李宏毅机器学习笔记L3 卷积神经网络
L3 卷积神经网络
by 熠熠发光的白
CNN架构介绍
将图片每一个类别都表示成one-hot,例如猫的话对应猫的dimension是1,其余都是0,主要种类长度也就对应了dimension的长度。
在模型输出后经过softmax得到的y’要和 y ^ \hat y y^相同
一张图片是三维的tensor(宽,高,channel(RGB)),将三维的Tensor拉直,也就能作为network的输入
例如对于100×100×3,就有30000个pixel,拉伸后得到30000长度的向量。
在通过layer的时候,可以通过feature来判断相应的物种,因此,其实并不需要用到全连接,只需要把一小部分作为输入即可。
receptive field
只需要考虑这一部分的数值即可,再加上bias通过下一层的neuron作为输出。同一个neuron可以检查不同的receptive field
经典的设计方式
查看所有的channel,所以只要讲高和宽即可,也就是kernel size(常见的为3*3),向旁边平移一些为stride(不设计太大)
在超出范围的stride时,通过padding补值来使特征不丢失
同样的,pattern相同位置可能不一样,可能可以用parameter sharing来解决问题
对于两个neuron,他们的weight完全一样,所以可以用来共享参数。
共享参数
作为两组neuron,他们的参数相同,于是采用一个filter
receptive field 和 parameter sharing也就已因此组合成了从convolutional layer,用到其的network即为CNN
对于bias而言,它太大不一定是坏事,一个较为灵活的特征,如果bias设置的过小,则很容易造成overfitting
第二种设计方式
convolutional layer中有很多filter,都是3×3×3的大小。用filter来和图片的局部进行相乘,直到全部扫完,得到全部的数字。得到的新的数字集就是feature map。和开始的6×6×3得到了一个64个channel的”新图片“
Pooling
缩放(sub pooling),在一定的范围内取最大值(max pooling)
convolution-pooling-convolution-pooling-softmax-fully connected layers
坏处:CNN不能处理放大和缩小问题,所以需要data augmentation(增大)
自注意力机制
文字处理,每一个词汇都描述成向量,向量集的大小就会不一样。解决这个问题的简单方法是one-hot,但是这样的话就看不出单词的关系,还有一个方法是word embedding,这样可以看到聚集在一起。
对于声音来说,以25ms为一段,每次移动10ms(已经调好的最佳结果)。一秒钟有100个声音讯号,1分钟有6000个声音讯号。对于graph(图片)也是一个向量。可以将每个人作为一个向量来进行整理,分子同样也是一个向量(用one-hot表达原子)。
应用:sentiment analysis,通过评论来判断是正面的还是负面的,或者是语者辨认或者是分子的特性输出。
sequence labeling
给每一个向量进行一个label
self attention
用整个输入作为判断依据,也就是vector是考虑完一整个sequence之后得到的资讯。
思考过程
1.根据a1找出哪些向量和其有关,用α来表示
dot-product
把输入的两个向量分别乘上两个不同的矩阵Wq和Wk,得到q和k,两者点乘后得到α
addictive
把输入的两个向量乘上Wq和Wk,得到结果后相加,并进行tanh计算,再与W相乘得到结果
在之后都默认使用dot-product来进行计算。

注意,不一定要softmax来过滤,也可以采用ReLU等,有效即可。

qi和kj做dot-product得到αi,j,再与vj进行相乘,再全部加起来,就得到bi

将a1,a2,a3,a4拼起来,组成I,再将WI相乘得到q,同理得到k和v
同样的,可以顺水推舟,得到下图所示

经过normalization后,将其中的值相加是1,正则化
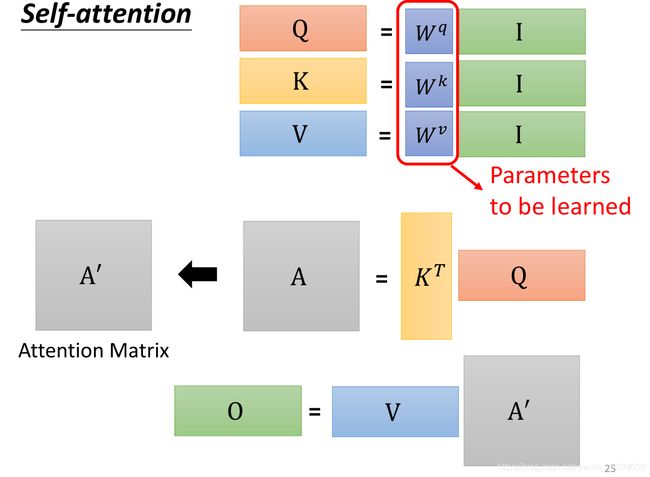
如图所示,通过I(input)来得到Q、K、和V,再利用Q和K的转置相乘等到A‘,V与A’相乘得到最后的答案O(output)
Multi-head Self-attention
多个Q来负责不同的相关性。通过将q与n个矩阵分别相乘,得到n个q,相应的,有n个k和n个v,对另一个位置也进行计算,然后用下图所示的dot-product来将bi1和bi2计算出来,将两者拼接在一块,最后与W0相乘得到bi

positional encoding
对于self-attention来说,并没有位置的咨询,所以可以为每一个位置设定一个ei,用ei+ai来判断
self attention的应用
transformer&bert
speech的自注意力应用
如果用语音来表示的话,则会非常的长,这样会导致计算量特别大,可以删减一些不必要的relavant来减少计算量
image的自注意力应用
将其作为每个pixel的三维向量来进行参考
Self-Attention GAN& DEtection Transformer(DETR)
Self-Attention和CNN的区别
CNN是一种简化的Self-Attention,因为它只在receptive field里考虑。具体可参照参考文献。
CNN对于较少的数据比较优秀,较多的数据的话Self-Attention比较好用。
Self-Attention和RNN的区别
总之就是self-attention更有效率,见参考文献
To learn more
未监督学习:word embedding
原因:使用one-hot编码的话相近的单词并不能有联系,因此采用word class的方式,将相同种类的归于一个class
word embedding是未监督的,要输入是词汇,输出是embedding。
问题:只知道输入,不知道输出。
count based: 如果两个单词wi和wj在同一个文章中出现,那么两个单词的value必须比较接近
prediction based:通过前一个单词来预测后面单词的可能性,必须通过对应转换将差不多类型的放置在一块。
对于wi-1和wi-2而言,不同的矩阵会带来不同的结果,所以要使他们相乘的weight保持一致。
training part
- skip gram:通过比对周围的单词来判断
- multi-domain embedding:将image进行分类
- document embedding
spacial transformer
CNN是对缩放和旋转有效的


就是这样进行transform
Recurrent Neural Network
slot filling:将句子里的信息填入,输入单词,输出结果。通过one-hot encoding来进行计算
如果输入的单词不在已有的向量label中,则归给other类型进行one-hot编码
这个时候就难以识别出发地和到达地,这个时候就要通过每一个段来进行观察来得到结果。前面的会影响到后面的结果。
Elman Network & Jordan Network
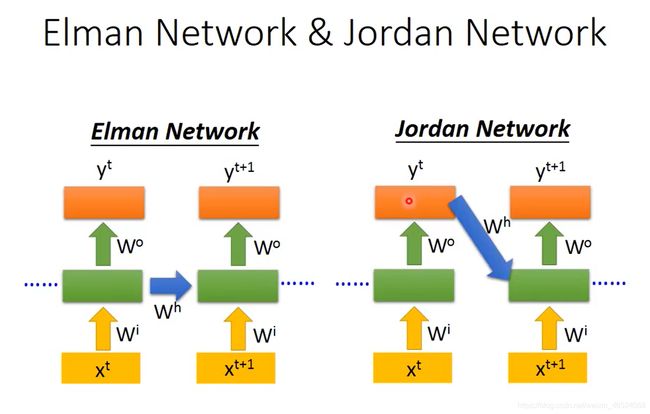
从图片中可以看到,Jorton Network存的是output,所以要准确率更高一点。
Bidirectional RNN
双向RNN,通过正向和逆向的output产生yt,范围就要较广一些
Long Short-term Memory (LSTM)
通过input-gate来写入memory cell,输出的地方有out-gate来决定是否读出值。通过network自己学习。同时还有forget-gate来让network自己学到是否要忘记信号。

Graph Neural Network
GNN可以用在classification和generation
通过相邻的labeled data来学习预测unlabeled data
GNN Roadmap
convolution(卷积)一共分为两种,一种是spatial-based(基于空间的),一种是spectral-based(基于光谱的),在这里简要介绍一下GAT和GCN两种model
spatial-based convolutional neural network
spectral gragh theory
讲的太无聊了我去…我跳过了,下次回来补