Prometheus监控kubernetes
Prometheus监控kubernetes
咱们的目标通过Prometheus监控Kubernetes集群。
1.使用ConfigMaps管理Prometheus的配置文件
创建prometheus-config.yml文件,并写入以下内容
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
data:
prometheus.yml: |
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
使用kubectl命令行工具,在命名空间default创建ConfigMap资源:
kubectl create -f prometheus-config.yml
configmap "prometheus-config" created
2.使用Deployment部署Prometheus
当ConfigMap资源创建成功后,我们就可以通过Volume挂载的方式,将Prometheus的配置文件挂载到容器中。 这里我们通过Deployment部署Prometheus Server实例,创建prometheus-deployment.yml文件,并写入以下内容:
apiVersion: v1
kind: "Service"
metadata:
name: prometheus
labels:
name: prometheus
spec:
ports:
- name: prometheus
protocol: TCP
port: 9090
targetPort: 9090
selector:
app: prometheus
type: NodePort
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
name: prometheus
name: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
containers:
- name: prometheus
image: prom/prometheus:v2.2.1
command:
- "/bin/prometheus"
args:
- "--config.file=/etc/prometheus/prometheus.yml"
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: "/etc/prometheus"
name: prometheus-config
volumes:
- name: prometheus-config
configMap:
name: prometheus-config
该文件中分别定义了Service和Deployment,Service类型为NodePort,这样我们可以通过虚拟机IP和端口访问到Prometheus实例。为了能够让Prometheus实例使用ConfigMap中管理的配置文件,这里通过volumes声明了一个磁盘卷。并且通过volumeMounts将该磁盘卷挂载到了Prometheus实例的/etc/prometheus目录下。
使用以下命令创建资源,并查看资源的创建情况:
[root@master-1 prometheus]# kubectl create -f prometheus-deployment.yml
service "prometheus" created
deployment "prometheus" created
[root@master-1 prometheus]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deploy-fb74b55d4-gz6cz 1/1 Running 2 (2d3h ago) 3d
prometheus-b487b9dfc-n74nv 1/1 Running 0 2d1h
[root@master-1 prometheus]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 3d1h
nginx-svc NodePort 10.104.88.55 80:30523/TCP 3d
prometheus NodePort 10.100.208.234 9090:32053/TCP 2d2h
我们可以通过worker虚拟机的IP地址和端口32053访问http://192.168.5.21:32053到Prometheus的服务。
但是这里只有Prometheus 9000的监控。接下来,我们配置Prometheus的config 和 rbac开始监控k8s.
3.kubernetes的服务发现
3.1kubernetes的访问授权
为了能够让Prometheus能够访问收到认证保护的Kubernetes API,我们首先需要做的是,对Prometheus进行访问授权。在Kubernetes中主要使用基于角色的访问控制模型(Role-Based Access Control),用于管理Kubernetes下资源访问权限。首先我们需要在Kubernetes下定义角色(ClusterRole),并且为该角色赋予相应的访问权限。同时创建Prometheus所使用的账号(ServiceAccount),最后则是将该账号与角色进行绑定(ClusterRoleBinding)。这些所有的操作在Kubernetes同样被视为是一系列的资源,可以通过YAML文件进行描述并创建,这里创建prometheus-rbac-setup.yml文件,并写入以下内容:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: default
其中需要注意的是ClusterRole是全局的,不需要指定命名空间。而ServiceAccount是属于特定命名空间的资源。通过kubectl命令创建RBAC对应的各个资源:
$ kubectl create -f prometheus-rbac-setup.yml
clusterrole "prometheus" created
serviceaccount "prometheus" created
clusterrolebinding "prometheus" created
在完成角色权限以及用户的绑定之后,就可以指定Prometheus使用特定的ServiceAccount创建Pod实例。修改prometheus-deployment.yml文件,并添加serviceAccountName和serviceAccount定义:
apiVersion: v1
kind: "Service"
metadata:
name: prometheus
labels:
name: prometheus
spec:
ports:
- name: prometheus
protocol: TCP
port: 9090
targetPort: 9090
selector:
app: prometheus
type: NodePort
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
name: prometheus
name: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
serviceAccountName: prometheus # 添加ServiceAccountName
containers:
- name: prometheus
image: prom/prometheus:v2.2.1
command:
- "/bin/prometheus"
args:
- "--config.file=/etc/prometheus/prometheus.yml"
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: "/etc/prometheus"
name: prometheus-config
volumes:
- name: prometheus-config
configMap:
name: prometheus-config
通过kubectl apply对Deployment进行变更升级:
$ kubectl apply -f prometheus-deployment.yml
service "prometheus" configured
deployment "prometheus" configured
[root@master-1 prometheus]# kubectl get pod
NAME READY STATUS RESTARTS AGE
prometheus-b487b9dfc-n73dv 0/1 Terminating 0 3d
prometheus-b487b9dfc-n74nv 1/1 Running 0 2d1h
指定ServiceAccount创建的Pod实例中,会自动将用于访问Kubernetes API的CA证书以及当前账户对应的访问令牌文件挂载到Pod实例的/var/run/secrets/kubernetes.io/serviceaccount/目录下,可以通过以下命令进行查看:
[root@master-1 prometheus]# kubectl exec -it prometheus-b487b9dfc-n74nv -- ls /var/run/secrets/kubernetes.io/serviceaccount/
ca.crt namespace token
3.2服务发现
在Kubernetes下,Promethues通过与Kubernetes API集成目前主要支持5种服务发现模式,分别是:Node、Service、Pod、Endpoints、Ingress。
通过kubectl命令行,可以方便的获取到当前集群中的所有节点信息:
[root@master-1 prometheus]# kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
master-1 Ready control-plane,master 3d1h v1.22.1 192.168.5.11 CentOS Linux 7 (Core) 3.10.0-1160.49.1.el7.x86_64 docker://20.10.12
master-2 Ready control-plane,master 3d1h v1.22.1 192.168.5.12 CentOS Linux 7 (Core) 3.10.0-1160.49.1.el7.x86_64 docker://20.10.12
master-3 Ready control-plane,master 3d1h v1.22.1 192.168.5.13 CentOS Linux 7 (Core) 3.10.0-1160.49.1.el7.x86_64 docker://20.10.12
worker-1 Ready 3d1h v1.22.1 192.168.5.21 CentOS Linux 7 (Core) 3.10.0-1160.49.1.el7.x86_64 docker://20.10.12
为了能够让Prometheus能够获取到当前集群中所有节点的信息,在Promtheus的配置文件中,我们添加如下Job配置:
- job_name: 'kubernetes-nodes'
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
通过指定kubernetes_sd_config的模式为node,Prometheus会自动从Kubernetes中发现到所有的node节点并作为当前Job监控的Target实例。如下所示,这里需要指定用于访问Kubernetes API的ca以及token文件路径。
对于Ingress,Service,Endpoints, Pod的使用方式也是类似的,下面给出了一个完整Prometheus配置的示例:
apiVersion: v1
data:
prometheus.yml: |-
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'kubernetes-nodes'
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
- job_name: 'kubernetes-service'
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: service
- job_name: 'kubernetes-endpoints'
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: endpoints
- job_name: 'kubernetes-ingress'
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: ingress
- job_name: 'kubernetes-pods'
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: pod
kind: ConfigMap
metadata:
name: prometheus-config
更新Prometheus配置文件,并重建Prometheus实例:
$ kubectl apply -f prometheus-config.yml
configmap "prometheus-config" configured
[root@master-1 prometheus]# kubectl get pod
NAME READY STATUS RESTARTS AGE
prometheus-b487b9dfc-n74nv 1/1 Running 0 2d1h
[root@master-1 prometheus]# kubectl delete pod prometheus-b487b9dfc-n74nv
pod "prometheus-b487b9dfc-n74nv" deleted
[root@master-1 prometheus]# kubectl get pod
NAME READY STATUS RESTARTS AGE
prometheus-b487b9dfc-s2rrr 1/1 Running 0 5s
Prometheus使用新的配置文件重建之后,打开Prometheus UI,通过Service Discovery页面可以查看到当前Prometheus通过Kubernetes发现的所有资源对象了:
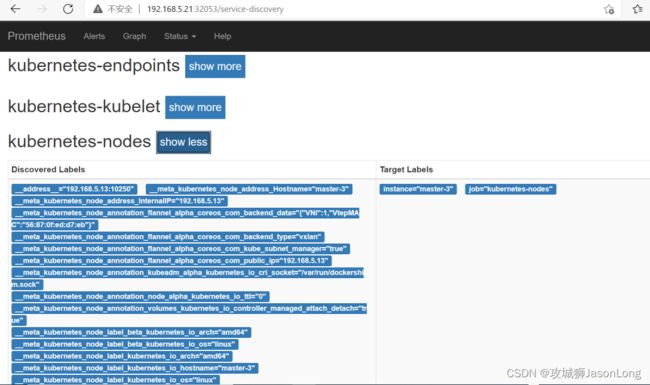
同时Prometheus会自动将该资源的所有信息,并通过标签的形式体现在Target对象上。如下所示,是Promthues获取到的Node节点的标签信息:
__address__="192.168.5.13:10250" __meta_kubernetes_node_address_Hostname="master-3" __meta_kubernetes_node_address_InternalIP="192.168.5.13" __meta_kubernetes_node_annotation_flannel_alpha_coreos_com_backend_data="{"VNI":1,"VtepMAC":"56:87:0f:ed:d7:eb"}" __meta_kubernetes_node_annotation_flannel_alpha_coreos_com_backend_type="vxlan" __meta_kubernetes_node_annotation_flannel_alpha_coreos_com_kube_subnet_manager="true" __meta_kubernetes_node_annotation_flannel_alpha_coreos_com_public_ip="192.168.5.13" __meta_kubernetes_node_annotation_kubeadm_alpha_kubernetes_io_cri_socket="/var/run/dockershim.sock" __meta_kubernetes_node_annotation_node_alpha_kubernetes_io_ttl="0" __meta_kubernetes_node_annotation_volumes_kubernetes_io_controller_managed_attach_detach="true" __meta_kubernetes_node_label_beta_kubernetes_io_arch="amd64" __meta_kubernetes_node_label_beta_kubernetes_io_os="linux" __meta_kubernetes_node_label_kubernetes_io_arch="amd64" __meta_kubernetes_node_label_kubernetes_io_hostname="master-3" __meta_kubernetes_node_label_kubernetes_io_os="linux" __meta_kubernetes_node_label_node_kubernetes_io_exclude_from_external_load_balancers="" __meta_kubernetes_node_label_node_role_kubernetes_io_control_plane="" __meta_kubernetes_node_label_node_role_kubernetes_io_master="" __meta_kubernetes_node_name="master-3" __metrics_path__="/metrics" __scheme__="http" instance="master-3" job="kubernetes-nodes"
目前为止,我们已经能够通过Prometheus自动发现Kubernetes集群中的各类资源以及其基本信息。不过,如果现在查看Promtheus的Target状态页面,结果可能会让人不太满意:
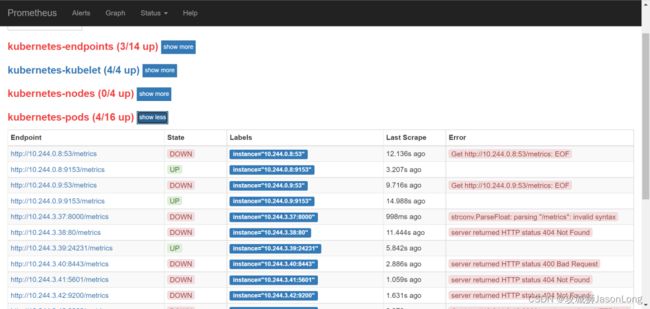
虽然Prometheus能够自动发现所有的资源对象,并且将其作为Target对象进行数据采集。 但并不是所有的资源对象都是支持Promethues的,并且不同类型资源对象的采集方式可能是不同的。因此,在实际的操作中,我们需要有明确的监控目标,并且针对不同类型的监控目标设置不同的数据采集方式。
接下来,我们将利用Promtheus的服务发现能力,实现对Kubernetes集群的全面监控。
4.监控kubernetes集群
我们介绍了Promtheus在Kubernetes下的服务发现能力,并且通过kubernetes_sd_config实现了对Kubernetes下各类资源的自动发现。在本小节中,我们将带领读者利用Promethues提供的服务发现能力,实现对Kubernetes集群以及其中部署的各类资源的自动化监控。
下表中,梳理了监控Kubernetes集群监控的各个维度以及策略:
| 目标 | 服务发现模式 | 监控方法 | 数据源 |
|---|---|---|---|
| 从集群各节点kubelet组件中获取节点kubelet的基本运行状态的监控指标 | node | 白盒监控 | kubelet |
| 从集群各节点kubelet内置的cAdvisor中获取,节点中运行的容器的监控指标 | node | 白盒监控 | kubelet |
| 从部署到各个节点的Node Exporter中采集主机资源相关的运行资源 | node | 白盒监控 | node exporter |
| 对于内置了Promthues支持的应用,需要从Pod实例中采集其自定义监控指标 | pod | 白盒监控 | custom pod |
| 获取API Server组件的访问地址,并从中获取Kubernetes集群相关的运行监控指标 | endpoints | 白盒监控 | api server |
| 获取集群中Service的访问地址,并通过Blackbox Exporter获取网络探测指标 | service | 黑盒监控 | blackbox exporter |
| 获取集群中Ingress的访问信息,并通过Blackbox Exporter获取网络探测指标 | ingress | 黑盒监控 | blackbox exporter |
4.1从Kubelet获取节点运行状态
Kubelet组件运行在Kubernetes集群的各个节点中,其负责维护和管理节点上Pod的运行状态。kubelet组件的正常运行直接关系到该节点是否能够正常的被Kubernetes集群正常使用。
基于Node模式,Prometheus会自动发现Kubernetes中所有Node节点的信息并作为监控的目标Target。 而这些Target的访问地址实际上就是Kubelet的访问地址,并且Kubelet实际上直接内置了对Promtheus的支持。
修改prometheus.yml配置文件,并添加以下采集任务配置:
- job_name: 'kubernetes-kubelet'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
这里使用Node模式自动发现集群中所有Kubelet作为监控的数据采集目标,同时通过labelmap步骤,将Node节点上的标签,作为样本的标签保存到时间序列当中。
重新加载promethues配置文件,并重建Promthues的Pod实例后,查看kubernetes-kubelet任务采集状态,我们会看到以下错误提示信息:
Get https://192.168.99.100:10250/metrics: x509: cannot validate certificate for 192.168.99.100 because it doesn't contain any IP SANs
这是由于当前使用的ca证书中,并不包含192.168.99.100的地址信息。为了解决该问题,第一种方法是直接跳过ca证书校验过程,通过在tls_config中设置 insecure_skip_verify为true即可。 这样Promthues在采集样本数据时,将会自动跳过ca证书的校验过程,从而从kubelet采集到监控数据:
- job_name: 'kubernetes-kubelet'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
第二种方式,不直接通过kubelet的metrics服务采集监控数据,而通过Kubernetes的api-server提供的代理API访问各个节点中kubelet的metrics服务,如下所示:
- job_name: 'kubernetes-kubelet'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics
通过relabeling,将从Kubernetes获取到的默认地址__address__替换为kubernetes.default.svc:443。同时将__metrics_path__替换为api-server的代理地址/api/v1/nodes/${1}/proxy/metrics。
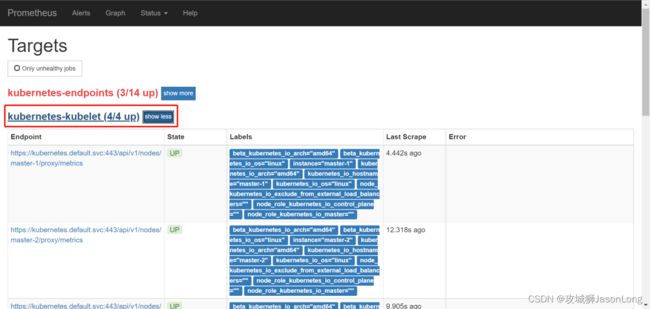
通过获取各个节点中kubelet的监控指标,用户可以评估集群中各节点的性能表现。例如,通过指标kubelet_pod_start_duration_seconds_count可以获得当前节点中Pod启动的数量。

4.2从Kubelet获取节点容器资源使用情况
各节点的kubelet组件中除了包含自身的监控指标信息以外,kubelet组件还内置了对cAdvisor的支持。cAdvisor能够获取当前节点上运行的所有容器的资源使用情况,通过访问kubelet的/metrics/cadvisor地址可以获取到cadvisor的监控指标,因此和获取kubelet监控指标类似,这里同样通过node模式自动发现所有的kubelet信息,并通过适当的relabel过程,修改监控采集任务的配置。 与采集kubelet自身监控指标相似,这里也有两种方式采集cadvisor中的监控指标:
方式一:直接访问kubelet的/metrics/cadvisor地址,需要跳过ca证书认证:
- job_name: 'kubernetes-cadvisor'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: metrics/cadvisor
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
方式二:通过api-server提供的代理地址访问kubelet的/metrics/cadvisor地址:
- job_name: 'kubernetes-cadvisor'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
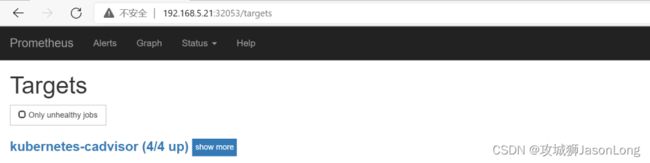
4.3使用NodeExporter监控集群资源使用情况
为了能够采集集群中各个节点的资源使用情况,我们需要在各节点中部署一个Node Exporter实例。在本章的“部署Prometheus”小节,我们使用了Kubernetes内置的控制器之一Deployment。Deployment能够确保Prometheus的Pod能够按照预期的状态在集群中运行,而Pod实例可能随机运行在任意节点上。而与Prometheus的部署不同的是,对于Node Exporter而言每个节点只需要运行一个唯一的实例,此时,就需要使用Kubernetes的另外一种控制器Daemonset。顾名思义,Daemonset的管理方式类似于操作系统中的守护进程。Daemonset会确保在集群中所有(也可以指定)节点上运行一个唯一的Pod实例。
创建node-exporter-daemonset.yml文件,并写入以下内容:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '9100'
prometheus.io/path: 'metrics'
labels:
app: node-exporter
name: node-exporter
spec:
containers:
- image: prom/node-exporter
imagePullPolicy: IfNotPresent
name: node-exporter
ports:
- containerPort: 9100
hostPort: 9100
name: scrape
hostNetwork: true
hostPID: true
由于Node Exporter需要能够访问宿主机,因此这里指定了hostNetwork和hostPID,让Pod实例能够以主机网络以及系统进程的形式运行。同时YAML文件中也创建了NodeExporter相应的Service。这样通过Service就可以访问到对应的NodeExporter实例。
[root@master-1 prometheus]# kubectl create -f node-exporter-daemonset.yml
daemonset.apps/node-exporter created
查看Daemonset以及Pod的运行状态
[root@master-1 prometheus]# kubectl get daemonsets
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
node-exporter 1 1 1 1 1 <none> 74s
[root@master-1 prometheus]# kubectl get pods
NAME READY STATUS RESTARTS AGE
node-exporter-brh9d 1/1 Running 0 79s
prometheus-b487b9dfc-4xf65 1/1 Running 0 9m28s
由于Node Exporter是以主机网络的形式运行,因此直接访问MiniKube的虚拟机IP加上Pod的端口即可访问当前节点上运行的Node Exporter实例:
[root@master-1 ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-exporter-brh9d 1/1 Running 0 104m 192.168.5.21 worker-1
prometheus-b487b9dfc-4xf65 1/1 Running 0 113m 10.244.3.50 worker-1
[root@master-1 ~]# curl http://192.168.5.21:9100/metrics
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 3.3862e-05
go_gc_duration_seconds{quantile="0.25"} 4.1737e-05
go_gc_duration_seconds{quantile="0.5"} 4.5937e-05
go_gc_duration_seconds{quantile="0.75"} 5.1647e-05
go_gc_duration_seconds{quantile="1"} 0.003094938
go_gc_duration_seconds_sum 0.020962164
go_gc_duration_seconds_count 353
目前为止,通过Daemonset的形式将Node Exporter部署到了集群中的各个节点中。接下来,我们只需要通过Prometheus的pod服务发现模式,找到当前集群中部署的Node Exporter实例即可。 需要注意的是,由于Kubernetes中并非所有的Pod都提供了对Prometheus的支持,有些可能只是一些简单的用户应用,为了区分哪些Pod实例是可以供Prometheus进行采集的,这里我们为Node Exporter添加了注解:
prometheus.io/scrape: 'true'
由于Kubernetes中Pod可能会包含多个容器,还需要用户通过注解指定用户提供监控指标的采集端口:
prometheus.io/port: '9100'
而有些情况下,Pod中的容器可能并没有使用默认的/metrics作为监控采集路径,因此还需要支持用户指定采集路径:
prometheus.io/path: 'metrics'
为Prometheus创建监控采集任务kubernetes-pods,如下所示:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
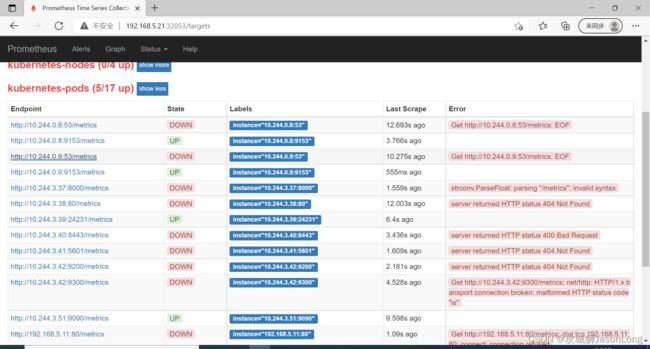
通过以上relabel过程实现对Pod实例的过滤,以及采集任务地址替换,从而实现对特定Pod实例监控指标的采集。需要说明的是kubernetes-pods并不是只针对Node Exporter而言,对于用户任意部署的Pod实例,只要其提供了对Prometheus的支持,用户都可以通过为Pod添加注解的形式为其添加监控指标采集的支持。
4.4从kube-apiserver获取集群运行监控指标
在开始正式内容之前,我们需要先了解一下Kubernetes中Service是如何实现负载均衡的,如下图所示,一般来说Service有两个主要的使用场景:
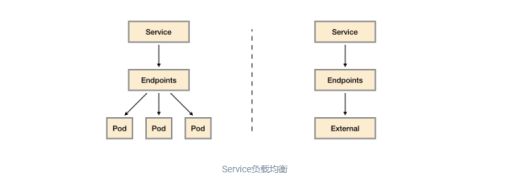
代理对集群内部应用Pod实例的请求:当创建Service时如果指定了标签选择器,Kubernetes会监听集群中所有的Pod变化情况,通过Endpoints自动维护满足标签选择器的Pod实例的访问信息;
代理对集群外部服务的请求:当创建Service时如果不指定任何的标签选择器,此时需要用户手动创建Service对应的Endpoint资源。例如,一般来说,为了确保数据的安全,我们通常讲数据库服务部署到集群外。 这是为了避免集群内的应用硬编码数据库的访问信息,这是就可以通过在集群内创建Service,并指向外部的数据库服务实例。
kube-apiserver扮演了整个Kubernetes集群管理的入口的角色,负责对外暴露Kubernetes API。kube-apiserver组件一般是独立部署在集群外的,为了能够让部署在集群内的应用(kubernetes插件或者用户应用)能够与kube-apiserver交互,Kubernetes会默认在命名空间下创建一个名为kubernetes的服务,如下所示:
[root@master-1 prometheus]# kubectl get svc kubernetes -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 3d4h <none>
而该kubernetes服务代理的后端实际地址通过endpoints进行维护,如下所示:
[root@master-1 prometheus]# kubectl get endpoints kubernetes
NAME ENDPOINTS AGE
kubernetes 192.168.5.11:6443,192.168.5.12:6443,192.168.5.13:6443 3d4h
通过这种方式集群内的应用或者系统主机就可以通过集群内部的DNS域名kubernetes.default.svc访问到部署外部的kube-apiserver实例。
因此,如果我们想要监控kube-apiserver相关的指标,只需要通过endpoints资源找到kubernetes对应的所有后端地址即可。
如下所示,创建监控任务kubernetes-apiservers,这里指定了服务发现模式为endpoints。Promtheus会查找当前集群中所有的endpoints配置,并通过relabel进行判断是否为apiserver对应的访问地址:
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- target_label: __address__
replacement: kubernetes.default.svc:443
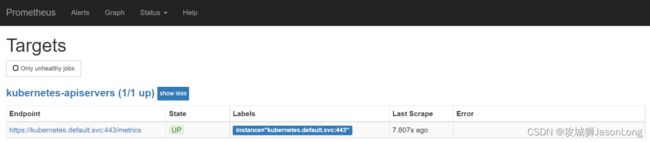
在relabel_configs配置中第一步用于判断当前endpoints是否为kube-apiserver对用的地址。第二步,替换监控采集地址到kubernetes.default.svc:443即可。重新加载配置文件,重建Promthues实例,得到以下结果。
5.Kubernetes 中部署 Grafana
grafana 是一个可视化面板,有着非常漂亮的图表和布局展示,功能齐全的度量仪表盘和图形编辑器,支持 Graphite、zabbix、InfluxDB、Prometheus、OpenTSDB、Elasticsearch 等作为数据源,比 Prometheus 自带的图表展示功能强大太多,更加灵活,有丰富的插件,功能更加强大。
通过Deployment部署grafana 创建grafana-deployment-5.0.0.yml文件,并写入以下内容:
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana-core
labels:
app: grafana
component: core
spec:
replicas: 1
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
containers:
- image: grafana/grafana:5.0.0
name: grafana-core
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
env:
- name: GF_AUTH_BASIC_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "false"
readinessProbe:
httpGet:
path: /login
port: 3000
volumeMounts:
- name: grafana-persistent-storage
mountPath: /var
volumes:
- name: grafana-persistent-storage
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
name: grafana
labels:
app: grafana
spec:
type: NodePort
ports:
- port: 3000
selector:
app: grafana
部署grafana
[root@master-1 prometheus]# kubectl apply -f grafana-deployment-5.0.0.yml
deployment.apps/grafana-core created
注意:
如果是用的grafana 5.0.0以上版本, 会报错
GF_PATHS_DATA='/var/lib/grafana' is not writable.
You may have issues with file permissions, more information here: http://docs.grafana.org/installation/docker/#migration-from-a-previous-version-of-the-docker-container-to-5-1-or-later
mkdir: cannot create directory '/var/lib/grafana/plugins': No such file or directory
解决办法:
securityContext:
fsGroup: 472
runAsUser: 472
完整的grafana-deployment-5.3.4.yml文件如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: kube-ops
labels:
app: grafana
spec:
revisionHistoryLimit: 10
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
containers:
- name: grafana
image: grafana/grafana:5.3.4
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
name: grafana
env:
- name: GF_SECURITY_ADMIN_USER
value: admin
- name: GF_SECURITY_ADMIN_PASSWORD
value: admin321
readinessProbe:
failureThreshold: 10
httpGet:
path: /api/health
port: 3000
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 30
livenessProbe:
failureThreshold: 3
httpGet:
path: /api/health
port: 3000
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources:
limits:
cpu: 100m
memory: 256Mi
requests:
cpu: 100m
memory: 256Mi
volumeMounts:
- mountPath: /var/lib/grafana
subPath: grafana
name: storage
securityContext:
fsGroup: 472
runAsUser: 472
volumes:
- name: storage
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
name: grafana
labels:
app: grafana
spec:
type: NodePort
ports:
- port: 3000
selector:
app: grafana
查看pod svc 状态
[root@master-1 prometheus]# kubectl get pod,svc
NAME READY STATUS RESTARTS AGE
pod/grafana-569d774b85-8244q 1/1 Running 0 7m20s
pod/node-exporter-brh9d 1/1 Running 0 21h
pod/prometheus-b487b9dfc-gvkd4 1/1 Running 0 17h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/blackbox-exporter ClusterIP 10.106.168.178 9115/TCP 18h
service/grafana NodePort 10.100.91.140 3000:30674/TCP 7m20s
service/kubernetes ClusterIP 10.96.0.1 443/TCP 3d23h
service/nginx-svc NodePort 10.104.88.55 80:30523/TCP 3d23h
service/prometheus NodePort 10.100.208.234 9090:32053/TCP 3d
这里,grafana的部署就完成了,接下来我们访问grafana并配置Prometheus数据源。
Grafana配置
访问grafana所在节点的的地址 http://192.168.5.21:30674/
grafana 默认用户名 admin 密码 admin
如果是grafana-deployment-5.3.4.yml生成的, 密码是 admin321
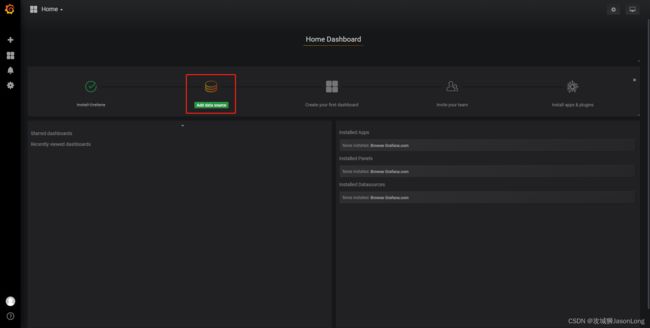
添加数据源
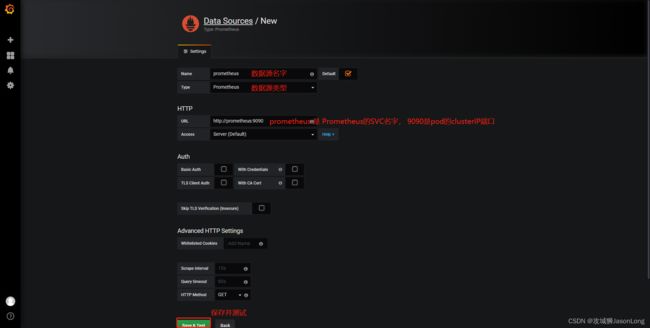
显示下面截图,说明数据源可用。
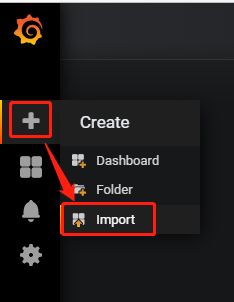
导入模板
grafana 的官方网站https://grafana.com/grafana/dashboards/上还有很多公共的 Dashboard 可以供我们使用,我们这里可以使用Kubernetes cluster monitoring (via Prometheus)(dashboard id 为162)这个 Dashboard 来展示 Kubernetes 集群的监控信息。

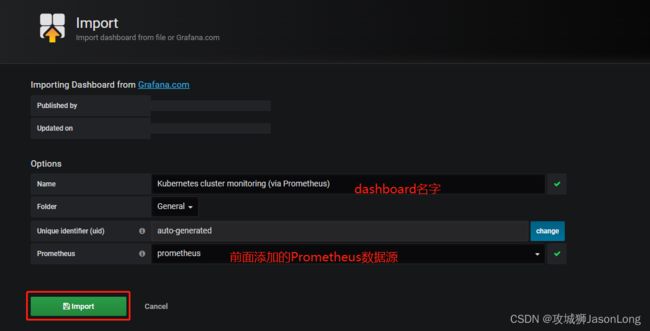
就会显示下面的界面,表示grafana配置成功。

仔细看看,这个dashboard是监控pod的,发现pod的数据有,但是cluster的数据没有。这时候我们就需要去检查一下https://grafana.com/grafana/dashboards/162 相关的配置是不是有漏掉的。
经过对grafana模板的监控字段进行修改,dashboard已经是下面这个样子
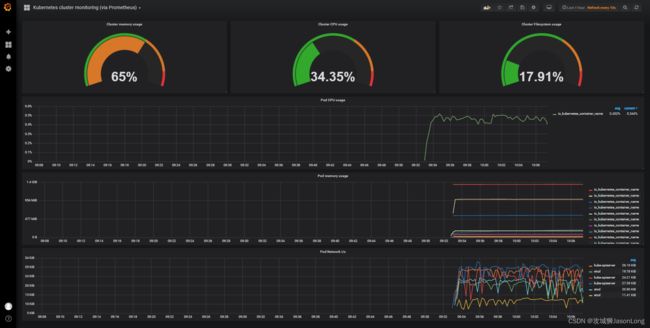
比如,cluster memory usage 点击edit, 修改metrics 为
(sum(node_memory_MemTotal_bytes) - sum(node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes) ) / sum(node_memory_MemTotal_bytes) * 100
然后点击Save,可以添加备注。
cluster_cpu_usage改为
sum(sum by (name)( rate(container_cpu_usage_seconds_total{image!=""}[1m] ) )) / count(node_cpu_seconds_total{mode=“system”}) * 100
cluster_file_system改为
(sum(node_filesystem_size_bytes{device="/dev/mapper/centos_centos7-root"}) - sum(node_filesystem_free_bytes{device="/dev/mapper/centos_centos7-root"}) ) / sum(node_filesystem_size_bytes{device="/dev/mapper/centos_centos7-root"}) * 100
其中{device=“xxx”}过滤条件,根据os的FS类型来决定。
附录:
我已将需要的yml文件上传至GitHub ,有需要的可以直接下载。
https://github.com/JasonYLong/prometheus-on-kubernetes.git
参考该文章,我只是做了新版本的修改,并加上了grafana的部分。
https://yunlzheng.gitbook.io/prometheus-book/part-iii-prometheus-shi-zhan/readmd