MySQL基础(DDL、DML、DQL)
每天进步一点点
- 数据库相关概念
-
- 什么是数据库
- 数据库的优点
- 常见的数据库
- 关系型数据库
- MySQL数据库
-
- SQL简介
- MySQL 目录结构
- MySQL 数据库连接
- SQL_DDL_操作数据库
-
- DDL_创建和查看数据库
- DDL_修改和删除数据库
- SQL_DDL_操作数据表
-
- DDL_数据库约束
- DDL_创建和查看和表
- DDL_删除表和修改表的结构
- SQL_DML_操作数据库
-
- DML_插入表数据
- DML_更新表数据
- DML_删除表记录
- SQL_DQL_ 简单查询数据
-
- DQL_基础查询
- DQL_条件查询
- DQL_模糊查询
- DQL_查询排序
- DQL_ 聚合函数
- DQL_分组查询
- DQL_分页查询
数据库相关概念
什么是数据库
保存数据的仓库。它体现我们电脑中,就是一个软件或者文件系统。然后把数据都保存这些特殊的文件中,并且需要使用固定的语言(SQL语言/语句)去操作文件中的数据。
- 存储数据的仓库,数据是具有组织的进行存储
- 英文名:
DataBase,简称 DB
数据库的优点
数据库是按照特定的格式将数据存储在文件中,通过SQL语句可以方便的对大量数据进行
增、删、改、查操作,数据库是对大量的信息进行管理的高效的解决方案。
常见的数据库
常见的关系型数据库管理系统
我们开发应用程序的时候,程序中的所有数据,最后都需要保存到专业软件中。这些专业的保存数据的软件我们称为数据库。我们学习数据库,并不是学习如何去开发一个数据库软件,我们学习的是如何使用数据库以及数据库中的数据记录的操作。而数据库软件是由第三方公司研发。

- Oracle:它是Oracle公司的大型关系型数据库。系统可移植性好、使用方便、功能强,适用于各类大、中、小、微机环境。它是一种高效率、安全可靠的。但是它是收费的。
- MYSQL:早期由瑞典一个叫MySQL AB公司开发的,后期被sun公司收购,再后期被Oracle收购。体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发都选择 MySQL 作为网站数据库。MySQL6.x版本也开始收费。
- DB2 :IBM公司的数据库产品,收费的。常应用在银行系统中.
- SQLServer:MicroSoft 公司收费的中型的数据库。C#、.net等语言常使用。
- SyBase:Sybase公司的。 已经淡出历史舞台。提供了一个非常专业数据建模的工具PowerDesigner。
常用数据库:Java开发应用程序主要使用的数据库:MySQL(5.6)、Oracle、DB2。(原因:开源,免费,功能足够强大,足以应付web开发)
关系型数据库
在开发软件的时候,软件中的数据之间必然会有一定的关系存在。比如商品和客户之间的关系,一个客户是可以买多种商品,而一种商品是可以被多个客户来购买的。
需要把这些数据保存在数据库中,同时也要维护数据之间的关系,这时就可以直接使用上述的那些数据库。而上述的所有数据库都属于关系型数据库。
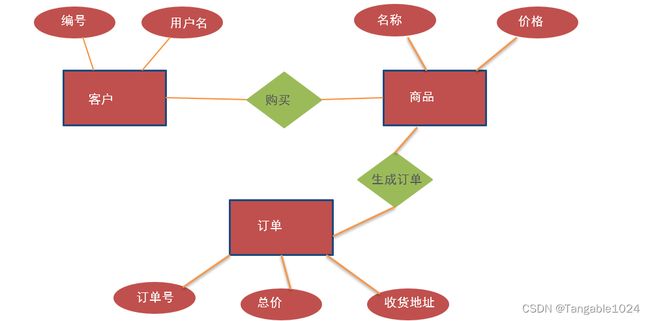
关系型数据:设计数据库的时候,需要使用E-R实体关系图来描述。
E-R 是两个单词的首字母,E表示
Entity实体 R表示Relationship关系。
- 1.数据表中的数据之间必然会有一定的关系存在,比如商品和客户之间的关系,一个客户是可以买多种商品,而一种商品是可以被多个客户来购买的。
- 2.设计数据库的时候,可以使用ER实体关系图来描述表之间的关系,E表示Entity 实体 , R表示Relationship 关系
- 3.实体:可以理解成我们Java程序中的一个对象。比如商品,客户等都是一个实体对象。在E-R图中使用 矩形(长方形) 表示。
- 4.属性:实体对象中是含有属性的,比如商品名、价格等。针对一个实体中的属性,我们称为这个实体的数据,在E-R图中使用椭圆表示。
- 5.关系:实体和实体之间的关系:在E-R图中使用菱形表示。
需求: 使用E-R图描述 客户、商品、订单之间的关系
MySQL数据库
SQL简介
什么是SQL
Structured Query Language结构化查询语言。SQL语句不依赖于任何平台,对所有的数据库是通用的。学会了SQL语句的使用,可以在任何的数据库使用,但都有特有内容。SQL语句功能强大、简单易学、使用方便。
SQL特点
SQL语句是一个非过程性的语言,每一条SQL执行完都会有一个具体的结果出现。多条语句之间没有影响
SQL作用
SQL语句主要是操作数据库,数据表,数据表中的数据记录
SQL通用语法
- SQL语句可以单行或多行书写,以分号结尾。
- 可使用空格和缩进来增强语句的可读性。
- MySQL数据库的SQL语句不区分大小写,关键字开发中一般大写.
- 三种注释
- 单行注释:-- 注释内容
- 多行注释:/* 注释内容 */
-# 注释内容:(mysql特有的单行注释)
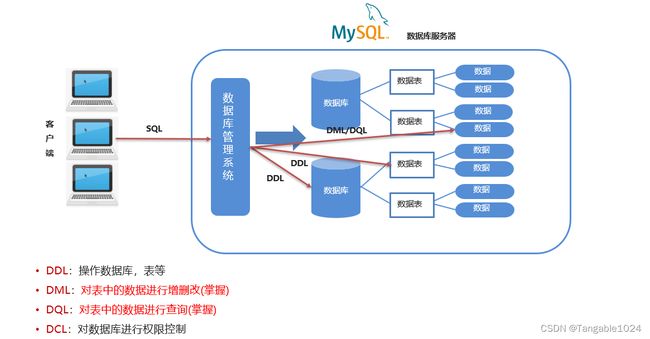
SQL分类
SQL是用来存取关系数据库的语言,具有定义、操纵、控制和查询关系型数据库的四方面功能。所以针对四方面功能,我们将SQL进行了分类。
DDL(Data Definition Language)数据定义语言
用来定义数据库对象:数据库,表,列等。关键字:create drop alter truncate(清空数据记录) show等DML(Data Manipulation Language)数据操作语言★★★
在数据库表中更新,增加和删除记录。如 update(更新), insert(插入), delete(删除) 不包含查询
DQL(Data Query Language) 数据查询语言★★★★★
数据表记录的查询。关键字select。DCL(Data Control Language)数据控制语言(了解)
是用来设置或更改数据库用户或角色权限的语句,如grant(设置权限),revoke(撤销权限),begin transaction等。这个比较少用到。
MySQL 目录结构

MySQL 数据库连接
MySQL是一个需要账户名密码登录的数据库,登陆后使用,它提供了一个默认的root账号,使用安装时设置的密码即可登录。
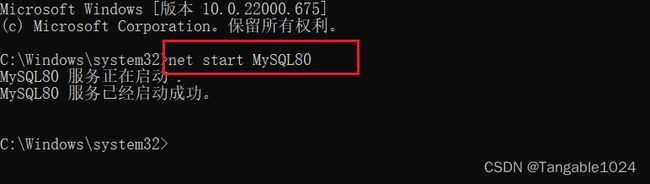
启动数据库服务:在打开dos窗口中输入net start MySQL命令
关闭数据库服务:在打开dos窗口中输入net stop MySQL命令

连接MySQL:登录格式1:mysql -u用户名 -p密码
mysql -uroot -p123456

登录格式2:mysql[-h连接主机ip地址 -P端口号3306] -u 用户名 -p 密码
mysql -h 127.0.0.1 -P 3306 -u root -p 123456

如果连接的是本机:可以省略 -h -P 主机IP和端口。这样就可以登录mysql数据库了
退出:exit命令

显示数据库: show databases;

SQL_DDL_操作数据库
DDL_创建和查看数据库
创建数据库:
1.直接创建数据库
create database 数据库名;
2.判断数据库是否存在并创建(如果不存在,则创建)
create database if not exists 数据库名;
3.创建数据库并指定字符集(编码表)
create database 数据库名 character set 字符集;
说明:字符集就是编码表名,在mysql中utf8
查看数据库:
1.查看所有数据库
show databases;
2.查看某个数据库的定义信息
show create database 数据库名;
3.查看当前使用的数据库
select database();
使用和切换数据库:
use 数据库名;
DDL_修改和删除数据库
修改数据库:
1.修改数据库字符集
-- alter 表示修改
alter database 数据库名 default character set 新字符集;
注意:如果修改数据库指定的编码表是utf8,记住不能写utf-8
Java中的常用编码对应mysql数据库中的编码
| Java | MySQL |
|---|---|
| UTF-8 | utf8 |
| GBK | gbk |
| GB2312 | gb2312 |
| ISO-8859-1 | latin1 |
删除数据库:
1.直接删除
-- drop 删除数据库
drop database 数据库名;
2.删除数据库时判断是否存在(如果存在,则删除)
drop database if exists 数据库名;
SQL_DDL_操作数据表
DDL_数据库约束
约束的概念:
-
约束是作用于表中列上的规则,用于限制加入表的数据
-
约束的存在保证了数据库中数据的正确性、有效性和完整性
约束的分类:
| 约束名称 | 关键字 | 描述 |
|---|---|---|
| 非空约束 | NOT NULL |
保证列中所有数据不能有null空值 |
| 唯一约束 | UNIQUE |
保证列中所有数据各不相同 |
| 主键约束 | PRIMARY KEY |
主键是一行数据的唯一标识,要求非空且唯一 |
| 检查约束 | CHECK |
保证列中的值满足某一条件 |
| 默认约束 | DEFAULT |
保存数据时,未指定值则采用默认值 |
| 外键约束 | FOREIGN KEY |
外键用来让两个表的数据之间建立链接,保证数据的一致性和完整性 |
MySQL5.7不支持检查约束,但写入语句不会报错,MySQL8.0版本支持检查约束
非空约束
非空约束用于保证列中所有数据不能有NULL值
1.建表时添加约束
-- 创建表时添加非空约束
create table 表名(
列名 数据类型 not null,
...
);
2.建完表之后添加约束
-- 建完表之后添加约束
alter table 表名 modify 字段名 数据类型 not null;
3.删除约束
alter table 表名 modify 字段名 数据类型;
唯一约束
唯一约束用于保证列中所有数据各不相同
1.创建表时添加唯一约束
-- 方式1
create table 表名(
字段名 数据类型 UNIQUE,
...
);
-- 方式2
create table 表名(
字段名 数据类型,
...
[CONSTRAINT] [约束名称] UNIQUE(列名)
);
2.建完表之后添加唯一约束
-- 建完表后添加唯一约束
alter table 表名 modify 字段名 数据类型 UNIQUE;
3.删除唯一约束
alter table 表名 drop index 字段名;
主键约束
- 主键是一行数据的唯一标识,要求非空且唯一
- 一张表只能有一个主键
1.创建表时添加主键约束
create table 表名(
字段名 数据类型 PRIMARY KEY [AUTO_INCREMENT],
-- [AUTO_INCREMENT] 当不指定值时自动增长
...
);
create table 表名(
列名 数据类型,
[CONSTRAINT] [约束名称] PRIMARY KEY(列名)
)
2.建完表之后添加主键约束
alter table 表名 add PRIMARY KEY(字段名);
3.删除主键约束
alter table 表名 drop PRIMARY KEY;
默认约束
保存数据时,未指定值则采用默认值
1.创建表时添加默认约束
create table 表名(
字段名 数据类型 default 默认值,
...
);
2.建完表后添加默认约束
alter table 表名 alter 列名 set DEFAULT 默认值;
3.删除约束
alter table 表名 alter 列名 drop DEFAULT;
DDL_创建和查看和表
前提 :创建数据库db1并使用这个数据库
-- 创建数据库
create database db1;
-- 使用数据库
use db1;
创建表:
create table 表名(
字段名1 字段类型 约束条件,
字段名2 字段类型 约束条件,
...
字段名n 字段类型 约束条件
);
-- 注意:最后一个字段不加逗号
创建一个表结构和其他表结构相同的表
create table 表名 like 其他表名;
MySQL中常用的数据类型

案列需求:
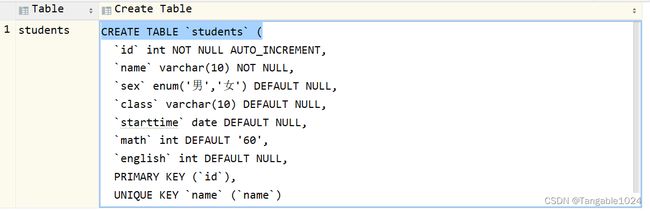
设计一张学生表,要求如下:
- 学号,要求唯一主键,自增
- 姓名,不能为空,且唯一
- 性别,只有男和女,默认值为null
- 班级,字符串类型
- 入学时间,取值为年、月、日
- 数学成绩,double类型,默认为60分
- 英语成绩,double类型,没有默认值
create table students(
id int primary key auto_increment,
name varchar(10) not null unique,
sex enum('男','女') default null,
class varchar(10),
starttime date,
math int default 60,
english int
);
![]()
查看表:
1.查看某个数据库中所有的表
show tables;
2.查看表结构
desc 表名;
3.查看创建表的SQL语句
show create table 表名;
-- 根据该语句查看上面案列的建表sql语句
show create table students;
DDL_删除表和修改表的结构
删除表:
1.直接删除
drop table 表名;
2.删除表时判断表是否存在(如果存在,则删除)
drop table if exists 表名;
修改表:
1.修改表名
alter table 旧表名 rename to 新表名;
2.向表中添加一个字段(一列)
alter table 表名 add 字段名 数据类型;
3.修改表中字段数据类型
alter table 表名 modify 字段名 新的数据类型;
4.修改表中字段名(列名)和数据类型
alter table 表名 change 字段名 新的字段名 新的数据类型;
5.删除表中字段(列)
alter table 表名 drop 字段名;
SQL_DML_操作数据库
DML_插入表数据
1.插入全部字段
-- 全部字段写出来
insert into 表名(字段1,字段2,...) values(值1,值2,...);
-- 插入全部不写字段名
insert into 表名 values(值1,值2,...);
-- 给案例中的表插入数据
insert into students(id,name,sex,class,starttime,math,english) values(1,'张三','男','高三1班','2022-03-02',80,69);
insert into students values(2,'李四','女','高三2班','2022-03-01',70,80);

2.插入部分数据
-- 插入姓名,班级,入学时间,英语成绩
-- id默认增长,性别默认null,数学默认60
insert into students(name,class,starttime,english) values('王五','高三3班','2022-03-02',78);

说明:插入部分数据的时候,要求列名一定书写出来。
3.批量插入数据
insert into 表名 values(字段值1, 字段值2...),
(字段值1, 字段值2...),
(字段值1, 字段值2...);
没有添加数据的字段会使用NULL
注意:
值与列一一对应。有多少个列,就需要写多少个值。如果某一个列没有值,可以使用null,表示插入空。
值的数据类型,与列被定义的数据类型要相匹配,并且值的长度,不能够超过定义的列的长度。
字符串:插入字符类型的数据,建议写英文单引号括起来。在mysql中,使用单引号表示字符串
date 时间类型的数据也得使用英文单引号括起来: 如
yyyy-MM-dd
DML_更新表数据
1.不带条件修改数据
update 表名 set 字段名=新的值,字段名=新的值,...;
-- 注意:不带条件的修改是将数据表中的整列都做修改
-- 修改students表中math的值为90
update students set math=90;

2.带条件修改数据
update 表名 set 字段名=新的值,字段名=新的值,... where 条件;
-- 修改students表中王五的性别为男,数学成绩设置为70
update students set sex='男',math=70 where name='王五';

3.关键字说明
UPDATE: 表示修改记录
SET: 要改哪个字段
WHERE: 设置条件
4.注意
- 不带条件的更新数据库记录:UPDATE 表名 SET 字段名=新的值;是将整个表中修改的列修改
- 带条件:UPDATE 表名 SET 字段名=新的值 WHERE 条件
DML_删除表记录
1.不带条件删除
DELETE -- 删除记录
DELETE FROM 表名;
表还在,可以操作,只是删除数据。
2.带条件删除
DELETE FROM 表名 WHERE 条件;
-- 删除学生表中的王五的信息
DELETE FROM students WHERE name='王五';

3.truncate删除表记录(属于DDL)
truncate table 表名;
4.truncate和delete区别
- delete是将表中的数据一条一条删除
- truncate是将整个表摧毁,重新创建一个新的表,新的表结构和原来表结构一模一样
SQL_DQL_ 简单查询数据
准备一张学生表,在这张表上进行查询操作
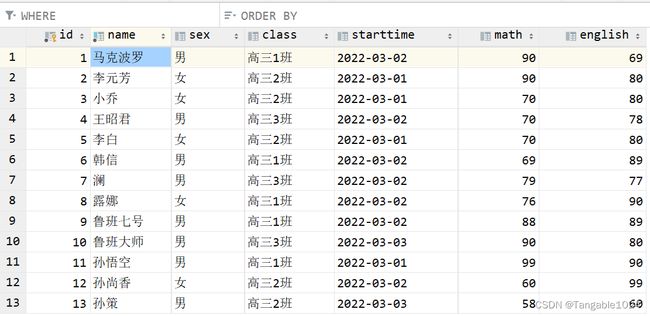
DQL_基础查询
1.查询所有数据
select * from 表名;
-- 查询学生表中所有的数据
select * from students;

2.查询指定列的数据
select 字段名1,字段名2,... from 表名;
-- 查询姓名和班级这两个字段
select name,class from students;

3.查询到的字段设置别名
select 字段名1 as 别名1,字段名2 as 别名2 from 表名;
-- 查询students表中的字段并设置别名
select id as 学号,name as 姓名,sex as 性别,class as 班级 , starttime as 入学时间 from students;
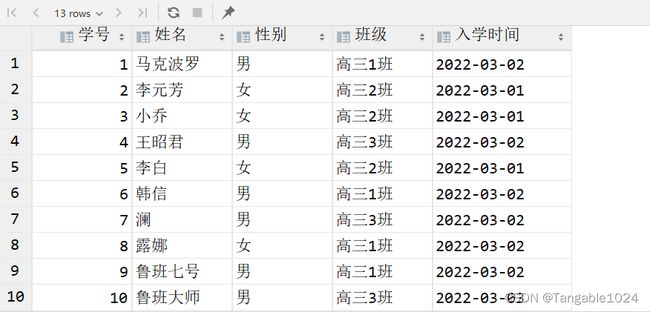
4.查询到的数据去重
-- DISTINCT 去重复
-- 查询班级字段结果不出现重复的
select DISTINCT class from students;

DQL_条件查询
1.条件查询语法
select 字段名1,字段名2,... where 条件列表;
2.条件运算符
| 符号 | 功能 |
|---|---|
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| = | 等于 |
| <>或!= | 不等于 |
| BETWEEN…AND… | 在某个范围内(都包括) |
| IN(…) | 多选一 |
| LIKE | 模糊查询,_单个任意字符,%多个任意字符 |
| IS NULL | 为空 |
| IS NOT NULL | 不为空 |
| AND 或 && | 与,并且 |
| OR 或 || | 或,或者 |
| NOT 或 ! | 非,不是 |
3.查询数学成绩大于80并且性别为男的学生
-- 两个条件同时满足
select * from students where math > 80 and sex='男';
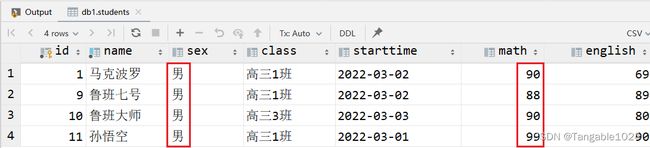
4.查询英语成绩在60-80之间的学生
-- BETWEEN 值1 AND 值2 -- 表示从值1到值2范围,包头又包尾
select * from students where english between 60 and 80;
select * from students where english>=60 && english<=80;

5.查询学号为1或者2或者3的学生
-- in里面的每个数据都会作为一次条件,只要满足条件的就会显示
select * from students where id in (1,2,3);

DQL_模糊查询
LIKE:表示模糊查询
select * from 表名 where 字段名 like '通配字符';
MySQL通配符有两个:
%:表示0个或多个字符(任意字符)_:表示一个字符
1.查找名字中以孙开头的学生
-- '孙%'表示孙后面有任意个字符
select * from students where name like '孙%';

2.查找名字中以孙开头的两个字的学习
-- '孙_'表示孙后面只能有一个字符
select * from students where name like '孙_';

DQL_查询排序
通过ORDER BY子句,可以将查询出的结果进行排序(排序只是显示方式,不会影响数据库中数据的顺序)
-- ASC:升序排序(默认)
-- DESC:降序排序
select 字段 from 表名 order by 排序字段 [ASC|DESC];
1.单列排序
-- 查询学生的数学成绩按照升序排序
select * from students order by math ASC;
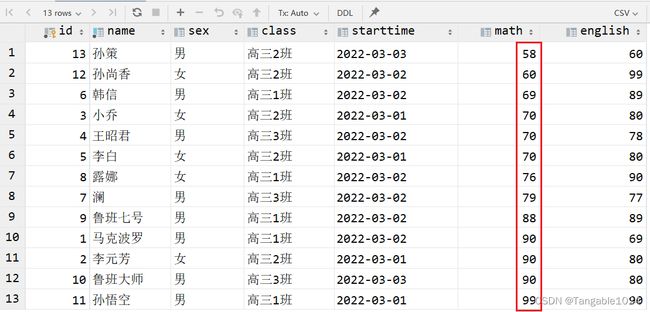
2.组合排序
-- 查询数学成绩升序的基础上,英语成绩降序
-- 组合排序就是先按第一个字段进行排序,如果第一个字段相同,才按第二个字段进行排序,依次类推。
select * from students order by math ASC,english DESC;

DQL_ 聚合函数
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个结果值;另外聚合函数会忽略空值,对于null不作为统计。
1.五个聚合函数
| 函数名 | 功能 |
|---|---|
| count(列名) | 统计数量(一般选用不为null的列) |
| max(列名) | 最大值 |
| min(列名) | 最小值 |
| sum(列名) | 求和 |
| avg(列名) | 平均值 |
2.聚合函数语法
select 聚合函数名(列名) from 表名;
注意:null 值不参与所有聚合函数运算
3.查询学生总数
select count(id) from students;
-- 通常使用
select count(*) from students;

4.查询最高分和最低分
-- 查询数学最高分和英语最低分
select max(math),min(english) from students;

5.求和求平均值
-- 求该表数学总分和平均值
select sum(math),avg(math) from students;

6.ifnull()函数
-- ifnull(列名,默认值)函数表示判断该列是否为空值,如果为null,返回默认值,如果不为空,返回实际值
ifnull(math,60); -- 如果数学成绩为null时,返回60,如果不为null,就返回实际值
DQL_分组查询
分组: 按照某一列或者某几列。把相同的数据,进行合并输出。
1.注意
- 按照某一列进行分组,目的为了统计使用。
- 聚合函数:分组之后进行计算
- 通常
select后面的内容是被分组的列,以及聚合函数 - 在
sql语句中的where后面不允许添加聚合函数 - 可以使用
having条件,表示分组之后的条件,在having后面可以书写聚合函数
2.查询各个班级的数学成绩总和
-- 查询每个班的数学成绩总和
select class,sum(math) from students group by class;

3.having用法
having必须和group by 一起使用,having和where的用法一模一样,where怎么使用having就怎么使用,where不能使用的,having也可以使用,比如说where后面不可以使用聚合函数,但是在having后面是可以使用聚合函数的。
-- 查询每个班数学总成绩大于300分的班级并显示总成绩
select class,sum(math) from students group by class having sum(math)>300;

4.where和having的区别
-
having 通常与group by 分组结合使用。 where 和分组无关。
-
having 可以书写聚合函数 (聚合函数出现的位置: having 之后),例如having中的 聚合函数(count,sum,avg,max,min),是不可以出现where条件中。
-
where 是在分组之前进行过滤的,having 是在分组之后进行过滤的。
DQL_分页查询
1.应用和概念
比如我们登录京东,淘宝,返回的商品信息可能有几万条,不是一次全部显示出来。是一页显示固定的条数。假设我们一每页显示5条记录的方式来分页。

-- 起始索引:从0开始,索引是0表示数据表第一行数据
select 字段列表 from 表名 limit 起始索引,查询条目数;
计算公式:起始索引=(当前页码-1)* 每页显示的条数
注意:
- 分页查询
limit是MySQL数据库的方言- Oracle分页查询使用
rownumber- SQLServer分页查询使用
top
2.分页查询
-- 查询学生表中数据,每四条数据为一页
select * from students limit 0,4;
select * from students limit 4,4;
select * from students limit 8,4;
select * from students limit 12,4;
...
-- 注意:最后一行不够查询条目数,有多少就显示多少
3.返回前几条或者中间某几行数据
-- 2表示分页查询的索引,对应数据表是第3行数据,4表示每页显示4条数据
-- 查询从第三行数据开始查询之后的四条数据
select * from students limit 2,4;

4.SQL执行顺序
SELECT 字段名(5) FROM 表名(1) WHERE 条件(2) GROUP BY 分组列名(3) HAVING 条件(4) ORDER BY 排序列名(6) LIMIT 跳过行数, 返回行数(7);
执行顺序:1234567
顺序:1234567