新星计划day8【Java语言IO流】转换流的详解

博客首页:痛而不言笑而不语的浅伤
欢迎关注点赞 收藏 ⭐留言 欢迎讨论!
本文由痛而不言笑而不语的浅伤原创,CSDN首发!
系列专栏:《JavaSE系列详解》
首发时间:2022年5月2日
❤:热爱Java学习,期待一起交流!
作者水平有限,如果发现错误,求告知,多谢!
有问题可以私信交流!!!
导航小助手
目录
☆引言☆
一、字符编码和字符集
字符编码
字符集
二、编码引出的问题
三、转换流的概述和原理
概述
原理
四、转换流的分类和作用
分类
作用
五、转换流的使用
字符输出转换流【OutputStreamWriter】
字符输入转换流【InputStreamReader】
小练习
总结:
☆引言☆
大家好,上一章我们学习了Java语言IO流中的缓冲流,本章我们一起来学习Java语言IO流中的转换流。这篇文章主要带大家从字符编码、字符集、编码的问题和转换流的概述、原理,分类,作用以及使用步骤等几个方面深入学习Java语言IO流中的转换流。文章来自我的专栏《JavaSE系列详解》中,想要学习更多JavaSE的其他内容,订阅专栏《JavaSE系列详解》。对文章中描述错误的希望大家积极指出。
一、字符编码和字符集
字符编码
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字,英文:标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码,反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码,比如说,按照A规则存储,同样按明规则解析,那么就能显示正确的文术符号。反之,按照A规则存储,再按照B规则解析,就会导致乱码现象。
编码:字符(能看懂的)--字节(看不懂的)

解码:字节(看不懂的)-->字符(能看懂的)
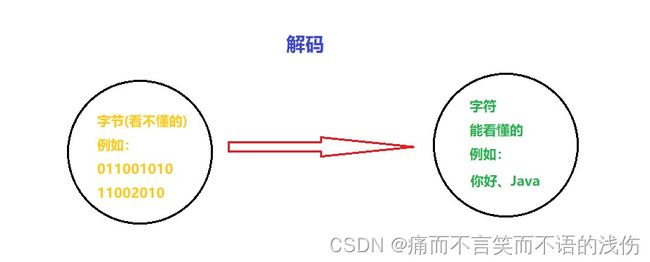
字符编码character Encoding:就是一真自然语言的字符与二进制数之间的对应规则。
编码表:生活中文字和计算机中二进制的对应规则
字符集
字符集Charset:也叫编码表。是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。
计算机要准确的存储和识别各种字符集符号,需要进行字符编码,一套字符集必然至少有一套字符编吗。常见字符集有ASCII字符集,GBK字符集,Unicode字符集等。

可见,当指定了编码,它所对应的字符集自然就指定了,所以编码才是我们最终要关心的。
ASCII字符集:
ASCII(American Standard Code for InformationInterchanee美国信息交换标准代码)是其于拉丁字母的一真电脑编码系统,用干显示现代英语,主要包括控制字符(回车键,退格,换行键等)和可显示字符(英文大小写字符,阿拉伯敦字和西文符号)。
基本的ASCIL字符集,使用7位(bits)表示一个字符,共128字符。ASCIL的扩展字符集使用8位(bits)表示一个字符,共256字符,方便支持欧洲常用字符。
ISO-8859-1字符集:
拉丁码表,别名Latin-1用于显示欧洲使用的语言包括荷兰、丹麦、德语、意大利语、西班牙语等。
ISO-5559-1使用单字节编码,兼客ASI编码
GBxxx字符集:
GB就是国标的意思,是为了显示中文而设计的一套字符集。
GB2312:简体中文码表。一个小干127的字符的意义与原来相同。但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含7000多个简体汉字,此外数学符号,罗马希腊的字母,日文的假名们都编进去了,连在ASCII里本来就有的数字,称点,字母都统统重新编了两个字节长的编码,这就是常说的"全角”字符,而原来在127号以下的那些就叫"半角字符了。
GBK:最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了双字节编码方案,共收录了21003个汉字,完全将容GB2312标准,同时支持整体汉字以及日韩汉字等GB18030:最新的中文码表。收录汉字70244个,采用多字节编码,每个字可以由1个,2个或4个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
Unicode字符集:
Unicode编码系统为表达任意语言的任意字符而设计,是业界的一种标准,也称为统一码、标准万国码。
它最多使用4个字节的数字来表达每个字母,符号,或者文字,有三种编码方案,UTF-8,UTF-16和UTE-32。最为常用的UTF-8编码。
UTF-8编码:可以用来表示Unicode标准中任何字符,它是电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。所以我们开发Web应用,也要使用UTF-8编码。它使用一至四个字节为每个字符编码,编码规则:
1.128个US-ASCII字符,只需一个字节编码。
2.拉丁文等字符,需要二个字节编码。
3.大部分常用字(含中文) 使用三个字节编码。
4.其他极少使用的Unicode辅助字符,使用四字节编码。
二、编码引出的问题
在Eclipse中,使用FileReade读取项目中的文本文件。由于Eclipse的设置,都是默认的GBK编码,所以没有任何问题。但是,当读取Windows系统中创建的文本文件时,如果在Windows系统中创建的文件格式是UTF-8编码,就会出现乱码。
public class Demo01FileReader {
public static void main(String[] args) throws IOException {
FileReader fr=new FileReader("F:\\workspace\\新建文件夹\\UTF-8.txt");
int line=0;
while((line=fr.read())!=-1){
System.out.print((char)line);
}
fr.close();
}
}杩欎釜鏄疓BK鏍煎紡鐨勬枃鏈枃浠讹紝涓?浼氬効浼氳浆鎹㈡垚UTF-8鏍煎紡鐨勬枃浠?
鐜板湪鏄疷TF-8鏍煎紡鏂囦欢
那么如何读取UTF-8编码的文件呢?
三、转换流的概述和原理
概述
按照某种规则,将字符存储到计算机中,称为编码,反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码,比如说,按照A规则存储,同样按明规则解析,那么就能显示正确的文术符号。反之,按照A规则存储,再按照B规则解析,就会导致乱码现象。而这种转换的方式就是转换流。
原理
编码:字符(能看懂的)--字节(看不懂的)
解码:字节(看不懂的)-->字符(能看懂的)
图解:

四、转换流的分类和作用
分类
转换流分为:
OutputStreamWriter字符输出转换流
InputStreamReader字符输入转换流
作用
按照指定的编码表格式对读取文件过程中的数据进行格式转换作用。
五、转换流的使用
字符输出转换流【OutputStreamWriter】
OutputStreamWriter:是字符流通向字节流的桥梁:可使用指定的 charset 将要写入流中的字符编码成字节。(将能看懂的变成看不懂的)
继承关系:
java.io.OutputStreamWriter extends Writer
继承自父类的共性方法:
void write(int c) 写入单个字符。
void write(char[] cbuf) 写入字符数组。
abstract void write(char[] cbuf, int off, int len) 写入字符数组的某一部分。
void write(String str) 写入字符串。
void write(String str, int off, int len) 写入字符串的某一部分。
void flush() 刷新该流的缓冲。
void close() 刷新该流的缓冲。
构造方法:
OutputStreamWriter(OutputStream out) 创建使用默认字符编码的 OutputStreamWriter。
OutputStreamWriter(OutputStream out, String charsetName) 创建使用指定字符集OutputStreamWriter。
参数:
OutputStream out:字节输出流,可以用来写转换之后的字节到文件里
String charsetName:指定编码表名称,不区分大小写,可以是utf-8,UTF-8
使用步骤:
1.创建OutputStreamWriter对象,构造方法中传递字节输出流和指定的编码表名称;
2.使用OutputStreamWriter对象中的方法write,把字符转换为字节存储到缓冲区中(编码)
3.使用OutputStreamWriter对象中的方法flush,把内存缓冲区中的字节刷新到文件中(使用字节流写字节的过程)
4.释放资源
代码演示:
public static void main(String[] args) throws IOException {
write_gbk();
//write_utf_8();
}
//使用转换流OutputStreamWriter写GBK格式文件
private static void write_gbk() throws IOException, FileNotFoundException {
//1.创建OutputStreamWriter对象,构造方法中传递字节输出流和指定的编码表名称;
OutputStreamWriter osw=new OutputStreamWriter(new FileOutputStream("F:\\workspace\\新建文件夹\\gbk.txt"),"gbk");
//2.使用OutputStreamWriter对象中的方法write,把字符转换为字节存储到缓冲区中(编码)
osw.write("你好,Java,很高兴今天学会转换流。");
//3.使用OutputStreamWriter对象中的方法flush,把内存缓冲区中的字节刷新到文件中(使用字节流写字节的过程)
osw.flush();
//4.释放资源
osw.close();
}运行结果:使用转换流OutputStreamWriter写GBK格式文件


代码演示:
public static void main(String[] args) throws IOException {
write_utf_8();
}
//使用转换流OutputStreamWriter写UTF-8格式文件
private static void write_utf_8() throws UnsupportedEncodingException, FileNotFoundException, IOException {
//1.创建OutputStreamWriter对象,构造方法中传递字节输出流和指定的编码表名称;
OutputStreamWriter osw=new OutputStreamWriter(new FileOutputStream("F:\\workspace\\新建文件夹\\e.txt"),"utf-8");
//2.使用OutputStreamWriter对象中的方法write,把字符转换为字节存储到缓冲区中(编码)
osw.write("你好,Java,很高兴今天学会转换流。");
//3.使用OutputStreamWriter对象中的方法flush,把内存缓冲区中的字节刷新到文件中(使用字节流写字节的过程)
osw.flush();
//4.释放资源
osw.close();
}运行结果:使用转换流OutputStreamWriter写UTF-8格式文件


字符输入转换流【InputStreamReader】
InputStreamReader:是字节流通向字符流的桥梁:它使用指定的 charset 读取字节并将其解码为字符。(解码:看不懂的变成能看懂的)
继承关系:
java.io.InputStreamReader extends Reader
继承自父类的共性方法:
int read() 读取单个字符。
int read(char[] cbuf) 将字符读入数组。
void close() 关闭该流并释放与之关联的所有资源
构造方法:
InputStreamReader(InputStream in) 创建一个使用默认字符集的 InputStreamReader。
InputStreamReader(InputStream in, String charsetName) 创建使用指定字符集的 InputStreamReader。
参数:
InputStream in:字节输入流,可以用来读取文件中保存的字节
String charsetName:指定编码表名称,不区分大小写,可以是utf-8,UTF-8
使用步骤:
1.创建InputStreamReader对象,构造方法中传递字节输入流和指定的编码表名称;
2.使用InputStreamReader对象中的方法read读取文件
3.释放资源
注意事项:
构造方法中指定的编码表名称和文件的编码相同,否则会发生乱码
代码演示:
public static void main(String[] args) throws IOException {
write_gbk();
}
//使用转换流InputStreamReader读取GBK格式文件
private static void write_gbk() throws IOException {
//1.创建InputStreamReader对象,构造方法中传递字节输入流和指定的编码表名称;
InputStreamReader isr=new InputStreamReader(new FileInputStream("F:\\workspace\\新建文件夹\\gbk.txt"),"gbk");
//2.使用InputStreamReader对象中的方法read读取文件
int len=0;
while((len=isr.read())!=-1){
System.out.print((char)len);
}
//3.释放资源
isr.close();
}运行结果:使用转换流InputStreamReader读取GBK格式文件


代码演示
public static void main(String[] args) throws IOException {
read_utf_8();
}
//使用转换流InputStreamReader读取UTF-8格式文件
private static void read_utf_8() throws IOException{
//1.创建InputStreamReader对象,构造方法中传递字节输入流和指定的编码表名称;
InputStreamReader isr=new InputStreamReader(new FileInputStream("F:\\workspace\\新建文件夹\\e.txt"),"utf-8");
//2.使用InputStreamReader对象中的方法read读取文件
int len=0;
while((len=isr.read())!=-1){
System.out.print((char)len);
}
//3.释放资源
isr.close();
}运行结果:使用转换流InputStreamReader读取UTF-8格式文件


小练习
练习:转换文件编码
将GBK编码的文件,转换为UTF-8编码的文本文件
F:\\workspace\\新建文件夹\\gbk.txt

分析:
1.创建InputStreamReader对象,构造方法中传递字节输入流和指定GBK编码表
2.创建OutputSteramWriter对象,构造方法中传递字节输出流和指定UTF-8编码表
3.使用InputStreamReader对象中的read方法读取文件
4.使用OutputSteramWriter对象中的write方法将字节流转换成字符流
5.释放资源
代码演示
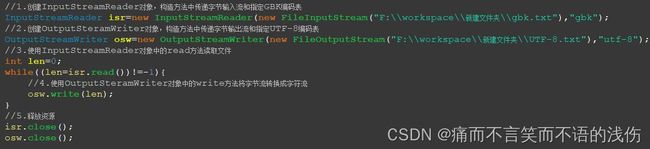
public class Demo04Test {
public static void main(String[] args) throws IOException{
//1.创建InputStreamReader对象,构造方法中传递字节输入流和指定GBK编码表
InputStreamReader isr=new InputStreamReader(new FileInputStream("F:\\workspace\\新建文件夹\\gbk.txt"),"gbk");
//2.创建OutputSteramWriter对象,构造方法中传递字节输出流和指定UTF-8编码表
OutputStreamWriter osw=new OutputStreamWriter(new FileOutputStream("F:\\workspace\\新建文件夹\\UTF-8.txt"),"utf-8");
//3.使用InputStreamReader对象中的read方法读取文件
int len=0;
while((len=isr.read())!=-1){
//4.使用OutputSteramWriter对象中的write方法将字节流转换成字符流
osw.write(len);
}
//5.释放资源
isr.close();
osw.close();
}
}运行结果:
运行前

运行后

总结:
好了以上就是转换流的一些学习,你是否学会了呢?今日的分享到此结束,由于笔者还在学习的路上辗转徘徊,水平有限,文章中可能有一些不对之处,还请各位大佬指正,最后祝愿每一个热爱编程的小伙伴,学习的路上不迷路,实现自己的追求。如果大家觉得还不错,希望多多支持一下,点赞,关注加收藏。
你的点赞是对我最大的鼓励。
你的收藏是对我文章的认可。
你的关注是对我创作的动力。
【完】