【PyTorch】迁移学习教程(计算机视觉应用实例)
文章目录
- 迁移学习
-
- 什么是迁移学习
- 为何用迁移学习
- 迁移学习的优点
- 迁移学习的方法
- 迁移方法的选择
- 学习目标
- 下载数据
- 导入模块
- 数据增强
- 制作数据集
- 数据加载器
- 相关信息的打印
- 训练数据可视化
- 训练模型
-
- 参数微调的方法
- 特征提取的方法
- 两种方法的对比
- 验证结果可视化
- 保存模型
- 加载模型
- 测试模型
- 完整代码
- 线上部署
- 温馨提示
- 引用参考
迁移学习
什么是迁移学习
举个栗子:你训练了一个猫的分类器模型,输入一张猫的图片,该分类器能作出正确的判断,是猫则输出True,不是则打印False。现在,组织上交给你的任务是训练一个狗的分类器模型。因为你已经有猫的分类器模型了,没必要从头开始训练,你可以将猫分类器模型的网络结构和参数迁移到训练狗的分类器模型中,然后稍微修改一下就能使用了。
为何用迁移学习
实际上,很少有人从头开始训练整个卷积网络(使用随机初始化),因为拥有足够大小的数据集相对很少。 相反,我们通常在非常大的数据集上对ConvNet进行预训练(例如ImageNet,其中包含1000个类别共计120万张图像),然后将ConvNet用作初始化或固定特征提取器以完成感兴趣的任务。
迁移学习的优点
迁移学习主要有以下三个优点:
- 更高的起点。微调前,源模型的初始性能比不使用迁移学习高。
- 更高的斜率。训练中,源模型的提升速率比不使用迁移学习高。
- 更高的渐进。训练得到的模型的收敛性比不使用迁移学习更好。

迁移学习的方法
实现迁移学习主要有两种常见的方法:
- Convnet微调:代替随机初始化,我们使用预训练的网络初始化我们的模型,例如在
imagenet 1000数据集上训练的网络。其余的训练方法还是照旧。 - Convnet作为固定的特征提取器:冻结除全连接层外的所有网络的权重,最后的全连接层用一个具有随机权重的新层来替换,并且仅训练该层。
本文中,我们将这两种方法分别简称为:参数微调和特征提取。
迁移方法的选择
| 数据集大小 | 和预训练模型使用数据集的相似度 | 一般选择 |
|---|---|---|
| 小 | 高 | 特征提取 |
| 大 | 高 | 参数微调 |
| 小 | 低 | 特征提取+SVM |
| 大 | 低 | 从头训练或参数微调(推荐) |
学习目标
今天我们要要解决的问题是训练一个模型来实现蚂蚁和蜜蜂的分类。如果从头开始训练的话,这是一个非常小的数据集,就算做了数据增强也难以达到很好的效果。因此我们引入迁移学习的方法,采用在imagenet上训练过的resnet18作为我们的预训练模型。
下载数据
推荐:https://download.csdn.net/download/qq_42951560/13201074
备用:https://ghgxj.lanzous.com/i9EGHiv97za
imagenet数据集三通道的均值和标准差分别是:[0.485, 0.456, 0.406],[0.229, 0.224, 0.225]。
该数据集是imagenet非常小的一个子集。只包含蚂蚁和蜜蜂两类。
所以数据标准化Normalize的时候我们也继承使用imagenet的均值和标准差。
| 种类 | 训练集 | 验证集 |
|---|---|---|
| 蚂蚁 | 123 | 70 |
| 蜜蜂 | 121 | 83 |
| 总计 | 244 | 153 |
导入模块
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torch.optim import lr_scheduler
import torchvision
from torchvision import datasets, models, transforms
import numpy as np
import matplotlib.pyplot as plt
import os
import time
import copy
数据增强
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
制作数据集
image_datasets = {
x: datasets.ImageFolder(
root=os.path.join('./dataset', x),
transform=data_transforms[x]
) for x in ['train', 'val']
}
数据加载器
dataloaders = {
x: DataLoader(
dataset=image_datasets[x],
batch_size=4,
shuffle=True,
num_workers=0
) for x in ['train', 'val']
}
相关信息的打印
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
'''输出
{'train': 244, 'val': 153}
['ants', 'bees']
device(type='cuda', index=0)
'''
dataset_sizes:数据集大小;训练集244张图片,验证集153张图片。
class_names:类名;就两类,ants和bees。
device:训练设备;如果有GPU就使用GPU,没有就用CPU,不过GPU训练要快很多倍。
训练数据可视化
inputs, labels = next(iter(dataloaders['train']))
grid_images = torchvision.utils.make_grid(inputs)
def no_normalize(im):
im = im.permute(1, 2, 0)
im = im*torch.Tensor([0.229, 0.224, 0.225])+torch.Tensor([0.485, 0.456, 0.406])
return im
grid_images = no_normalize(grid_images)
plt.title([class_names[x] for x in labels])
plt.imshow(grid_images)
plt.show()

训练模型
之前提到过,迁移学习有两种常见的方法,我们就简单的称之为参数微调和特征提取吧。下面,我们将分别使用这两种方法来训练我们的模型,最后再进行对比分析。两种方法用同一个函数训练,只不过传的参数不同。公用的训练函数如下:
def train_model(model, criterion, optimizer, scheduler, num_epochs=10):
t1 = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
lr = optimizer.param_groups[0]['lr']
print(
f'EPOCH: {epoch+1:0>{len(str(num_epochs))}}/{num_epochs}',
f'LR: {lr:.4f}',
end=' '
)
# 每轮都需要训练和评估
for phase in ['train', 'val']:
if phase == 'train':
model.train() # 将模型设置为训练模式
else:
model.eval() # 将模型设置为评估模式
running_loss = 0.0
running_corrects = 0
# 遍历数据
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# 梯度归零
optimizer.zero_grad()
# 前向传播
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
preds = outputs.argmax(1)
loss = criterion(outputs, labels)
# 反向传播+参数更新
if phase == 'train':
loss.backward()
optimizer.step()
# 统计
running_loss += loss.item() * inputs.size(0)
running_corrects += (preds == labels.data).sum()
if phase == 'train':
# 调整学习率
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
# 打印训练过程
if phase == 'train':
print(
f'LOSS: {epoch_loss:.4f}',
f'ACC: {epoch_acc:.4f} ',
end=' '
)
else:
print(
f'VAL-LOSS: {epoch_loss:.4f}',
f'VAL-ACC: {epoch_acc:.4f} ',
end='\n'
)
# 深度拷贝模型参数
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
t2 = time.time()
total_time = t2-t1
print('-'*10)
print(
f'TOTAL-TIME: {total_time//60:.0f}m{total_time%60:.0f}s',
f'BEST-VAL-ACC: {best_acc:.4f}'
)
# 加载最佳的模型权重
model.load_state_dict(best_model_wts)
return model
参数微调的方法
该方法使用预训练的参数来初始化我们的网络模型,修改全连接层后再训练所有层。
# 加载预训练模型
model_ft = models.resnet18(pretrained=True)
# 获取resnet18的全连接层的输入特征数
num_ftrs = model_ft.fc.in_features
# 调整全连接层的输出特征数为2
model_ft.fc = nn.Linear(num_ftrs, len(class_names))
# 将模型放到GPU/CPU
model_ft = model_ft.to(device)
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 选择优化器
optimizer_ft = optim.SGD(model_ft.parameters(), lr=1e-3, momentum=0.9)
# 定义优化器器调整策略,每5轮后学习率下调0.1个乘法因子
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=5, gamma=0.1)
# 调用训练函数训练
model_ft = train_model(
model_ft,
criterion,
optimizer_ft,
exp_lr_scheduler,
num_epochs=10
)
特征提取的方法
该方法冻结除全连接层外的所有层的权重,修改全连接层后仅训练全连接层。
# 加载预训练模型
model_conv = models.resnet18(pretrained=True)
# 冻结除全连接层外的所有层, 使其梯度不会在反向传播中计算
for param in model_conv.parameters():
param.requires_grad = False
# 获取resnet18的全连接层的输入特征数
num_ftrs = model_conv.fc.in_features
# 调整全连接层的输出特征数为2
model_conv.fc = nn.Linear(num_ftrs, 2)
# 将模型放到GPU/CPU
model_conv = model_conv.to(device)
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 选择优化器, 只传全连接层的参数
optimizer_conv = optim.SGD(model_conv.fc.parameters(), lr=1e-3, momentum=0.9)
# 定义优化器器调整策略,每5轮后学习率下调0.1个乘法因子
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=5, gamma=0.1)
# 调用训练函数训练
model_conv = train_model(
model_conv,
criterion,
optimizer_conv,
exp_lr_scheduler,
num_epochs=10
)
两种方法的对比
- 参数微调
EPOCH: 01/10 LR: 0.0010 LOSS: 0.8586 ACC: 0.5902 VAL-LOSS: 0.2560 VAL-ACC: 0.9020
EPOCH: 02/10 LR: 0.0010 LOSS: 1.1052 ACC: 0.6803 VAL-LOSS: 0.3033 VAL-ACC: 0.8758
EPOCH: 03/10 LR: 0.0010 LOSS: 0.6706 ACC: 0.7910 VAL-LOSS: 0.9216 VAL-ACC: 0.8039
EPOCH: 04/10 LR: 0.0010 LOSS: 0.7949 ACC: 0.7623 VAL-LOSS: 0.2686 VAL-ACC: 0.8954
EPOCH: 05/10 LR: 0.0010 LOSS: 0.5725 ACC: 0.7500 VAL-LOSS: 0.3638 VAL-ACC: 0.8431
EPOCH: 06/10 LR: 0.0001 LOSS: 0.3003 ACC: 0.8525 VAL-LOSS: 0.2749 VAL-ACC: 0.8758
EPOCH: 07/10 LR: 0.0001 LOSS: 0.4123 ACC: 0.8197 VAL-LOSS: 0.2747 VAL-ACC: 0.8889
EPOCH: 08/10 LR: 0.0001 LOSS: 0.3650 ACC: 0.8361 VAL-LOSS: 0.2942 VAL-ACC: 0.8758
EPOCH: 09/10 LR: 0.0001 LOSS: 0.3748 ACC: 0.8279 VAL-LOSS: 0.2560 VAL-ACC: 0.9020
EPOCH: 10/10 LR: 0.0001 LOSS: 0.3523 ACC: 0.8361 VAL-LOSS: 0.2687 VAL-ACC: 0.9085
----------
TOTAL-TIME: 1m10s BEST-VAL-ACC: 0.9085
训练10轮,总用时1m10s,验证集最大准确率0.9085
- 特征提取
EPOCH: 01/10 LR: 0.0010 LOSS: 0.7262 ACC: 0.6598 VAL-LOSS: 0.2515 VAL-ACC: 0.9085
EPOCH: 02/10 LR: 0.0010 LOSS: 0.5294 ACC: 0.7951 VAL-LOSS: 0.3064 VAL-ACC: 0.8627
EPOCH: 03/10 LR: 0.0010 LOSS: 0.5121 ACC: 0.7746 VAL-LOSS: 0.1943 VAL-ACC: 0.9346
EPOCH: 04/10 LR: 0.0010 LOSS: 0.4977 ACC: 0.7992 VAL-LOSS: 0.1751 VAL-ACC: 0.9477
EPOCH: 05/10 LR: 0.0010 LOSS: 0.5162 ACC: 0.7992 VAL-LOSS: 0.1880 VAL-ACC: 0.9412
EPOCH: 06/10 LR: 0.0001 LOSS: 0.4928 ACC: 0.7869 VAL-LOSS: 0.1695 VAL-ACC: 0.9542
EPOCH: 07/10 LR: 0.0001 LOSS: 0.3889 ACC: 0.8156 VAL-LOSS: 0.1952 VAL-ACC: 0.9412
EPOCH: 08/10 LR: 0.0001 LOSS: 0.3160 ACC: 0.8648 VAL-LOSS: 0.1897 VAL-ACC: 0.9412
EPOCH: 09/10 LR: 0.0001 LOSS: 0.4431 ACC: 0.7828 VAL-LOSS: 0.1689 VAL-ACC: 0.9542
EPOCH: 10/10 LR: 0.0001 LOSS: 0.2999 ACC: 0.8770 VAL-LOSS: 0.2250 VAL-ACC: 0.9346
----------
TOTAL-TIME: 0m45s BEST-VAL-ACC: 0.9542
训练10轮,总用时0m46s,验证集最大准确率0.9542
- 从头训练(不使用迁移学习,将参数微调的代码
pretrained设置为False即可)
EPOCH: 01/10 LR: 0.0010 LOSS: 0.7462 ACC: 0.5574 VAL-LOSS: 0.7228 VAL-ACC: 0.5556
EPOCH: 02/10 LR: 0.0010 LOSS: 0.7729 ACC: 0.5984 VAL-LOSS: 0.8003 VAL-ACC: 0.6209
EPOCH: 03/10 LR: 0.0010 LOSS: 0.8077 ACC: 0.5943 VAL-LOSS: 0.7597 VAL-ACC: 0.5163
EPOCH: 04/10 LR: 0.0010 LOSS: 0.7494 ACC: 0.5820 VAL-LOSS: 0.6755 VAL-ACC: 0.5556
EPOCH: 05/10 LR: 0.0010 LOSS: 0.7517 ACC: 0.6148 VAL-LOSS: 0.6289 VAL-ACC: 0.6144
EPOCH: 06/10 LR: 0.0001 LOSS: 0.6333 ACC: 0.6475 VAL-LOSS: 0.5897 VAL-ACC: 0.6797
EPOCH: 07/10 LR: 0.0001 LOSS: 0.6007 ACC: 0.6967 VAL-LOSS: 0.6266 VAL-ACC: 0.6667
EPOCH: 08/10 LR: 0.0001 LOSS: 0.6316 ACC: 0.6516 VAL-LOSS: 0.6142 VAL-ACC: 0.6797
EPOCH: 09/10 LR: 0.0001 LOSS: 0.6109 ACC: 0.6639 VAL-LOSS: 0.5907 VAL-ACC: 0.6928
EPOCH: 10/10 LR: 0.0001 LOSS: 0.5951 ACC: 0.6844 VAL-LOSS: 0.5939 VAL-ACC: 0.6928
----------
TOTAL-TIME: 1m11s BEST-VAL-ACC: 0.6928
训练10轮,总用时1m11s,验证集最大准确率0.6928
对比发现,使用迁移学习起点更高,收敛更快。其中特征提取总用时更短,准确率更高。这个结果是预料之中的,在迁移方法的选择中,我们知道对于数据集较小,且与原始数据集相似度高时,选择特征提取的方法会更好。
验证结果可视化
def visualize_model(model):
model.eval()
with torch.no_grad():
inputs, labels = next(iter(dataloaders['val']))
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
preds = outputs.argmax(1)
plt.figure(figsize=(9, 9))
for i in range(inputs.size(0)):
plt.subplot(2,2,i+1)
plt.axis('off')
plt.title(f'pred: {class_names[preds[i]]}|true: {class_names[labels[i]]}')
im = no_normalize(inputs[i].cpu())
plt.imshow(im)
plt.savefig('train.jpg')
plt.show()

保存模型
更详细的
pytorch保存和加载模型的方法可以看我的这篇文章
torch.save(model_conv.state_dict(), 'model.pt')
加载模型
更详细的
pytorch保存和加载模型的方法可以看我的这篇文章
device = torch.device('cpu')
model = models.resnet18(pretrained=False)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, len(class_names))
model.load_state_dict(torch.load('model.pt', map_location=device))
测试模型
百度或必应图片中随便找几张张蚂蚁和蜜蜂的图片,或者用手机拍几张照片也行。用上一步加载的模型测试一下分类的效果。

完整代码
https://github.com/XavierJiezou/pytorch-transfer-learning
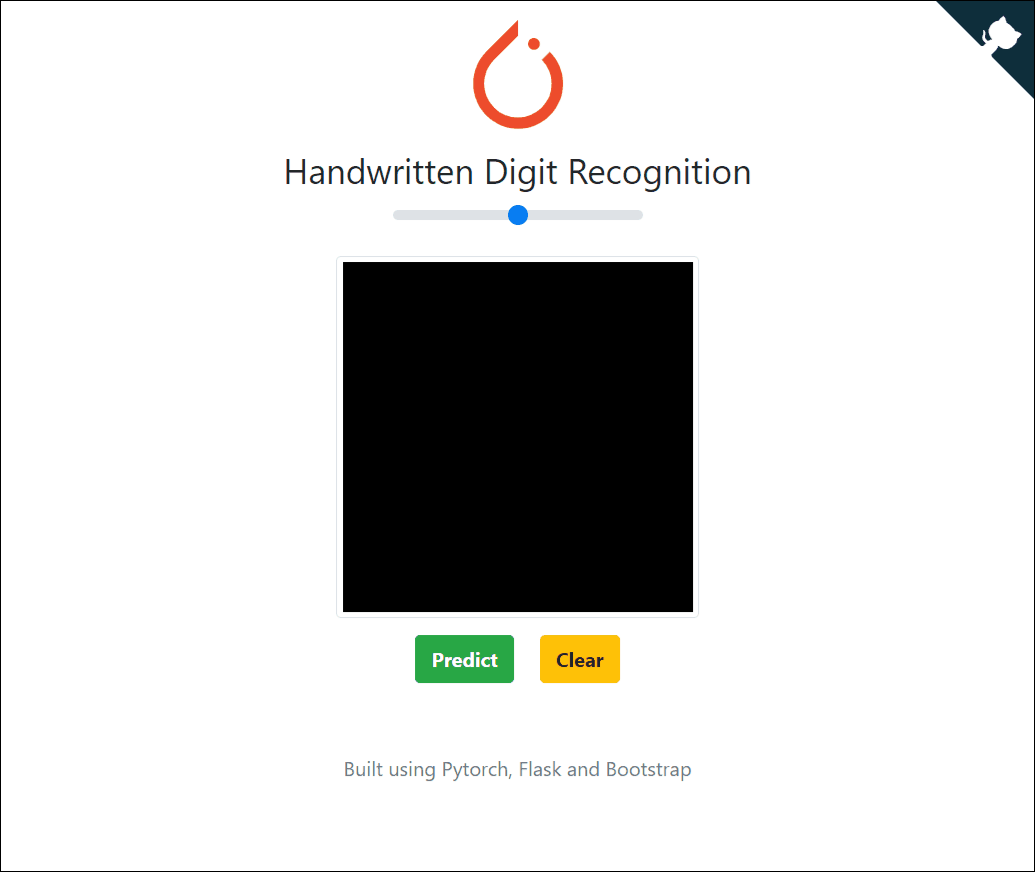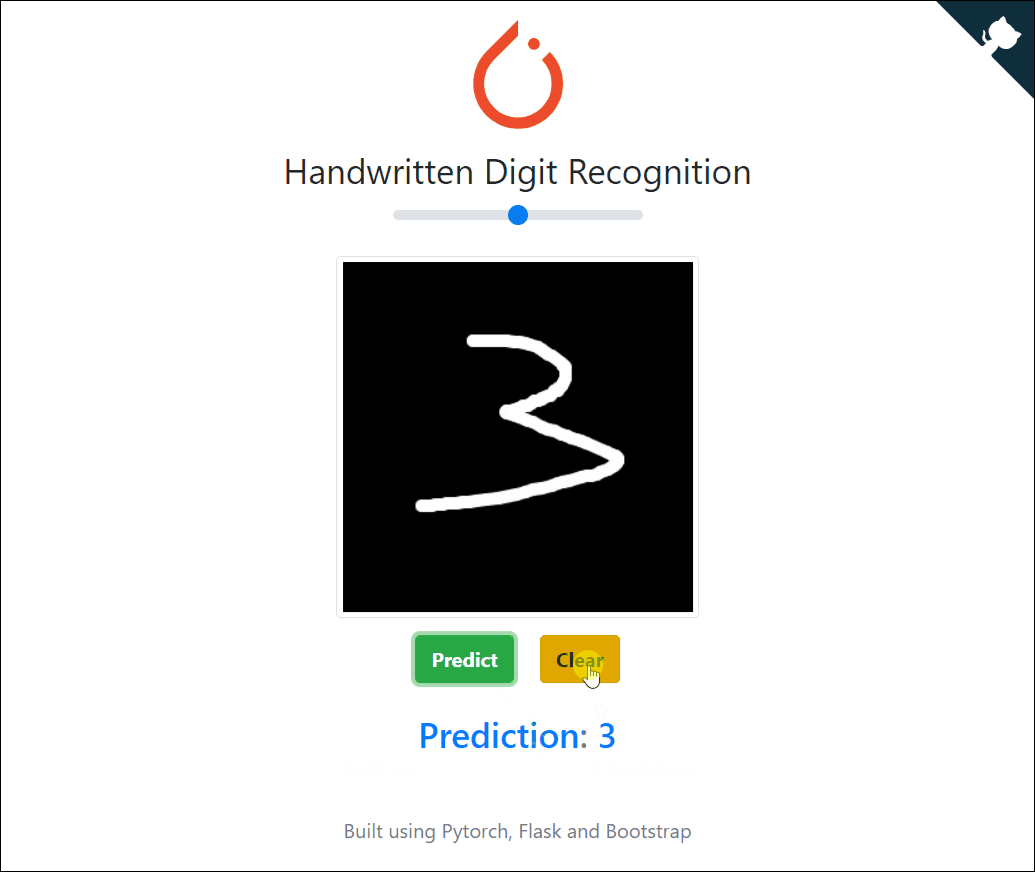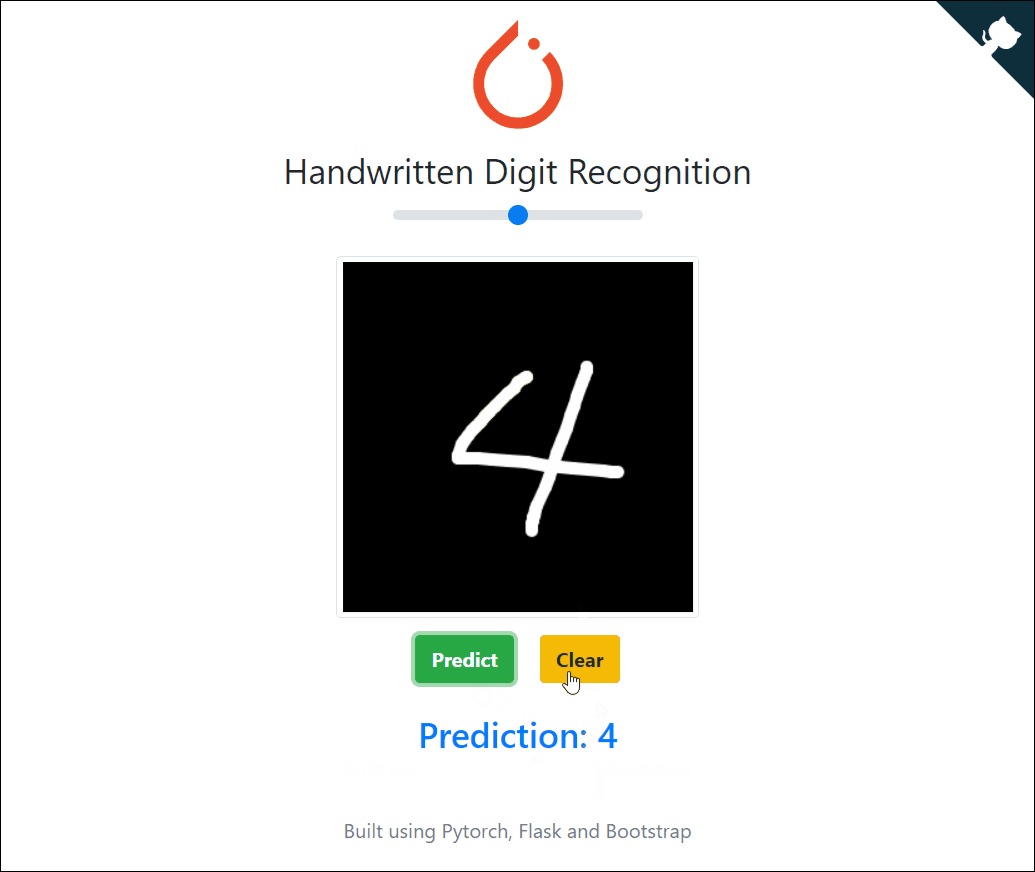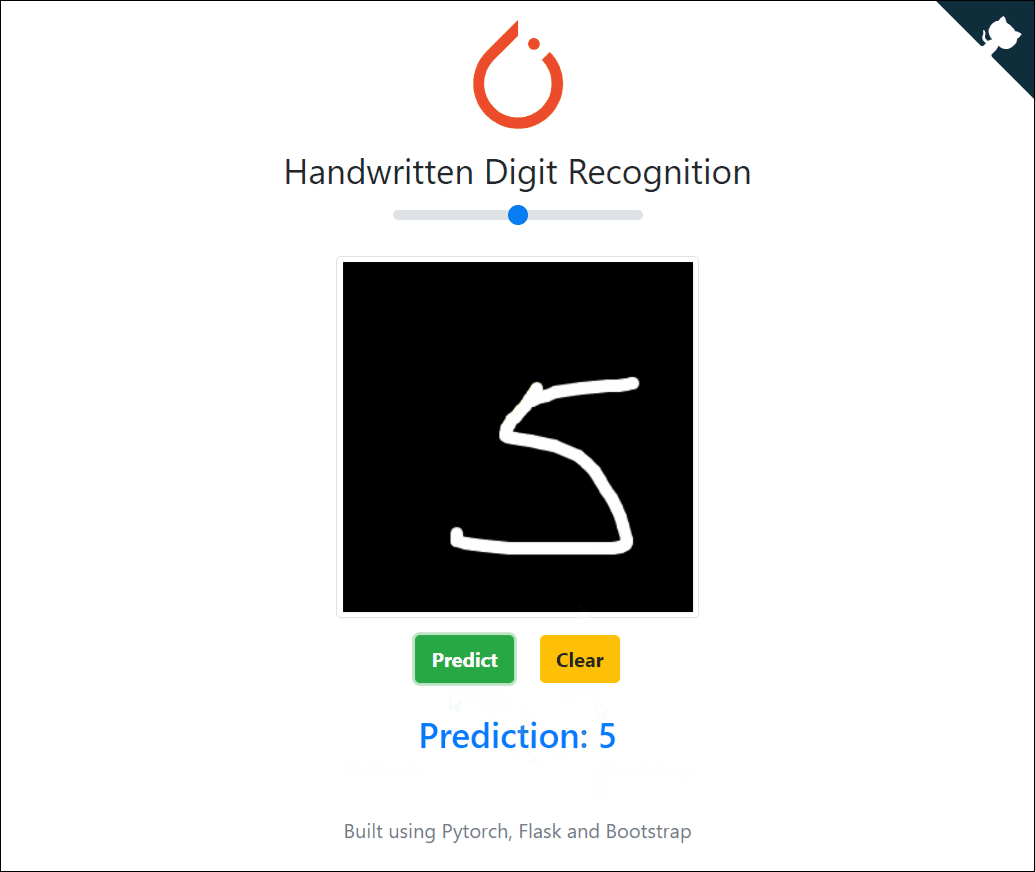
线上部署
有兴趣的话,你还可以将你的机器学习模型部署到线上。下方就是一个手写数字模型线上成功部署的实例:
https://pytorch-cnn-mnist.herokuapp.com/
温馨提示
本文只讲述了迁移学习在计算机视觉领域的应用,其实迁移学习还能应用到自然语言处理上,迁移的方法和计算机视觉一样。
引用参考
https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html