要单独拿出来讲一下。
简单的说,call指令会跳转到指定的函数地址处执行,并将返回地址(主调函数中call指令的下一条指令)压入到栈上保存下来。
ret指令则是退出当前函数,并从栈中取出主调函数的返回地址(下一条指令)放到IP寄存器中,让代码返回到主调函数返回地址对应的位置继续向下执行。
CPU执行call指令和ret指令的具体过程如下:
call指令:CPU 将call func指令的机器码读入,IP寄存器就指向了主调函数中的call func指令的下一条指令(主调函数调用被调函数时的返回地址,被调用函数返回后执行该返回地址处的汇编指令),然后CPU执行call func指令,将当前的IP寄存器的值压栈(返回地址压入栈中),并将IP寄存器值改变为标号func处的地址(即call指令中的函数地址);
ret指令:CPU将ret指令的机器码读入,IP寄存器指向了ret 指令后的内存单元,然后CPU执行ret指令,从栈中弹出函数执行完后的返回地址(pop出栈操作会加esp),送入 IP寄存器中。然后再执行IP寄存器中的指令,即返回地址,即调用函数下面的下一条指令。
此处我们还要重点提下EIP寄存器。EIP寄存器中存放的是下一条即将被执行到的指令,当CPU将要执行的指令从IP寄存器中读到CPU中准备执行,IP寄存器中的地址会自动累加,自动累加的值就是CPU刚取走的那条指令的长度值,这样IP寄存器就指向下一条要执行的指令(IP寄存器中的值就是指令地址)。当CPU执行完当前指令后,就从EIP寄存器中读取下一条指令地址,执行下一条指令,这样代码就不断地执行下去。
注意,上面讲的地址均是代码段地址,和数据段的内存地址(变量的内存地址)是不同的。另外,上面讲的指令是二进制机器码,不是汇编代码,机器码和汇编代码有一一对应关系。比如我们在Visual Studio开发环境中可以看到如下的二进制机器码和汇编代码,如下:
5、memcpy函数的汇编代码实现
以下面一段执行memcpy操作的代码为例,将一个TStreamInfo结构体对象的值,拷贝到另一个TStreamInfo结构体对象中:
TStreamInfo* pStreamInfo = new TStreamInfo_Api;
// ...... // 对pStreamInfo进行赋值操作
TStreamInfo tCurStreamInfo;
memcpy( &tCurStreamInfo, pStreamInfo, sizeof(tCurStreamInfo) ); 我们再来看一下C函数memcpy的内部实现:
void * __cdecl memcpy (
void * dst,
const void * src,
size_t count
)
{
void * ret = dst;
#if defined (_M_IA64)
{
__declspec(dllimport)
void RtlCopyMemory( void *, const void *, size_t count );
RtlCopyMemory( dst, src, count );
}
#else /* defined (_M_IA64) */
/*
* copy from lower addresses to higher addresses
*/
while (count--) {
*(char *)dst = *(char *)src;
dst = (char *)dst + 1;
src = (char *)src + 1;
}
#endif /* defined (_M_IA64) */
return(ret);
}从memcpy内部的实现代码可以看出,通过循环去执行逐字节内存拷贝的操作。
对于memcpy在汇编代码上的实现,在此给大家详细介绍一下,下次在看到类似的汇编代码时,就能知道对应的是memcpy的操作。
上面执行memcpy的C++代码,对应的汇编代码,类似于下面的汇编代码片:

从汇编代码上看,memcpy内存拷贝的操作对应rep movsd指令,其中的d对应dword(在32位程序中是4字节),所以rep movsd等同于rep movs dword ptr es:[edi], dword ptr [esi]。这句汇编指令中用到了esi和edi寄存器,esi寄存器用于存放源内存地址,edi寄存器用于存放目标内存地址。
指令中还用到rep重复执行指令,rep指令每次执行时都会把ecx寄存器中的值读出来,如果ecx值大于0,就执行后面语句,执行完后,会让ecx中的值减1,然后再去执行rep指令,再去判断ecx中的值,直到ecx中的值为0,就退出rep指令。所以,在rep movsd指令之前会将需要重复执行的次数压入到ecx寄存器中。
对于rep movs dword ptr es:[edi],dword ptr [esi],每次拷贝dword 4字节数据,拷贝要重复执行N次,每执行一次movs操作,esi和esi寄存器中值都会累加。
6、C++函数调用时的栈分布
了解函数调用时的栈分布,对理解汇编代码的上下文至关重要。
6.1、函数调用的预备知识
函数调用是发生在某个线程中,单个线程的栈空间在创建线程时就固定下来了,在Windows系统中默认的线程栈空间大小为1MB,在创建线程时也可以修改这个默认值。
函数中的局部变量是在栈空间中分配内存的,函数调用时的参数的传递也是通过栈内存来传递的。在程序运行到一个函数的入口时,当前这个函数的栈内存的大小就分配好了,这是代码在编译期间就确定下来的。
另外,栈的使用方向从大地址向小地址的方向的,即先分配的栈内存是在大地址内存上的,后分配的内存是在小地址内存上的。
6.2、函数调用栈分布图
以A函数调用B函数为例,函数调用时的栈分布如下所示:
A函数在调用B函数时,会先将给B函数传递的参数压到栈上,然后去执行call指令,call指令会将主调函数中的返回地址压到栈上,然后跳转到B函数的起始地址(代码段地址)处执行。
然后在B函数的入口处,会将A函数(主调函数)的栈基址(A函数的栈基址存放在ebp寄存器中)压入到栈上保存下来。保存主调函数的栈基址,是为了回溯出函数调用堆栈的,这点会涉及到函数调用的栈回溯原理。
6.3、利用汇编代码详解函数调用时的栈分布
下面我们通过一段C++测试代码,来查看发生函数调用时涉及到栈分布的汇编代码。我们编写了一个将两个int型整数相加的函数Add,然后在main函数中去调用这个Add函数,C++源代码如下:
int Add(inta,intb)
{
int hSum = a+b;
return nSum;
}
int __cdecl _tmain(int argc,_ TCHAR* argv[])
{
int a = 3;
int b = 4;
int nSum = Add(a,b);
printf(" nSum = %d\r\n", nSum );
return 0;
}我们使用Visual Studio开发环境,可以在调用Add函数的代码附近打断点,然后调试运行,当命中断点时,右键点击断点处的代码,在从弹出的右键菜单中点击“转到反汇编”菜单项:
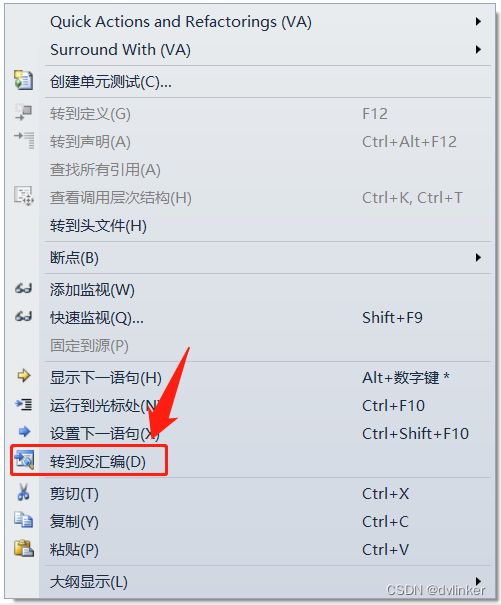
可以查看到调用Add函数附近的汇编代码如下:
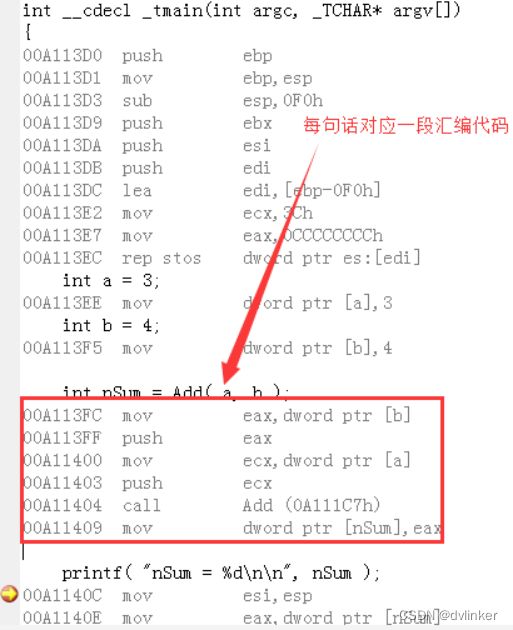
从汇编代码可以看出,在call Add函数之前,先将传给Add函数的参数a和b的值压到栈上,然后再去执行call Add函数的指令。这个call指令会把主调函数的返回地址压到栈上,当Add函数执行完后,会返回到这个返回地址对应的汇编代码处开始继续向下执行。
我们继续向下看,在执行完call指令后,Add函数的返回值就保存到eax寄存器中了,然后就把eax寄存器中的值设置给nSum变量了。
如果要从汇编代码页面返回到源代码页面,可以右键点击汇编代码,在弹出的右键菜单中点击“转到源代码”菜单项,如下:

然后我们再在Add函数中添加一个断点,让代码执行到该断点处,查看Add函数的汇编代码实现:

在Add函数的入口处,先执行了这两句汇编代码:
push ebp
mov ebp, esp每个函数的开头都有两句汇编指令。第一句汇编指令中的ebp寄存器中的值,其实是主调函数的栈基址,这句话是将主调函数的栈基址压到栈上保存下来。接下来的一句,是将esp栈顶寄存器中的值设置到ebp寄存器中,即当前的栈顶地址就是被调用函数的栈基址。ebp栈基址寄存器和esp栈顶寄存器中存放的栈基址和栈顶地址,是针对当前运行进入的某个函数来说的,即是该函数的栈基址和栈顶地址。
在Add函数结尾的地方,我们可以看到两句汇编指令:
mov esp, ebp
pop ebp这两句汇编指令,也是所有函数结尾处都有的。在退出Add函数时,要将Add函数的ebp寄存器值设置到esp中,在返回到主调函数后esp就要指向主调函数的栈顶地址了。pop ebp,就是将之前保存的主调函数的栈基址,从栈内存中pop出来,设置到ebp寄存器中。Add函数返回到主调函数中后,ebp就要指向主调函数的栈基址了。
最后执行的ret 8指令,也比较有意思,它有多个作用。首先,这个8是为了清理传入的两个int型变量占用的栈空间的,在函数返回后要保证栈平衡。其次,ret指令会从之前call指令压到栈上的主调函数的返回地址pop出来,然后设置到eip寄存器中,这样CPU就返回到主调函数中,从返回地址指向的汇编代码开始继续向下执行了。
注意,上面截图中除了显示汇编代码,还显示了二进制机器码,其实汇编代码是机器码的便于记忆的书写形式,即汇编代码是机器码的助记符,二者是完全等同的。之所以显示二进制机器码,是因为我们在右键菜单中勾选了“显示代码字节”。
7、C++虚函数调用的汇编实现

多态是C++中一个很重要的概念,C++代码中到处都在使用多态。多态可以描述为,将一个子类的对象赋给一个父类的指针,然后使用父类的指针去调用虚函数,实际调用的是子类实现的虚函数。
7.1、虚函数调用过程中的两次寻址
多态中虚函数的调用需要到虚函数表中找到虚函数的地址(函数代码段地址),然后再去call这个虚函数,整个过程会涉及到两次寻址。
整个过程中涉及到几个概念:虚函数表指针变量和虚函数表。只要类中有虚函数或者父类中有虚函数,那这个类中就会掩藏一个虚函数表指针,该指针中存放的就是虚函数表的首地址。虚函数表就是一段连续的内存,其中存放的就是虚函数地址,即每个虚函数的代码段地址。拿到虚函数的首地址,直接去call这个地址,就可以完成虚函数调用了。
在虚函数调用的具体过程中,子类对象的首地址,就是子类对象的内存起始地址,而子类的虚函数表指针变量在所在对象的内存排布上位于类对象内存的第一位,所以子类对象的首地址,就是类中虚函数表指针的首地址,取出该首地址内存中的内容,就是虚函数表指针变量中的内容,就是虚函数表的首地址,这是第一次寻址。
拿到虚函数表的首地址,再根据虚函数在虚函数表中的偏移,计算出目标虚函数在虚函数表中的位置,将该位置内存中的内容取出,就是虚函数的首地址,这样我们就可以直接去call这个虚函数的地址,完成虚函数调用了,这是第二次寻址。
7.2、虚函数调用的汇编代码走读
以如下的C++代码为例:
// 定义类
class CContact : public IContactPtr
{
CContact();
~CContact();
// ......
// 类中的虚函数func1
virtual func1();
// ......
};
// 获取IContactPtr类指针
IContactPtr* GetContactPtr()
{
// 此处return一个子类CContact对象地址
}
// 通过类指针调用类的虚函数func1
GetContactPtr()->func1();我们定义了一个继承于接口类IContactPtr的子类CContact,然后调用GetContactPtr接口获取一个父类的指针,指针中存放的是子类对象的地址,然后去调用虚函数func1。调用虚函数的func1的汇编代码如下:

先call函数 GetContactPtr获取CContact业务类指针,call完成后,CContact业务类指针
保存到eax寄存器中,下面来详细解释接下来的几句汇编代码:
(1)mov edx, [eax]
eax寄存器中存放的C++类对象首地址,该类对象首地址就是类中成员变量虚函数表指针变量的地址(虚函数表指针变量在内存排列上位于C++对象的首位),所以对eax取址得到的就是虚函数表指针变量中存放的虚函数表的首地址,将虚函数表的首地址存到edx寄存器中(第一次寻址)。
(2)mov ecx, [ebp+var_8]
将[ebp+var_8]内存中保存的C++类对象首地址再给到ecx寄存器中,是为了调用虚函数(C++类的成员函数IsExistLocalArchFile)传递类的this指针的,C++的汇编代码中是通过ecx寄存器传递this指针的。
(3)mov eax, [edx+140h]
目标虚函数在虚函数表中的偏移是140h,所以edx+140h就是目标虚函数在虚函数表中的内存地址,对edx+140h取址(即[edx+140h])得到的就是虚函数表中存放的目标虚函数的首地址(虚函数代码段的地址),然后将虚函数的首地址放置到eax寄存器中,接下来直接去call eax,就是去调用虚函数了。(第二次寻址)
至此,就完成虚函数的调用了。
所以,在阅读到类似于上面的汇编代码时,就要下意识地想到,可能是虚函数调用对应的代码块。如果不了解虚函数调用的汇编代码实现,很难读懂这块汇编代码的。
8、IDA反汇编工具
上面我们说过,可以在Visual Studio中查看C++代码对应的汇编代码。只需要在C++代码中设置断点,开启调试运行,当命中断点时,右键点击断点附近的C++源码,在弹出的右键菜单中点击“转到反汇编”,就可以看到汇编代码了。在右键菜单中点击“显示代码字节”,还可以看到二进制机器码。我们可以利用这个途径,去熟悉去学习汇编代码,有效地将C++源码和汇编代码联系起来。
在实际工作中,我们一般使用反汇编工具IDA去打开二进制文件,查看二进制文件中的汇编代码。IDA既支持打开Windows下的.exe、.dll等二进制文件,也可以打开Linux下的.bin、.so等二进制文件。
使用IDA查看WIndows平台上二进制文件的汇编代码时,最好拿来二进制文件对应的.pdb符号库文件(文件中包含函数及变量的符号信息),将pdb文件放在二进制文件的同级目录中,这样IDA在打开二进制文件时会去自动加载pdb符号库文件。加载符号库后,汇编代码中能看到具体的函数名及变量注解,以及一些额外的注释信息。通过这些注释信息,可以很好地将C++代码和汇编上下文对应起来,这样我们能快速搞懂汇编代码的上下文,定位发生异常的原因。
至于如何使用IDA查看二进制文件的汇编代码,可以查看我之前写的一篇关于如何使用IDA的文章:
IDA反汇编工具使用详解详细介绍IDA反汇编工具的使用。https://blog.csdn.net/chenlycly/article/details/120635120 其实这里我们只是用了IDA的一小部分功能,IDA应该是当今最强大的一款反汇编工具,在逆向工程领域有着广泛的应用。
此外,在Windows系统中我们主要使用Windbg去分析软件异常,使用Windbg打开异常捕获模块捕获到的dump文件,至于如何使用Windbg可以查看文章:
Windbg调试工具使用详解1、Windbg简介Windbg是微软提供的Windows平台下强大的用户态和内核态调试利器,给我们分析Windows上软件的异常提供了极大的便利和有力的支持,比原始的直接查看代码分析异常的效率要来的高的多。Windbg在某些方面甚至要比微软的Visual Studio还要强大。 Windbg的主界面如上所示。Windbg可以静态分析dump文件,也可以对目标进程进行动态调试。Windbg可以直接启动进程,也可以附加到正在运行的目标进程上,可以查看进程运行时变量内存中的数据。Windbg在排查死..https://blog.csdn.net/chenlycly/article/details/120631007
9、总结
以上是我多年来处理软件异常问题的心得和经验总结。大家在了解上面讲到的一些关于汇编语言的基本点和细节之后,结合一些排查软件异常常用的方法和工具软件,应该就能很好地应对日常开发维护中遇到的多种软件异常问题了。当然要熟练掌握这些技能,要去不断的实践,多去分析项目中遇到的多个异常问题,不断的积累经验。
在日常开发维护工作中,不要仅仅只研究自己负责的模块问题,底层模块(比如网络模块、协议模块、组件模块、开源组件模块、音视频编解码模块等)的一些发生崩溃和异常,也可以去看看,主动去协助兄弟部门去排查,不仅能见识更多类型的软件异常,积累更多的经验,还能扩大眼界,能了解底层库的实现逻辑和编码的思想,这对于把握整个系统的业务有很大的作用!学习是需要主动的,需要主动去发掘一些学习的机会,再和其他开发组的同事一起联调、一起排查问题、一起交流时,也能学到不少东西的!
有不少入职一两年的应届生,经常会说他们学不到什么东西了,其实很多时候还是他们不够主动,把眼光仅仅局限在自己做的模块中,没有积极主动地发掘学习的机会!
我之前已经创建了C++软件异常排查的技术专栏,专栏中系统地讲述了引发C++软件异常的常见原因,并详细阐述了解决这些异常的常用方法以及一些常用的软件工具,相关文章链接如下:
引发C++软件异常的常见原因分析引发C++软件异常的常见原因分析。https://blog.csdn.net/chenlycly/article/details/121054292排查C++软件异常的常见思路与方法排查C++软件异常的常见思路与方法https://blog.csdn.net/chenlycly/article/details/120629327 后面我会在该专栏中持续输出这类主题的文章,并给出项目中遇到的各种软件异常分析实例,争取给大家提供一些更具体的借鉴与参考。