Raft or not? 为什么 Consensus-based replication 不是分布式数据库日志复制的银弹?
背景
近期在跟团队同学聊天的过程中,听到了这样一句观点:
“我们团队目前的技术路线是不是错了?基于 Kafka/Pulsar 在做日志存储, 感觉更像是在做中间件,而不是在做数据库!”
我在和很多朋友讨论的过程中,发现大家对于 Consistency、Consensus、Replication 这些基本概念存在很多误解,也有很多人认为只有基于 Paxos/Raft 这类分布式一致性算法的日志复制才是分布式数据库的唯一正解。
要说清楚这个问题,首先要梳理清楚下面的几个基本概念。
Replication
Replication 指的是将数据拷贝到多个位置的过程(不同磁盘、进程、机器、集群),这一过程通常起到两个作用
- 提升数据的可靠性 - 解决坏盘,物理机故障,集群异常时的故障恢复问题
- 加速查询 - 多副本可以同时使用来提高性能
Replication 的分类有很多,先明确一点,我们今天讨论的是增量日志的同步方式,而非全量数据的拷贝。
除此之外,常见的 Replication 区分方式还有:同步/异步,强一致/最终一致,基于主从/去中心化等等。
Replication 模式的选择会影响系统的可用性和一致性,因此才有人提出了著名的 CAP 理论,在网络隔离无法避免的情况下,系统设计者必须在一致性和可用性之间进行权衡。
Consistency
简单理解一致性,就是同一时间下对于多副本进行读写是否可以得到一致的数据。
首先明确这里我们讨论的是 CAP 中的 “C”,而不是 ACID 中的 “C”。对于一致性级别的描述,我认为这篇 CosmosDB 的文档是最为靠谱的 https://docs.microsoft.com/en... (不得不承认 Azure 的产品文档要强过 AWS 不少,且有着满满的学院风)
通常 OLTP 数据库会要求强一致性,或者说线性一致性,即:
- 任何一次读都能读到某个数据的最近一次写入。
- 任何一个读取返回新值后,所有后续读取(在相同或其它客户端上)也必须返回新值。
线性一致的本质是数据多副本之间新鲜度的保证(recency guarantee),它保证了一旦新的值被写入或读取,后续所有的读都会看到写入的值,直到它被再次覆盖。这也就意味着提供线性一致保证的分布式系统,用户可以不用关心多副本的实现,每个操作都可以实现原子有序。
Consensus
人们希望像使用单机系统一样使用分布式系统,因此不可避免地引入了“分布式共识”问题。
简单来说,就是当一个进程提议某一个值是什么之后,系统中所有的进程对这个值的变化能够达成一致,下图就是一个达成一致的过程。

最早的共识算法来源于 1988 年发表的 Viewstamped Replication 和 1989 年 Leslie 老爷子提出的 Paxos 算法。
近年来 Raft 算法也因为其相对而言比较容易实现,而在业界有了大量应用(比如在主流的 NewSQL 中:CockRoachDB、TiDB、Oceanbase 几乎都是基于 Raft 和 Paxos 实现的)
事实上,共识算法还有另外一类,也就是 leaderless consensus protocol。
这类算法被广泛的运用在区块链中,比如比特币所采用的 PoW 算法。这类算法由于效率问题,较少被应用于并发量较高的数据库系统中。
值得注意的是,即使采用了分布式共识算法,也并不意味着系统就能够支持线性一致性。
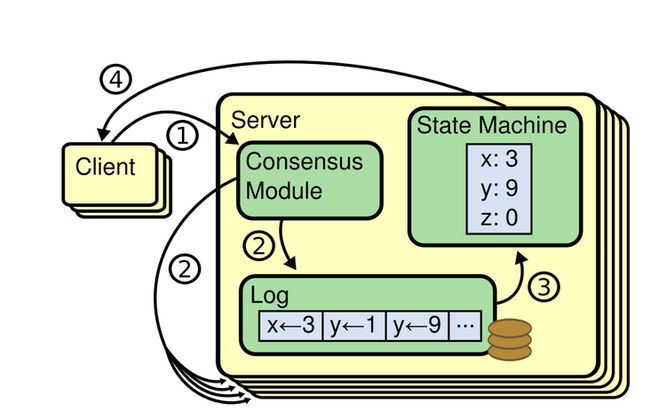
当我们在设计一个系统的时候,需要仔细考虑日志与状态机器的 commit 顺序问题,以及谨慎地维护 Raft/Paxos leader 的 lease,避免在网络隔离的情况下出现脑裂。
Milvus 的可调一致性(Tunable Consistency)实际上非常类似于分布式共识算法中的 Follower Read 实现。Follower Read 指的在强一致性读的前提下使用 follower 副本来承载数据读取的任务,从而提升集群的吞吐能力并降低 leader 负载。其实现方式是:询问主节点最新的日志 commit index ,等待该 commit index 所有的数据顺利 apply 到状态机上,再提供查询服务。
我们在 Milvus 的设计过程中,并未采取每次查询都询问生产者 commit index 的策略,而是通过类似于 Flink 中 watermark 的机制定期通知查询执行节点 commit index 的位置。这种设计,主要是因为 Milvus 用户对数据一致性要求并不高,通常情况下可以接受降低数据的可见性换取更高的性能,所以不需要每次查询都确定 commit index 的位置。
为什么 Consensus-based replication 会如此流行
简单来说,就是人们喜欢线性一致性(Linearizability)。
无论是 Raft、ZAB,还是 Aurora 基于 Quorum 的日志协议,其实在某种程度上都是 Paxos 算法的变种之一。而线性一致性往往是实现分布式数据库 ACID 的基础,这让这种技术在事务型数据库中具备了很强的不可替代性。
Consensused-based replication 之所以如此流行,还有以下三个原因:
第一点是相比于传统主从复制,尽管 Consensus-based replication 在 CAP 理论中更偏重 “CP”,但其依然提供了不错的 Availability,通常情况下进程崩溃,服务器重启都可以在秒级恢复。
第二点是 Raft 的提出极大地简化了 Consensus 算法的实现复杂度,越来越多的数据库选择了自己写 Raft 算法,或者改造目前的 Raft 实现。据不完全统计,Github 上超过 1000 stars 的 Raft 实现就已超过 15 种,最知名的如 Etcd 提供的 Raft 库以及蚂蚁开源的 sofa-jraft,基于这些算法做二次改造的项目更是不计其数。在国内,随着 TiKV、Etcd 等开源产品的流行,越来越多的人关注到这一技术领域。
第三点是 Consensus-based replication 从性能上而言,确实能够满足现在的业务需求。尤其是高性能 SSD 和万兆网卡的推广,极大地降低了多副本同步的流量和落盘负担,使得 Paxos/Raft 算法的使用成为主流。
Consensus-based replication 有什么问题
讽刺的是,Consensus-based replication 并不是分布式系统解决一切的万能良药,恰巧因为可用性、复杂度、性能这些挑战,导致了它无法成为 replication 的唯一事实标准。
1)可用性
对比弱一致性系统,以及基于 Quorum 实现的分布式系统,Paxos/Raft 在进行优化之后往往对主副本有较强的依赖,导致其对抗 Grey Failure 的能力较弱。Consensus 重新选主的策略往往依赖于主节点长时间不响应,而这种策略并不能特别好地处理主节点慢或者抖的问题:实际生产中太多次遇到因为某些机器风扇坏掉、内存故障或者网卡频繁丢包导致的系统抖动问题。
2)复杂度
尽管已经有了很多的参考实现,做对 Consensus 算法并不是一件简单的事情,随着 Multi Raft、Parallel raft 之类的算法出现,日志和状态机之间的协同也需要更多的理论思考和测试验证。相反,我更加欣赏 PacificA、ISR 之类的 replication 协议,借助一个小的 Raft group 进行选主和 membership 管理,从而能够大幅降低设计复杂度。
3)性能成本
云原生时代,EBS 和 S3 等共享存储方案越来越多地替代了本地存储,数据可靠性和一致性已经可以得到很好的保证。基于分布式共识来实现数据多副本已经不再是刚性需求,且这种复制方式存在数据冗余放置的问题(基于 Consensus 本身需要多副本,EBS 自身又是多副本)。
对于跨机房/跨云的数据备份而言,过于追求一致性的代价除了牺牲可用性,也牺牲了请求延迟(参考:https://en.wikipedia.org/wiki... ),造成性能的大幅下降,因此在绝大多数业务场景下,线性一致性不会成为跨机房容灾的刚性需求。
云原生时代,究竟应该采用什么样的日志复制策略
聊了那么多 Consensus-based replication 的优势和劣势,到底什么才是云原生时代数据库应该采用的 Replication 策略呢?
不可否认,基于 raft 和 paxos 的算法依然会被很多 OLTP 数据库所采用,不过我们应该可以从 PacificA 协议、Socrates、Aurora、Rockset 中看出一些新的趋势。
在介绍具体的实现之前,先提出我总结出的两个原则:
1)Replication as a service
使用一个专门用于同步数据的微服务,而非将同步模块和存储模块紧耦合在一个进程里。
2)“套娃”
前面已经说了,避免 Single Point Failure,似乎逃不开 Paxos 的限制,但如果我们把问题缩小,把 leader election 交给 raft/paxos 实现(比如基于 chubby、zk、etcd 这类服务),那么 log replication 就可以大幅简化,性能成本的问题也迎刃而解!分享几个我很喜欢的设计方案。
第一个例子,我最喜欢的协议是微软的 PacificA,这篇文章的 paper 发布于 08 年,相比 paxos 的逻辑完备性,PacificA 更关注工程。当年我们在阿里云设计自研 Lindorm 数据库的强一致方案的时候,就发现我们的方案跟 PacificA 非常相似。
微软的 PacificA 的实现也非常简单,对于数据同步链路,primary 复制给 secondary 的时候等待所有的节点 ack 该请求后,才被认为是提交,因此线性一致性是非常容易保证的。
PacificA 的可用性保证更加简单,以 Zk、etcd 这一类系统来进行选主、或者完成成员变更操作。也就是说主挂了,lease 消失,备服务会申请替换为主将主节点退群。备挂了,primary 会申请让 secondary 退群。
第二个例子,我很欣赏的系统是 Socrates,不得不说微软产品确实很符合我个人的技术审美。
Socrates 的核心特点就是“解耦计算-日志-存储”。把日志和存储拆开,日志基于一个单独的服务来实现。
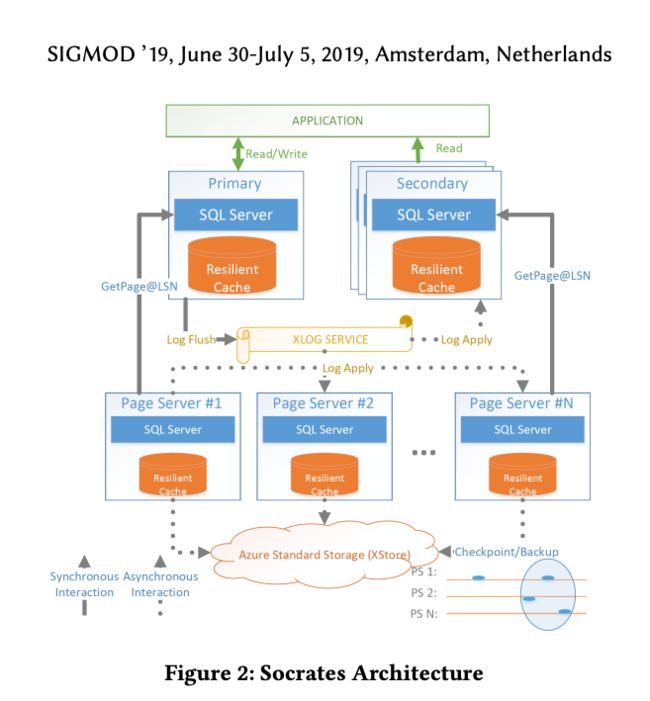
日志基于单独服务实现(XLog Service),利用低延迟存储实现持久化:在 Socrates 中用了一个组件叫 landing zone,做高速三副本持久化,虽然容量有限,只能做 circular buffer,但是很容易让我联想到 EMC 中用带电容的内存做数据持久化。
主节点会异步将日志分发给 log broker,并在 log broker 中完成数据落盘 Xstore(较低成本的数据存储),缓存在本地 SSD 进行加速读取,一旦数据落盘成功,LZ 中的 buffer 就可以被清理。这样一来,整个日志数据就分为了 LZ、本地 SSD 缓存和 Xstore 三层,近线数据充分利用热存储,可以更好地缓存提升故障恢复速度和提升 log tailing 的效率。
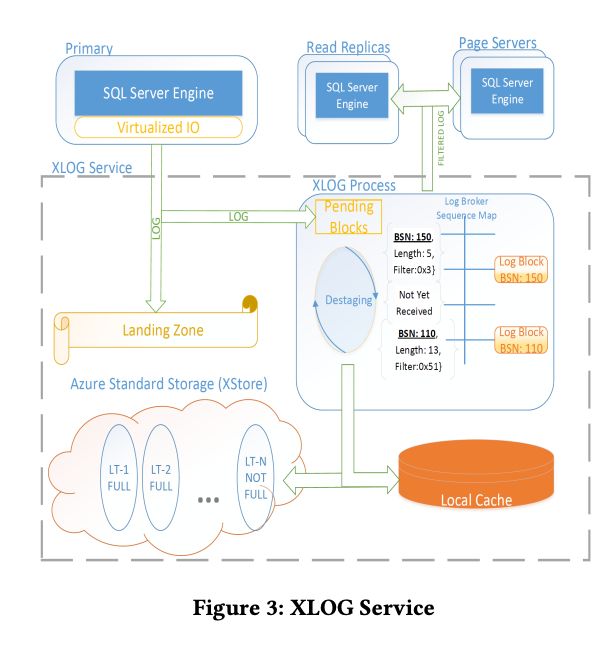
第三个例子,我认为比较值得一提的是 AWS Aurora,这款数据库几乎成为了云原生数据库的代名词。
首先 Aurora 也采用了非常典型的存储计算分离架构,存储层是一个针对 MySQL 的定制服务,负责 redo log、page 的持久化,完成 redo log 到 page 的转换。
Aurora 的强大之处在于使用 6 副本的 NWR 协议保证了写入的高可用性。相比于 DynamoDB 的 NWR,Aurora 由于只存在 single writer,可以产生递增的 log sequence numer,解决了传统 NWR 系统中最难规避的冲突仲裁问题。
事实上,通过 Single DB instance 和存储层 Quorum 的共同配合,其实是实现了一个类 Paxos 协议。Aurora paper 并未讨论上层 DB instance 的故障时如何判断,不过我的猜测是依然使用了依赖 Paxos、Raft、ZAB 协议的组件切换策略,组件在切换时可能会对下层的 storage 执行 lease recovery,保证不会同时出现双主发生脑裂(纯属个人猜测,欢迎纠正答疑)。
最后一个例子,有一个有意思的产品叫 Rockset,这是一家由 Facebook RocksDB 原团队设计的分析型产品。
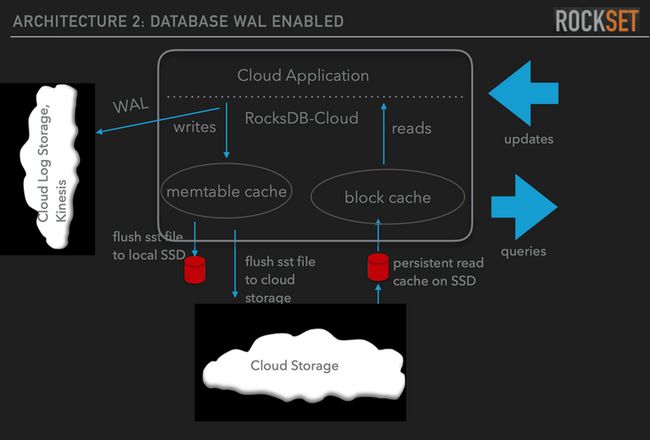
RocksDB Cloud架构
之后有机会可以单独聊聊 rockset 这款产品,在我看来它是 Snowflake 之外 OLAP 产品中云原生做的最好的。这里不得不提的是,他们像 Milvus 一样,直接使用了 Kafka/Kineses 作为分布式日志,使用 S3 作为存储,使用本地 SSD 作为缓存提升查询性能。更加有意思的是,Kafka 的数据复制协议 ISR 也跟 PacificA 有诸多类似之处,本质上也是一个“套娃”。做云原生服务,学会通过借力其他服务,降低系统实现复杂度已经是架构师的必修课。
总结
现在,越来越多的云数据库,把日志 replication 做成了单独的 service。这极大降低了添加只读副本/异构副本的成本,同时也更有利于日志存储服务的性能成本优化。微服务化的设计也可以快速复用一些成熟的云上基础设施,这对于传统紧耦合的数据库系统来说是不可想象的:这个独立的日志服务也许依赖了 Consensus-based replication,也可以采用“套娃”的策略,并且使用各种不同的一致性协议搭配 Paxos/Raft 来实现线性一致性。
最后,再分享一个例子。
很多年前,当我无意间听到了 Google Colossus 存储元信息的方式,不禁为它的设计拍案叫绝:Colossus 基于 GFS 存储所有的元信息,GFS 的数据存储在 Colossus 上,而 Colossus 中最原始的元信息因为已经足够小,可以直接存储在 Chubby 上。这不就是一个“天然的”基于 Paxos 的、类似 Zookeeper 的协调服务嘛。
无论技术如何进步发展,其外在形式如何转变,深入了解和思考“技术发展背后的事情”才是技术人更应该做的事情,也更符合第一性原理思维方式。
参考文献
- Lamport L. Paxos made simple[J]. ACM SIGACT News (Distributed Computing Column) 32, 4 (Whole Number 121, December 2001), 2001: 51-58.
- Ongaro D, Ousterhout J. In search of an understandable consensus algorithm[C]//2014 USENIX Annual Technical Conference (Usenix ATC 14). 2014: 305-319.
- Oki B M, Liskov B H. Viewstamped replication: A new primary copy method to support highly-available distributed systems[C]//Proceedings of the seventh annual ACM Symposium on Principles of distributed computing. 1988: 8-17.
- Lin W, Yang M, Zhang L, et al. PacificA: Replication in log-based distributed storage systems[J]. 2008.
- Verbitski A, Gupta A, Saha D, et al. Amazon aurora: On avoiding distributed consensus for i/os, commits, and membership changes[C]//Proceedings of the 2018 International Conference on Management of Data. 2018: 789-796.
- Antonopoulos P, Budovski A, Diaconu C, et al. Socrates: The new sql server in the cloud[C]//Proceedings of the 2019 International Conference on Management of Data. 2019: 1743-1756.
作者介绍
栾小凡
Zilliz 合伙人兼技术总监
Linux Foundation AI & Data 基金会技术咨询委员会成员。毕业于康奈尔大学计算机工程系,曾先后任职于 Oracle 美国总部、新一代软件定义存储公司 Hedvig、阿里云数据库团队。曾负责阿里云开源 HBase,带领团队完成自研 NoSQL 数据库 Lindorm 的研发工作。
Zilliz 以重新定义数据科学为愿景,致力于打造一家全球领先的开源技术创新公司,并通过开源和云原生解决方案为企业解锁非结构化数据的隐藏价值。
Zilliz 构建了 Milvus 向量数据库,以加快下一代数据平台的发展。Milvus 数据库是 LF AI & Data 基金会的毕业项目,能够管理大量非结构化数据集,在新药发现、推荐系统、聊天机器人等方面具有广泛的应用。