机器学习炼丹必看——找对方向
找到修炼的方向
- 引言
- 改进算法
-
- 评估方法(Evaluating a Hypothesis)
- 模型选择
- 诊断的偏差与方差 Bias vs. Variance
- 正则化和偏差、方差
- 学习曲线
- 总结
- 机器学习系统设计
-
- 误差分析
- 类偏斜的误差度量(Error for Skewed Classes )
- 大量数据的作用
引言
本文旨在帮助找到改善机器学习模型的方向。
机器学习的模型算法固然重要,但参数更加是影响模型准确性的重要因素。有些人可能没有完全理解怎样运用这些算法。因此总是把时间浪费在毫无意义的尝试上。
以此在设计机器学习的系统时,选择一条最合适、最正确的道路去尝试,可以节约很多时间,不会像乱飞的苍蝇一样。
改进算法
我们以线性回归为例:
m i n θ 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 + λ ∑ j = 1 n θ j 2 min_\theta\ \dfrac{1}{2m}\ \sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})^2 + \lambda\ \sum_{j=1}^n \theta_j^2 minθ 2m1 i=1∑m(hθ(x(i))−y(i))2+λ j=1∑nθj2
当我们运用训练好了的模型来预测未知数据的时候发现有较大的误差,我们下一步可以做什么?
- 获得更多的训练样本?通常是有效的,但代价较大
- 尝试更少的特征?
- 尝试增加特征?
- 尝试增加多项式( x 1 2 . . . x_1^2... x12...)的特征?
- 尝试增加正则化程度λ?
- 尝试减小λ?
我们不应该随机选择上面的某种方法来改进我们的算法,而是运用一些机器学习诊断法(Diagnostic)来帮助我们知道上面哪些方法对我们的算法是有效的
“诊断法”()的意思是:这是一种测试,能够深入了解某种算法到底是否有用。这通常也能够告诉你,要想改进一种算法的效果,什么样的尝试,才是有意义的。这些诊断法的执行和实现,有时候确实需要花很多时间来理解和实现,但这样做的确会让没有头绪的我们找到思路。
先来介绍如何评价学习算法。在此之后,介绍一些诊断法,希望能让你更清楚。在接下来的尝试中,如何选择更有意义的方法。
评估方法(Evaluating a Hypothesis)
评估方法就是判断模型是否过拟合
当我们确定学习算法的参数的时候,我们考虑的是选择参量来使训练误差最小化,但仅仅是因为这个假设具有很小的训练误差,并不能说明它就一定是一个好的假设函数。比如过拟合假设函数推广到新的训练集上是不适用的。如何判断一个假设函数是过拟合的呢?这就需要我们的评估方法大显身手。
一般 为了检验算法是否过拟合,我们将数据分成训练集和测试集,通常用70%的数据作为训练集,用剩下30%的数据作为测试集。
那么使用这两套新步骤是:
- 学习Θ并使用训练集最小化 J t r a i n ( Θ ) J_{train(Θ)} Jtrain(Θ)
- 计算测试集错误 J t e s t ( Θ ) J_{test(Θ)} Jtest(Θ)
The test set error计算为:
J t e s t ( Θ ) = 1 2 m t e s t ∑ i = 1 m t e s t ( h Θ ( x t e s t ( i ) ) − y t e s t ( i ) ) 2 J_{test}(\Theta) = \dfrac{1}{2m_{test}} \sum_{i=1}^{m_{test}}(h_\Theta(x^{(i)}_{test}) - y^{(i)}_{test})^2 Jtest(Θ)=2mtest1∑i=1mtest(hΘ(xtest(i))−ytest(i))2
对于分类问题:
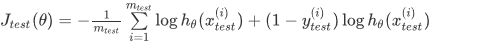
误分类的比率,对于每一个测试集样本,计算: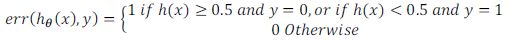
然后对计算结果求平均。
我们将基于以上得到模型选择的方法的方法
模型选择
当我们通过上面的评估方法发现,误差比较大,所以我们需要进行模型选择
只是因为学习算法很好地适合训练集,这并不意味着这是一个很好的假设。它可能会过于合适,对测试集的预测会很差。
假设我们要在10个不同次数的二项式模型之间进行选择:
显然越高次数的多项式模型越能够适应我们的训练数据集,但是适应训练数据集并不代表着能推广至一般情况,我们应该选择一个更能适应一般情况的模型。
我们需要使用交叉验证(Cross Validation)集来帮助选择模型。 即:使用60%的数据作为训练集,使用 20%的数据作为交叉验证集,使用20%的数据作为测试集。(这里的交叉验证需要注意,很多人会使用错误)

- 通过训练集来针对每一个级数的多项式来最优化参数theta
- 通过交叉验证集来找到最误差最小的级数d
- 使用来估计使用测试集得到的模型的泛化误差,这样的话,多项式的级数就不用通过测试集训练得到了。
如果只分分为training set和test set
对第二种分法来说,取得min(Err(test_set))的model作为最佳model,但是我们并不能评价选出来的这个model的性能,如果就将Err(test_set)的值当作这个model的评价的话,这是不公正的,因为这个model本来就是最满足test_set的model
诊断的偏差与方差 Bias vs. Variance
(模型参数曲线)
当运行一个学习算法时,若这个算法的结果不理想,多半是出现两种情况:要么是偏差比较大(high bias),要么是方差比较大(high variance)。换句话说,要么是欠拟合问题要么是过拟合问题。
即高偏差导致欠拟合,高方差导致过拟合。理想情况下,我们要在这两者之间找到最佳的平均值。
当增加多项式的级数d时,训练集的误差将会减小。同时当增加级数d到达某个点时,交叉验证误差会渐渐的减小,然后其会伴随着d的增加而增加,图像为一个凸曲线。如下图:

次数d越低,训练集误差越高,交叉验证集泛化误差同样也高,次数越高,训练集拟合的越好,可是泛化误差同样高。
判断
- 高偏差(underfitting):Jtrain(Θ)和JCV(Θ)都很高。而且,JCV(Θ)≈Jtrain(Θ)。
- 高方差(overfitting):Jtrain(Θ)将是低的,JCV(Θ)将比Jtrain(Θ)大得多。
正则化和偏差、方差
(正则化程度曲线)
我们给代价函数加上正则惩罚项,是为了防止过拟合,然而这并不是代表着 λ \lambda λ可以任取,事实上:

在上图中,我们看到随着λ的增加,我们的拟合变得更加低下。(右边欠拟合)
另一方面,当λ接近0时,我们倾向于过度拟合数据。(左边过拟合)
那么我们如何选择我们的参数λ来使其“恰到好处”呢?
为了选择模型和正则化项λ,我们需要:
- 创建一个lambda ( λ ∈ 0 , 0.01 , 0.02 , 0.04 , 0.08 , 0.16 , 0.32 , 0.64 , 1.28 , 2.56 , 5.12 , 10.24 ) (λ∈{0,0.01,0.02,0.04,0.08,0.16,0.32,0.64,1.28,2.56,5.12,10.24}) (λ∈0,0.01,0.02,0.04,0.08,0.16,0.32,0.64,1.28,2.56,5.12,10.24)
- 创建一个不同程度的模型或任何其他变体。
- 通过迭代,并为每个λ遍历所有的模型学习一些Θ。
- 使用 J C V ( θ ) J_{CV(\theta)} JCV(θ)上学习的Θ(用λ计算)来计算交叉验证误差,
- 选择交叉验证集合中产生最低错误的最佳组合。
使用最佳组合 θ \theta θ和λ,将其应用于 J t e s t ( θ ) J_{test(\theta)} Jtest(θ),以查看它是否具有良好的问题概括性(泛化generalization ability)。

J t r a i n ( θ ) J_{train}(\theta) Jtrain(θ)随着 λ \lambda λ值的增加而增加,因为 λ \lambda λ值增大会对应着高偏差问题,此时连训练集都不能很好的拟合,当很小时,对应着你可以很容易地用高次多项式拟合你的数据此时又容易出现过拟合。
λ \lambda λ很大时,会出现欠拟合问题,因此是那一片是高偏差区域,此时交叉验证集的误差会很大.
当 λ \lambda λ很小时,会出现过拟合问题,对应的是高方差问题,因此交叉验证集的误差也会很大。同样的,总会有中间的某个点对应的表现的结果正好合适,交叉验证误差和测试误差都很小。
我们可以与之前的对比去理解。
学习曲线
学习曲线表示了经验与效率之间的关系,指的是越是经常地执行一项任务,每次所需的时间就越少。 将学习效果数量化绘制于坐标纸上,横轴代表练习次数(或产量) ,纵轴代表学习的效果(单位产品所耗时间),这样绘制出的一条曲线,就是学习曲线。
学习曲线就是一种很好的工具,我经常使用学习曲线来判断某一个学习算法是否处于偏差、方差问题。 即,如果我们有m行数据,我们从1行数据开始,逐渐学习更多行的数据。思想是:当训练较少行数据的时候,训练的模型将能够非常完美地适应较少的训练数据,但是训练出来的模型却不能很好地适应交叉验证集数据或测试集数据。
- 随着训练集变大,二次函数的误差增加。
- 经过一定的m或训练集大小后,误差值将平稳。
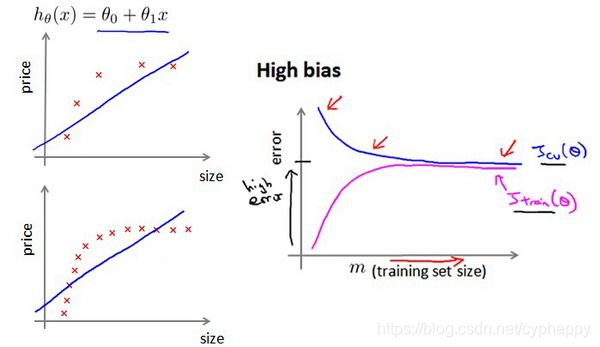
在高偏差/欠拟合的情况下,增加数据到训练集不一定能有帮助。无论训练集有多么大误差都不会有太大改观。

在高方差/过拟合的情况下,增加更多数据到训练集可能可以提高算法效果。假设我们使用一个非常高次的多项式模型,并且正则化非常小,可以看出,当交叉验证集误差远大于训练集误差时,往训练集增加更多数据可以提高模型的效果。
画出学习曲线对判断问题类型非常有效!!!!!!!!
总结
用以上三种方法就可以判断何时处于高方差何时处于高偏差,并有相应的措施
- 获取更多数据:高方差
- 减小特征:高方差
- 增加特征:高偏差
- 添加多项式特征:高偏差
- 降低λ:高偏差
- 增加λ:高方差
以训练集和交叉验证集的误差为基础进行判断
对于各种情况总结
| 高偏差和低方差 | 低偏差和高方差 |
|---|---|
| 低模型复杂度(训练误差大,验证误差大) | 高模型复杂度(训练误差小,验证误差大) |
| 正则化惩罚程度大(训练误差大,验证误差大) | 正则化惩罚程度小(训练误差小,验证误差大) |
| 大量数据不起作用(不能明显减少泛化误差) | 大量数据起作用(明显减少泛化误差) |
实际上,我们希望选择一个介于两者之间的模型,这个模型可以很好地推广,但是也能很好地适合数据。
我们以神经网络的例子,类比分析:
- 一个参数较少的神经网络容易出现underfitting/high bias。这也是计算待价更低,可以减少 λ \lambda λ。
- 具有更多参数的大型神经网络容易过度拟合overfitting/high variance。这在计算上也是昂贵的。在这种情况下,可以使用正则化(增加λ)来解决过度拟合问题。
机器学习系统设计
以判断分类电子邮件是否是垃圾邮件为例。
那么你怎么能花时间来提高这个分类器的准确度呢?
- 收集大量的数据(例如“蜜罐”项目,但并不总是有效)
- 开发复杂的功能(例如:在垃圾电子邮件中使用电子邮件标题数据)
- 开发算法以不同的方式处理您的输入(识别垃圾邮件中的拼写错误)。
误差分析!!!!
我们将在随后讲误差分析,告诉怎样用一个更加系统性的方法,从一堆不同的方法中,选取合适的那一个。
误差分析
构建一个学习算法的推荐方法为:
- Step1.使用快速但不完美的算法实现;
- Step2.画出学习曲线,分析偏差、方差,判断是否需要更多的数据、增加特征
- Step3.误差分析:人工检测错误、发现系统短处,来增加特征量以改进系统。
误差分析就是尝试新的特征,为我们的错误率得到一个数值,并根据我们的结果决定是否要保留新的特征。(使用误差度量值 来判断是否添加新的特征)
假设你有了一个快速而不完美的算法实现,又有一个数值的评估数据,这会帮助你尝试新的想法,快速地发现你尝试的这些想法是否能够提高算法的表现,从而你会更快地做出决定,在算法中放弃什么,吸收什么误差分析可以帮助我们系统化地选择该做什么。
类偏斜的误差度量(Error for Skewed Classes )
前面我们讲了误差估计的重要性,那关键是具体的误判率是多少才能让我们信服了。有一件重要的事情要注意,就是使用一个合适的误差度量值,这有时会对于你的学习算法造成非常微妙的影响,这件重要的事情就是偏斜类(skewed classes)的问题。
判断癌症的分类器,建立逻辑回归模型hθ(x),y=1表示有癌症,y=0则没有。假设你的算法在测试集上只有1%的错误,可实际上,测试集中只有0.5%的病人患有癌症,因此我们可以近似认为所有人都没有癌症。
不管是谁来看病统统判断为没有癌症。准确度就提高了,迟早会耽误。有些时候,一些数据很不平衡,比如正向的占99%、负向的占1%(倾斜数据shewed data)。这样只用准确度这个指标就不能很好的衡量算法的好坏,所以我们引入了查准率(Precision)和查全率(Recall)。
我们将算法预测的结果分成四种情况:
1.正确肯定(True Positive,TP):预测为真,实际为真
2.正确否定(True Negative,TN):预测为假,实际为假
3.错误肯定(False Positive,FP):预测为真,实际为假
4.错误否定(False Negative,FN):预测为假,实际为真

则:Precision=TP/(TP+FP)。例,在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,越高越好。
Recall=TP/(TP+FN)。例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比,越高越好。 这样,对于我们刚才那个总是预测病人肿瘤为良性的算法,其查全率和查准率是0。
解决skewed classes的方法
我们希望能够保证查准率和召回率的相对平衡。 有一些一些查准率和召回率作为算法评估度量值的更有效的方式。
继续沿用刚才预测肿瘤性质的例子。假使,我们的算法输出的结果在0-1 之间,我们使用阀值来预测真和假。
- 假设考虑到一个正常人如果误判为癌症,将会承受不必要的心理和生理压力,所以我们要有很大把握才预测一个病人患癌症(y=1)。那么一种方式就是提高阙值(threshold),不妨设我们将阙值提高到0.7。将会有较高的precision(预测为正类人数减少),但是recall将会变低(预测成功的人少)。
- 假设考虑到一个已经患癌症的病人如果误判为没有患癌症,那么病人可能将因不能及时治疗而失去宝贵生命,所以我们想要避免错过癌症患者的一种方式就是降低阙值,假设降低到0.3。将得到较高的recall,但是precision将会下降。
为了将precision和Recal转变为一个单一数值,我们引入了F1值
F = 2 P R P + R F = 2\frac{PR}{P+R} F=2P+RPR
总结:
衡量一个算法应该用一下值综合考虑:
- Accuracy = (true positives + true negatives) / (total examples)
- Precision = (true positives) / (true positives + false positives)
- Recall = (true positives) / (true positives + false negatives)
- F1_score = (2 * precision * recall) / (precision + recall)
大量数据的作用
但事实证明 在一定条件下 , 得到大量的数据并在 某种类型的学习算法中进行训练。 可以是一种 获得 一个具有良好性能的学习算法 有效的方法。
现在假设我们使用了非常非常大的训练集,在这种情况下,尽管我们希望有很多参数,但是如果训练集比参数的数量还大,甚至是更多,那么这些算法就不太可能会过度拟合。也就是说训练误差有希望接近测试误差。
另一种考虑这个问题的角度是为了有一个高性能的学习算法,我们希望它不要有高的偏差和方差。 因此偏差问题,我么将通过确保有一个具有很多参数的学习算法来解决,以便我们能够得到一个较低偏差的算法,并且通过用非常大的训练集来保证。