MySQL基础总结:DDL、DML和DQL
目录
一、MySQL常见数据类型
二、DDL
1.数据库操作
2.数据表操作
2.1 表的创建
2.2 表的修改
2.3 表的删除
2.4 表的复制
3.约束
3.1 主键约束:primary key
3.2 非空约束:not null
3.3 唯一约束:unique
3.4 外键约束:foreign key
三、DML
1.添加数据
2.删除数据
3.修改数据
四、DQL
1.简单查询
2.条件查询
3.排序查询
4.分组查询
5.多表连接查询★
5.1 内连接
5.2 外连接
5.3 子查询
5.4 分页查询
5.5 联合查询
一、MySQL常见数据类型
数值类型
| 类型 | 大小 | 范围 | 用途 |
| INT或INTEGER | 4 Bytes | (0,4 294 967 295) | 大整数值 |
| DOUBLE | 8 Bytes | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
日期和时间类型
| 类型 | 大小 | 范围 | 格式 | 用途 |
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 3 | 1970-01-01 00:00:00/2038 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
字符串类型
| 类型 | 大小 | 用途 |
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TEXT | 0-65535 bytes | 长文本数据 |
二、DDL
DDL(Data Define Languge):数据定义语言,用于库和表的创建、修改、删除
1.数据库操作
1.1 创建数据库:
create database 数据库名称;
创建数据库,判断不存在,再创建:
create database if not exists 数据库名称;
创建数据库,并指定字符集
create database 数据库名称 character set 字符集名;
1.2 查询所有数据库的名称:
show databases;
查询某个数据库的字符集:查询某个数据库的创建语句
show create database 数据库名称;
1.3 修改数据库的字符集
alter database 数据库名称 character set 字符集名称;
1.4 删除数据库
drop database 数据库名称;
判断数据库存在,存在再删除
drop database if exists 数据库名称;
1.5 查询当前正在使用的数据库名称
select database();
1.6 使用数据库
use 数据库名称;
2.数据表操作
2.1 表的创建
语法:
create table 表名(
列名1 数据类型1 【字段约束】,
列名2 数据类型2 【字段约束】,
....
列名n 数据类型n 【字段约束】
);
例子:创建一个student表
| 字段名 | 数据类型 |
| sno | int(11) |
| sname | varchar(10) |
CREATE TABLE student(
sno INT(11),
sname VARCHAR(10)
);2.2 表的修改
修改表名
alter table 表名 rename to 新的表名;
修改表的字符集
alter table 表名 character set 字符集名称;
修改列名称 类型
alter table 表名 change 列名 新列别 新数据类型;
alter table 表名 modify 列名 新数据类型;
2.3 表的删除
drop table 表名;
drop table if exists 表名;
2.4 表的复制
表结构的复制:
create table 复制后的表名 like 被复制的表名
表结构和数据一起复制
create table 复制后的表名 select * from 被复制的表名
当然你也可以灵活运用,查询语句只写你需要复制的部分
3.约束
约束:对表中的数据进行限定,保证数据的正确性、有效性和完整性。
分类: 1. 主键约束:primary key
2. 非空约束:not null
3. 唯一约束:unique
4. 外键约束:foreign key
3.1 主键约束:primary key
1.含义:非空且唯一
2.一张表只能有一个字段为主键
3.主键就是表中记录的唯一标识
在创建表时,添加主键约束
create table stu(
id int primary key, //给id添加主键约束
name varchar(20)
);删除主键
ALTER TABLE stu DROP PRIMARY KEY; //删除stu表中的主键创建完表后,添加主键
ALTER TABLE stu MODIFY id INT PRIMARY KEY; 自动增长:(也称为标识列)
1. 概念:如果某一列是数值类型的,使用 auto_increment 可以来完成值得自动增长
2. 在创建表时,添加主键约束,并且完成主键自增长
create table stu(
id int primary key auto_increment,//给id添加主键约束,并设置为自动增长
name varchar(20)
);3. 删除自动增长
ALTER TABLE stu MODIFY id INT; //删除id设置的自动增长4. 创建完表后,添加自动增长
ALTER TABLE stu MODIFY id INT AUTO_INCREMENT;3.2 非空约束:not null
某一列的值不能为null
创建表时添加约束
CREATE TABLE stu(
id INT,
NAME VARCHAR(20) NOT NULL //name为非空
);创建表完后,添加非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20) NOT NULL;删除name的非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20);3.3 唯一约束:unique
某一列的值不能重复,唯一约束可以有NULL值,但是只能有一条记录为null
创建表时,添加唯一约束
CREATE TABLE stu(
id INT,
phone_number VARCHAR(20) UNIQUE //手机号
);删除唯一约束
ALTER TABLE stu DROP INDEX phone_number;在表创建完后,添加唯一约束
ALTER TABLE stu MODIFY phone_number VARCHAR(20) UNIQUE;3.4 外键约束:foreign key
让表于表产生关系,从而保证数据的正确性
创建表时,可以添加外键
create table 表名(
....
外键列
constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称)
);
删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
创建表之后,添加外键
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称);
级联操作
1. 添加级联操作
语法:ALTER TABLE 表名 ADD CONSTRAINT 外键名称
FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称) ON UPDATE CASCADE ON DELETE CASCADE ;
2. 分类:
1. 级联更新:ON UPDATE CASCADE
2. 级联删除:ON DELETE CASCADE
三、DML
DML(Data Manipulate Language):数据操纵语言,用于添加、删除、修改数据库记录,并检查数据完整性
1.添加数据
添加单行数据:
方式1:insert into 表名(列名1,列名2,...列名n) values(值1,值2,...值n);
方式2:insert into 表名 set 列名1=值1,列名2=值2,...列名n=值n;
添加多行数据:
insert into 表名(列名1,列名2,...列名n)
values(值1,值2,...值n),
...........
values(值1,值2,...值n);
注意:
1. 列名和值要一一对应。
2. 如果表名后,不定义列名,则默认给所有列添加值
insert into 表名 values(值1,值2,...值n);
3. 除了数字类型,其他类型需要使用引号(单双都可以)引起来
2.删除数据
删除单行数据:
delete from 表名 where 条件
删除表中全部数据:
方式1:delete from 表名
方式2:truncate table 表名
delete与TRUNCATE区别?
1.truncate不能加where条件,而delete可以加where条件
2.truncate的效率高
3.truncate 删除带自增长的列的表后,如果再插入数据,数据从1开始
4.delete 删除带自增长列的表后,如果再插入数据,数据从上一次的断点处开始
5.truncate删除不能回滚,delete删除可以回滚
3.修改数据
修改单表
update 表名 set 列名1 = 值1, 列名2 = 值2,... [where 条件];
修改多表
update 表1 别名1,表2 别名2 set 字段=新值,字段=新值 where 连接条件 and 筛选条件
注意:如果不加任何条件,则会将表中所有记录全部修改
四、DQL
DQL(Data Query Language):数据查询语言,用来查询数据库中表的记录(数据)
1.简单查询
1.1 查询表中所有记录
select * from 表名;
1.2 查询表中多个字段
select 字段1,字段2... from 表名;
1.3 去除表中重复值
select distinct(字段名) from 表名;
1.4 计算列
一般可以使用四则运算计算一些列的值。
ifnull(表达式1,表达式2):null参与的运算,计算结果都为null
表达式1:哪个字段需要判断是否为null
表达式2:如果该字段为null后的替换值
1.5 起别名
as(可以省略)
例子:select name (as) 姓名 from students
2.条件查询
2.1 语法:select 查询内容 from 表名 where 条件
2.2 运算符
> 、< 、<= 、>= 、= 、<>
BETWEEN...AND
IN( 集合)
LIKE:模糊查询
占位符:
_:单个任意字符
%:多个任意字符
IS NULL
and 或 &&
or 或 ||
not 或 !
3.排序查询
3.1 语法
select 要查询的东西
from 表名
where 条件
order by 排序的字段名|表达式|函数|别名 【asc|desc】
3.2 排序方式
ASC:升序,默认的
DESC:降序
3.3 排序分类
1.按单个字段进行排序
2.按多个字段排序
3.按表达式排序
4.按别名排序
5.按函数排序
注意:如果有多个排序条件,则当之前的条件值一样时,才会判断第二条件
4.分组查询
4.1分组函数
count:计算个数,一般选择非空的列:主键 count( )
max:计算最大值
min:计算最小值
sum:计算和
avg:计算平均值
特点:
1、以上五个分组函数都忽略null值,除了 count( )
2、sum和avg一般用于处理数值型,max、min、count可以处理任何数据类型
3、都可以搭配distinct使用,用于统计去重后的结果
4、count的参数可以支持:字段、 、常量值,一般放1
注意:聚合函数的计算,排除null值。
解决方案:
选择不包含非空的列进行计算
IFNULL函数
4.2 分组查询
语法:
select 查询的字段,分组函数
from 表
group by 分组的字段
特点:
1、可以按单个字段分组
2、和分组函数一同查询的字段最好是分组后的字段
3、可以按多个字段分组,字段之间用逗号隔开
4、可以支持排序
5、having后可以支持别名(分组后再筛选)
6、分组字段可以为函数
where 和 having 的区别?
1. where 在分组之前进行限定,如果不满足条件,则不参与分组。having在分组之
后进行限定,如果不满足结果,则不会被查询出来
2. where 后不可以跟聚合函数,having可以进行聚合函数的判断。
5.多表连接查询★
5.1 内连接:两个表的所有数据

语法:
select 字段列表
from 表名1
[inner] join 表名2 on 条件
where 筛选条件
group by 分组条件
having 分组后的筛选条件
order by 排序字段
注意:
1. 使用表名前缀在多个表中区分相同的列
2. 在不同表中具有相同列名的列可以用表的别名加以区分
3. 如果使用了表别名,则在select语句中需要使用表别名代替表名
4. 表别名最多支持32个字符长度,但建议越少越好
5.2 外连接
应用场景:用于查询一个表中有,另一个表没有的记录
左外连接:左外连接查询的是左表所有数据以及其交集部分
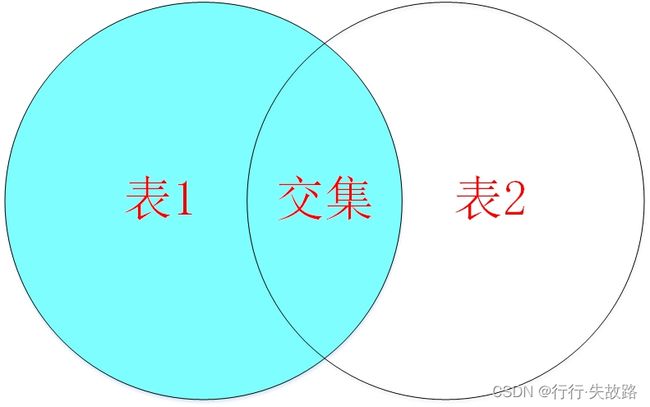
语法:
select 字段列表
from 表1
left [outer] join 表2 on 条件
...
右外连接:右外连接查询的是右表所有数据以及其交集部分
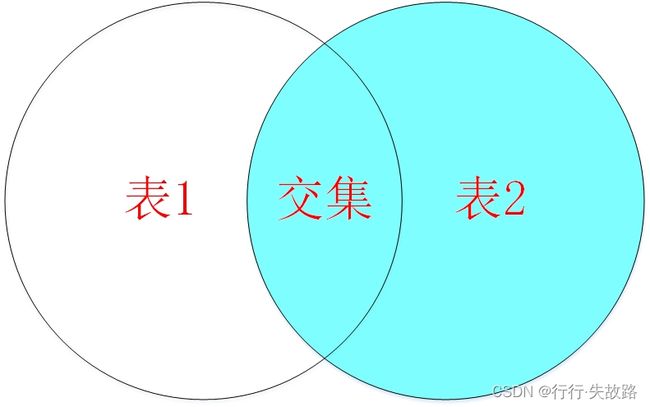
语法:
select 字段列表
from 表1
right [outer] join 表2 on 条件
...
全外连接:全外连接就是将左连接和右连接的结果合并,中间用unino关键字
5.3 子查询
概念:查询中嵌套查询,称嵌套查询为子查询
特点:
1、子查询都放在小括号内
2、子查询可以放在from后面、select后面、where后面、having后面,但一般放在 条件的右侧
3、子查询优先于主查询执行,主查询使用了子查询的执行结果
4、子查询根据查询结果的行数不同分为以下两类:
① 单行子查询
结果集只有一行
一般搭配单行操作符使用:> < = <> >= <=
非法使用子查询的情况:
a、子查询的结果为一组值
b、子查询的结果为空
② 多行子查询
结果集有多行
一般搭配多行操作符使用:any、all、in、not in
in: 属于子查询结果中的任意一个就行
any和all往往可以用其他查询代替
5.4 分页查询
语法:
select 字段|表达式,...
from 表
where 条件
group by 分组字段
having 条件
order by 排序的字段
limit 起始的条目索引,条目数;
示例:每页显示3条记录
SELECT * FROM student LIMIT 0,3; -- 第1页
SELECT * FROM student LIMIT 3,3; -- 第2页
SELECT * FROM student LIMIT 6,3; -- 第3页
特点:
1.起始条目索引从0开始
2.limit子句放在查询语句的最后
3.公式:select * from 表 limit (page-1)*sizePerPage,sizePerPage
假如:
每页显示条目数sizePerPage
要显示的页数 page
5.5 联合查询
语法:
select 字段|常量|表达式|函数 from 表 where 条件 union 【all】
select 字段|常量|表达式|函数 from 表 where 条件 union 【all】
select 字段|常量|表达式|函数 from 表 where 条件 union 【all】
.....
select 字段|常量|表达式|函数 from 表 where 条件
特点:
1、多条查询语句的查询的列数必须是一致的
2、多条查询语句的查询的列的类型几乎相同
3、union代表去重,union all代表不去重
应用场景:
要查询的结果来自于多个表,且多个表没有直接的连接关系,但查询的信息一致时
特点:★
1、要求多条查询语句的查询列数是一致的!
2、要求多条查询语句的查询的每一列的类型和顺序最好一致
3、union关键字默认去重,如果使用union all可以包含重复项
本次MySQL基础介绍完毕,如有缺少和错误地方,请指出!!!