Self-supervised Pre-training and Contrastive Representation Learning for Multiple-choice Video QA
AAAI 2021
Abstract
In this paper, we propose novel training schemes for multiple-choice video question answering with a self-supervised pre-training stage and a supervised contrastive learning in the main stage as an auxiliary learn- ing.
1. In the self-supervised pre-training stage, we transform the original problem format of predicting the correct answer into the one that predicts the relevant question to provide a model with broader contextual inputs without any further dataset or annotation.
2. For contrastive learning in the main stage, we add a masking noise to the input corresponding to the ground-truth answer, and consider the original input of the ground-truth answer as a positive sample, while treat- ing the rest as negative samples.
Introduction

In our setting, we additionally extract object in- formation and visual features from the video frames using Faster R-CNN and ResNet-101 as in the bottom right yel- low box. We use question, answer, subtitles, and objects as our text input and visual features as our visual input.
Framework
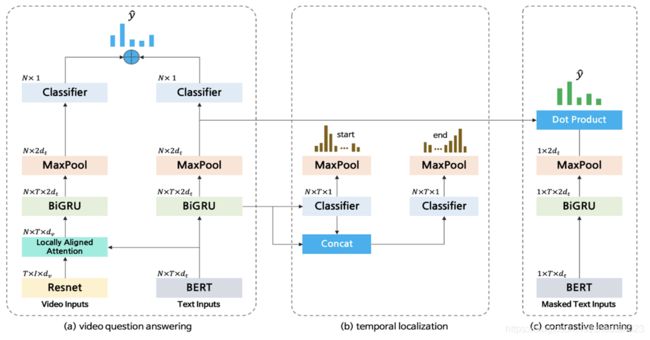
(a) For a video QA part, we use ResNet and BERT to extract video and text representations. A locally aligned attention mechanism is introduced to match each subtitle sentence with the corresponding images. Then, we use RNNs to learn sequential information of subtitle sentences. We predict the final answer distribution on both modalities. At inference time, we use this video QA part only.
(b) Temporal localization, one of our auxiliary tasks, is used to predict the necessary part to answer the question.
(c) We introduce the contrastive loss, which is another component of our auxiliary tasks, to enhance the model’s performance.
We utilize the identical BERT and RNN, used in a video QA part with the masked text input of the ground-truth and predict the answer distribution by contrasting positive pair against negative pairs.
Example


Examples of predictions of models with or without the contrastive loss and the self-supervised pre-training scheme. The ground truths are denoted in red, and the predictions of our proposed model are colored in green.
result
TVQA:

TVQA+:

DramaQA:

video QA datasets: TVQA, TVQA+, and DramaQA.
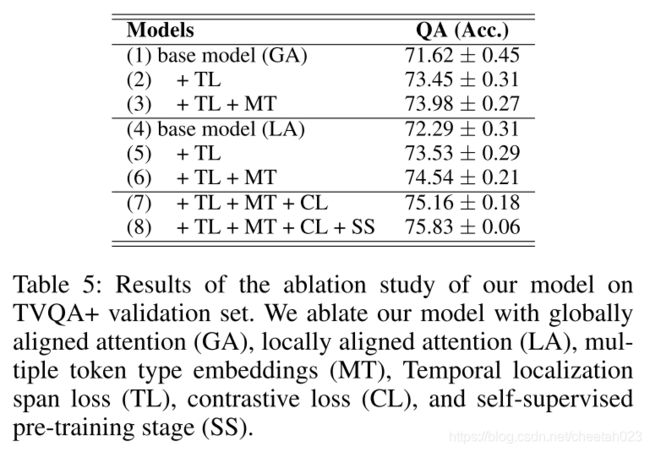
Experimental results show that our model achieves state-of-the-art performance on all datasets.