Linux进阶---第三篇
目录
1. fork复制效率---写时拷贝
2.文件基本常识
3.Linux的文件操作
4. 文件描述符
5.系统调用和库函数
1. fork复制效率---写时拷贝
对于一些页面,父进程和子进程都是只进行读取而并不修改
为了提高fork复制的效率,我们让父进程和子进程共享这些页面,也就是所谓的写时拷贝
1)假设不存在写实拷贝,并且存在部分页面,父子进程只读不写

对于逻辑页的7,8页面来说,父子进程都是只读不写,那么就可以共享7,8页
但不存在写实拷贝时,父子进程的逻辑页的7,8,在物理页上却是相互独立,各自使用各自的物理页面,这就造成的物理页面的浪费,也降低了fork复制的效率
2)存在写时拷贝时
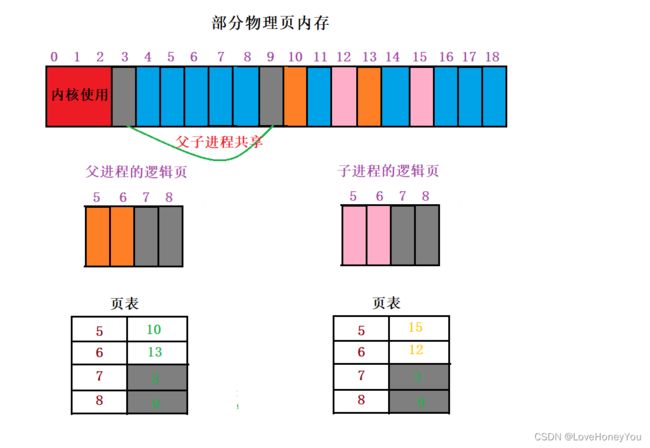
3)即使存在写时拷贝,父进程和子进程仍是相互独立的,在父子进程的运行期间,父进程依然认为自己是4个页面,子进程亦是同样的道理
4)如果父子进程共享的页面,不管是父进程还是子进程只要对其进行了修改,哪怕是一个字节,那么整个页面的内容将会被重新复制一份到一个新的物理页面,然后再将其分配给需要对页面进行修改的进程
2.文件基本常识
1)对Linux系统而言,不区分文本文件和二进制文件
2)每个文件都有一个唯一的id号,表示这个文件

不同目录下可以有同名的文件,本质还是由于他们的id不同,文件管理系统通过id来管理文件
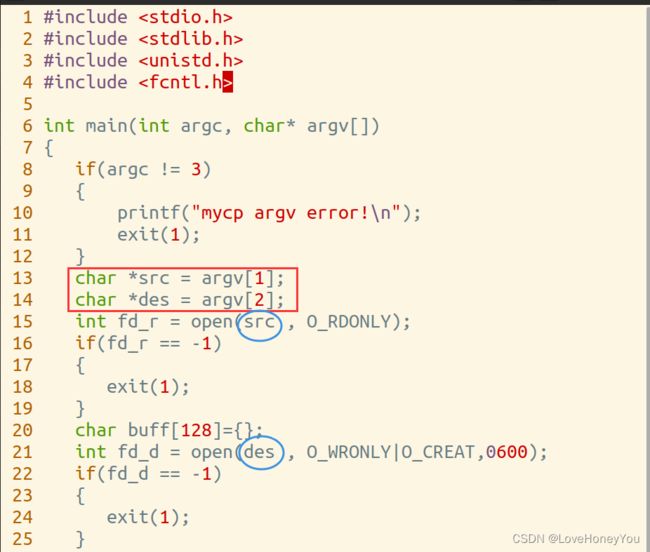
3) 打开文件---open

open有两个参数的,有三个参数的
第一个参数是:路径名称
第二个参数是:以什么方式打开文件,只读或者只写,或者读写
O_RDONLY 只读打开 O_RDWR 读写方式打开 O_CREAT 文件不存在则创建
O_APPEND 文件末尾追加 O_TRUNC 清空文件,重新写入
第三个参数是:权限,如果文件已经存在,那么文件权限就已经确定好了,就采用第一个open函数,如果文件不存在,则需要确定文件权限来创建此文件,此时调用第二个open函数
open返回值为int,称为文件描述符,通过这个整型值来操作打开的文件
4)Linux操作文件采用的是系统调用:open,read,write,close ,系统调用在内核中实现,系统调用是内核留给用户的接口,调用系统调用会从用户态切换为内核态
5)C语言的fopen() ---》底层调用的还是open(), fclose() ---》底层调用的还是close()
3.Linux的文件操作
1)
ssize_t read(int fd,void* buff ,size_t count);
fd:对应打开的文件描述符
buff:存放数据的空间
count:计划一次从文件中读多少字节数据
返回值:实际读到的字节数
2)
ssize_t write(int fd,const void* buff,size_t count);
fd:打开的文件描述符
buff:存放待写入的数据
count:计划一次向文件写入多少数据,这个很重要,会对我们写入文件的真实数据有影响
如果count大于buff中存放的数据数量,则会在字符常量区将buff越界后可以访问的数据写入文件,如果不可访问,则会报错
返回值:写入文件成功的字数, 为 -1 表示写入出错
3)
int close (int fd);
fd:要关闭文件的描述符
返回值:文件顺利关闭返回0,发生错误返回-1
4)向一个文件写入数据

![]()

5)读取一个文件

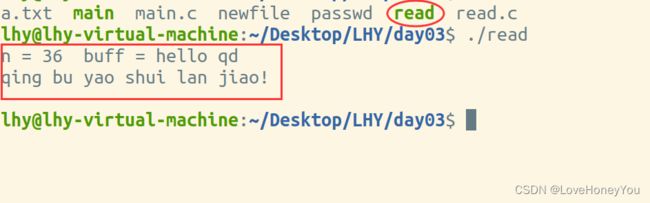
当read返回的值为0时
第一种情况:文件为空
第二种情况:已经读到文件末尾
6)文件复制
 passwd里的内容:
passwd里的内容:
将psswd里的内容复制到newfile
图解:

将文件分块,一块一块的进行复制,直到结束

![]()
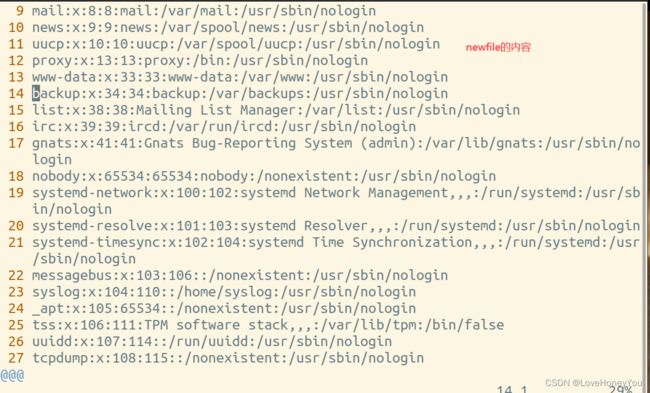


newfile和passwd的内容一模一样,但是两个文件
优化版:
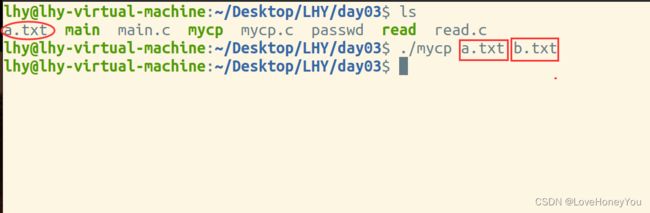
vim b.txt 进入b.txt查看复制后的内容

通过给主函数传参来实现
4. 文件描述符
1)先打开文件再fork
c.txt的内容

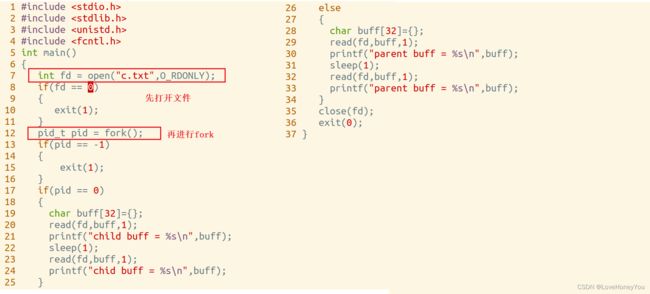
输出结果:

先打开的文件再进行fork时,父子进程对于此文件只进行了读,并未写入,所以父子进程共享同一个文件资源,父进程读取文件后的偏移量,在子进程中仍然存在,所以输出结果为a,b,c,d
2). 先fork再打开文件
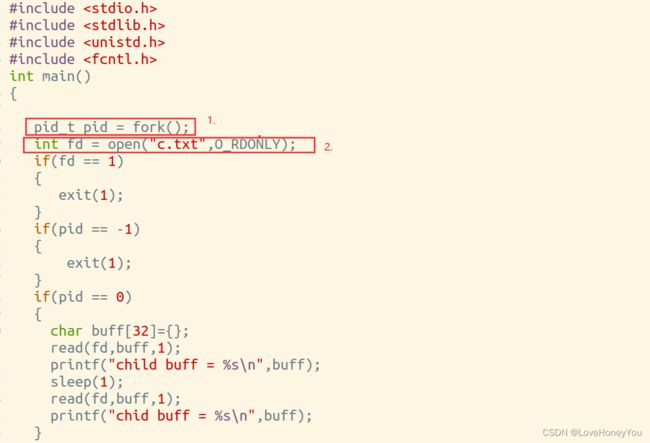
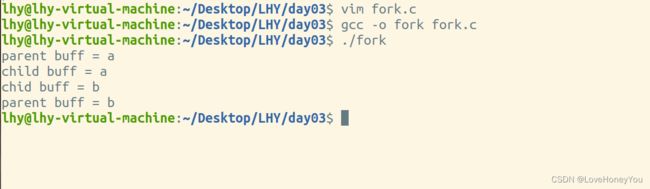
fork完成后父进程和子进程是两个独立的进程,由于是先fork,再打开的文件,所以父进程读取文件后的偏移量不会给子进程,子进程亦是同理,所以输出结果为:a,a,b,b
3)
对C语言:
标准输入: 键盘 FILE* stdin
标准输出: 屏幕 FILE* stdout
标准错误输出: 屏幕 FILE* stderr
Linux系统:
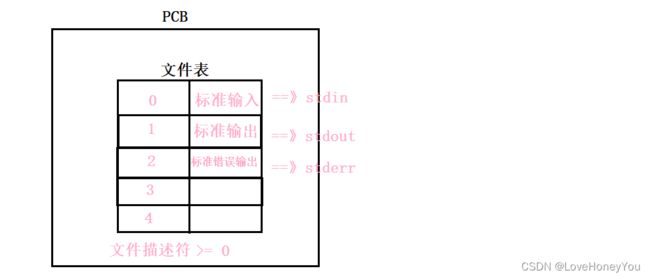
对main进行一下修改:



Linux系统会把进程中打开的文件,记录在PCB的文件表(char*[])中,0,1,2为默认,由系统控制打开关闭,所谓的文件描述符其实就是结构体指针数组的下标
6)
先打开文件再fork的本质
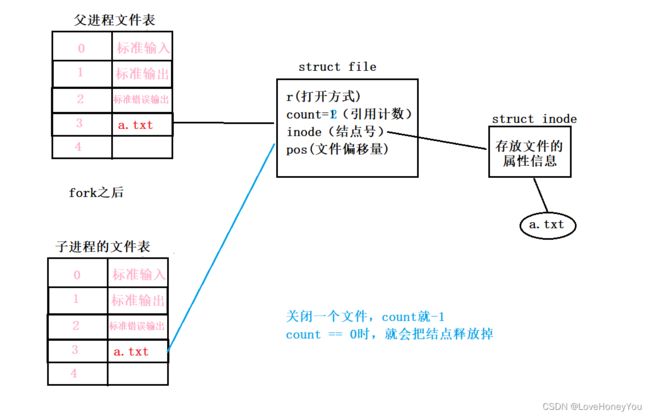
先fork再打开文件的本质

7)缓冲区存在的意义
库函数printf()通过调用系统调用write()在屏幕上打印数据,在调用系统调用时,需要从用户态切换到内核态,让内核去处理,这必然会有很大的开销,所以在调用系统调用write()前,加入了缓冲区,等待缓冲区数据满或者遇到强制刷新缓冲区时,再调用系统调用write(),一把把数据输出到屏幕上


B直接被write输出在屏幕上,A在缓冲区中被fork复制给子进程,等进程结束强制刷新缓冲区时,被输出到屏幕上
5.系统调用和库函数
库函数:printf,strlen等这些函数的实现,放在共享库中,库函数的实现就在库里
系统调用:系统调用的实现在内核中,内核中编写的函数,留给用户的接口
用户不能直接去执行内核中的代码,只能通过接口反馈给内核,等待内核处理完,再把结果返回给用户

man 1命令,2系统调用,3库函数