2022_WSDM_Contrastive Meta Learning with Behavior Multiplicity for Recommendation
[论文阅读笔记]2022_WSDM_Contrastive Meta Learning with Behavior Multiplicity for Recommendation
论文下载地址: https://doi.org/10.1145/3488560.3498527
发表期刊:WSDM
Publish time: 2022
作者及单位:
- Wei Wei1,3, Chao Huang1,2∗, Lianghao Xia1, Yong Xu3, Jiashu Zhao4, Dawei Yin5
- 1Department of Computer Science,2Musketeers Foundation Institute of Data Science, University of Hong Kong
- 3South China University of Technology,4Wilfrid Laurier University,5Baidu Inc
- [email protected], [email protected], [email protected],
- [email protected], [email protected], [email protected]
数据集: 正文中的介绍
- Tmall
- IJCAI-Contest
- Retail Rocket
代码:
- https://github.com/weiwei1206/CML.git (文中作者给的)
其他:
其他人写的文章
简要概括创新点: (1)Contrastive Meta Learning
- We propose a new multi-behavior learning paradigm CML for recommendation by emphasizing the importance of diverse and multiplex user-item relationships, as well as tackling the label scarcity problem for target behaviors. (我们提出了一种新的多行为学习范式CML推荐,强调了多样化和多元化*的用户-项目关系的重要性,并解决了目标行为的 标签稀缺问题。)
- In our CML framework, we design a multi-behavior contrastive learning paradigm to capture the transferable user-item relationships from multi-typed user behavior data, which incorporates auxiliary supervision signals into the sparse target behavior modeling. (在我们的CML框架中,我们设计了一个多行为对比学习范式,从多类型用户行为数据中捕获可转移的用户-项目关系,该范式将辅助监督信号纳入稀疏目标行为建模中。)
- Furthermore, our proposed meta contrastive encoding scheme allows CML to preserve the personalized multi-behavior characteristics, so as to be reflective of the diverse behavior-aware user preference under a customized self-supervised framework. (此外,我们提出的 元对比编码方案允许CML保留 个性化的多行为特征,从而在定制的 自我监督框架下反映用户的不同行为感知偏好。)
ABSTRACT
- (1) A well-informed recommendation framework could not only help users identify their interested items, but also benefit the revenue of various online platforms (e.g., e-commerce, social media). (一个消息灵通的推荐框架不仅可以帮助用户识别他们感兴趣的项目,还可以从各种在线平台(如电子商务、社交媒体)的收入中受益。)
- (2) Traditional recommendation models usually assume that only a single type of interaction exists between user and item, and fail to model the multiplex user-item relationships from multi-typed user behavior data, such as page view, add-to-favourite and purchase. (传统的推荐模型通常假设用户和项目之间只存在单一类型的交互,而无法从页面浏览、添加到收藏夹和购买等多类型用户行为数据中建模多重用户-项目关系。)
- (3) While some recent studies propose to capture the dependencies across different types of behaviors, two important challenges have been less explored: (虽然最近的一些研究提出要捕捉不同类型行为之间的依赖关系,但有两个重要的挑战尚未被探索:)
- i) Dealing with the sparse supervision signal under target behaviors (e.g., purchase). (处理目标行为(如购买)下的稀疏监督信号。)
- ii) Capturing the personalized multi-behavior patterns with customized dependency modeling. (通过定制的依赖关系建模捕获个性化的多行为模式。)
- (4) To tackle the above challenges, we devise a new model CML, Contrastive Meta Learning (CML), to maintain dedicated crosstype behavior dependency for different users. (为了应对上述挑战,我们设计了一种新的模式CML,即对比元学习(CML),为不同的用户维护专用的跨类型行为依赖。)
- In particular, we propose a multi-behavior contrastive learning framework to distill transferable knowledge across different types of behaviors via the constructed contrastive loss. (特别是,我们提出了一个多行为对比学习框架,通过构建的对比损失提取不同类型行为的可转移知识。)
- In addition, to capture the diverse multi-behavior patterns, we design a contrastive meta network to encode the customized behavior heterogeneity for different users. (此外,为了捕捉不同的多行为模式,我们设计了一个对比元网络来编码不同用户的定制行为异质性。)
- (5) Extensive experiments on three real-world datasets indicate that our method consistently outperforms various state-of-the-art recommendation methods. (在三个真实数据集上的大量实验表明,我们的方法始终优于各种最先进的推荐方法。)
- (6) Our empirical studies further suggest that the contrastive meta learning paradigm offers great potential for capturing the behavior multiplicity in recommendation. We release our model implementation at: https://github.com/weiwei1206/CML.git (我们的实证研究进一步表明,对比元学习范式为捕获推荐中的行为多样性提供了巨大的潜力。我们将在以下网站发布我们的模型实现:https://github.com/weiwei1206/CML.git.)(https://github.com/weiwei1206/CML.git).
CCS CONCEPTS
• Information systems → Recommender systems.
KEYWORDS
Collaborative filtering, Self-Supervised Learning, Multi-Behavior Recommendation, Meta Learning, Graph Neural Network
1 INTRODUCTION
-
(1) Recommender systems have emerged as critical components to alleviate information overloading for users in various online applications, e.g., e-commerce [40], online video platform [46] and social media [30]. The goal is to learn user preference and forecast the items that he or she will consume based on observed user behaviors. (推荐系统已经成为缓解各种在线应用中用户信息过载的关键组件,例如电子商务[40]、在线视频平台[46]和社交媒体[30]。目标是了解用户偏好,并根据观察到的用户行为预测他或她将消费的商品。)
-
(2) Among various recommendation techniques, (在各种推荐技巧中)
- collaborative filtering (CF) has become the most promising recommendation architecture to model historical user interactions over items [4, 57]. (协同过滤(CF) 已经成为最有前途的推荐体系结构,可以对项目上的历史用户交互进行建模[4,57]。)
- Commonly, the core of existing CF paradigm is to project users and items into latent representation space such that their interaction structural information is preserved. (通常,现有CF 范式的核心是将用户和项目投影到潜在的表示空间 中,从而保留其交互结构信息。)
- For example, Autoencoder has been employed as the effective embedding function for the representation projection in AutoRec [33] and CDAE [49]. (例如,Autoencoder在AutoRec[33]和CDAE[49]中被用作表示投影的有效嵌入函数 。)
- To inject the high-order connection signals in CF, another promising research line model user-item interactions as a graph and generate the user/item feature representations with the graph structural information preserved. (为了在CF中注入高阶连接信号,另一条有前途的研究路线将用户-项目交互建模为图 ,并在保留图结构信息 的情况下生成用户/项目特征表示。)
- These models perform the message passing over the interaction graph to generate node-level embeddings layer by layer, such as PinSage [53], NGCF [43] and LightGCN [15]. (这些模型通过交互图执行消息传递, 以逐层生成节点级嵌入,例如PinSage[53]、NGCF[43]和LightGCN[15]。)
- collaborative filtering (CF) has become the most promising recommendation architecture to model historical user interactions over items [4, 57]. (协同过滤(CF) 已经成为最有前途的推荐体系结构,可以对项目上的历史用户交互进行建模[4,57]。)
-
(3) However, the majority of existing recommendation models assume that only a single type of interaction exists between user and item, whereas in practical recommendation scenarios are multiplex in nature [12, 41]. (然而,大多数现有的推荐模型都假设用户和项目之间只存在单一类型的交互,而在实际推荐场景中,这种交互本质上是多重的[12,41]。)
- Taking the online retail platform as an example, users can interact with items in multiple manners, including page view, add-to-favourite and purchase. (以在线零售平台为例,用户可以通过多种方式与商品互动,包括页面浏览、添加到收藏夹和购买。)
- Different types of behaviors may characterize user preference from different intention dimensions and complement with each other for better user preference learning [37]. (不同类型的行为可以从不同的意图维度表征用户偏好,并相互补充,以更好地学习用户偏好[37]。)
- Therefore, it is challenging but valuable to capture behavior multiplicity and the underlying dependencies in recommendation. (因此,在推荐中捕捉行为的多样性和潜在的依赖性是很有挑战性但很有价值的。)
- To address this challenge, existing work models the behavior dependency by introducing different aggregation schemes to integrate type-specific behavior embeddings, to enhance the representation on target user behaviors (e.g., customer purchase) [23, 50, 51]. (为了应对这一挑战,现有工作通过引入不同的聚合方案来建模行为依赖性,以集成特定类型的行为嵌入,从而增强对目标用户行为(例如,客户购买)的表示[23,50,51]。)
- For example, MATN [50] adopts the self-attention to encode the pairwise correlations between different types of behaviors, and make predictions on the target behaviors. (例如,MATN [50]采用自我注意 编码不同类型行为之间的 成对相关性 ,并对目标行为进行预测。)
- A relation-aware embedding propagation layer is developed to learn the behavior multiplicity in MBGCN [23], to gather multi-behavior interaction information from high-order neighbors. (开发了一个感知嵌入传播层,用于学习MBGCN [23]中的 行为多样性,从高阶邻居 收集多行为交互信息。)
-
(4) Despite the effectiveness of existing methods, these studies share two common limitations: (尽管现有方法有效,但这些研究有两个共同的局限性:)
- First, Sparse Supervision Signal under Target Behaviors: the most of current multi-behavior recommender systems are trained with supervised information in an end-to-end manner. (首先,目标行为下的稀疏监督信号:目前大多数多行为推荐系统都是用监督信息进行端到端的训练。)
- That is to say, for making forecasting on the target user behaviors, it is required to have sufficient labeled data corresponding to the target behaviors (e.g., user purchase data). (也就是说,为了对目标用户行为进行预测,需要有足够的与目标行为相对应的标记数据(例如用户购买数据)。)
- Unfortunately, the observed interactions under the target behavior type, are often sparse as compared with other types of user-item interactions. (不幸的是,与其他类型的用户项交互相比,在目标行为类型下观察到的交互通常是稀疏的。)
- For example, purchase prediction task in online retail system still faces the challenge of lacking of ground-truth labels [20]. Hence, directly integrating type-specific behavior embeddings will sacrifice the performance due to lacking supervision signals of target behaviors. (例如,在线零售系统中的购买预测任务仍然面临缺乏地面真相标签的挑战[20]。因此,由于缺乏目标行为的监督信号,直接集成特定类型的行为嵌入将牺牲性能。)
- Second, Personalized Multi-Behavior Patterns: multi-behaviour patterns may vary by users. Semantics of multi-typed user-item interactions and their mutual relationships are diverse, depending on the personalized characteristics of users [27]. Without considering diverse user intents which motivates different types of user behaviors, previous modeling of multiplex user-item relationships leads to suboptimal representations. (第二,个性化的多行为模式:多行为模式可能因用户而异。根据用户的个性化特征,多类型用户项交互的语义及其相互关系是多样的[27]。在没有考虑激发不同类型用户行为的不同用户意图的情况下,以前对多重用户项关系的建模会导致次优表示。)
- First, Sparse Supervision Signal under Target Behaviors: the most of current multi-behavior recommender systems are trained with supervised information in an end-to-end manner. (首先,目标行为下的稀疏监督信号:目前大多数多行为推荐系统都是用监督信息进行端到端的训练。)
-
(5) Contributions.
- Having realized the above challenges for recommendation with behavior multiplicity, we focus on exploring diverse multi-behavior patterns under a contrastive self-supervised learning prototype. (在意识到上述行为多样性推荐的挑战后,我们专注于在对比自我监督学习原型下探索不同的多行为模式。)
- Towards this end, this work proposes a new model-Contrastive Meta Learning (CML) for multi-behavior recommendation. In CML, we design a multi-behavior contrastive learning framework to capture the cross-type interaction dependency from different behavior views. (为此,本文提出了一种新的多行为推荐模式——对比元学习(CML)。在CML中,我们设计了一个多行为对比学习框架,从不同的行为视角捕捉跨类型交互依赖 。)
- This endows our developed recommender system to effectively distill additional supervision signal from different types of user behaviors, which augments the model optimization process with sparse supervision labels. (这使得我们开发的推荐系统能够有效地从不同类型的用户行为中提取额外的监督信号,从而用稀疏的监督标签来 增强模型优化过程)
- Inspired by the recent success achieved by self-supervised representation learning, we leverage the idea of contrastive learning to design cross-type behavior dependency modeling task with the user self-discrimination. (受 自监督表征学习 最近取得的成功的启发,我们利用对比学习 的思想设计了具有用户自辨别能力 的 跨类型行为依赖 建模任务。)
- The goal of our multi-behavior contrastive learning is to reach the agreement between user’s type-specific behavior representations via the constructed contrastive loss. (我们的多行为对比学习 的目标是通过构建的对比损失 ,在用户特定类型的行为表征 之间达成一致。)
- In addition, to handle the preference diversity of users and capture the personalized multi-behavior patterns, we design contrastive meta network to characterize the customized behavior heterogeneity, empowering CML to maintain dedicated representations for different users. (此外,为了处理用户偏好的多样性和捕捉个性化的多行为模式,我们设计了对比元网络来描述定制的行为异质性,使CML能够为不同的用户维护专用的表示。)
- Our meta contrastive encoder first extracts the personalized meta-knowledge from users, and then feeds it into our weighting function for customized multi-behavior dependency modeling. (我们的元对比编码器首先从用户那里提取个性化的元知识,然后将其输入到我们的加权函数中,用于定制多行为依赖建模。)
-
(6) In a nutshell, this work makes the following contributions: (简而言之,这项工作做出了以下贡献:)
- We propose a new multi-behavior learning paradigm CML for recommendation by emphasizing the importance of diverse and multiplex user-item relationships, as well as tackling the label scarcity problem for target behaviors. (我们提出了一种新的多行为学习范式CML推荐,强调了多样化和多元化*的用户-项目关系的重要性,并解决了目标行为的 标签稀缺问题。)
- In our CML framework, we design a multi-behavior contrastive learning paradigm to capture the transferable user-item relationships from multi-typed user behavior data, which incorporates auxiliary supervision signals into the sparse target behavior modeling. (在我们的CML框架中,我们设计了一个多行为对比学习范式,从多类型用户行为数据中捕获可转移的用户-项目关系,该范式将辅助监督信号纳入稀疏目标行为建模中。)
- Furthermore, our proposed meta contrastive encoding scheme allows CML to preserve the personalized multi-behavior characteristics, so as to be reflective of the diverse behavior-aware user preference under a customized self-supervised framework. (此外,我们提出的 元对比编码方案允许CML保留 个性化的多行为特征,从而在定制的 自我监督框架下反映用户的不同行为感知偏好。)
- We perform extensive experiments on three real-world recommendation datasets to justify the rationality of our assumptions and the effectiveness of our proposed framework. By comparing CML with 12 baselines, we show that CML is able to consistently improve the performance of different techniques under various settings. Further analysis demonstrates the effectiveness of the designed sub-modules with ablation study. (我们在三个真实世界的推荐数据集上进行了大量实验,以证明我们假设的合理性和我们提出的框架的有效性。通过将CML与12个基线进行比较,我们发现CML能够在各种设置下持续改善不同技术的性能。进一步的分析证明了所设计的子模块在消融实验中的有效性。)
2 PRELIMINARY
- We first define U \mathcal{U} U and I \mathcal{I} I to represent the set of users and items, respectively. (我们首先定义 U \mathcal{U} U 和 I \mathcal{I} I,分别表示用户和项目集。)
- In our multi-behavior recommendation scenario, let X ( k ) \mathcal{X}^{(k)} X(k) denote the user-item interaction matrix under the k k k-th behavior type (e.g., page view, add-to-favorite, purchase). (在我们的多行为推荐场景中,让 X ( k ) \mathcal{X}^{(k)} X(k)表示第 k k k行为类型下的用户项交互矩阵(例如,页面视图、添加到收藏夹、购买)。)
- Hence, multi-behavior interaction data is represented as { X ( 1 ) , . . . , X ( k ) , . . . , X ( K ) } \{\mathcal{X}^{(1)}, ..., \mathcal{X}^{(k)}, ..., \mathcal{X}^{(K)}\} {X(1),...,X(k),...,X(K)},
- where K K K is the number of behavior types. (其中 K K K是行为类型的数量。)
- In particular, the element x u , i k = 1 x^k_{u, i} = 1 xu,ik=1 indicates that user u u u has interacted with item i i i under the behavior type of k k k before, and x u , i k = 0 x^k_{u, i} = 0 xu,ik=0 otherwise. (特别地,元素 x u , i k = 1 x^k_{u, i} = 1 xu,ik=1 表示用户 u u u之前曾以 k k k的行为类型与第 i i i项进行过交互)
- Generally, there exist target behavior as the prediction objective. (一般来说,存在目标行为作为预测目标。)
- Other types of user behaviors serve as the auxiliary behaviors. (其他类型的用户行为用作辅助行为)
- For example, purchases are directly related to Gross Merchandise Value (GMV) in E-commerce services, and are usually considered as the target behaviors in various user modeling applications. (例如,在电子商务服务中,购买与 商品总值(GMV) 直接相关,并且通常被视为各种用户建模应用程序中的目标行为。)
- Auxiliary behaviors could be the interactions of page view and add-to-favorite/cart. (辅助行为可以是页面查看和添加到收藏夹/购物车的交互。)
2.1 Problem Statement.
The studied task is formally stated as: (所研究的任务正式表述为:)
- Input: observed user-item interactions with multiplex K K K types of behaviors { X ( 1 ) , . . . , X ( k ) , . . . , X ( K ) } \{\mathcal{X}^{(1)}, ..., \mathcal{X}^{(k)}, ..., \mathcal{X}^{(K)}\} {X(1),...,X(k),...,X(K)} among users U \mathcal{U} U and items I \mathcal{I} I. (观察到的用户项交互与多重 K K K类型的行为)
- Output: a predictive function which estimates the likelihood of user u u u will interact with item i i i under the target type ( k ) (k) (k) of behaviors. (一个预测函数,用于估计用户 u u u在目标类型 ( k ) (k) (k)下与第 i i i项目交互的可能性。)
2.2 Multi-Behavior Interaction Graph. (多行为交互图)
- Inspired by the representation paradigm of graph collaborative filtering methods [43, 45], we explore the user-item graph structure for our multi-behavior recommendation scenario. (受图协同过滤方法的表示范式[43,45]的启发,我们探索了多行为推荐场景的用户项图结构。)
- Specifically, given K K K types of user-item interaction matrices { X ( 1 ) , . . . , X ( k ) , . . . , X ( K ) } \{\mathcal{X}^{(1)}, ..., \mathcal{X}^{(k)}, ..., \mathcal{X}^{(K)}\} {X(1),...,X(k),...,X(K)}, we generate the multi-behavior interaction graph, in which the set of nodes V = U ∪ I \mathcal{V} = \mathcal{U} \cup \mathcal{I} V=U∪I involves the user and item set. (给定 K K K类型的用户项交互矩阵, 我们生成了多行为交互图,其中节点集 V = U ∪ I \mathcal{V} = \mathcal{U} \cup \mathcal{I} V=U∪I涉及用户和项目集)
- We further define the set of multiplex edges E \mathcal{E} E to represent observed interactions with K K K types of behaviors. (我们进一步定义了多重边集合 E \mathcal{E} E来表示观察到的与KK类型行为的交互作用。)
- In E \mathcal{E} E, edge e u , i k e^k_{u, i} eu,ik between u u u and i i i indicates that x u , i k = 1 x^k_{u, i} = 1 xu,ik=1.
3 METHODOLOGY
- We present our Contrastive Meta Learning (CML) framework in this section, which encapsulates the customized meta learning into a self-supervised neural architecture, for personalized multi-behavior dependency modeling. (在本节中,我们将介绍我们的对比元学习(CML) 框架,该框架将定制元学习封装到一个自我监督的神经架构中,用于个性化的多行为依赖建模。)
- The overall model flow is shown in Figure 1. Key components will be elaborated in following subsections. (整体模型流程如图1所示。以下小节将详细介绍关键组件。)
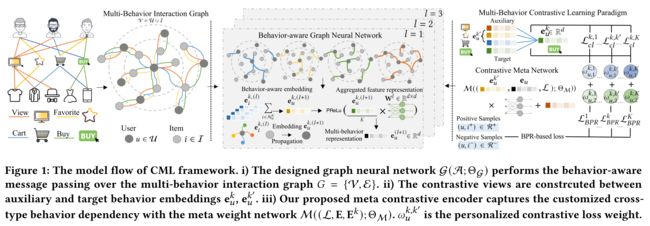
3.1 Behavior-aware Graph Neural Network (行为感知图神经网络)
-
(1) To inject the high-order connectivity into the multiplex relation learning across users/items, we first develop a graph-based message passing framework with the awareness of behavior context. (为了将高阶连通性注入到跨用户/项目的多重关系学习 中,我们首先开发了一个基于图形的具有行为上下文意识 的消息传递框架。)
-
Motivated by graph-based information propagation neural architecture [55] and the findings in the state-of-the-art model Light-GCN [15, 22], our behavior-aware message passing scheme is built over a lightweight graph architecture, which can be represented: (受 基于图形的信息传播神经架构 [55]和最先进的 Light GCN 模型[15,22]的研究结果的启发,我们的行为感知消息传递方案建立在一个 轻量级图形架构 之上,可以表示为:)
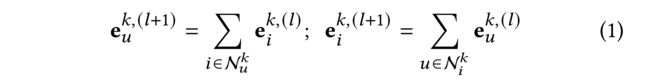
- where e v k , ( l + 1 ) ∈ R d e^{k, (l+1)}_{v} \in R^d evk,(l+1)∈Rd is defined as the obtained representation of node v ( v ∈ { u , i } ) v (v \in \{u, i\}) v(v∈{u,i}) under the l l l-th graph neural layer. (其中 e v k , ( l + 1 ) ∈ R d e^{k, (l+1)}_{v} \in R^d evk,(l+1)∈Rd定义为节点 v ( v ∈ { u , i } ) v (v \in \{u, i\}) v(v∈{u,i})的表示,在第 l l l个图神经层下。)
- N u k \mathcal{N}^k_u Nuk and N i k \mathcal{N}^k_i Nik denotes the neighboring nodes of item i i i and user u u u, respectively. (分别表示项目 i i i和用户 u u u的相邻节点。)
-
(2) After encoding the behavior-specific interaction patterns of users, we propose to perform the embedding aggregation across different types of behaviour patterns with the following operation for user representations (similar aggregation is applied for item side): (在编码用户的行为特定交互模式后,我们建议通过以下用户表示操作,在不同类型的行为模式之间执行嵌入聚合(类似聚合适用于项目端):)

- The aggregated feature representation e u ( l + 1 ) e^{(l+1)}_u eu(l+1) could preserve multi-behavior contextual information. (聚合特征表示 e u ( l + 1 ) e^{(l+1)}_u eu(l+1)可以保存多种行为的上下文信息。)
- W l ∈ R d × d W^l \in R^{d\times d} Wl∈Rd×d represents the transformation matrix corresponding to l l l-th graph propagation layer. (表示对应于第 l l l个图形传播层 的 变换矩阵。)
3.2 Multi-Behavior Contrastive learning (多行为对比学习)
- In our CML framework, we propose a multi-behavior contrastive learning paradigm to capture the complex dependencies across different types of user interactions via a self-supervised principle. (在我们的CML框架中,我们提出了一种多行为对比学习范式,通过自我监督原则捕捉不同类型用户交互的复杂依赖关系。)
- Conceptually, we utilize the idea of contrastive learning strategy for instance discrimination by contrasting positive and negative samples [31, 54]. (从概念上讲,我们利用了对比学习策略的概念,例如通过对比正和负样本进行区分[31,54]。)
- Our contrastive learning architecture endows our main supervised task (i.e., target behavior prediction) with the auxiliary supervision signals from the auxiliary behaviors. (我们的对比学习架构赋予我们的主要监督任务(即目标行为预测)来自辅助行为的辅助监督信号。)
3.2.1 Contrastive View Generation. (对比视图生成)
- (1) In contrastive learning paradigm, it is important to generate appropriate views for constructing diverse representations for the method to contrast with [5]. (在对比学习范式中,重要的是生成适当的视图,以构建与[5]对比的方法的不同表征。)
- (2) In our recommendation scenario with behavior multiplicity, we propose to consider each type of behaviors as individual view, which performs the contrastive learning between user embeddings in different behavior views. (在具有行为多样性 的推荐场景中,我们建议将每种行为视为个体视图,在不同行为视图中执行用户嵌入之间的对比学习。)
- (3) Different from current multi-behavior recommender systems (e.g., MATN [50], MBGCN [23]) which merely rely on behavior-wise embedding combination for target behavior prediction, we conduct the data augmentation by incorporating auxiliary behavior contextual information as supervision signals. (与当前的多行为推荐系统(如MATN[50],MBGCN[23])不同,该系统仅依赖行为层面的嵌入组合进行目标行为预测,我们通过合并辅助行为上下文信息作为监督信号来进行数据增强。)
- (4) This design not only encodes the cross-type behavior dependency, but also alleviates the skewed data distribution across different types of user interaction data (这种设计不仅对跨类型的行为依赖进行编码,而且缓解了不同类型用户交互数据之间的数据分布不均)
3.2.2 Behavior-Wise Contrastive Learning Paradigm. (行为层面的对比学习范式)
-
(1) After establishing contrastive views from multi-behavior context, we further devise a behavior-wise contrastive learning paradigm between the target behaviors and auxiliary behaviors. (在建立了多行为语境下的对比视角后,我们进一步设计了目标行为和辅助行为之间的行为层面对比学习范式。)
-
In particular,
- different behavior views of the same user are considered as positive pairs, (同一用户的不同行为视图被视为正对,)
- and the views of different users are sampled as negative pairs. (将不同用户的视图作为负对进行采样。)
-
Given the encoded target behavior representatione e u k e^k_u euk from our graph neural architecture, the generated positive and negative pairs are { e u k , e u k ′ ∣ u ∈ U } \{e^k_u, e^{k′}_u | u \in \mathcal{U}\} {euk,euk′∣u∈U} and { e u k , e u ′ k ′ ∣ u , u ′ ∈ U , u ≠ u ′ } \{e^k_u, e^{k′}_{u′} | u, u′ \in \mathcal{U}, u \neq u' \} {euk,eu′k′∣u,u′∈U,u=u′}. (给定编码的目标行为表示 e u k e^k_u euk,根据我们的图形神经结构,生成的正对和负对是)
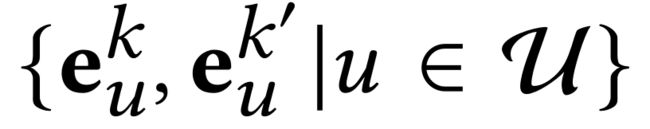
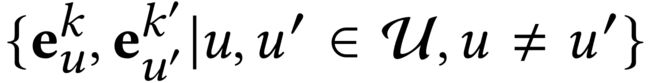
-
The incorporated auxiliary supervision enables our model to still recognize user u u u from different behavior views (i.e., k k k and k ′ k′ k′; k , k ′ ∈ K k, k′ \in K k,k′∈K) and captures the latent relationships between the auxiliary behaviors and target behaviors. (合并的辅助监督使我们的模型仍然能够从不同的行为视图(即 k k k and k ′ k′ k′; k , k ′ ∈ K k, k′ \in K k,k′∈K)识别用户 u u u) 并捕捉辅助行为和目标行为之间的潜在关系。)
-
Meanwhile, for different users u u u and u ′ u' u′, the contrastive loss aims to discriminate their behavior embeddings after data augmentation. (同时,对于不同的用户 u u u 和 u ′ u' u′,对比损失的目的是区分他们在数据增强后的行为嵌入。)
-
-
(2) Following works [48, 58], we utilize the InfoNCE [29] loss in our multi-view contrastive learning framework, to measure the distance between embeddings. (接下来的工作[48,58],我们利用多视角对比学习框架中的InfoNCE[29]损失来测量嵌入之间的距离。)
-
We define our self-supervised learning loss with the objective of maximizing the Mutual Information (MI) between user representations through contrasting positive pairs with the sampled negative pair counterparts. The InfoNCE-based contrastive loss is calculated as below:

- Here, we define φ ( ⋅ ) \varphi (·) φ(⋅) as the similarity function (e.g., inner-product or cosine similarity) between two embeddings.
- τ \tau τ represents the temperature hyperparameter for the softmax function.
-
(3) To sum up, we perform the contrastive learning via maximizing the agreement between two behavior views based on the above defined contrastive loss, and enforcing the divergence among different users.
-
We obtain the contrastive loss L c l k , k ′ \mathcal{L}^{k, k'}_{cl} Lclk,k′ for each pair of target behavior ( k ) (k) (k) and auxiliary behavior ( k ′ ) (k′) (k′).
-
Therefore, we generate a list of ontrastive loss functions as:
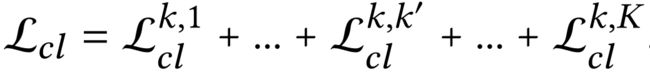
3.3 Meta Contrastive Encoding (元对比编码)
- (1) In our recommendation scenario, different users have various behaviour patterns and item interaction preferences. (在我们的推荐场景中,不同的用户有不同的行为模式和项目交互偏好)
- For example, some users are likely to pick up most of products from their favorite item list to purchase, (例如,一些用户可能会从他们最喜欢的商品列表中挑选大部分产品进行购买,)
- while others may only buy sporadic products given that they add a lot of items with less interest into their list [27]. (而其他人可能只购买零星的产品,因为他们在列表中添加了很多不太感兴趣的项目[27]。)
- The diversity of multi-behavior patterns from different users, results in different item interactions. (来自不同用户的多种行为模式的多样性导致了不同的项目交互。)
- (2) Hence, effectively modeling the personalized dependencies across different types of behaviors, is also important in making accurate recommendations. (因此,有效地建模不同类型行为之间的个性化依赖关系,对于做出准确的建议也很重要。)
- (3) To achieve this goal, we propose a meta contrastive encoding scheme to learn an explicit weighting function for the integration of multi-behavior contrastive loss. (为了实现这一目标,我们提出了一种元对比编码方案来学习一个显式的权重函数来整合多行为对比损失。)
- (4) This module customizes our self-supervised learning paradigm with the diverse constrastive loss integration. (本模块通过不同的结构损失整合定制我们的自我监督学习模式。)
- (5) Our meta contrastive encoding schema is a two-phase learning paradigm: (我们的元对比编码模式是一种两阶段学习范式)
- i) We propose a meta-knowledge encoder to capture the personalized multi-behavior characteristics, so as to reflect the diverse behavior-aware user preferences. (我们提出了一种元知识编码器来捕捉个性化的多行为特征,从而反映出用户对不同行为的感知偏好。)
- ii) Then, the extracted meta-knowledge will be incorporated into our developed meta weight network, to generate customized contrastive loss weight for cross-type behavior dependency modeling. (然后,将提取的元知识整合到我们开发的元权重网络中,为跨类型行为依赖建模生成定制的对比loss。)
3.3.1 Meta-Knowledge Encoder. (元知识编码器)
- (1) In our meta contrastive encoding framework, we firstly extract the meta-knowledge to preserve user-specific behavior dependencies. Inspired by feature interaction mechanisms in [16, 56], we design two types of meta-knowledge encoder with different integration techniques based on learned user behavior representations: e u e_u eu and e u k ′ e^{k'}_u euk′ (auxiliary behavior of k ′ k^′ k′): (在我们的元对比编码框架中,我们首先提取元知识来保持用户特定的行为依赖性。受[16,56]中特征交互机制的启发,我们基于学习到的用户行为表示设计了两种具有不同集成技术的元知识编码器: e u e_u eu 和 e u k ′ e^{k'}_u euk′( k ′ k^′ k′的辅助行为):)
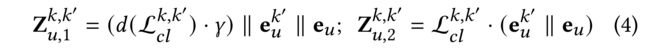
- where the encoded meta-knowledge is represented by Z u , 1 k , k ′ Z^{k, k^′}_{u, 1} Zu,1k,k′ and Z u , 2 k , k ′ Z^{k, k^′}_{u, 2} Zu,2k,k′. ( e u e_u eu and e u k ′ e^{k'}_u euk′) (编码后的元知识)
- We define d ( ⋅ ) d(\cdot) d(⋅) as the duplicate function to generate a value vector corresponding to the embedding dimensionality. (作为复制函数,生成与嵌入维数相对应的值向量。)
- ∥ \parallel ∥ denotes the concatenation operation. (表示串联操作。)
- γ \gamma γ is a scale factor for the enlarge value. (是放大值的比例因子。)
- (2) With this design for learning the personalized characteristics, both the auxiliary-target behavior dependency and user-specific interaction context are preserved in the extracted meta-knowledge. (通过这种学习个性化特征的设计,在提取的元知识中同时保留了辅助目标行为依赖和用户特定的交互上下文。)
3.3.2 Meta Weight Network. (元权重网络)
- (1) After encoding the meta knowledge with user-specific multi-behavior patterns, we design a weighting function ξ ( ⋅ ) \xi(·) ξ(⋅) mapping from meta-knowledge to contrastive loss weights. (在用用户特定的多行为模式对元知识进行编码后,我们设计了一个加权函数 ξ ( ⋅ ) \xi(·) ξ(⋅),从元知识到对比损失权重的映射。)
- (2) This module endows our recommendation framework with the capability of learning the multi-behavior relationships in a customized manner, to be reflective of personalized user preference under various types of behavior intentions. (本模块赋予我们的推荐框架以定制方式学习多行为关系的能力,以反映不同类型行为意图下的个性化用户偏好。)
- (3) Formally, we define our weighting function as the following transformation layer: (形式上,我们将权重函数定义为以下转换层:)
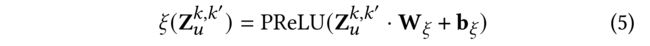
- where W ξ ∈ R d × d W_{\xi} \in R^{d\times d} Wξ∈Rd×dand b ξ ∈ R d b_{\xi} \in R^d bξ∈Rd represent the projection layer and bias term, respectively. (分别表示投影层和偏移项)
- Here, we utilize the PReLU activation function to incorporate non-linearity.
- (4) On the basis of our meta weight network, we can obtain our personalized contrastive loss weight as follows: (基于我们的元权重网络,我们可以获得如下个性化对比减肥)

- For each user u u u, ω u k , k ′ \omega^{k, k^{'}}_{u} ωuk,k′ weight represents the customized explicit dependence between the target behavior type of k k k and auxiliary behavior type of k ′ k^′ k′. (权重表示目标行为类型 k k k和辅助行为类型 k ′ k^′ k′之间的定制显式依赖关系)
- Accordingly, with our meta contrastive encoding scheme, we can generate two lists of loss weights for InfoNCE-based self-supervised loss and Bayesian personalized ranking (BPR)-based recommendation objective loss. (因此,通过我们的元对比编码方案,我们可以为基于InfoNCE的自我监督损失和基于贝叶斯个性化排名(BPR)的推荐目标损失生成两个损失权重列表。)
3.4 The Learning Process of CML Framework (CML框架的学习过程)
- In this section, we first introduce our optimization objective and then present the training strategy for our CML framework. (在本节中,我们首先介绍我们的优化目标,然后介绍CML框架的培训策略。)
- Finally, the analysis on the time complexity of our model is provided. (最后,对模型的时间复杂度进行了分析。)
3.4.1 Optimization Objective. (优化目标)
- (1) In the model inference of CML, we leverage the Bayesian Personalized Ranking (BPR) loss to learn parameters, which encourages the probability estimation of user’s observed interaction to be higher than his/her unobserved counterparts. (在CML的模型推理中,我们利用贝叶斯个性化排名(BPR)损失来学习参数,这鼓励用户观察到的交互的概率估计高于他/她未观察到的部分。)
- (2) Formally, the behavior-specific BPR loss is defined as: (形式上,特定于行为的BPR损失定义为)
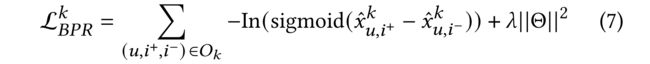
- O k O_k Ok represents the pairwise training samples of k k k-th behavior type, (表示第 k k k个行为类型的成对训练样本,)
- i.e., O k = { ( u , i + , i − ) ∣ ( u , i + ) ∈ R + , ( u , i − ) ∈ R − } O_k = \{(u, i^+, i^−) | (u, i^+) \in \mathcal{R}^+, (u, i^−) \in \mathcal{R}^− \} Ok={(u,i+,i−)∣(u,i+)∈R+,(u,i−)∈R−}.
- Here, R + \mathcal{R}^+ R+ and R − \mathcal{R}^− R− denotes the corresponding observed and unobserved interaction of user u u u. (表示用户 u u u的相应观察到和未观察到的交互。)
- Θ \Theta Θ represents the learnable parameters and the L 2 L_2 L2 regularization is applied for alleviating overfitting issue. (表示可学习的参数和 L 2 L_2 L2正则化用于缓解过度拟合问题。)
3.4.2 Model Training. (模型训练)
- In this work, we follow the training strategy of meta-learning methods in previous work [9, 34], by updating the parameters of our graph neural architecture (represented as G ( A ; Θ G ) ) \mathcal{G}(\mathcal{A}; Θ_{\mathcal{G}})) G(A;ΘG)) and multi-behavior contrastive meta network (represented as M ( ( L , E , E k ) ; Θ M ) ) \mathcal{M}((\mathcal{L}, E,E^k);Θ_{\mathcal{M}})) M((L,E,Ek);ΘM)) in an alternative way. (在这项工作中,我们遵循之前工作[9,34]中元学习方法的训练策略,通过更新我们的图神经结构(表示为 G ( A ; Θ G ) ) \mathcal{G}(\mathcal{A}; Θ_{\mathcal{G}})) G(A;ΘG)))) 和 多行为对比元网络(表示为 M ( ( L , E , E k ) ; Θ M ) ) \mathcal{M}((\mathcal{L}, E,E^k);Θ_{\mathcal{M}})) M((L,E,Ek);ΘM))) 以另一种方式。)
- Here, A \mathcal{A} A denotes the input adjacent matrix of behavior-aware user-item interaction graph. (这里, A \mathcal{A} A表示行为感知用户项交互图的输入邻接矩阵。)
- E E E and E k E^k Ek represents the learned cross-type and behavior-specific embedding matrix of all users, respectively. (分别表示所有用户的学习交叉类型和行为特定嵌入矩阵。)
- (2) The model training consists of three phases in an optimization loop to improve the training efficiency of our models. In particular: (模型训练包括优化循环中的三个阶段,以提高模型的训练效率。特别地)
- i) In the first stage, we integrate the behavior-aware graph neural network (with cloned state) and contrastive meta network, to learn initial parameter space of our multi-behavior contrastive encoder over the entire training data. (在第一阶段,我们将行为感知图神经网络(带克隆状态)和对比元网络相结合,在整个训练数据中学习我们的多行为对比编码器的初始参数空间。)
- ii) In the second stage, we refine the model parameters Θ M Θ_{\mathcal{M}} ΘM of our contrastive meta network based on the meta data. (在第二阶段,我们细化模型参数 Θ M Θ_{\mathcal{M}} ΘM基于元数据的对比元网络)
- iii) After generating the personalized contrastive loss weights, we leverage the updated Θ M Θ_{\mathcal{M}} ΘM to ameliorate the parameter Θ G Θ_{\mathcal{G}} ΘG of our graph neural network. (在生成个性化的对比损失权重后,我们利用更新的 Θ M Θ_{\mathcal{M}} ΘM改进我们的图形神经网络参数 Θ G Θ_{\mathcal{G}} ΘG。)
- (3) We formally present the nested optimization process as follows ( B B B denote the size of training batch): (我们正式提出了嵌套优化过程,如下所示( B B B表示训练批的大小))
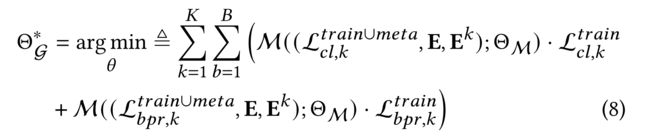
3.4.3 Model Complexity Analysis. (模型复杂性分析)
- (1) We analyze the complexity of our CML framework from several key components: (我们从几个关键组件分析了CML框架的复杂性)
- i) the computational cost of our lightweight graph neural architecture is O ( L × K × ∣ R k + ∣ × d ) O(L × K × |R^{k+}| × d) O(L×K×∣Rk+∣×d) for performing message passing across graph layers. (我们的轻量级图形神经结构的计算成本是 O ( L × K × ∣ R k + ∣ × d ) O(L × K × |R^{k+}| × d) O(L×K×∣Rk+∣×d),执行跨图形层的消息传递)
- ∣ R k + ∣ |R^{k+}| ∣Rk+∣ represents the number of non-zero elements in the adjacent matrix under the behavior of k k k, (表示 k k k行为下相邻矩阵中非零元素的数量)
- and L L L denotes the number of information propagation layers. ( L L L表示信息传播层的数量)
- The operations of linear transformations and mean-pooling for multi-behavior aggregation takes O ( L × ( N + M ) × d × ( K + d ) ) O(L × (N + M) ×d × (K +d)) O(L×(N+M)×d×(K+d)) time. (多行为聚合的线性变换和平均池运算需要 O ( L × ( N + M ) × d × ( K + d ) ) O(L × (N + M) ×d × (K +d)) O(L×(N+M)×d×(K+d)))
- ii) Our meta ontrastive encoder takes O ( K × ∣ R k + ∣ × d 2 ) O(K × |\mathcal{R}^{k+}| × d^2) O(K×∣Rk+∣×d2) time overhead. (我们的元压缩编码器采用 O ( K × ∣ R k + ∣ × d 2 ) O(K × |\mathcal{R}^{k+}| × d^2) O(K×∣Rk+∣×d2)de 时间开销)
- iii) The cost of InfoNCE-based mutual information calculation is O ( B × d ) O(B × d) O(B×d) and O ( B × S × d ) O(B × S × d) O(B×S×d) for the numerator and denominator (in Equation 3), respectively. (基于信息的互信息计算的成本分别是分子和分母的 O ( B × d ) O(B × d) O(B×d) 和 O ( B × S × d ) O(B × S × d) O(B×S×d)(在等式3中))
- Here, S S S is the sampling size of contrastive learning for reducing the time complexity and increasing the randomness to achieve model robustness [44]. (在这里, S S S是对比学习的样本大小,用于降低时间复杂度和增加随机性,以实现模型稳健性[44]。)
- Therefore, our multi-behavior contrastive learning paradigm takes O ( K × ∣ R k + ∣ × S × d ) O(K × |\mathcal{R}^{k+}| × S × d) O(K×∣Rk+∣×S×d) time per epoch. (因此,我们的多行为对比学习范式每一epoch需要 O ( K × ∣ R k + ∣ × S × d ) O(K × |\mathcal{R}^{k+}| × S × d) O(K×∣Rk+∣×S×d))
- i) the computational cost of our lightweight graph neural architecture is O ( L × K × ∣ R k + ∣ × d ) O(L × K × |R^{k+}| × d) O(L×K×∣Rk+∣×d) for performing message passing across graph layers. (我们的轻量级图形神经结构的计算成本是 O ( L × K × ∣ R k + ∣ × d ) O(L × K × |R^{k+}| × d) O(L×K×∣Rk+∣×d),执行跨图形层的消息传递)
- (2) In conclusion, our model could achieve comparable time complexity with state-of-the-art multi-behavior recommendation techniques (e.g., MBGCN, EHCF). (总之,我们的模型可以实现与最先进的多行为推荐技术相当的时间复杂度(例如,MBGCN, EHCF))
4 EVALUATION
To evaluate CML’s performance, we conduct experiments on several real-world datasets by answering the following research questions: (为了评估CML的性能,我们通过回答以下研究问题,在几个真实数据集上进行了实验:)
- RQ1: How effective is the developed CML framework to tackle the behavior multiplicity in recommendation? (RQ1:开发的CML框架在解决推荐中的行为多样性方面有多有效?)
- RQ2: How do different modules contribute to the performance of CML, such as the multi-behavior contrastive learning paradigm and meta contrastive encoder? (不同的模块,如多行为对比学习范式和元对比学习范式,对CML的表现有何影响?)
- RQ3: How does CML perform to alleviate interaction data sparsity, when competing with state-of-the-art methods? (在与最先进的方法竞争时,CML如何缓解交互数据稀疏性?)
- RQ4: How do different hyperparameter settings affect CML? (不同的超参数设置如何影响CML?)
- RQ5: How is the model interpretation ability of our CML? (我们CML的模型解释能力如何?)
4.1 Experimental Settings
4.1.1 Datasets.

- (1) We evaluate the effectiveness of our proposed CML on three publicly available recommendation datasets. (我们在三个公开的推荐数据集上评估了我们提出的慢性粒细胞白血病的有效性。)
- (2) We present the statistical information in Table 1. (我们在表1中给出了统计信息。)
- (3) Tmall: This dataset is collected from Tmall site–one of the largest E-commerce platform in China. (该数据集收集自天猫网——中国最大的电子商务平台之一)
- The user behavior data contains various interactions: Page View, Add-to-Favorite, Add-to-Cart and Purchase. (用户行为数据包含各种交互:页面视图(浏览)、添加到收藏夹、添加到购物车和购买。)
- Following the setting in [50], we keep users with at least three purchases for training and test. (按照[50]中的设置,我们为用户保留至少三次购买,用于培训和测试。)
- (4) IJCAI-Contest: This data was adopted in IJCAI15 Challenge from a business-to-customer retail system. It shares the same behavior types with the Tmall data, which are reflective of various user intention over items. (IJCAI竞赛:该数据在IJCAI15挑战赛(从企业到客户的零售系统)中采用。它与天猫数据共享相同的行为类型,反映了用户对商品的各种意图。)
- (5) Retailrocket: It is another benchmark dataset collected from Retailrocket recommender system. (这是从Retailrocket推荐系统收集的另一个基准数据集)
- In this dataset, user interactions are consisted of Page View, Add-to-Cart and Transaction. (在这个数据集中,用户交互包括页面视图(浏览)、添加到购物车和交易。)
- Following previous works for recommendation with multi-behaviors [23, 50], purchase behaviors are set as the target behaviors and other types of interactions are considered as the auxiliary behaviors. (继之前的多行为推荐工作[23,50]之后,购买行为被设置为目标行为,其他类型的交互被视为辅助行为)
4.1.2 Baselines.
- We compare our CML with the following state-of-the-art methods from two groups: Single-Behavior and Multi-Behavior recommender systems. These methods leverage various techniques to improve the recommendation performance: (我们将我们的CML与以下两组最先进的方法进行比较:单行为和多行为推荐系统。这些方法利用各种技术来提高推荐性能:)
4.1.2.1 Single-Behavior Recommendation Methods: (单一行为推荐方法)
- BPR [32]: It is a widely adopted matrix factorization model with the optimization criterion of Bayesian personalized ranking. (它是一种广泛采用的矩阵分解模型,具有贝叶斯个性化排序的优化准则。)
- PinSage [53]: This method defines the importance-based neighboring nodes to perform the graph convolution. (该方法定义了基于重要性的相邻节点来执行图卷积)
- In PinSage, the message passing paths are constructed through the random walk. (在PinSage中,通过随机游走构造消息传递路径)
- NGCF [43]: it is a representative graph neural framework which captures the collaborative effects in the embedding function of users based on the convolutional message passing scheme. (它是一种典型的图神经网络框架,基于卷积消息传递机制捕获用户嵌入函数中的协作效果。)
- LightGCN [15]: it simplifies the graph convolution network-based recommendation architecture by removing the feature transformation and nonlinear activation operations. (通过去除特征变换和非线性激活操作,简化了基于图卷积网络的推荐体系结构。)
- SGL [48]: this method performs the self-supervised learning over the user-item interaction graph with data augmentation from different views (e.g., node and edge dropout). The integrated auxiliary task is on the basis of node self-discrimination. (该方法对用户项交互图进行自监督学习,并从不同的视图(如节点和边dropout)进行数据增强。综合辅助任务是基于节点自判别的。)
4.1.2.2 Multi-Behavior Recommendation Models: (多行为推荐模型)
- NMTR [11]: it combines the multi-task learning framework and neural collaborative filtering to investigate multi-typed user interaction behaviors based on the predefined cascading relationships. (它结合多任务学习框架和神经协同过滤,基于预定义的级联关系研究多类型用户交互行为。)
- MATN [50]: it adopts the attention mechanism for multi-behavior recommendation. (它采用注意机制进行多行为推荐)
- Specifically, it uses memory-enhanced self-attention to measure the influence between different behaviors. (具体来说,它使用记忆增强的自我注意来衡量不同行为之间的影响。)
- The number of memory units is tuned from the range of [2,8]. (内存单元的数量在[2,8]范围内调整)
- MBGCN [23]: this approach is a GCN-based model by capturing the multi-behavioral patterns over the constructed user-item interaction graph. (该方法是一种基于GCN的模型,通过在构建的用户项交互图上捕获多个行为模式。)
- The high-order connectivity is considered during the information propagation. (在信息传播过程中考虑了高阶连通性。)
- KHGT [51]: this approach leverages transformer to incorporate the temporal information into the multi-behavior modeling, and differentiates the behaviors with graph attention network. (该方法利用transformer将时间信息融入到多行为建模中,并用图形注意网络区分行为。)
- EHCF [2]: it conducts the knowledge transfer among heterogeneous user feedback to correlate behavior dependency. A new loss is used for model optimization from the positive-only data. (它在异构用户反馈之间进行知识转移,以关联行为依赖。一个新的损失用于从纯正数据进行模型优化。)
We further compare our CML with two state-of-the-art heterogeneous graph neural networks, by applying them to capture the heterogeneous behavior relations in recommendation. (我们进一步将我们的CML与两个最先进的异构图神经网络进行比较,通过应用它们来捕获推荐中的异构行为关系。)
- HGT [17]: This graph transformer models heterogeneous relations in graphs. We adopt the heterogeneous message passing schema to encode the multiplex behaviors with dedicated representations. (该图转换器对图中的异构关系进行建模。我们采用异构消息传递模式,用专用的表示对多路行为进行编码。)
- HeCo [44]: It is a recently developed heterogeneous graph neural network based on the cross-view supervised learning architecture. We generate the meta-path relation from our multi-behavior interaction graph. (它是最近发展起来的一种基于交叉视图监督学习结构的异构图神经网络。我们从多行为交互图中生成元路径关系。)
4.1.3 Hyperparameters and Metrics. (超参数和指标)
-
(1) We implement our CML with PyTorch.
-
The embedding initialization is performed with Xavier [14] and the model is optimized by adopting the AdamW optimizer [26] and the Cyclical Learning Rate (CyclicLR) strategy [35].
-
In specific, the base and max learning rate is searched from { 0.6 e − 4 , 1 e − 4 , 1 e − 3 } \{ 0.6e^{−4}, 1e^{−4}, 1e^{−3} \} {0.6e−4,1e−4,1e−3} and { 0.6 e − 3 , 1 e − 3 , 2 e − 3 , 5 e − 3 } \{ 0.6e^{−3}, 1e^{−3}, 2e^{−3}, 5e^{−3} \} {0.6e−3,1e−3,2e−3,5e−3}, respectively. (使用Xavier[14]进行嵌入初始化,并采用AdamW优化器[26]和循环学习率(CyclicLR)策略[35]对模型进行优化。)
-
For all graph-based baselines, the number of graph-based message propagation layers is tuned from {1,2,3,4}. (对于所有基于图的基线,基于图的消息传播层的数量从{1,2,3,4}调整。)
-
We apply the L2 regularization for the learned embeddings with the weight tuned from { 1 e − 3 , 5 e − 3 , 1 e − 2 } \{ 1e^{−3}, 5e^{−3}, 1e^{−2} \} {1e−3,5e−3,1e−2}. (我们对学习到的嵌入应用L2正则化,权重从 { 1 e − 3 , 5 e − 3 , 1 e − 2 } \{ 1e^{−3}, 5e^{−3}, 1e^{−2} \} {1e−3,5e−3,1e−2})
-
Additionally, to alleviate the overfitting issue, the dropout is used in our designed meta network. (此外,为了缓解过度拟合的问题,我们在设计的元网络中使用了dropout)
-
(2) We adopt the widely used leave-one-out strategy by generating the test set from users’ last interacted items under the target behavior type (i.e., purchase/transaction). (我们采用了广泛使用的遗漏策略,根据用户在目标行为类型(即购买/交易)下最后一次交互的项目生成测试集。)
-
Two representative evaluation metrics are used for performance comparison: (两个有代表性的评估指标用于效果比较:)
- NDCG (Normalized Discounted Cumulative Gain)
- and HR (Hit Ratio) .
-
We also run our CML model and the best-performed baseline method for 10 times to calculate p-values for significance analysis. (我们还运行我们的CML模型和表现最佳的基线方法10次,以计算p值进行显著性分析)
4.2 Performance Comparison (RQ1) (性能比较)
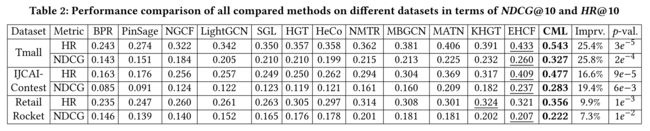
We present the detailed evaluation results of all methods on different datasets in Table 2 where the results of our CML and the best performed baselines are highlighted with bold and underlined, respectively. Key observations are as follows: (我们在表2中给出了不同数据集上所有方法的详细评估结果,其中CML和最佳执行基线的结果分别用粗体和下划线突出显示。主要观察结果如下:)
- CML consistently outperforms all types of baselines on three datasets. The p-values are much less than 0.05, which indicates statistically significant improvements between our method and baselines. We attribute the significant performance improvements to the following two reasons: (CML在三个数据集上始终优于所有类型的基线。p值远小于0.05,这表明我们的方法和基线之间有显著的统计学改进。我们将显著的性能改进归因于以下两个原因:)
- (1) Through the meta contrastive network, CML captures the multi-behavior dependencies in a customized manner; (通过元对比网络,CML以定制的方式捕获多行为依赖;)
- (2) The designed contrastive learning paradigm incorporates auxiliary self-supervised signals from different types of behavior dimensions, which offers informative gradients to the graph-based collaborative filtering architecture. (所设计的对比学习范式结合了来自不同类型行为维度的辅助自监督信号,为基于图形的协同过滤架构提供了信息梯度。)
- Multi-behavior recommendation approaches (e.g., MBGCN, EHCF, KHGT) yield better performance than single-behavior recommendation methods (e.g., NGCF, LightGCN, PinSage), which reveals the helpfulness of exploring multi-behavioral information into the user preference modeling. (多行为推荐方法(如MBGCN、EHCF、KHGT)比单一行为推荐方法(如NGCF、LightGCN、PinSage)具有更好的性能,这揭示了在用户偏好建模中探索多行为信息的帮助。)
- Among various multi-behavior recommendation models, EHCF is the best baseline in most cases. (在各种多行为推荐模型中,EHCF是大多数情况下的最佳基准。)
- This observation indicates that incorporating the different behavior semantics with supervision labels is able to guide the model optimization. (这一观察结果表明,将不同的行为语义与监管标签相结合能够指导模型优化。)
- Additionally, different from the topology-based self-supervised method-SGL, our CML designs new contrastive learning paradigm to fit the multi-behavior recommendation. (此外,与基于拓扑结构的自监督方法SGL不同,我们的CML设计了新的对比学习范式,以适应多行为推荐。)
- CML outperforms heterogeneous graph neural networks (i.e., HGT and HeCo) by a large margin in all cases, verifying that our designed meta contrastive network endows the heterogeneous collaborative filtering with the capability of effectively encoding the relation heterogeneity. (CML在所有情况下都大大优于异构图神经网络(即HGT和HeCo),验证了我们设计的元对比网络赋予异构协同过滤有效编码关系异构性的能力。)
4.3 Ablation and Effectiveness Analyses (RQ2) (消融和有效性分析)
To shed light on the performance improvement, we further conduct the ablation study for our CML, to justify the rationality of the designed key components. Analysis details are summarized as: (为了阐明性能改进,我们进一步对我们的CML进行了烧蚀研究,以证明设计的关键部件的合理性。分析细节总结如下:)

- Effect of multi-behavior contrastive learning framework. We first aim to answer the question: is it beneficial to integrate behavior-wise dependency under a contrastive learning prototype for CML. (多行为对比学习框架的效果。我们首先要回答这样一个问题:在CML的对比学习原型下整合行为依赖是否有益。)
- Towards this end, we generate a model variant CML(w/o)-CLF by disabling the contrastive learning between the target and auxiliary user behaviors. (为此,我们通过禁用目标用户行为和辅助用户行为之间的对比学习来生成模型变体CML(w/o)-CLF。)
- Instead, we only rely on the behavior-aware graph neural network to capture the behavior relationships. We present the evaluation results in Table 3 with the following key summaries: (相反,我们只依赖行为感知图神经网络来捕捉行为关系。我们在表3中给出了评估结果,并给出了以下关键总结:)
- (1) CML always outperforms CML(w/o)- CLF. This suggests the effectiveness of our contrasive learning paradigm, by capturing the complex dependent relations across different types of behaviors. (CML总是优于CML(w/o)-CLF。这表明,通过捕捉不同类型行为之间的复杂依赖关系,我们的对比学习范式是有效的。)
- (2) This design also mitigates the effect of skewed data distribution in the multi-behavior data, and effectively transfers knowledge from different behavior views. (这种设计还减轻了多行为数据中数据分布不均的影响,并有效地从不同的行为视图传递知识。)
- Effect of meta contrastive network. To investigate whether the meta contrastive network benefit the multi-behavior dependency modeling, we propose another variant CML(w/o)-MCN which only conducts the contrastive learning between type-specific behavior embeddings based on the estimated mutual information. (元对比网络效应。为了研究元对比网络是否有利于多行为依赖建模,我们提出了另一种变体CML(w/o)-MCN,它仅基于估计的互信息在特定类型的行为嵌入之间进行对比学习。)
- In other words, cross-behavior contrastive loss functions are integrated with the BPR-based loss using the equal weights, i.e., without explicitly differentiating the influence degrees under the augmented self-supervised learning tasks. (换言之,跨行为对比损失函数与基于BPR的损失函数使用等权重进行集成,即在不明确区分增强自监督学习任务下的影响程度的情况下。)
- Clearly, CML obtains better performance than CML(w/o)-MCN. It suggests that by employing the meta contrastive network, we can automatically discriminate the influence between different target-auxiliary behavior pairs. The cross-view behavior dependency can mutually complement with each other. (显然,CML比CML(w/o)-MCN获得更好的性能。这表明,通过元对比网络,我们可以自动区分不同目标辅助行为对之间的影响。跨视图行为依赖可以相互补充。)
- Effect of meta knowledge encoder. To verify the impact of meta knowledge encoder in our contrastive learning framework, we do an ablation study (with variant CML(w/o)-MKE) by disabling the meta contrastive weight network M ( ⋅ ) M (·) M(⋅). (元知识编码器的效果。为了验证元知识编码在我们的对比学习框架中的影响,我们通过禁用元对比权重网络M(·)进行了一项消融研究(使用变异CML(w/o)-MKE)。)
- Instead, we use a weighted gating mechanism to aggregate the behavior-specific contrastive loss in a uniform manner. Removing the incorporation of our meta knowledge degrades the performance, suggesting the necessity of our customized contrastive learning for different types of target-auxiliary behavior dependency. (相反,我们使用加权选通机制以统一的方式聚合特定于行为的对比损失。去除元知识会降低学习成绩,这表明我们有必要针对不同类型的目标辅助行为依赖进行定制对比学习。)
4.4 Model Performance on Alleviating (缓解的模型性能)
-
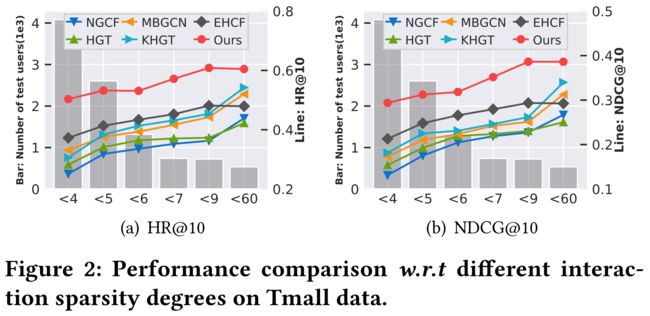
(1) Interaction Data Sparsity (RQ3) In this section, we aim to show the rationality of bringing the contrastive learning into the multi-behavior recommendation, so as to alleviate the data sparsity issue. (交互数据稀疏性(RQ3)在本节中,我们旨在展示将对比学习引入多行为推荐的合理性,以缓解数据稀疏性问题。)
- In Figure 2, we show the evaluation result comparison with respect to different interaction sparsity degrees on Tmall data. (在图2中,我们展示了天猫数据上不同交互稀疏度的评估结果比较。)
- Due to space limit, we select several representative baselines to make comparison. Specifically, we split users into six groups in terms of the number of their interactions (e.g., “<7” and “<60”). The reported model performance measured by HR and NDCG (as shown in the right side of y-axis in Figure 2) is averaged over all users in each group. The total number of users belonging to each group is shown in the left side of Figure 2. (由于篇幅限制,我们选择了几个有代表性的基线进行比较。具体来说,我们根据用户的交互次数将用户分为六组(例如,“<7”和“<60”)。通过HR和NDCG(如图2 y轴右侧所示)测量的报告模型性能是各组所有用户的平均值。属于每个组的用户总数如图2左侧所示。)
-
(2) We have the following findings: (我们有以下发现:)
- i) The recommendation accuracy improves for all compared methods as the number of user interactions increases. It is reasonable since the quality behavior embeddings are more likely to be learned with sufficient user behaviors. (随着用户交互次数的增加,所有比较方法的推荐精度都会提高。这是合理的,因为质量行为嵌入更有可能通过足够的用户行为来学习。)
- ii) As compared to the vanilla collaborative filtering model (NGCF), multi-behavior recommender systems (e.g., KHGT, MBGCN) achieve better performance, suggesting the effectiveness of incorporating multi-typed behavior context for data sparsity alleviation. (与普通协同过滤模型(NGCF)相比,多行为推荐系统(如KHGT、MBGCN)实现了更好的性能,这表明结合多类型行为上下文可以有效地缓解数据稀疏性。)
- iii) CML consistently outperforms other multi-behavior recommendation methods under different interaction degrees. This observation indicates that CML solves the data sparsity issue better, by embracing the self-supervised contrastive learning paradigm for preserving the behavior heterogeneity in recommendation. (在不同的交互程度下,CML的性能始终优于其他多行为推荐方法。这一观察结果表明,CML通过采用自我监督的对比学习范式来保持推荐中的行为异质性,从而更好地解决了数据稀疏性问题。)
4.5 Hyperparameter Analysis on CML (RQ4) (CML的超参数分析)
- This section examines the impact of different settings of several key hyperparameters in our proposed CML framework, including # graph propagation layers L L L, representation dimensionality d d d, batch size in training process. Figure 3 reports the evaluation results. (本节探讨了我们提出的CML框架中几个关键超参数的不同设置的影响,包括#图传播层 L L L、表示维度 d d d、训练过程中的批量大小。图3显示了评估结果。)
- For each time, we investigate the effect of one hyperparameter at a time and keep other parameters with their default settings. (对于每一次,我们一次研究一个超参数的影响,并将其他参数保留为默认设置。)
4.5.1 # graph propagation layers L L L. (图传播层)
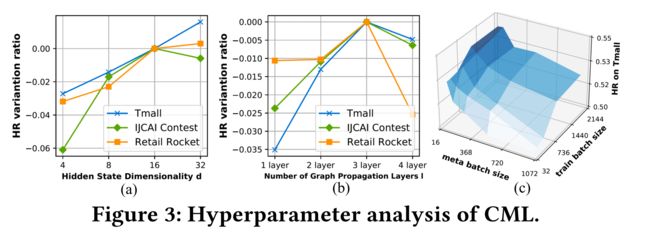
- From Figure 3, we can observe that more graph propagation layers results in better performance when L L L ≤ 3. (从图3中,我们可以观察到,当 L ≤ 3 L \le 3 L≤3)
- This suggests that more message passing layers will capture latent dependency from high-order neighbors. (这表明,更多的消息传递层将捕获来自高阶邻居的潜在依赖性。)
- When further stacking more graph layers might introduce noise to the user representations, which leads to the oversmoothing issue [3, 28]. (当进一步叠加更多图形层时,可能会给用户表示带来噪声,从而导致过度平滑问题[3,28]。)
4.5.2 Representation dimensionality d d d. (表征维度 d d d)
- Our model can achieve good performance with the embedding dimensionality 16 ≤ d ≤ 32. It indicates that our CML can boost the performance with small hidden state dimensionality, This can be attributed to effectively enhancing the user-item interaction learning with multiplex relationships. (在嵌入维数为16 ≤ d ≤ 32的情况下,我们的模型可以获得良好的性能.这表明我们的CML可以在较小的隐藏状态维度下提高性能,这可以归因于有效地增强了具有多重关系的用户项交互学习。)
4.5.3 Batch size in learning process. (学习过程中的批量大小)
- We search the batch size for our meta contrastive network (meta batch) and the graph neural architecture (train batch) from the range of {128, 256, 512, 1024, 2048} and {256, 512, 1024, 2048, 4096}, respectively. (我们分别从{128、256、512、1024、2048}和{256、512、2048、4096}范围内搜索元对比网络(元批次)和图形神经结构(训练批次)的批次大小。)
- Darker color signals better performance in Figure 3 (c). (在图3(c)中,颜色越深表示性能越好。)
- When the sampled batch size of meta network is smaller than that of base graph network, the model performance becomes better. (当元网络的采样批量小于基图网络时,模型性能更好。)
- This configuration will improve the cooperation between our augmented self-supervised learning task and BPR-based ranking objective. (这种配置将改善我们的增强自监督学习任务和基于BPR的排名目标之间的合作。)
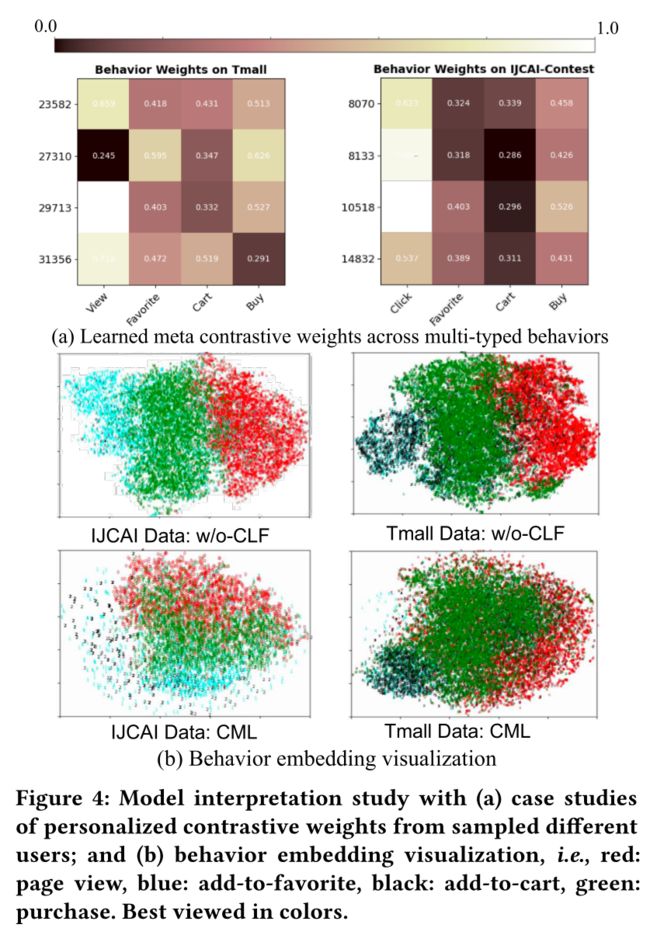
4.6 Qualitative Evaluation (RQ5) (定性评价)
- In this section, we perform the qualitative evaluation to show the model interpretation with the learned meta contrastive weights across different behavior types. We also visualize the projected behavior embeddings to have a better understanding of our achieved agreement between type-specific behavior embeddings. (在这一部分中,我们进行定性评估,以展示模型的解释,以及学习到的跨不同行为类型的元对比权重。我们还将投射的行为嵌入可视化,以便更好地理解特定类型行为嵌入之间达成的一致。)
4.6.1 Meta Contrastive Weight Visualization. (元对比权重可视化)
- We visualize the learned meta contrastive weights ω u k , k ′ \omega^{k, k^′}_u ωuk,k′ for each auxiliary behavior pairs ( k − k ′ ) (k − k^′) (k−k′) from several sampled users. (我们将学习的元对比权重 ω u k , k ′ \omega^{k, k^′}_u ωuk,k′,对于每个辅助行为对 ( k − k ′ ) (k − k^′) (k−k′)来自几个抽样用户。)
- The customized contrastive weights can be observed in Figure 4 (a), which reflect the personalized multi-behavior interaction patterns of different users. (定制的对比权重如图4(a)所示,反映了不同用户的个性化多行为交互模式。)
- Each ω u k , k ′ \omega^{k, k^′}_u ωuk,k′ value indicates the weight of individual contrastive loss between the target and auxiliary behavior views. (每个 ω u k , k ′ \omega^{k, k^′}_u ωuk,k′值表示目标和辅助行为视图之间个体对比损失的权重)
- For example, for user with id: 27310, the learned weights for the constructed view-buy and favorite-buy contrastive loss is 0.243 and 0.595, respectively. (例如,对于id为27310的用户,构建的查看-购买和收藏-购买对比损失的学习权重分别为0.243和0.595。)
- This suggests that this user is more likely to place the order after he or she adds the products into the favorite list, as compared with his/her page view behaviors. (这表明,与他/她的页面浏览行为相比,该用户在将产品添加到收藏夹列表后更有可能下订单。)
4.6.2 Embedding Visualization. (嵌入可视化)
- We further show the visualization (2- D projection with t-SNE [38]) of user behavior embeddings encoded from CML and w/o-CLF on IJCAI-Contest data, respectively. (我们进一步展示了在IJCAI竞赛数据上分别从CML和w/o-CLF编码的用户行为嵌入的可视化(t-SNE[38]的二维投影)。)
- In particular, we use different colors to represent different types of behaviors, i.e., red: page view, blue: add-to-favorite, black: add-to-cart, green: purchase. (特别是,我们使用不同的颜色来表示不同类型的行为,即红色:页面视图、蓝色:添加到收藏夹、黑色:添加到购物车、绿色:购买。)
- From Figure 4 (b), we observe the embedding agreement achieved by our CML. (从图4(b)中,我们观察到CML实现的嵌入协议。)
- This again justifies the effectiveness of our CML in alleviating data scarcity issue with the knowledge transfer across different types of behaviors, under our contrastive self-supervised learning architecture. (这再次证明了我们的CML在我们的对比自我监督学习架构下,通过不同类型的行为之间的知识转移,在缓解数据稀缺问题方面的有效性。)
5 RELATED WORK
5.1 Graph-based Recommendation Models (基于图的推荐模型)
- Recent studies have demonstrated the promising results offered by GNN-based recommendation models, by using different information propagation functions to aggregate embeddings over neighbors [1, 7, 15, 18, 19, 36]. (最近的研究已经证明了基于GNN的推荐模型所提供的有希望的结果,通过使用不同的信息传播函数来聚合邻居上的嵌入[1,7,15,18,19,36]。)
- For example, by stacking multiple embedding propagation layers, NGCF [43] can gather information from neighboring nodes with high-order connectivity. (例如,通过堆叠多个嵌入传播层,NGCF[43]可以从具有高阶连接性的相邻节点收集信息。)
- To address the burdensome design of GCN-based message passing in NGCF, LightGCN [15] omits the weight matrix and utilizes the sum-based pooling operation to obtain better recommendation performance. (为了解决NGCF中基于GCN的消息传递的繁重设计,LightGCN[15]省略了权重矩阵,并利用基于和的池操作来获得更好的推荐性能。)
- Additionally, to differentiate relations in recommendation, attention-based aggregation functions have been designed for fusing various information in recommender systems, such as social influence [8, 21, 36], knowledge graph embedding [24, 42], textual information [47]. (此外,为了区分推荐中的关系,基于注意的聚合函数被设计用于融合推荐系统中的各种信息,例如社会影响[8,21,36]、知识图谱嵌入[24,42]、文本信息[47]。)
- Specifically, GraphRec [8] discriminates influence between users using graph-based attention mechanism. (具体来说,GraphRec[8]使用基于图的注意机制区分用户之间的影响。)
- Wu et al. [47] develops an attentional graph neural paradigm to enhance the user and item representations with textural information. (Wu等人[47]开发了一种注意图神经范式,用文本信息增强用户和项目表征。)
- Motivated by the above research works, our contrastive meta learning framework is built over the graph neural network to capture the behavior-aware collaborative effects between users and items. (在上述研究工作的推动下,我们构建了基于图神经网络的对比元学习框架,以捕捉用户和项目之间的行为感知协作效应。)
5.2 Multi-Behavior Recommender Systems (多行为推荐系统)
- Under the multi-typed user-item interactions, there exist some recent works attempting to designing effective approaches for handling behavior multiplicity [2, 23, 50–52]. (在多类型用户项交互下,最近有一些工作试图设计有效的方法来处理行为多样性[2,23,50–52]。)
- In particular, the behavior-wise relationships are characterized by attention mechanism in [50, 51]. (特别是,在[50,51]中,行为方面的关系以注意机制为特征。)
- MBGCN [23] learns discriminative behavior representations using graph convolutional network. (MBGCN[23]使用图卷积网络学习区分性行为表示。)
- MATN [50] considers the influences among different types of interactions with attentive weights for pattern aggregation. (考虑不同类型的互动之间的影响有着不同的注意权重,针对模式聚合。)
- However, most of them are not designed with the sparse behavior data in mind. (然而,它们中的大多数并没有考虑到稀疏的行为数据。)
- To fill this gap, we propose a new model with contrastive learning at behavior semantic levels, which provides auxiliary informative supervision signals for knowledge transferring between behavior types. (为了填补这一空白,我们提出了一种在行为语义层面上进行对比学习的新模型,该模型为行为类型之间的知识转移提供了辅助信息监督信号。)
5.3 Contrastive Representation Learning (对比表征学习)
- Self-supervised learning techniques have been demonstrated to be effective in learning representations from both image data [6] and textual data [10]. (自监督学习技术已被证明在从图像数据[6]和文本数据[10]学习表征方面是有效的。)
- It aims to learn quality discriminative representations by contrasting positive and negative samples from different views. (它的目的是通过对比不同观点的正面和负面样本来学习高质量的区别表征。)
- For visual data, different data augmentation strategies (e.g., rotation [13], color distortion [5]) are used to generate negative instances. (对于视觉数据,使用不同的数据增强策略(例如,旋转[13],颜色失真[5])来生成负面实例。)
- To better represent the graph topological structures, Deep Graph InfoMax (DGI) [39] aims to maximize the mutual information between node embedding and graph representations based on the original and corrupted graphs. (为了更好地表示图的拓扑结构,Deep graph InfoMax(DGI)[39]的目标是在原始图和损坏图的基础上最大化节点嵌入和图表示之间的互信息。)
- In addition, a model-agnostic recommendation model SGL [48] has been proposed to augment the supervised task of recommendation with auxiliary tasks. (此外,还提出了一个模型不可知的推荐模型SGL[48],用辅助任务来扩充推荐的监督任务。)
- It performs dropout operations over the graph connection structures with different strategies, i.e., node dropout, edge dropout and random walk. (它使用不同的策略,即drop节点、drop边和随机游走,在图连接结构上执行drop操作。)
- SMIN [25] is a social-aware recommendation method with generative self-supervision. (是一种具有生成性自我监督的社会意识推荐方法。)
- Inspired by the existing contrastive learning paradigms, this work proposes a new graph contrastive representation framework with the adaptive multi-behavior modeling, by exploring various semantic aspects of user-item interactions. (受现有对比学习范式的启发,本研究通过探索用户项交互的各个语义方面,提出了一种新的基于自适应多行为建模的图对比表示框架。)
6 CONCLUSION
-
(1) In this paper, we develop a novel multi-behavior contrastive meta learning framework for recommendation. (我们开发了一个新的多行为对比元学习推荐框架。)
- Our model learns user representations by preserving behavior heterogeneous context with ==the agreement++ between behaviors views constructed from our contrastive learning paradigm. (我们的模型通过保持行为的异质性和基于对比学习范式构建的行为视图之间的一致性来学习用户表示。)
- The behavior-aware graph neural architecture with multi-behavior self-supervision bring benefits to the heterogeneous relational learning for recommendation. (多行为自监督的行为感知图神经网络结构有利于异构关系学习的推荐。)
- We perform comprehensive experiments using several real-world datasets to demonstrate the effectiveness of our proposed CML method, by comparing it with various state-of-the-arts. (我们使用多个真实数据集进行了综合实验,通过与各种最新技术的比较,证明了我们提出的CML方法的有效性。)
-
(2) In this paper, we take the initial step to capture the diverse multi-behavior patterns of users for recommendation under the self-supervised learning paradigm. (在本文中,我们首先在自监督学习范式下捕获用户多样的多行为模式以供推荐。)
- In the future, it would be interesting to explore the pre-train model strategy of our CML for online user modeling applications (e.g., user profiling). (在未来,探索我们的CML在线用户建模应用程序(例如,用户评测)的预训练模型策略将是一件有趣的事情。)
- Additionally, another meaningful future research direction can be extending our framework to learn disentangled representations of users, which could reflect the multi-dimensional user interests. (此外,另一个有意义的未来研究方向可以是扩展我们的框架,学习用户的分离表示,这可以反映多维用户兴趣。)