Web渗透测试-实战 方法 思路 总结
尽可能的搜集目标的信息
- 端口信息
- DNS信息
- 员工邮箱
信息搜集的分类
1、主动式信息搜集(可获取到的信息较多,但易被目标发现)
2、通过直接发起与被测目标网络之间的互动来获取相关信息,如通过Nmap扫描目标系统。
3、被动式信息搜集(搜集到的信息较少,但不易被发现)
4、通过第三方服务来获取目标网络相关信息。如通过搜索引擎方式来搜集信息。
搜索引擎
Google hacking
常用搜索语法:
intitle:KEYWORD //搜索网页标题中含有关键词的网页
intext:KEYWORD //搜索站点正文中含有关键词的网页
inurl:KEYWORD //搜索URL中包含有指定字符串的网址
inurl:phpid= //搜索PHP网页
site:DOMAIN //在指定站点内查找相关的内容
filetype:FILE //搜索指定类型的文件
我们可以同时附加多个条件进行筛选,比如 inurl:admin intitle:农具
两个筛选条件之间用空格隔开
搜索引擎语法
关键字(搜索范围) 引擎
【1】完全匹配搜索——精确匹配 “” 引号 和书名号《》
查询词很长 ,baidu分析过后 可能是拆分
把包含引号部分 作为整体 顺序匹配 来搜索
引号为英文状态下的引号。
屏蔽一些百度推广
eg:
“网站推广策划” 整个名字
"“手机” / 《手机》 "
【2】± 加减号的用法
加号 同时包含两个关键字 相当于空格和and。
减号 搜索结果中不含特定查询词 —— 前面必须是空格 后面紧连着需要排除的词
eg:
电影 -搜狐
音乐 +古风
【3】OR的用法
搜索两个或更多关键字
eg:
“seo or 深圳seo”
可能出现其中的一个关键字,也可能两个都出现。
“seo or 你的名字”(这里不加引号)。
如果你的名字为常见名。你会发现意外的惊喜,和你同名同姓的居然还有同行业。
“seo or 深圳seo”(这里不加引号) 就发现了和同名同姓的,还跟我同行。
【4】intitle
网页标题内容——网页内容提纲挈领式的归纳
竞争页面
关键词优化
eg:
(搜的时候不加引号)
“intitle:管理登录”
“新疆 intitle:雪菊”
“网络推广 intitle:他的名字”
【5】intext和 allintext (针对google有效)
在网页的内容中出现,而不是标题,
找页面里包含‘SEO’,标题包含SEO的对应文章页面。
只搜索网页部分中包含的文字(忽略了标题,URL等的文字),
类似在某些网站中使用的“文章内容搜索”功能。
eg:
“深圳SEO intext:SEO”
【6】inurl
搜索网址中 url链接 包含的的字符串 (中文 英文),
竞争对手 排名
eg:
搜索登录地址,可以这样写“inurl:admin.asp”,
想搜索Discuz的论坛,可以输入inurl:forum.php,
“csdn博客 inurl:py_shell”
【7】site
搜索特定网页
看搜索引擎收录了多少页面。
——某个站点中有自己需要找的东西,就可以把搜索范围限定在这个站点中
“胡歌 空格 insite:www.sina.com.cn”
【8】link
搜索某个网站的链接。
搜索某个网站url的内部链接和外部链接
不是对每个搜索引擎都很准,尤其是Google,
只会返回索引库中的一部分,并且是随机的一部分,
百度则不支持这个指令。
雅虎全面支持,而且查询得比较准确,
一般我们查看网站的链接都以雅虎为准,
【9】filetype
搜索你想要的电子书,限定在指定文档格式中
并不是所有的格式都会支持,现在百度支持的格式有pdf、doc、xls、all、ppt、rtf,
eg:
“python教程 filetype:pdf”
doc文件,就写“filetype:doc”,
“seo filetype:doc”,(搜的时候不加引号) ,
【10】related(只使用于google)
指定URL相关的页面、
一般都会显示与你网站有相同外链的网站。
竞争的对手,
相同的外链。
【11】 * 通配符 (百度不支持)
eg: 搜索 * 擎
【12】inanchor 导入链接 锚文字中包含 (百度不支持)
竞争对手
链接指向
【13】allintitle 包含多组关键字
【14】allinurl
【15】linkdomain (雅虎)
某域名反向链接 排除 得到外部链接
linkdomain: xxx.com -xxx.com
【16】related (google) 某个网站 关联页面
有共同外部链接
【17】domain 某一网站相关信息
“domain:url”
【18】index (百度)
“index of mp3”
【19】A|B 包含a或者b
2. Shodan
Shodan与Google这种搜索网址的搜索引擎不同的是,
Shodan是用来搜索网络空间中在线设备的。
shodan常用命令:
asn 区域自治编号
port 端口
org ip所属组织机构
os 操作系统类型
http.html 网页内容
html.title 网页标题
http.server http请求返回中server的类型
http.status http请求返回响应码的状态
city 市
country 国家
product 所使用的软件或产品
vuln CVE漏洞编号,例如:vuln:CVE-2014-0723
net 搜索一个网段,例如:123.23.1.0/24
country:"CN" os:"windows"

3. Zoomeye(钟馗之眼)
ZoomEye是一款针对网络空间的搜索引擎,收录了互联网空间中的设备、网站及其使用的服务或组件等信息。
搜索语法
1、app:nginx 组件名
2、ver:1.0 版本
3、os:windows 操作系统
4、country:”China” 国家
5、city:”hangzhou” 城市
6、port:80 端口
7、hostname:google 主机名
8、site:thief.one 网站域名
9、desc:nmask 描述
10、keywords:nmask’blog 关键词
11、service:ftp 服务类型
12、ip:8.8.8.8 ip地址
13、cidr:8.8.8.8/24 ip地址段
通过以上不同种类的搜索引擎我们可以获得相当多的有用的信息,甚至平时搜索东西我们也可以通过zoomeye来找到自己想要的东西
企业信息
- 天眼查
天眼查是一款“都能用的商业安全工具”,根据用户的不同需求,实现了企业背景、企业发展、司法风险、经营风险、经营状况、知识产权方面等多种数据维度的检索。
-
企业信用信息公示系统
-
工业和信息化部ICP/IP地址/域名信息备案管理系统
以上几个可以用来深入了解渗透目标网站所属企业的相关信息
whois信息
whois(读作“Who is”,非缩写)是用来查询域名的IP以及所有者等信息的传输协议。
whois信息可以获取关键注册人的信息,包括注册商、联系人、联系邮箱、联系电话、创建时间等,
可以进行邮箱反查域名,爆破邮箱,社工,域名劫持,寻找旁站等等。
常用的工具有:
站长工具、爱站、微步在线
Nslookup的用法
作用:
查询DNS的记录,查看域名解析是否正常,在网络故障的时候用来诊断网络问题
- 直接查询域名情况:
命令格式:nslookup domain[dns-server]
示例:nslookup www.163.com
- 查询其他记录
命令格式:nslookup -qt=type domain[dns-server]
示例:nslookup -qt=CNAME www.163.com
其中,type可以是以下这些类型:
A 地址记录(直接查询默认类型)
AAAA 地址记录
AFSDB Andrew文件系统数据库服务器记录
ATMA ATM地址记录
CNAME 别名记录
HINFO 硬件配置记录,包括CPU、操作系统信息
ISDN 域名对应的ISDN号码
MB 存放指定邮箱的服务器
MG 邮件组记录
MINFO 邮件组和邮箱的信息记录
MR 改名的邮箱记录
MX 邮件服务器记录
NS 名字服务器记录
PTR 反向记录
RP 负责人记录
RT 路由穿透记录
SRV TCP服务器信息记录
TXT 域名对应的文本信息
X25 域名对应的X.25地址记录
查询语法:
nslookup–d[其他参数]domain[dns-server]
- 返回信息说明
服务器:本机DNS服务器信息
非权威应答:Non-authoritative answer,
除非实际存储DNS Server中获得域名解析回答的,都称为非权威应答。
也就是从缓存中获取域名解析结果。
address:目标域名对应物理IP可有多个
aliase:目标域名
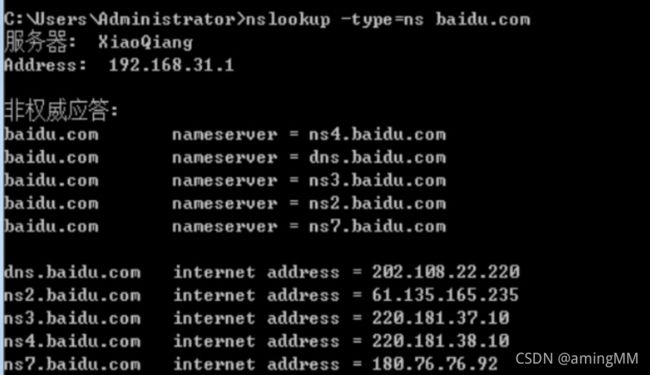
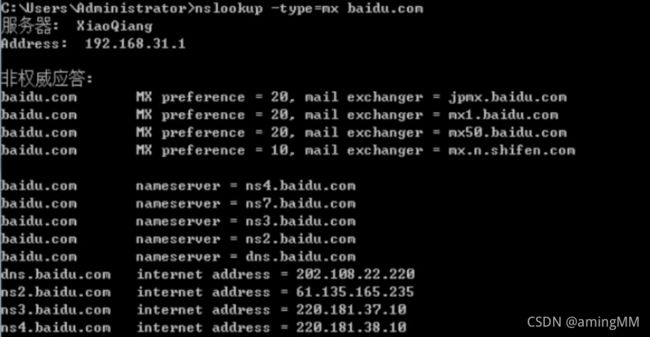

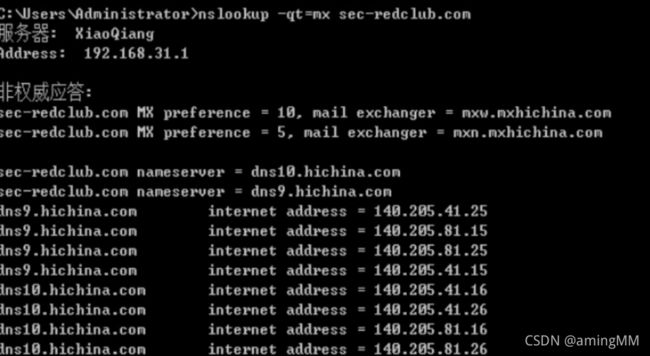
同样nslookup也可以验证是否存在域传送漏洞,步骤如下:
nslookup进入交互式模式
Server 设置使用的DNS服务器
ls命令列出某个域中的所有域名
子域名收集
子域名收集可以发现更多渗透测试范围内的域名/子域名,以增加漏洞发现机率;
探测到更多隐藏或遗忘的应用服务,这些应用往往可导致一些严重漏洞。
常用的工具有:
子域名挖掘机Layer、
subDomainsBrute、
Dnsenum、
Dnsmap
这里推荐一个在线收集子域名的网站 https://phpinfo.me/domain/
但是可能会出现遇到泛解析防御机制的情况
真实IP获取
现在大多数的网站都开启了CDN加速,导致我们获取到的IP地址不一定是真实的IP地址。
什么是CDN呢?
CDN的全称是Content Delivery Network,即内容分发网络。
其基本思路是尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快、更稳定。
通过在网络各处放置节点服务器所构成的在现有的互联网基础之上的一层智能虚拟网络,
CDN系统能够实时地根据网络流量和各节点的连接、
负载状况以及到用户的距离和响应时间等综合信息将用户的请求重新导向离用户最近的服务节点上
其目的是使用户可就近取得所需内容,解决 Internet网络拥挤的状况,提高用户访问网站的响应速度。
如果想获取真实IP,我们可以使用以下几种方法
1.多地Ping法:由CDN的原理,不同的地方去Ping服务器,如果IP不一样,则目标网站肯定使用了CDN。
这里推荐一个网站可以多个地点ping服务器,https://asm.ca.com/en/ping.php
2.二级域名法:目标站点一般不会把所有的二级域名放cdn上。
通过在线工具
如站长帮手,收集子域名,确定了没使用CDN的二级域名后。
本地将目标域名绑定到同IP(修改host文件),如果能访问就说明目标站与此二级域名在同一个服务器上;
如果两者不在同一服务器也可能在同C段,扫描C段所有开80端口的IP,然后挨个尝试。
3.nslookup法:
找国外的比较偏僻的DNS解析服务器进行DNS查询,因为大部分CDN提供商只针对国内市场,
而对国外市场几乎是不做CDN,所以有很大的几率会直接解析到真实IP。
4.Ping法:
直接ping example.com而不是www.example.com,因
为现有很多CDN厂商基本只要求把www.example.com cname到CDN主服务器上去,
那么直接ping example.com有可能直接获得真实IP。
指纹识别
通过识别目标网站所使用的操作系统、CMS、服务器与中间件信息,
可以帮助我们进一步了解渗透测试环境,可以利用已知的一些CMS漏洞或中间件漏洞来进行攻击。
1、可以在以下地方获取信息:
1.指定路径下指定名称的js文件或代码
2.指定路径下指定名称的css文件或代码
3.中的内容,有些程序标题中会带有程序标识,但不是很多。
4.meta标记中带程序标识
<meta name="description"/>
<meta name="keywords"/>
<meta name="generator"/>
<meta name="author"/>
<meta name="copyright"/>
5.display:none中的版权信息。
6.页面底部版权信息,关键字? Powered by等。
7.readme.txt、License.txt、help.txt等文件。
8.指定路径下指定图片文件,如一些小的图标文件,后台登录页面中的图标文件
等,一般管理员不会修改它们。
9.注释掉的html代码中<!–
10.http头的X-Powered-By中的值,有的应用程序框架会在此值输出。
11.cookie中的关键字
12.robots.txt文件中的关键字
robots.txt 中禁止的路径很可能说明站点就有这些路径 而且robots.txt 多是可访问的
13.404页面
14.302返回时的旗标
</code></pre>
<h6>2、 大小写</h6>
<p>访问网站:<br> http://www.xxx.com/index.html<br> http://www.xxx.com/inDex.html</p>
<p>Windows操作系统不区分大小写,Linux系统大小写敏感,用此方法能够判断是Windows还是Linux系统。</p>
<p>工具 :<br> 云悉指纹、<br> Whatweb、<br> httprint、<br> Bugscanner、<br> 浏览器插件 wappalyzer</p>
<h6>3、有的时候HTTP返回报文的server也可能泄露相关信息</h6>
<h1>端口扫描</h1>
<p>扫描端口可以使用Nmap,masscan进行扫描探测,<br> 尽可能多的搜集开启的端口好已经对应的服务版本,</p>
<p>得到确切的服务版本后可以搜索有没有对应版本的漏洞。<br> 常见的端口信息及渗透方法:</p>
<p>端口 ———————————— 服务 —————————— 渗透用途</p>
<pre><code>tcp 20,21
FTP 允许匿名的上传下载,爆破,嗅探,win提权,远程执行(proftpd 1.3.5),各类后门(proftpd,vsftp 2.3.4)
tcp 22
SSH 可根据已搜集到的信息尝试爆破,v1版本可中间人,ssh隧道及内网代理转发,文件传输等等
tcp 23
Telnet 爆破,嗅探,一般常用于路由,交换登陆,可尝试弱口令
tcp 25
SMTP 邮件伪造,vrfy/expn查询邮件用户信息,可使用smtp-user-enum工具来自动跑
tcp/udp 53
DNS 允许区域传送,dns劫持,缓存投毒,欺骗以及各种基于dns隧道的远控
tcp/udp 69
TFTP 尝试下载目标及其的各类重要配置文件
tcp 80-89,443,8440-8450,8080-8089
各种常用的Web服务端口 可尝试经典的topn,,owa,webmail,目标oa,各类Java控制台,各类服务器Web管理面板,各类Web中间件漏洞利用,各类Web框架漏洞利用等等……
tcp 110
POP3 可尝试爆破,嗅探
tcp 111,2049
NFS 权限配置不当
tcp 137,139,445
Samba 可尝试爆破以及smb自身的各种远程执行类漏洞利用,如,ms08-067,ms17-010,嗅探等……
tcp 143
IMAP 可尝试爆破
udp 161
SNMP 爆破默认团队字符串,搜集目标内网信息
tcp 389
LDAP ldap注入,允许匿名访问,弱口令
tcp 512,513,514
Linux rexec 可爆破,rlogin登陆
tcp 873
Rsync 匿名访问,文件上传
tcp 1194
OpenVPN 想办法钓VPN账号,进内网
tcp 1352
Lotus 弱口令,信息泄漏,爆破
tcp 1433
SQL Server 注入,提权,sa弱口令,爆破
tcp 1521
Oracle tns爆破,注入,弹shell…
tcp 1500
ISPmanager 弱口令
tcp 1723
PPTP 爆破,想办法钓VPN账号,进内网
tcp 2082,2083
cPanel 弱口令
tcp 2181
ZooKeeper 未授权访问
tcp 2601,2604
Zebra 默认密码zerbra
tcp 3128
Squid 弱口令
tcp 3312,3311
kangle 弱口令
tcp 3306
MySQL 注入,提权,爆破
tcp 3389
Windows rdp shift后门[需要03以下的系统],爆破,ms12-020
tcp 3690
SVN svn泄露,未授权访问
tcp 4848
GlassFish 弱口令
tcp 5000
Sybase/DB2 爆破,注入
tcp 5432
PostgreSQL 爆破,注入,弱口令
tcp 5900,5901,5902
VNC 弱口令爆破
tcp 5984
CouchDB 未授权导致的任意指令执行
tcp 6379
Redis 可尝试未授权访问,弱口令爆破
tcp 7001,7002
WebLogic Java反序列化,弱口令
tcp 7778
Kloxo 主机面板登录
tcp 8000
Ajenti 弱口令
tcp 8443
Plesk 弱口令
tcp 8069
Zabbix 远程执行,SQL注入
tcp 8080-8089
Jenkins,JBoss 反序列化,控制台弱口令
tcp 9080-9081,9090
WebSphere Java反序列化/弱口令
tcp 9200,9300
ElasticSearch 远程执行
tcp 11211
Memcached 未授权访问
tcp 27017,27018
MongoDB 爆破,未授权访问
tcp 50070,50030
Hadoop 默认端口未授权访问
</code></pre>
<h1>Nmap</h1>
<p>Nmap是一个网络连接端口扫描软件,用来扫描网上电脑开放的网络连接端口。<br> 确定哪些服务运行在哪些连接端口,<br> 并且推断计算机运行哪个操作系统。它是网络管理员必用的软件之一,以及用以评估网络系统安全。<br> 功能:<br> 1、 主机发现<br> 2、 端口扫描<br> 3、 版本侦测<br> 4、 OS侦测</p>
<h1>旁站C段查询</h1>
<p>旁站:是和目标网站在同一台服务器上的其它的网站。</p>
<p>旁注:通过入侵安全性较差的旁站,之后可以通过提权跨目录等手段拿到目标服务器的权限。</p>
<p>工具:<br> K8_C段旁注工具、<br> WebRobot、<br> 御剑、<br> 明小子 …</p>
<p>C段:每个IP有ABCD四个段,<br> 也就是说是D段1-255中的一台服务器,<br> 然后利用工具嗅探拿下该服务。</p>
<p>比如192.168.3.0-255的设备都处于同一个c段。</p>
<p>C段入侵:<br> 目标ip为192.168.1.128,可以入侵192.168.1.*的任意一台机器,<br> 然后利用一些黑客工具嗅探获取在网络上传输的各种信息。</p>
<p>工具:<br> Cain、<br> Sniffit 、<br> Snoop、<br> Tcpdump、</p>
<p>Dsniff</p>
<p>其他信息<br> Web敏感文件<br> robots.txt、crossdomin.xml、sitemap.xml、源码泄漏文件 …</p>
<p>WAF信息<br> WAF识别大多基于Headers头信息,</p>
<p>还可以使用Wafw00f,Sqlmap的waf脚本,Nmap的http-waf-detect和http-waf-fingerprint脚本等等。</p>
<p>相关漏洞</p>
<p>漏洞查询站点:exploitdb、hackerone、CNVD、0day5、乌云漏洞库镜像站 …</p>
<hr>
<hr>
<hr>
<hr>
<h2>httpscan</h2>
<p>httpscan是一个扫描指定CIDR网段的Web主机的小工具。<br> 和端口扫描器不一样,httpscan是以爬虫的方式进行Web主机发现,<br> 因此相对来说不容易被防火墙拦截</p>
<p><img src="http://img.e-com-net.com/image/info8/4b891307924c4319829b77880617630d.jpg" alt="在这里插入图片描述" width="0" height="0"></p>
<pre><code>Usage:./httpscan IP/CIDR –t threads
Example:./httpscan.py 10.20.30.0/24 –t 10
</code></pre>
<p>https://github.com/zer0h/httpscan</p>
<hr>
<hr>
<hr>
<hr>
<h2>dirsearch</h2>
<pre><code> python3.x ./dirsearch.py -u "http://xxxx.xxx" -e php
</code></pre>
<p>dirsearch需要使用Python3.x<br> 替换"http://xxxx.xxx"为目标网址即可</p>
<h1>1 前端信息泄露</h1>
<h2>1 调试器</h2>
<pre><code> static目录 下的 webpack目录
</code></pre>
<p><img src="http://img.e-com-net.com/image/info8/5f2496b8d1544269858920f16a817f86.jpg" alt="在这里插入图片描述" width="0" height="0"></p>
<pre><code>Webpack 是一个前端资源加载/打包工具。
它将根据模块的依赖关系进行静态分析,然后将这些模块按照指定的规则生成对应的静态资源。
可以将多种静态资源 js、css、less 转换成一个静态文件,减少了页面的请求。
它的存在依赖于node.js
</code></pre>
<p>包揽了其它静态文件 , 可以从中找一下敏感数据或是接口</p>
<ul>
<li> <p>平常项目 api所部署的服务器中间件会更多<br> 看起来都是SpringBoot框架<br> <img src="http://img.e-com-net.com/image/info8/3494ebdbfd8042868aa74fdfcaeb93b1.jpg" alt="在这里插入图片描述" width="0" height="0"><br> burp和spring专属字典 (springboot 信息泄露)</p> <p>/%20/swagger-ui.html<br> /actuator<br> /actuator/auditevents<br> /actuator/beans<br> /actuator/conditions<br> /actuator/configprops<br> /actuator/env<br> /actuator/health<br> /actuator/heapdump<br> /actuator/httptrace<br> /actuator/hystrix.stream<br> /actuator/info<br> /actuator/jolokia<br> /actuator/logfile<br> /actuator/loggers<br> /actuator/mappings<br> /actuator/metrics<br> /actuator/scheduledtasks<br> /actuator/swagger-ui.html<br> /actuator/threaddump<br> /actuator/trace<br> /api.html<br> /api/index.html<br> /api/swagger-ui.html<br> /api/v2/api-docs<br> /api-docs<br> /auditevents<br> /autoconfig<br> /beans<br> /caches<br> /cloudfoundryapplication<br> /conditions<br> /configprops<br> /distv2/index.html<br> /docs<br> /druid/index.html<br> /druid/login.html<br> /druid/websession.html<br> /dubbo-provider/distv2/index.html<br> /dump<br> /entity/all<br> /env<br> /env/(name)<br> /eureka<br> /flyway<br> /gateway/actuator<br> /gateway/actuator/auditevents<br> /gateway/actuator/beans<br> /gateway/actuator/conditions<br> /gateway/actuator/configprops<br> /gateway/actuator/env<br> /gateway/actuator/health<br> /gateway/actuator/heapdump<br> /gateway/actuator/httptrace<br> /gateway/actuator/hystrix.stream<br> /gateway/actuator/info<br> /gateway/actuator/jolokia<br> /gateway/actuator/logfile<br> /gateway/actuator/loggers<br> /gateway/actuator/mappings<br> /gateway/actuator/metrics<br> /gateway/actuator/scheduledtasks<br> /gateway/actuator/swagger-ui.html<br> /gateway/actuator/threaddump<br> /gateway/actuator/trace<br> /health<br> /heapdump<br> /heapdump.json<br> /httptrace<br> /hystrix<br> /hystrix.stream<br> /info<br> /intergrationgraph<br> /jolokia<br> /jolokia/list<br> /liquibase<br> /logfile<br> /loggers<br> /mappings<br> /metrics<br> /monitor<br> /prometheus<br> /refresh<br> /scheduledtasks<br> /sessions<br> /shutdown<br> /spring-security-oauth-resource/swagger-ui.html<br> /spring-security-rest/api/swagger-ui.html<br> /static/swagger.json<br> /sw/swagger-ui.html<br> /swagger<br> /swagger/codes<br> /swagger/index.html<br> /swagger/static/index.html<br> /swagger/swagger-ui.html<br> /swagger-dubbo/api-docs<br> /swagger-ui<br> /swagger-ui.html<br> /swagger-ui/html<br> /swagger-ui/index.html<br> /system/druid/index.html<br> /template/swagger-ui.html<br> /threaddump<br> /trace<br> /user/swagger-ui.html<br> /v1.1/swagger-ui.html<br> /v1.2/swagger-ui.html<br> /v1.3/swagger-ui.html<br> /v1.4/swagger-ui.html<br> /v1.5/swagger-ui.html<br> /v1.6/swagger-ui.html<br> /v1.7/swagger-ui.html<br> /v1.8/swagger-ui.html<br> /v1.9/swagger-ui.html<br> /v2.0/swagger-ui.html<br> /v2.1/swagger-ui.html<br> /v2.2/swagger-ui.html<br> /v2.3/swagger-ui.html<br> /v2/swagger.json<br> /webpage/system/druid/index.html</p> </li>
</ul>
<p><img src="http://img.e-com-net.com/image/info8/3d90978994664cb4a5c575260a426507.jpg" alt="在这里插入图片描述" width="0" height="0"><br> <img src="http://img.e-com-net.com/image/info8/a564a98fcee34f89afeeb389c7db79bb.jpg" alt="在这里插入图片描述" width="0" height="0"></p>
<h2>2 功能点 - 注册</h2>
<p>注册完后登陆的功能也少的可怜,只能上传上传头像。<br> 格式被严格限制,绕不过去,而上传上去了,也是上传到了oss上</p>
<p>没有直接调用oss上的图片资源,而是将用户的图片地址存储起来<br> 控制存储地址, 能造成ssrf</p>
<p>有关图片(头像)操作的地方</p>
<p><img src="http://img.e-com-net.com/image/info8/f54a144ba35a42cfb9e5dded8ce09c08.jpg" alt="在这里插入图片描述" width="0" height="0"><br> baseurl为api的服务器地址,那groupId是什么<br> 翻了翻别的地方的js,<br> 此域名的每个子域名,都对应着一个id,有了id才知道是哪个子公司进行的相应操作</p>
<p><img src="http://img.e-com-net.com/image/info8/51c52fdeb2ce48ff83bd4c69c7c28293.jpg" alt="在这里插入图片描述" width="0" height="0"><br> <img src="http://img.e-com-net.com/image/info8/3140bfed700948c8b49bbb8c1825684a.jpg" alt="在这里插入图片描述" width="0" height="0"><br> 拿到groupId<br> 进行不了相应操作, 没有携带access_token</p>
<p><img src="http://img.e-com-net.com/image/info8/39609158469d4964b597c5d94feeea60.jpg" alt="在这里插入图片描述" width="0" height="0"><br> 网站有个注册功能,登陆后,它会自动给你分配一个access_token</p>
<p><img src="http://img.e-com-net.com/image/info8/a5a73871d463454d8c14bbe2c3afdc3f.jpg" alt="在这里插入图片描述" width="0" height="0"></p>
<h2>3 dnslog</h2>
<p><img src="http://img.e-com-net.com/image/info8/19e19417991940baa8e438654d78d508.jpg" alt="在这里插入图片描述" width="0" height="0"></p>
<h6>Python爬虫——爬取 url 采集器</h6>
<h2>url采集器</h2>
<p>0x01 前言</p>
<ul>
<li>URl采集 批量刷洞</li>
</ul>
<p>0x02 ZoomEyeAPI脚本编写</p>
<ul>
<li>ZoomEye是一款针对网络空间的搜索引擎</li>
<li>收录了互联网空间中的设备、网站及其使用的服务或组件等信息。<br> ZoomEye 拥有两大探测引擎:Xmap 和 Wmap<br> 分别针对网络空间中的设备及网站,<br> 通过 24 小时不间断的探测、识别,标识出互联网设备及网站所使用的服务及组件。</li>
<li>研究人员可以通过 ZoomEye 方便的了解组件的普及率及漏洞的危害范围等信息。</li>
<li>虽然被称为 “黑客友好” 的搜索引擎,</li>
<li>但 ZoomEye 并不会主动对网络设备、网站发起攻击,收录的数据也仅用于安全研究。</li>
<li>ZoomEye更像是互联网空间的一张航海图。<br> <a href="http://img.e-com-net.com/image/info8/dbbba70efbcc46c19a961d2341c9a458.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/dbbba70efbcc46c19a961d2341c9a458.jpg" alt="Web渗透测试-实战 方法 思路 总结_第5张图片" width="650" height="265" style="border:1px solid black;"></a><br> API 文档</li>
</ul>
<p><a href="http://img.e-com-net.com/image/info8/cbfe93c47d25429799d894a6ad7a6d2a.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/cbfe93c47d25429799d894a6ad7a6d2a.jpg" alt="Web渗透测试-实战 方法 思路 总结_第6张图片" width="650" height="111" style="border:1px solid black;"></a></p>
<p>先登录,然后获取access_token<br> <a href="http://img.e-com-net.com/image/info8/c0137cf30da94224963a7642a113ffa5.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/c0137cf30da94224963a7642a113ffa5.jpg" alt="在这里插入图片描述" width="650" height="72"></a><br> <a href="http://img.e-com-net.com/image/info8/0d4eb7818a2545798562542a7783fd2d.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/0d4eb7818a2545798562542a7783fd2d.jpg" alt="Web渗透测试-实战 方法 思路 总结_第7张图片" width="650" height="240" style="border:1px solid black;"></a><br> <img src="http://img.e-com-net.com/image/info8/236d57b8e9164c0a92aedb31ed94460f.jpg" alt="在这里插入图片描述" width="0" height="0"><br> <a href="http://img.e-com-net.com/image/info8/f3d50e3b0e504cabab678cf19020c757.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/f3d50e3b0e504cabab678cf19020c757.jpg" alt="Web渗透测试-实战 方法 思路 总结_第8张图片" width="650" height="398" style="border:1px solid black;"></a></p>
<pre><code> user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
if __name__ == '__main__':
print Login()
</code></pre>
<p><a href="http://img.e-com-net.com/image/info8/b5ebaa8793e94c5daeefacabd06485cf.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/b5ebaa8793e94c5daeefacabd06485cf.jpg" alt="在这里插入图片描述" width="650" height="81"></a></p>
<pre><code> def search():
headers = {'Authorization': 'JWT ' + Login()}
r = requests.get(url = 'https://api.zoomeye.org/host/search?query=tomcat&page=1',
headers = headers)
response = json.loads(r.text)
print(response)
if __name__ == '__main__':
search()
</code></pre>
<p><a href="http://img.e-com-net.com/image/info8/f86e20ad0e49423096037ef6e8ca589c.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/f86e20ad0e49423096037ef6e8ca589c.jpg" alt="Web渗透测试-实战 方法 思路 总结_第9张图片" width="650" height="290" style="border:1px solid black;"></a><br> JSON数据,<br> 我们可以取出IP部分…</p>
<pre><code> print(response)
for x in response['matches']:
print(x['ip'])
</code></pre>
<p><a href="http://img.e-com-net.com/image/info8/854a50db2aa74082b0c8cd13e85547b8.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/854a50db2aa74082b0c8cd13e85547b8.jpg" alt="Web渗透测试-实战 方法 思路 总结_第10张图片" width="650" height="432" style="border:1px solid black;"></a><br> HOST的单页面采集<br> 接下来,就是用FOR循环…获取多页的IP</p>
<pre><code>#-*- coding: UTF-8 -*-
import requests
import json
from click._compat import raw_input
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search():
headers = {'Authorization': 'JWT ' + Login()}
for i in range(1, int(PAGECOUNT)):
r = requests.get(url='https://api.zoomeye.org/host/search?query=tomcat&page=' + str(i),
headers=headers)
response = json.loads(r.text)
print(response)
for x in response['matches']:
print(x['ip'])
if __name__ == '__main__':
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
PAGECOUNT = raw_input('[-] PLEASE INPUT YOUR SEARCH_PAGE_COUNT(eg:10):')
search()
</code></pre>
<p>这样就取出了你想要的页码的数据,然后就是完善+美观代码了…</p>
<pre><code>#-*- coding: UTF-8 -*-
import requests
import json
from click._compat import raw_input
def Login(user,passwd):
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search(queryType,queryStr,PAGECOUNT,user,passwd):
headers = {'Authorization': 'JWT ' + Login(user,passwd)}
for i in range(1, int(PAGECOUNT)):
r = requests.get(url='https://api.zoomeye.org/'+ queryType +'/search?query='+queryStr+'&page='+ str(i),
headers=headers)
response = json.loads(r.text)
try:
if queryType == "host":
for x in response['matches']:
print(x['ip'])
if queryType == "web":
for x in response['matches']:
print(x['ip'][0])
except KeyError:
print("[ERROR] No hosts found")
def main():
print (" _____ _____ ____ " )
print ("|__ /___ ___ _ __ ___ | ____| _ ___/ ___| ___ __ _ _ __" )
print (" / // _ / _ | '_ ` _ | _|| | | |/ _ ___ / __/ _` | '_ ")
print (" / /| (_) | (_) | | | | | | |__| |_| | __/___) | (_| (_| | | | |")
print ("/_______/ ___/|_| |_| |_|_______, |___|____/ _____,_|_| |_|")
print (" |___/ ")
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
PAGECOUNT = raw_input('[-] PLEASE INPUT YOUR SEARCH_PAGE_COUNT(eg:10):')
queryType = raw_input('[-] PLEASE INPUT YOUR SEARCH_TYPE(eg:web/host):')
queryStr = raw_input('[-] PLEASE INPUT YOUR KEYWORD(eg:tomcat):')
Login(user,passwd)
search(queryType,queryStr,PAGECOUNT,user,passwd)
if __name__ == '__main__':
main()
</code></pre>
<p><a href="http://img.e-com-net.com/image/info8/0a608ce1589b4ce081c6830dac846120.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/0a608ce1589b4ce081c6830dac846120.jpg" alt="Web渗透测试-实战 方法 思路 总结_第11张图片" width="650" height="781" style="border:1px solid black;"></a><br> <a href="http://img.e-com-net.com/image/info8/9631ad60fa4a485a8f7ecbdbd1168cc3.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/9631ad60fa4a485a8f7ecbdbd1168cc3.jpg" alt="Web渗透测试-实战 方法 思路 总结_第12张图片" width="650" height="280" style="border:1px solid black;"></a></p>
<p>0x03 ShoDanAPI脚本编写<br> <a href="http://img.e-com-net.com/image/info8/97af4129ed0a45caa680e880cf2d392b.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/97af4129ed0a45caa680e880cf2d392b.jpg" alt="Web渗透测试-实战 方法 思路 总结_第13张图片" width="650" height="382" style="border:1px solid black;"></a></p>
<p>Shodan是互联网上最可怕的搜索引擎。<br> CNNMoney的一篇文章写道,<br> 虽然目前人们都认为谷歌是最强劲的搜索引擎,<br> 但Shodan才是互联网上最可怕的搜索引擎。<br> 与谷歌不同的是,Shodan不是在网上搜索网址,<br> 而是直接进入互联网的背后通道。<br> Shodan可以说是一款“黑暗”谷歌,<br> 一刻不停的在寻找着所有和互联网关联的服务器、摄像头、打印机、路由器等等。<br> 每个月Shodan都会在大约5亿个服务器上日夜不停地搜集信息。<br> Shodan所搜集到的信息是极其惊人的。<br> 凡是链接到互联网的红绿灯、安全摄像头、家庭自动化设备以及加热系统等等都会被轻易的搜索到。<br> Shodan的使用者曾发现过一个水上公园的控制系统,一个加油站,甚至一个酒店的葡萄酒冷却器。</p>
<p>而网站的研究者也曾使用Shodan定位到了核电站的指挥和控制系统及一个粒子回旋加速器。</p>
<p>Shodan真正值得注意的能力就是能找到几乎所有和互联网相关联的东西。<br> 而Shodan真正的可怕之处就是这些设备几乎都没有安装安全防御措施,其可以随意进入。</p>
<p>0x04 简易BaiduURL采集脚本编写</p>
<p>0x05 【彩蛋篇】论坛自动签到脚本</p>
<p><a href="http://img.e-com-net.com/image/info8/cdfe68b1c9c04839939e1a29c9441dab.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/cdfe68b1c9c04839939e1a29c9441dab.jpg" alt="Web渗透测试-实战 方法 思路 总结_第14张图片" width="650" height="272" style="border:1px solid black;"></a></p>
<h6>渗透采集——superl-url</h6>
<hr>
<hr>
<hr>
<hr>
<p><a href="http://img.e-com-net.com/image/info8/a488a2959e534c03877c4f2a3430bde0.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/a488a2959e534c03877c4f2a3430bde0.png" alt="Web渗透测试-实战 方法 思路 总结_第15张图片" width="601" height="300" style="border:1px solid black;"></a></p>
<p>https://github.com/super-l/superl-url</p>
<p>@ 环境 3.7 python</p>
<pre><code> pip install pymysql
pip install tldextract
pip install tld==0.7.6 https://pypi.org/project/tld/0.7.6/
pip install ConfigParser
</code></pre>
<p><a href="http://img.e-com-net.com/image/info8/c61de32e95b142898808f97922ca4906.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/c61de32e95b142898808f97922ca4906.jpg" alt="Web渗透测试-实战 方法 思路 总结_第16张图片" width="650" height="290" style="border:1px solid black;"></a><a href="http://img.e-com-net.com/image/info8/1b0d3f3887854411913738f5aeb158d2.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/1b0d3f3887854411913738f5aeb158d2.jpg" alt="Web渗透测试-实战 方法 思路 总结_第17张图片" width="650" height="136" style="border:1px solid black;"></a></p>
<p><a href="http://img.e-com-net.com/image/info8/1c5de9dfaf0d4420808f0aaa47771a84.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/1c5de9dfaf0d4420808f0aaa47771a84.jpg" alt="Web渗透测试-实战 方法 思路 总结_第18张图片" width="650" height="657" style="border:1px solid black;"></a><br> <a href="http://img.e-com-net.com/image/info8/c9c2cf552c3c4074bc2c3cd4218a86a7.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/c9c2cf552c3c4074bc2c3cd4218a86a7.jpg" alt="Web渗透测试-实战 方法 思路 总结_第19张图片" width="549" height="471" style="border:1px solid black;"></a></p>
<hr>
<hr>
<hr>
<h1>2 业务 身份认证安全</h1>
<h2>2.1 暴力破解</h2>
<p>没有验证码限制<br> 或者一次验证码可以多次使用的地方<br> 使用已知用户对密码进行暴力破解<br> 或者用一个通用密码对用户进行暴力破解。<br> 简单的验证码爆破。</p>
<p>案列:某药app暴力破解</p>
<p>抓包一看请求全是明文的<br> 先从登陆界面开始:<br> <img src="http://img.e-com-net.com/image/info8/20c901827a064ae493ce88de66e2c0b0.jpg" alt="在这里插入图片描述" width="0" height="0"><br> 随便输入几个手机号和密码<br> 返回内容不一样<br> 手机号没有注册过的,返回手机号不存在,手机号注册过的,返回用户名密码错误,<br> 这就好办了,自己构造个手机号字典去刷,如图:<br> <img src="http://img.e-com-net.com/image/info8/600ba78790674ec8aafb2f4edfb26472.jpg" alt="在这里插入图片描述" width="0" height="0"><br> ok,拿到手机号了,<br> 下面就开始暴力破解验证码了,<br> 用自己手机试了下,验证码是4位的,而且请求也是明文的,<br> 接下来暴力破解验证码,<br> 刚开始成功了,但是用这个验证码却登陆不上去,<br> 于是就关了那个爆破结果,后来我静下来想想,想到人家验证码可能是一次有效的,<br> 后来我又刷了一遍,但是可能被发现了,再刷结果返回302了,失败<br> <img src="http://img.e-com-net.com/image/info8/9b46d841f95441a6815b9e00c9f3a3c8.jpg" alt="在这里插入图片描述" width="0" height="0"><br> 于是我发现有个找回密码功能,<br> 也是手机验证码,填上自己自定义的密码,然后获取验证码,抓包</p>
<p><img src="http://img.e-com-net.com/image/info8/ebd4710435704df2ab40eb485fef8985.jpg" alt="在这里插入图片描述" width="0" height="0"><br> 继续爆破,这次找到了,<br> 其实暴力破解登陆验证码的时候跟这个一样,只不过我没保存下来,如图:<br> <img src="http://img.e-com-net.com/image/info8/7d1def07f44443bb84cf8d2bccddab8c.jpg" alt="在这里插入图片描述" width="0" height="0"><br> 用我修改的密码登陆,如图:<br> <img src="http://img.e-com-net.com/image/info8/b974efcdd87e453ca8f8c698157eddb8.jpg" alt="在这里插入图片描述" width="0" height="0"><br> 登陆成功</p>
<p>总结,这次爆破的跟之前不太一样,<br> 之前的验证码都是用过之后还有效的,这次验证码是一次性的,</p>
<p>一些工具及脚本<br> Burpsuite<br> htpwdScan 撞库爆破必备 URL: https://github.com/lijiejie/htpwdScan<br> hydra 源码安装xhydra支持更多的协议去爆破 (可破WEB,其他协议不属于业务安全的范畴)</p>
<hr>
<hr>
<hr>
<h2>2.2 Cookie&session</h2>
<h3>a.会话固定攻击</h3>
<p>利用服务器的session不变机制,借他人之手获得认证和授权,冒充他人。</p>
<p>案列:新浪广东美食后台验证逻辑漏洞,直接登录后台,566764名用户资料暴露</p>
<p>网站源码可直接下载本地,分析源码可直接登陆后台。<br> 暴露所有用户个人资料,联系方式等,目测用户566764名。</p>
<p>用户资料暴露<br> <img src="http://img.e-com-net.com/image/info8/c17d57ec34d34c398f4d0191090a4483.jpg" alt="在这里插入图片描述" width="0" height="0"><br> 566764名用户资料<br> <img src="http://img.e-com-net.com/image/info8/8beb42413d644275983d412dd092e1df.jpg" alt="在这里插入图片描述" width="0" height="0"><br> 直接进入后台<br> <img src="http://img.e-com-net.com/image/info8/24f316f98cd84aa1b6c9efdd7c206aea.jpg" alt="在这里插入图片描述" width="0" height="0"><br> 源码直接下载<br> <img src="http://img.e-com-net.com/image/info8/3ce7fd3e51cf4a758eeecbcf23a10ab9.jpg" alt="在这里插入图片描述" width="0" height="0"><br> 566764名用户资料直接跨后台浏览<br> <img src="http://img.e-com-net.com/image/info8/0b136bb1180c4fd1a42a8e85da189c57.jpg" alt="在这里插入图片描述" width="0" height="0"><br> 修复方案:</p>
<p>漏洞较多,不知怎么说起,只列举一项<br> phpsessid会话固定,通过利用此漏洞,攻击者可以进行会话固定攻击。<br> 在一个会话固定攻击,攻击者将用户的会话ID之前,用户甚至登录到目标服务器<br> 从而消除了需要获得用户的会话ID之后。<br> 从php.ini设置session.use_only_cookies = 1。<br> 该选项使管理员能够使他们的用户不会受到攻击涉及在URL传递的会话ID,缺省值为0。</p>
<h3>b.Cookie仿冒:</h3>
<p>修改cookie中的某个参数可以登录其他用户。</p>
<p>案例:益云广告平台任意帐号登录</p>
<p>只需要添加cookie<br> yibouid=数字 即可登录任意用户帐号!</p>
<p>通过遍历 找到一个官方管理的ID 291<br> 登录<br> <img src="http://img.e-com-net.com/image/info8/309e2d939a4845b1ba3b226f1ff03816.jpg" alt="在这里插入图片描述" width="0" height="0"><br> <img src="http://img.e-com-net.com/image/info8/200272b3e75f46fbbbd571201e1c857b.jpg" alt="在这里插入图片描述" width="0" height="0"></p>
<p>修复方案:</p>
<p>增强对cookie的验证机制!</p>
<h1>3 加密测试</h1>
<p>未使用https,是功能测试点,不好利用。<br> 前端加密,用密文去后台校验,并利用smart decode可解。</p>
<h1>4 业务一致性安全</h1>
<h2>4.1 手机号篡改</h2>
<p>抓包修改手机号码参数为其他号码尝试,<br> 例如在办理查询页面,输入自己的号码然后抓包,修改手机号码参数为其他人号码,<br> 查看是否能查询其他人的业务。</p>
<h2>4.2 邮箱和用户名更改</h2>
<p>抓包修改用户或者邮箱参数为其他用户或者邮箱</p>
<p>案例:绿盟RSAS安全系统全版本通杀权限管理员绕过漏洞,包括最新 RSAS V5.0.13.2</p>
<p>RSAS默认的审计员</p>
<p>账号是:reporter,auditor<br> 密码是:nsfocus</p>
<p>普通账户登陆后<br> 查看版本,为最新V**.<strong>.</strong>.** 版本<br> <img src="http://img.e-com-net.com/image/info8/94b4c9d9f69c4bebaa57377ced4ccf82.jpg" alt="在这里插入图片描述" width="0" height="0"></p>
<p>然后修改审计员密码,抓包,<br> 将referer处的auditor和post的数据里面的auditor一律修改为admin,<br> 也就是管理员账号,</p>
<p>2处修改完后的数据包如下图:<br> <img src="http://img.e-com-net.com/image/info8/e8f40e52290d47d1abfa460ea3006963.jpg" alt="在这里插入图片描述" width="0" height="0"><br> 提交数据后,直接返回给我们超级管理员的密码修改页面,利用逻辑错误直接得到超级权限,如图:<br> <img src="http://img.e-com-net.com/image/info8/95ec97e52f6f40308f034c57c5707af1.jpg" alt="在这里插入图片描述" width="0" height="0"><br> 我们直接在这里修改admin的密码,然后提交即可:<br> <img src="http://img.e-com-net.com/image/info8/ae83478001ed434390fe580998907d40.jpg" alt="在这里插入图片描述" width="0" height="0"><br> 超级管理员登陆<br> <img src="http://img.e-com-net.com/image/info8/37acefc0fb9b4e5286f0a3e0820af7e0.jpg" alt="在这里插入图片描述" width="0" height="0"><br> <img src="http://img.e-com-net.com/image/info8/ae4188c8e7974d14aa9c6b9d5787c55f.jpg" alt="在这里插入图片描述" width="0" height="0"></p>
<h2>4.3 订单ID更改</h2>
<p>查看自己的订单id,然后修改id(加减一)查看是否能查看其它订单信息。</p>
<p>案例:广之旅旅行社任意访问用户订单</p>
<p>可以任意访问旅客的订单,泄露旅客的敏感信息!</p>
<p>用户登陆广之旅官方网站注册登陆<br> http://www.gzl.com.cn/<br> 只要随便假订一张订单,在我的订单里面获得订单号,就能穷举其它订单信息<br> <img src="http://img.e-com-net.com/image/info8/5c4e1ac4e1b744d693e600f80236b576.jpg" alt="在这里插入图片描述" width="0" height="0"><br> http://www.gzl.com.cn/Users/Order/Groups.aspxOrderId=订单号<br> 该页没过滤权限,相信还有更大的漏洞。</p>
<p>修复方案:<br> 对<br> http://www.gzl.com.cn/Users/Order/Groups.aspx<br> 订单页增加过滤</p>
<h2>4.4 商品编号更改</h2>
<p>例如积分兑换处,<br> 100个积分只能换商品编号为001,<br> 1000个积分只能换商品编号005,<br> 在100积分换商品的时候抓包把换商品的编号修改为005,用低积分换区高积分商品。</p>
<p>案例:联想某积分商城支付漏洞再绕过</p>
<p>http://ideaclub.lenovo.com.cn/club/index.phpm=goods&c=lists<br> 还是这个积分商城、 看我怎么用最低的积分换最高积分的礼物的~</p>
<p>1.我先挑选出我最喜欢的礼物,并复制下goods_id=1419f75d406811e3ae7601beb44c5ff7<br> <img src="http://img.e-com-net.com/image/info8/dac90705e93c4d9082f558fd3d309607.jpg" alt="在这里插入图片描述" width="0" height="0"><br> 2.选择积分最低的礼物兑换(5积分的杯子),并填好相关信息,抓包修改goods_id<br> 替换为1419f75d406811e3ae7601beb44c5ff7<br> <img src="http://img.e-com-net.com/image/info8/01131119e0854d44adecfda9454eb588.jpg" alt="在这里插入图片描述" width="0" height="0"><br> 3.这里显示兑换成功,虽然显示的是被子兑换成功,但是兑换记录里,就不相同了<br> <img src="http://img.e-com-net.com/image/info8/957c0cd8e1de44249b9e2635b93d25d0.jpg" alt="在这里插入图片描述" width="0" height="0"><br> <img src="http://img.e-com-net.com/image/info8/d8a81d95f65c4970a47ee9a72806f8df.jpg" alt="在这里插入图片描述" width="0" height="0"><br> 到这我们心仪的礼物要30积分,我只花5积分就兑换来了,是不是很划算?</p>
<p>修复方案:</p>
<p>积分参数还是放后台来操作,有goods_id,在后台计算的时候取出并计算,这样会安全些。</p>
<hr>
<hr>
<hr>
<p><img src="http://img.e-com-net.com/image/info8/63dfc5c87b2446e199de38a25775fe74.jpg" alt="在这里插入图片描述" width="0" height="0"><img src="http://img.e-com-net.com/image/info8/afe20ece0ca74315833ae89635bb2b02.jpg" alt="在这里插入图片描述" width="0" height="0"><img src="http://img.e-com-net.com/image/info8/f7b2b5ca72c44a499461a73653a90d3c.jpg" alt="在这里插入图片描述" width="0" height="0"><img src="http://img.e-com-net.com/image/info8/8a518036b694417a82c68d3a7684c07c.jpg" alt="在这里插入图片描述" width="0" height="0"><br> <img src="http://img.e-com-net.com/image/info8/2ef15dfb5a914d67b99488fc91c5bae0.jpg" alt="在这里插入图片描述" width="0" height="0"><br> <img src="http://img.e-com-net.com/image/info8/4dfc4a7a3b5a4c9499c195100628e6e2.jpg" alt="在这里插入图片描述" width="0" height="0"><img src="http://img.e-com-net.com/image/info8/23cd2dbd6adf4a22b1fa926c3f87540c.jpg" alt="在这里插入图片描述" width="0" height="0"><img src="http://img.e-com-net.com/image/info8/fbdd0336565d488991ffa7518844835a.jpg" alt="在这里插入图片描述" width="0" height="0"></p>
<p>渗透信息收集–资产探测</p>
<h4>python2 knockpy.py www.ycxy.com</h4>
<h4>python2 subDomainsBrute.py www.ycxy.com -o 123.txt</h4>
<h4>dirsearch.py [-u|–url] target [-e|–extensions] extensions [options]web路径收集与扫描</h4>
<h3>实战某大学</h3>
<p>信息收集:<br> 来源 url采集<br> inurl:xxx.php 学校</p>
<p>注入点批量检测 :枫叶</p>
<p>sql注入验证 safe3 注入安全检测<br> 猜解表名 字段名</p>
<h3>burpsuite抓包</h3>
<ul>
<li>浏览器代理<br> proxy 抓包拦截–>intruder<br> clear</li>
<li>选中密码 $add</li>
<li>选择字典<br> payloads options --> load</li>
<li>start attack</li>
</ul>
<h3>admin权限进后台 getshell(wordpress后台审计)</h3>
<h5>插件 -->上传插件zip格式包</h5>
<p>上传xxx.zip 内容x.php</p>
<ul>
<li>原理 源码中自解压 到 /wp-content/upgrade/xxx/x.php</li>
<li>配置删除后ban访问</li>
</ul>
<h2>生成字典</h2>
<p>社会工程学 密码生成工具 -猜密码<br> http://www.hacked.com.cn/pass.html<br> <img src="http://img.e-com-net.com/image/info8/c3b3f8c026194f05a32c41d85a98e056.png" alt="在这里插入图片描述" width="0" height="0"><br> 或者自己写一个</p>
<h3>开源系统/github泄漏 敏感目录/文件</h3>
<ul>
<li> <p>后台</p> </li>
<li> <p>敏感配置文件<br> eg: wordpress 默认后台 http://xxxx.com/wp-login.php<br> admin<br> <img src="http://img.e-com-net.com/image/info8/700e665223a64779bb862beac2868d2c.jpg" alt="在这里插入图片描述" width="0" height="0"><br> <img src="http://img.e-com-net.com/image/info8/a0163f0288674dbc8e7257715cc333c7.jpg" alt="在这里插入图片描述" width="0" height="0"></p> </li>
<li> <p>历史密码</p> </li>
<li> <p>QQ</p> </li>
<li> <p>姓名 字母拼写</p> </li>
<li> <p>家庭住址</p> </li>
<li> <p>学校</p> </li>
<li> <p>网站/域名</p> </li>
<li> <p>邮件地址</p> </li>
</ul>
<p><img src="http://img.e-com-net.com/image/info8/fc3ce15db277487f93d314f5ef7eb0b6.jpg" alt="在这里插入图片描述" width="0" height="0"><img src="http://img.e-com-net.com/image/info8/3d6e797cc3ca45f68d5b76a75b14c66b.jpg" alt="在这里插入图片描述" width="0" height="0"></p>
<h4>web渗透 一般步骤 及 实战思路</h4>
<ul>
<li>1 站长之家 类似 全国测速(ping) 判断有无cdn加速节点<br> <img src="http://img.e-com-net.com/image/info8/77a6bda1f29f4327a2de9e8e5b60eb06.jpg" alt="在这里插入图片描述" width="0" height="0"></li>
<li>2 无节点 进行<br> 端口 + 服务器 系统指纹扫描 (从 软件漏洞 和 系统漏洞下手)<br> <img src="http://img.e-com-net.com/image/info8/097539f111d048928b63d27c21480bcb.jpg" alt="在这里插入图片描述" width="0" height="0"></li>
<li>3 C段扫描 旁站+ 内网渗透<br> <img src="http://img.e-com-net.com/image/info8/4939d3acf2a742f180e18372c3ea3906.jpg" alt="在这里插入图片描述" width="0" height="0"><br> <img src="http://img.e-com-net.com/image/info8/fa9cc5dd078440d680da67f2410179cb.jpg" alt="在这里插入图片描述" width="0" height="0"></li>
</ul>
<h3>2020 .3.16</h3>
<ul>
<li> <p>没事闲的 逛逛fofa 发现还是 admin 空</p> </li>
<li> <p>但是 、、、、<br> <img src="http://img.e-com-net.com/image/info8/8621bc431ce9474abbdfa5c891f58865.jpg" alt="在这里插入图片描述" width="0" height="0"><img src="http://img.e-com-net.com/image/info8/ed1c3744f8814106b4ce1d4fcfdc48b3.jpg" alt="在这里插入图片描述" width="0" height="0"></p> </li>
<li> <p>这是个什么鬼</p> </li>
<li> <p>iis + asp <img src="http://img.e-com-net.com/image/info8/28bc74f697484548b4167b693922dd96.jpg" alt="在这里插入图片描述" width="0" height="0"><img src="http://img.e-com-net.com/image/info8/cbd8236fd08541169aec411af5517af7.jpg" alt="在这里插入图片描述" width="0" height="0"></p> </li>
<li> <p>大马试一试</p> </li>
<li> <p>老鼠盗洞 一打一个准<br> <img src="http://img.e-com-net.com/image/info8/2bcade62723e4c63981270359d43913e.jpg" alt="在这里插入图片描述" width="0" height="0"></p> </li>
<li> <p>已经擦了屁股 删了入口 <img src="http://img.e-com-net.com/image/info8/1c835282754c4518932bd7ecb20a3c22.jpg" alt="在这里插入图片描述" width="0" height="0"></p> </li>
<li> <p>逗的是 好像是个人电脑<br> <img src="http://img.e-com-net.com/image/info8/66d57e57422b4b41a1c9f2be2a238914.png" alt="在这里插入图片描述" width="0" height="0"><img src="http://img.e-com-net.com/image/info8/25cf607986704275871f7e0268377209.png" alt="在这里插入图片描述" width="0" height="0"><img src="http://img.e-com-net.com/image/info8/c9c040243f47438fbb0cf63ad32b266c.png" alt="在这里插入图片描述" width="0" height="0"></p> </li>
<li> <p>应该是某某小区的门卫电脑忘记关掉了</p> </li>
<li> <p>这个shell 不好用 一句话连一下<br> <img src="http://img.e-com-net.com/image/info8/e22d9ce1c696497498e0a390a01394cf.jpg" alt="在这里插入图片描述" width="0" height="0"><img src="http://img.e-com-net.com/image/info8/e7705386ff164bda8ad1fd809d3b20a1.jpg" alt="在这里插入图片描述" width="0" height="0"><img src="http://img.e-com-net.com/image/info8/891f00ebb63e4e0cb75199e231acf01a.png" alt="在这里插入图片描述" width="0" height="0"><img src="http://img.e-com-net.com/image/info8/fdd57356e6344bedb1f3247d591f65b1.jpg" alt="在这里插入图片描述" width="0" height="0"><img src="http://img.e-com-net.com/image/info8/8b20bdf4194c4943b57cc0552bb32fef.jpg" alt="在这里插入图片描述" width="0" height="0"></p> </li>
</ul>
<p><img src="http://img.e-com-net.com/image/info8/cb781041fb064c6a9535606044668cb5.jpg" alt="在这里插入图片描述" width="0" height="0"><br> you haven’t updated sqlmap for more than 440 days!!!<br> <img src="http://img.e-com-net.com/image/info8/3b75f2389b8c480185515b87f90b2cef.jpg" alt="在这里插入图片描述" width="0" height="0"></p>
<p><img src="http://img.e-com-net.com/image/info8/af96ef8a6d8f4705b59a9f9d00524627.jpg" alt="在这里插入图片描述" width="0" height="0"><br> <img src="http://img.e-com-net.com/image/info8/e77aa35b85b44cfc9311ebbe6f188a5b.jpg" alt="在这里插入图片描述" width="0" height="0"></p>
<hr>
<hr>
<hr>
<p>inurl: http:// tw</p>
<hr>
<p>中间件</p>
<p>Microsoft-IIS</p>
<p>版本: 7/7.5</p>
<p>fast-CGI运行模式 文件路径/xx.jpg</p>
<p>Nginx</p>
<p>1.1</p>
<p>apache tomcat<br> 文件包含漏洞(CVE-2020-1938)<br> 二、影响范围<br> 受影响版本</p>
<p>Apache Tomcat 6<br> Apache Tomcat 7 < 7.0.100<br> Apache Tomcat 8 < 8.5.51<br> Apache Tomcat 9 < 9.0.31<br> 不受影响版本</p>
<p>Apache Tomcat = 7.0.100<br> Apache Tomcat = 8.5.51<br> Apache Tomcat = 9.0.31<br> 远程代码执行漏洞(CVE-2019-0232)<br> 远程命令执行漏洞(CVE-2017-12615)<br> 跨站脚本漏洞处理(CVE-2019-0221)</p>
<p>apache coyote</p>
<hr>
<p>.aspx jsp</p>
<p>site: 域名</p>
<p>多地ping</p>
<p>ycxy.com<br> 60.216.8.0/24</p>
<p>223.99.192.0/24</p>
<p>POST注入 GET注入</p>
<p>./dirsearch.py -u http://223.99.192.14:8080/ -e *<br> -u 指定url<br> -e 指定网站语言—— *指全部语言可换php等<br> -w 可以加上自己的字典(带上路径)<br> -r 递归跑(查到一个目录后,在目录后在重复跑,很慢,不建议用)<br> –random-agents 使用代理(使用的代理目录在uesr-agents.txt中,可以自己添加)</p>
<p>5webdav 漏洞<br> cadaver是WEBDAV的 客户端<br> DAVTest</p>
<p>2021 hw 0day</p>
<p>暴力穷举破解<br> XSS跨站伪造请求<br> sql注入 sql-inject<br> RCE<br> 文件包含<br> 文件下载<br> 文件上传<br> 越权访问<br> 目录遍历<br> 敏感信息泄露<br> PHP反序列化<br> XXE<br> url重定向<br> SSRF<br> waf绕过<br> CRLF</p>
<p>sql插入<br> insert into test(name,second) values(null,null)</p>
</div>
</div>
</div>
</div>
</div>
<!--PC和WAP自适应版-->
<div id="SOHUCS" sid="1527656585831186432"></div>
<script type="text/javascript" src="/views/front/js/chanyan.js"></script>
<!-- 文章页-底部 动态广告位 -->
<div class="youdao-fixed-ad" id="detail_ad_bottom"></div>
</div>
<div class="col-md-3">
<div class="row" id="ad">
<!-- 文章页-右侧1 动态广告位 -->
<div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_1"> </div>
</div>
<!-- 文章页-右侧2 动态广告位 -->
<div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_2"></div>
</div>
<!-- 文章页-右侧3 动态广告位 -->
<div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_3"></div>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="container">
<h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(前端,html,面试,前端,搜索引擎,百度)</h4>
<div id="paradigm-article-related">
<div class="recommend-post mb30">
<ul class="widget-links">
<li><a href="/article/1947610292972220416.htm"
title="迅雷iOS版时隔4年重新上架,主推私密云盘,跟百度网盘抢生意" target="_blank">迅雷iOS版时隔4年重新上架,主推私密云盘,跟百度网盘抢生意</a>
<span class="text-muted">郭静</span>
<div>很难相信,到2020年,竟然还有公司扎进网盘行业。2016年的倒闭潮让网盘行业一度陷入低谷,就连用户量达到2亿的360云盘也没能幸免,UC网盘、新浪微盘、乐视云盘等逐渐关闭,用户的网盘自由变成了奢望。最终,百度网盘、115、腾讯微云成为行业的幸存者。即使是仅存的三家网盘公司,短期内也没能看到成功的曙光。2018年,中国科技行业迎来上市潮,据不完全统计,截至9月20日,2018年就有39家科技公司在</div>
</li>
<li><a href="/article/1947609274645540864.htm"
title="美剧《模范爱侣 》1080p超清中字2024(完美夫妻电视剧)全6集完整未删减版免费在线观看夸克网盘高清迅雷网盘百度云" target="_blank">美剧《模范爱侣 》1080p超清中字2024(完美夫妻电视剧)全6集完整未删减版免费在线观看夸克网盘高清迅雷网盘百度云</a>
<span class="text-muted">全网优惠分享君</span>
<div>《模范爱侣》是一部由Netflix出品的犯罪悬疑迷你剧,共六集,以其紧凑的剧情、精湛的演技和深刻的主题吸引了众多观众的目光。该剧改编自艾琳·希尔德布兰德的同名畅销书,由苏珊娜·比尔执导,妮可·基德曼、列维·施瑞博尔、达科塔·范宁等一众实力派演员共同演绎。提示:文章排版原因,观剧资源链接地址放在文章结尾,往下翻就行故事发生在风景如画的楠塔基特岛,围绕着即将嫁入岛上最富有家族之一的阿梅莉亚·萨克斯(由</div>
</li>
<li><a href="/article/1947608582660878336.htm"
title="Three.js入门:创建第一个3D场景" target="_blank">Three.js入门:创建第一个3D场景</a>
<span class="text-muted">薯条说影</span>
<a class="tag" taget="_blank" href="/search/Three.js/1.htm">Three.js</a><a class="tag" taget="_blank" href="/search/3D%E5%9C%BA%E6%99%AF%E5%88%9B%E5%BB%BA/1.htm">3D场景创建</a><a class="tag" taget="_blank" href="/search/%E8%B7%A8%E5%B9%B3%E5%8F%B0%E8%AE%BE%E7%BD%AE/1.htm">跨平台设置</a><a class="tag" taget="_blank" href="/search/%E5%AE%89%E5%85%A8%E5%BC%82%E5%B8%B8%E5%A4%84%E7%90%86/1.htm">安全异常处理</a><a class="tag" taget="_blank" href="/search/HTML%E9%AA%A8%E6%9E%B6%E6%90%AD%E5%BB%BA/1.htm">HTML骨架搭建</a>
<div>背景简介Three.js是一个轻量级的3D图形库,它让Web开发者能够在浏览器中创建和显示3D图形。本章介绍如何设置环境以开始使用Three.js,包括不同操作系统下的安装步骤、安全异常处理以及基本的HTML骨架创建。安装与设置操作系统兼容性:Three.js的使用不仅限于Windows系统。对于其他操作系统,如Linux和MacOS,需要将可执行文件复制到目标目录,并通过命令行启动。无论是哪种操</div>
</li>
<li><a href="/article/1947604831229243392.htm"
title="备考中心面试" target="_blank">备考中心面试</a>
<span class="text-muted">海陵燕飞</span>
<div>2018.10.21古北启德备考中心面试V的主要问题是害羞,有的时候没有自信。我突然觉得这几年她的幼儿园生活太动荡,我有一丝丝愧疚,因为我的确有点折腾,外加选择困难症。好在V没有过早进入补习鸡血的大军,她还是个快乐的小朋友,这点我很自豪。期待接下去的两个半月,V我会和你一起努力。图片发自App</div>
</li>
<li><a href="/article/1947603164693852160.htm"
title="JavaScript进阶:探索模块化、ES6+与前端框架" target="_blank">JavaScript进阶:探索模块化、ES6+与前端框架</a>
<span class="text-muted">WayneYalejk</span>
<a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a><a class="tag" taget="_blank" href="/search/es6/1.htm">es6</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF%E6%A1%86%E6%9E%B6/1.htm">前端框架</a>
<div>随着Web技术的快速发展,JavaScript也在不断演进。ES6(ECMAScript2015)及更高版本的发布为JavaScript带来了许多新特性和改进,使得JavaScript更加强大和易用。同时,模块化编程和前端框架的兴起也极大地推动了前端开发的现代化进程。本文将带您深入探索JavaScript的进阶话题,包括模块化、ES6+新特性以及前端框架的应用。1.模块化编程模块化的重要性:解释模</div>
</li>
<li><a href="/article/1947600632177291264.htm"
title="零投资零风险的赚钱平台有哪些(零投资日赚100元的app)" target="_blank">零投资零风险的赚钱平台有哪些(零投资日赚100元的app)</a>
<span class="text-muted">高省APP珊珊</span>
<div>今天给大家介绍一个日赚200+的项目,手机赚钱软件之高省,分享赚钱的APP平台:购物返利省钱助手。高省APP,是2022年推出的平台,0投资,0风险、高省APP佣金更高,模式更好,终端用户不流失。【高省】是一个自用省钱佣金高,分享推广赚钱多的平台,百度有几百万篇报道,也期待你的加入。珊珊导师,高省邀请码777777,注册送2皇冠会员,送万元推广大礼包,教你如何1年做到百万团队。高省邀请码77777</div>
</li>
<li><a href="/article/1947595985240780800.htm"
title="爬虫_加速乐秒杀" target="_blank">爬虫_加速乐秒杀</a>
<span class="text-muted">kisloy</span>
<a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/%E9%80%86%E5%90%91/1.htm">逆向</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a>
<div>加速乐补环境补环境window={navigator:{userAgent:"Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/104.0.0.0Safari/537.36"},outerWidth:1920,outerHeight:1050,};location={reload:functi</div>
</li>
<li><a href="/article/1947595985811206144.htm"
title="【爬虫】某某查cookie逆向" target="_blank">【爬虫】某某查cookie逆向</a>
<span class="text-muted">kisloy</span>
<a class="tag" taget="_blank" href="/search/%E9%80%86%E5%90%91/1.htm">逆向</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a>
<div>代码仅供技术人员进行学习和研究使用,请勿将其用于非法用途或以任何方式窃取第三方数据。使用该代码产生的所有风险均由用户自行承担,作者不对用户因使用该代码而造成的任何损失或损害承担任何责任。加密参数加密参数主要是cookie,其中只有三个cookie最重要,BAIDUIDBAIDUID_BFESS和一个ab开头的cookiecookie获取BAIDUID和BAIDUID_BFESS在访问百度系的产品时</div>
</li>
<li><a href="/article/1947594406689304576.htm"
title="2024梦幻西游手游搬砖赚钱攻略,梦幻西游手游搬砖一个月能赚多少" target="_blank">2024梦幻西游手游搬砖赚钱攻略,梦幻西游手游搬砖一个月能赚多少</a>
<span class="text-muted">高省张导师</span>
<div>梦幻西游是一款回合制MMORPG类游戏,很多玩家不知道梦幻西游搬砖一天多少钱,小编整理了梦幻西游搬砖一天赚钱一览,希望能对大家有所帮助。在分享之前给大家推荐一个互联网最新导购平台(高省)买东西先上高省领取隐藏优惠券,还有高额返利,让你更优惠!大家好,我是高省APP最大团队,【高省】是一个可省钱佣金高,能赚钱有收益的平台,百度有几百万篇报道,也期待你的加入。高省邀请码520888,注册送2皇冠会员,</div>
</li>
<li><a href="/article/1947591602411204608.htm"
title="《逃脱2024》韩国电影【1080p超清韩语中字】逃脱大结局完整无删未删减版在线观看百度云/夸克网盘高清迅雷免费播放" target="_blank">《逃脱2024》韩国电影【1080p超清韩语中字】逃脱大结局完整无删未删减版在线观看百度云/夸克网盘高清迅雷免费播放</a>
<span class="text-muted">资源共享猫</span>
<div>2024年7月,一部震撼韩国影坛的动作电影《逃脱》正式上映,由李宗弼执导,实力派演员李帝勋和具教焕主演。这部影片以紧张刺激的追击故事为主线,讲述了跨越生死界线的朝鲜士兵与朝鲜保卫部军官之间展开的惊心动魄的逃脱与追捕。于是《逃脱2024》韩国电影【1080p超清韩语中字】逃脱大结局完整无删未删减版在线观看百度云/夸克网盘高清迅雷免费播放就上了呢。影片开篇,一位勇敢的朝鲜士兵在生死关头毅然选择越界,寻</div>
</li>
<li><a href="/article/1947587789264580608.htm"
title="前端使用 Vue 3,后端使用 Spring Boot 构建 Hello World 程序" target="_blank">前端使用 Vue 3,后端使用 Spring Boot 构建 Hello World 程序</a>
<span class="text-muted">天天进步2015</span>
<a class="tag" taget="_blank" href="/search/%E7%BC%96%E7%A8%8B%E6%8A%80%E5%B7%A7/1.htm">编程技巧</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/vue.js/1.htm">vue.js</a><a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/boot/1.htm">boot</a>
<div>前端使用Vue3,后端使用SpringBoot构建HelloWorld程序前端(Vue3)首先,创建一个Vue3项目。1.安装VueCLInpminstall-g@vue/cli2.创建Vue项目vuecreatefrontend在交互式提示中,选择默认的Vue3预设。3.修改App.vue在frontend/src目录下,修改App.vue文件:{{message}}{{error}}expor</div>
</li>
<li><a href="/article/1947587284941467648.htm"
title="URL GET +号后台接收成空格" target="_blank">URL GET +号后台接收成空格</a>
<span class="text-muted">墨着染霜华</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/vue/1.htm">vue</a>
<div>问题:参数spdm=whbs+001其中包含URL特殊符号如果用GET请求方式不做任何不处理那么浏览器自动将+转为%20请求链接为details?spdm=whbs%20001&limitKcysType=1后台接收到的参数为whbs001,自动将+号转成空格了。尝试解决(失败):前端URLENCODE然后后台解密params:{spdm:encodeURIComponent(this.spdm)</div>
</li>
<li><a href="/article/1947585252465635328.htm"
title="陈嘉桦《今夜一起为爱鼓掌》台剧全12集完结大结局资源夸克百度网盘在线观看播放步骤" target="_blank">陈嘉桦《今夜一起为爱鼓掌》台剧全12集完结大结局资源夸克百度网盘在线观看播放步骤</a>
<span class="text-muted">小小编007</span>
<div>《今夜一起为爱鼓掌》作为一部近期备受瞩目的台剧,它不仅以其独特的剧名吸引了观众的眼球,更通过细腻的情感描绘与深刻的社会议题探讨,赢得了广泛的讨论与好评。该剧巧妙地将爱情、友情、家庭以及个人成长等多重元素交织在一起,构建了一个既温馨又略带苦涩的情感世界。提示:文章排版原因,观剧资源链接地址放在文章结尾,往下翻就行首先,剧名《今夜一起为爱鼓掌》虽略带诙谐,实则是对现代爱情观的一次深刻反思。剧中人物在面</div>
</li>
<li><a href="/article/1947584006119813120.htm"
title="软件测试面试?太简单了 2025测试面经 (答案+思路+史上最全)" target="_blank">软件测试面试?太简单了 2025测试面经 (答案+思路+史上最全)</a>
<span class="text-muted">软件测试雪儿</span>
<a class="tag" taget="_blank" href="/search/%E8%BD%AF%E4%BB%B6%E6%B5%8B%E8%AF%95/1.htm">软件测试</a><a class="tag" taget="_blank" href="/search/%E8%87%AA%E5%8A%A8%E5%8C%96%E6%B5%8B%E8%AF%95/1.htm">自动化测试</a><a class="tag" taget="_blank" href="/search/%E9%9D%A2%E8%AF%95/1.htm">面试</a><a class="tag" taget="_blank" href="/search/%E9%9D%A2%E8%AF%95/1.htm">面试</a><a class="tag" taget="_blank" href="/search/%E8%81%8C%E5%9C%BA%E5%92%8C%E5%8F%91%E5%B1%95/1.htm">职场和发展</a>
<div>从年后开始投简历面试的,在boss和拉钩上投了有几十份简历,其中70%未读状态,30%已读,已读的一半回复要求发送附件简历,然后这周接到面试的有七、八家公司,所以,当前这个大环境真的难这半个月来,每天安排三到四场面试,平均每个公司至少都是两轮面试打底,经此一役,截止今天下午,算是拿到四个offer,两个已经发了,两个口头约定好了。个人比较心仪其中的一家外企,毕竟不太卷,真的国内的互联网公司真的卷怕</div>
</li>
<li><a href="/article/1947583879778988032.htm"
title="全网最全,软件测试-性能测试面试题汇总(附答案)" target="_blank">全网最全,软件测试-性能测试面试题汇总(附答案)</a>
<span class="text-muted">软件测试雪儿</span>
<a class="tag" taget="_blank" href="/search/%E8%BD%AF%E4%BB%B6%E6%B5%8B%E8%AF%95/1.htm">软件测试</a><a class="tag" taget="_blank" href="/search/%E9%9D%A2%E8%AF%95/1.htm">面试</a><a class="tag" taget="_blank" href="/search/%E8%BD%AF%E4%BB%B6%E6%B5%8B%E8%AF%95/1.htm">软件测试</a><a class="tag" taget="_blank" href="/search/%E9%9D%A2%E8%AF%95/1.htm">面试</a>
<div>前言面试题:性能测试指标有哪些?分别是什么含义?tps:每秒事务量,代表了系统的处理能力,tps越高,性能越好响应时间:从发出请求到接受到系统响应数据所花费的时间,响应时间越短,性能越好吞吐量:网络上行和下行流量的总和,吞吐量是网络瓶颈定位的重要指标错误率:在压测过程中系统出现错误的比例面试题:什么是集合点,什么场景下需要用集合点?集合点是测试脚本中的一个标记,当每个虚拟用户执行到标记处时,会停留</div>
</li>
<li><a href="/article/1947575989064232960.htm"
title="保湿效果好的身体乳排行榜,亲测好用又保湿的身体乳排名前五名推荐" target="_blank">保湿效果好的身体乳排行榜,亲测好用又保湿的身体乳排名前五名推荐</a>
<span class="text-muted">高省APP珊珊</span>
<div>身体乳可以说是身体肌肤保养的必备护肤品,但很多女生往往都不重视它。其实和我们的小脸蛋一样,身体肌肤也同样需要滋润呵护的,要争做360度无死角滑溜溜的美少女哇!高省APP,是2021年推出的平台,0投资,0风险、高省APP佣金更高,模式更好,终端用户不流失。【高省】是一个自用省钱佣金高,分享推广赚钱多的平台,百度有几百万篇报道,也期待你的加入。珊珊导师,高省邀请码666123,注册送2皇冠会员,送万</div>
</li>
<li><a href="/article/1947573543596257280.htm"
title="从零入门 HTML 开发:构建网页世界的基石指南" target="_blank">从零入门 HTML 开发:构建网页世界的基石指南</a>
<span class="text-muted">incidite</span>
<a class="tag" taget="_blank" href="/search/html/1.htm">html</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a>
<div>从零入门HTML开发:构建网页世界的基石指南在互联网蓬勃发展的今天,我们每天浏览的网页、使用的App界面,背后都离不开HTML这一基础技术的支撑。作为前端开发的入门语言,HTML(超文本标记语言)就像建筑中的砖石,是构建网页骨架的核心。无论你是想成为专业的前端工程师,还是单纯想了解网页背后的运作原理,掌握HTML基础都是迈出的第一步。认识HTML:网页的“骨架”语言HTML的全称为HyperTex</div>
</li>
<li><a href="/article/1947571652640436224.htm"
title="Taro 网络 API 详解与实用案例" target="_blank">Taro 网络 API 详解与实用案例</a>
<span class="text-muted"></span>
<div>Taro网络API详解与实用案例在现代前端开发中,网络通信是不可或缺的一环。Taro作为一款多端开发框架,提供了丰富且统一的网络API,帮助开发者在小程序、H5、ReactNative等多端环境下高效地进行数据交互。本文将详细介绍Taro的四大网络API:Taro.request、Taro.uploadFile、Taro.downloadFile和Taro.connectSocket,并结合实际案</div>
</li>
<li><a href="/article/1947571149412036608.htm"
title="“美逛”是什么?怎么邀请赚钱?" target="_blank">“美逛”是什么?怎么邀请赚钱?</a>
<span class="text-muted">古楼</span>
<div>今天古楼导师要分享的是一个新上线的购物返利平台,目前有权利人再推,我也很好奇的下载了这个APP,全流程体验了下。这个APP叫“美逛”至于我为何从美逛转到高省APP佣金更高,模式更好,终端用户不流失。【高省】是一个自用省钱佣金高,分享推广赚钱多的平台,百度有几百万篇报道,也期待你的加入。古楼导师高省邀请码555888,注册送2皇冠会员,送万元推广大礼包,教你如何1年做到百万团队。一、美逛APP是什么</div>
</li>
<li><a href="/article/1947565477190496256.htm"
title="网站藏着的「机器人红绿灯」:5 分钟看懂 Robots 协议" target="_blank">网站藏着的「机器人红绿灯」:5 分钟看懂 Robots 协议</a>
<span class="text-muted">incidite</span>
<a class="tag" taget="_blank" href="/search/%E6%9C%BA%E5%99%A8%E4%BA%BA/1.htm">机器人</a>
<div>你有没有想过:当搜索引擎爬取网站时,是谁在指挥它们“该去哪、不该去哪”?答案就藏在一个名叫Robots协议的简单规则里。这个看似神秘的技术,其实就像网站门口的“交通信号灯”,用几句明文代码就能规范爬虫的行为。今天,我们用5分钟揭开它的面纱,新手也能轻松掌握。什么是Robots协议?简单说,Robots协议是网站给搜索引擎爬虫看的“说明书”。它通过一个名为robots.txt的文本文件,告诉爬虫哪些</div>
</li>
<li><a href="/article/1947559837671944192.htm"
title="对标ChatGPT,「文心一言」今日亮相!AI人机时代来临,未来在何方?" target="_blank">对标ChatGPT,「文心一言」今日亮相!AI人机时代来临,未来在何方?</a>
<span class="text-muted">AI医学</span>
<div>本文由「AI医学er」提供医海无涯,AI同舟。关注我们,助力高效科研。3月15日,OpenAI公布了其大型语言模型的最新版本——GPT-4。3月16日,百度文心一言人工智能聊天机器人正式上线。一个时代开始了。OpenAI在官网表示,GPT-4是一个能接受图像和文本输入,并输出文本的多模态模型,是OpenAI在扩展深度学习方面的最新成果。此前的ChatGPT,只能通过向其输入文字提问才能生成文字回答</div>
</li>
<li><a href="/article/1947559710395789312.htm"
title="2024车胜元韩剧《暴君》全集【1080p超清韩语中字】网盘资源(百度云夸克迅雷无删节版)视频免费在线观看大全" target="_blank">2024车胜元韩剧《暴君》全集【1080p超清韩语中字】网盘资源(百度云夸克迅雷无删节版)视频免费在线观看大全</a>
<span class="text-muted">帮忙赚赏金</span>
<div>《暴君》(폭군/TheTyrant)是一部由朴勋政执导并编剧,车胜元、金宣虎、金康宇、赵允秀主演的韩国动作剧集。该剧于2024年8月14日首播,共4集,讲述了围绕名为“暴君计划”的超人基因药物的最后样品展开的一场追逐战。金宣虎在剧中饰演主导“暴君计划”的局长“崔国章”,而车胜元则饰演负责铲除与该计划相关势力的前任要员“林尚”。暴君全集(尽快保存,随时失效)链接:https://pan.quark.</div>
</li>
<li><a href="/article/1947559426240081920.htm"
title="Redis面试精讲 Day 4:Redis事务与原子性保证" target="_blank">Redis面试精讲 Day 4:Redis事务与原子性保证</a>
<span class="text-muted">在未来等你</span>
<a class="tag" taget="_blank" href="/search/Redis%E9%9D%A2%E8%AF%95%E4%B8%93%E6%A0%8F/1.htm">Redis面试专栏</a><a class="tag" taget="_blank" href="/search/Redis/1.htm">Redis</a><a class="tag" taget="_blank" href="/search/%E9%9D%A2%E8%AF%95/1.htm">面试</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/%E7%BC%93%E5%AD%98/1.htm">缓存</a>
<div>【Redis面试精讲Day4】Redis事务与原子性保证开篇欢迎来到"Redis面试精讲"系列的第4天!今天我们将深入探讨Redis的事务机制与原子性保证,这是Redis面试中出现频率极高的核心知识点。掌握Redis事务不仅能帮助你在面试中脱颖而出,更能让你在实际开发中合理利用事务特性构建可靠的分布式系统。在面试中,面试官通常会通过以下方式考察候选人对Redis事务的理解:解释Redis事务的基本</div>
</li>
<li><a href="/article/1947558922462228480.htm"
title="实现一个HTML页面,上传图片后可以测量两条辅助线之间的距离,支持点击添加、拖动和右键删除辅助线" target="_blank">实现一个HTML页面,上传图片后可以测量两条辅助线之间的距离,支持点击添加、拖动和右键删除辅助线</a>
<span class="text-muted"></span>
<div>一、项目背景偶尔需要测量图片上元素的宽度高度和间距。因此实现一个交互式、可视化的测距工具。开发一个简单易用的HTML页面,用户可以上传任意图片,在图片上通过点击添加辅助线,拖动调整辅助线位置,右键删除不需要的辅助线,同时自动计算并显示相邻辅助线间的距离,提升效率和准确度。二、核心功能图片上传用户可以上传本地图片作为测距背景,图片会按用户指定的宽高展示,支持任意尺寸,不做限制。辅助线添加用户点击图片</div>
</li>
<li><a href="/article/1947557935617994752.htm"
title="5. 移动端适配rem方案" target="_blank">5. 移动端适配rem方案</a>
<span class="text-muted">未路过</span>
<div>1.rem+动态html的font-sizerem单位是相对于html元素的font-size来设置的,那么如果我们需要在不同的屏幕下有不同的尺寸,可以动态的修改html的font-size尺寸。比如如下案例:1.设置一个盒子的宽度是2rem;2.设置不同的屏幕上html的font-size不同;image.png这样在开发中,我们只需要考虑两个问题:问题一:针对不同的屏幕,设置html不同的fo</div>
</li>
<li><a href="/article/1947555015702933504.htm"
title="centos7常用的国内yum源整理" target="_blank">centos7常用的国内yum源整理</a>
<span class="text-muted">inrgihc</span>
<a class="tag" taget="_blank" href="/search/Linux/1.htm">Linux</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a>
<div>清华大学yum源参考地址:https://mirrors.tuna.tsinghua.edu.cn/help/centos/网易yum源参考地址:http://mirrors.163.com/.help/centos.htmlyum-yinstallwgetrm-rf/etc/yum.repo.d/*wget-O/etc/yum.repos.d/CentOS-Base.repohttp://mir</div>
</li>
<li><a href="/article/1947554259331510272.htm"
title="Vite:下一代前端构建工具的革命" target="_blank">Vite:下一代前端构建工具的革命</a>
<span class="text-muted">布兰妮甜</span>
<a class="tag" taget="_blank" href="/search/vite/1.htm">vite</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/%E6%9E%84%E5%BB%BA%E5%B7%A5%E5%85%B7/1.htm">构建工具</a>
<div>Hi,我是布兰妮甜!在现代前端开发领域,构建工具的选择对开发体验和项目效率有着决定性影响。从早期的Grunt、Gulp到Webpack、Rollup,前端构建工具不断演进。而Vite的出现,则彻底改变了传统构建工具的工作模式,为开发者带来了前所未有的开发体验。本文将深入探讨Vite的设计哲学、核心特性、工作原理以及实际应用场景。文章目录一、什么是Vite?二、Vite的核心设计理念2.1利用浏览器</div>
</li>
<li><a href="/article/1947553743394369536.htm"
title="ChatGPT 与 AIGC 简问乱答" target="_blank">ChatGPT 与 AIGC 简问乱答</a>
<span class="text-muted">MatrixOnEarth</span>
<div>ChatGPT与AIGC简问乱答**仅代表个人观点。**[Q1]ChatGPT最近非常火爆,2个月突破1亿月活,从产品形态来看,我们知道的微软、谷歌的搜索引擎都会嵌入。那么我们如何看待它的用户粘性,真的会有那么多人持续使用吗还是说只是一阵热潮?[A1]首先,工业界长久以来对搜索引擎的最终产品形态的定义是:信息问答助理。目前的信息检索黄页的产品形态个人认为其实是在技术发展未能满足最终产品形态目标的情</div>
</li>
<li><a href="/article/1947553628831150080.htm"
title="MEMS定向短节的作用如何在HDD中体现?" target="_blank">MEMS定向短节的作用如何在HDD中体现?</a>
<span class="text-muted">ericco123</span>
<a class="tag" taget="_blank" href="/search/MEMS/1.htm">MEMS</a><a class="tag" taget="_blank" href="/search/%E9%99%80%E8%9E%BA%E4%BB%AA/1.htm">陀螺仪</a><a class="tag" taget="_blank" href="/search/%E6%83%AF%E6%80%A7%E6%8A%80%E6%9C%AF/1.htm">惯性技术</a><a class="tag" taget="_blank" href="/search/%E5%88%B6%E9%80%A0/1.htm">制造</a><a class="tag" taget="_blank" href="/search/%E7%A7%91%E6%8A%80/1.htm">科技</a>
<div>ER-MNS-09作为一款基于MEMS陀螺技术的定向短节,其异形圆柱体设计(直径30mm,长度120mm)使其能适配探管等钻探设备前端的有限空间。其核心在于采用可自寻北的高精度MEMS陀螺仪,摆脱了对地磁场的依赖。这一特性对于HDD至关重要,因其常在埋地管线、强电磁干扰或金属结构密集区域施工,传统磁传感器易受干扰失效,而ER-MNS-09能在此类复杂地下环境中提供稳定、可靠的方位基准。在HDD管道</div>
</li>
<li><a href="/article/1947549909183950848.htm"
title="2024最新韩剧《无声蛙鸣》全集【1080p超清韩语中字】无声蛙鸣完整无删未删减版百度云/夸克迅雷网盘资源免费在线播放" target="_blank">2024最新韩剧《无声蛙鸣》全集【1080p超清韩语中字】无声蛙鸣完整无删未删减版百度云/夸克迅雷网盘资源免费在线播放</a>
<span class="text-muted">全网优惠分享</span>
<div>2024最新韩剧《无声蛙鸣》全集【1080p超清韩语中字】无声蛙鸣完整无删未删减版百度云/夸克迅雷网盘资源免费在线播放《无声蛙鸣》是一部由牟完日执导,金伦奭、尹启相、高旻示、李姃垠等主演的Netflix韩剧。这部剧集以其独特的叙事手法、扣人心弦的剧情和黄金阵容的精湛演技,引发了全球观众的热烈关注。剧集围绕一家汽车旅店和一家民宿展开,讲述了两个男人——全煐夏(金伦奭饰)与具相俊(尹启相饰)各自经历的</div>
</li>
<li><a href="/article/102.htm"
title="xml解析" target="_blank">xml解析</a>
<span class="text-muted">小猪猪08</span>
<a class="tag" taget="_blank" href="/search/xml/1.htm">xml</a>
<div>1、DOM解析的步奏
准备工作:
1.创建DocumentBuilderFactory的对象
2.创建DocumentBuilder对象
3.通过DocumentBuilder对象的parse(String fileName)方法解析xml文件
4.通过Document的getElem</div>
</li>
<li><a href="/article/229.htm"
title="每个开发人员都需要了解的一个SQL技巧" target="_blank">每个开发人员都需要了解的一个SQL技巧</a>
<span class="text-muted">brotherlamp</span>
<a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/linux%E8%A7%86%E9%A2%91/1.htm">linux视频</a><a class="tag" taget="_blank" href="/search/linux%E6%95%99%E7%A8%8B/1.htm">linux教程</a><a class="tag" taget="_blank" href="/search/linux%E8%87%AA%E5%AD%A6/1.htm">linux自学</a><a class="tag" taget="_blank" href="/search/linux%E8%B5%84%E6%96%99/1.htm">linux资料</a>
<div>
对于数据过滤而言CHECK约束已经算是相当不错了。然而它仍存在一些缺陷,比如说它们是应用到表上面的,但有的时候你可能希望指定一条约束,而它只在特定条件下才生效。
使用SQL标准的WITH CHECK OPTION子句就能完成这点,至少Oracle和SQL Server都实现了这个功能。下面是实现方式:
CREATE TABLE books (
id &</div>
</li>
<li><a href="/article/356.htm"
title="Quartz——CronTrigger触发器" target="_blank">Quartz——CronTrigger触发器</a>
<span class="text-muted">eksliang</span>
<a class="tag" taget="_blank" href="/search/quartz/1.htm">quartz</a><a class="tag" taget="_blank" href="/search/CronTrigger/1.htm">CronTrigger</a>
<div>转载请出自出处:http://eksliang.iteye.com/blog/2208295 一.概述
CronTrigger 能够提供比 SimpleTrigger 更有具体实际意义的调度方案,调度规则基于 Cron 表达式,CronTrigger 支持日历相关的重复时间间隔(比如每月第一个周一执行),而不是简单的周期时间间隔。 二.Cron表达式介绍 1)Cron表达式规则表
Quartz</div>
</li>
<li><a href="/article/483.htm"
title="Informatica基础" target="_blank">Informatica基础</a>
<span class="text-muted">18289753290</span>
<a class="tag" taget="_blank" href="/search/Informatica/1.htm">Informatica</a><a class="tag" taget="_blank" href="/search/Monitor/1.htm">Monitor</a><a class="tag" taget="_blank" href="/search/manager/1.htm">manager</a><a class="tag" taget="_blank" href="/search/workflow/1.htm">workflow</a><a class="tag" taget="_blank" href="/search/Designer/1.htm">Designer</a>
<div>1.
1)PowerCenter Designer:设计开发环境,定义源及目标数据结构;设计转换规则,生成ETL映射。
2)Workflow Manager:合理地实现复杂的ETL工作流,基于时间,事件的作业调度
3)Workflow Monitor:监控Workflow和Session运行情况,生成日志和报告
4)Repository Manager:</div>
</li>
<li><a href="/article/610.htm"
title="linux下为程序创建启动和关闭的的sh文件,scrapyd为例" target="_blank">linux下为程序创建启动和关闭的的sh文件,scrapyd为例</a>
<span class="text-muted">酷的飞上天空</span>
<a class="tag" taget="_blank" href="/search/scrapy/1.htm">scrapy</a>
<div>对于一些未提供service管理的程序 每次启动和关闭都要加上全部路径,想到可以做一个简单的启动和关闭控制的文件
下面以scrapy启动server为例,文件名为run.sh:
#端口号,根据此端口号确定PID
PORT=6800
#启动命令所在目录
HOME='/home/jmscra/scrapy/'
#查询出监听了PORT端口</div>
</li>
<li><a href="/article/737.htm"
title="人--自私与无私" target="_blank">人--自私与无私</a>
<span class="text-muted">永夜-极光</span>
<div> 今天上毛概课,老师提出一个问题--人是自私的还是无私的,根源是什么?
从客观的角度来看,人有自私的行为,也有无私的</div>
</li>
<li><a href="/article/864.htm"
title="Ubuntu安装NS-3 环境脚本" target="_blank">Ubuntu安装NS-3 环境脚本</a>
<span class="text-muted">随便小屋</span>
<a class="tag" taget="_blank" href="/search/ubuntu/1.htm">ubuntu</a>
<div>
将附件下载下来之后解压,将解压后的文件ns3environment.sh复制到下载目录下(其实放在哪里都可以,就是为了和我下面的命令相统一)。输入命令:
sudo ./ns3environment.sh >>result
这样系统就自动安装ns3的环境,运行的结果在result文件中,如果提示
com</div>
</li>
<li><a href="/article/991.htm"
title="创业的简单感受" target="_blank">创业的简单感受</a>
<span class="text-muted">aijuans</span>
<a class="tag" taget="_blank" href="/search/%E5%88%9B%E4%B8%9A%E7%9A%84%E7%AE%80%E5%8D%95%E6%84%9F%E5%8F%97/1.htm">创业的简单感受</a>
<div>
2009年11月9日我进入a公司实习,2012年4月26日,我离开a公司,开始自己的创业之旅。
今天是2012年5月30日,我忽然很想谈谈自己创业一个月的感受。
当初离开边锋时,我就对自己说:“自己选择的路,就是跪着也要把他走完”,我也做好了心理准备,准备迎接一次次的困难。我这次走出来,不管成败</div>
</li>
<li><a href="/article/1118.htm"
title="如何经营自己的独立人脉" target="_blank">如何经营自己的独立人脉</a>
<span class="text-muted">aoyouzi</span>
<a class="tag" taget="_blank" href="/search/%E5%A6%82%E4%BD%95%E7%BB%8F%E8%90%A5%E8%87%AA%E5%B7%B1%E7%9A%84%E7%8B%AC%E7%AB%8B%E4%BA%BA%E8%84%89/1.htm">如何经营自己的独立人脉</a>
<div>独立人脉不是父母、亲戚的人脉,而是自己主动投入构造的人脉圈。“放长线,钓大鱼”,先行投入才能产生后续产出。 现在几乎做所有的事情都需要人脉。以银行柜员为例,需要拉储户,而其本质就是社会人脉,就是社交!很多人都说,人脉我不行,因为我爸不行、我妈不行、我姨不行、我舅不行……我谁谁谁都不行,怎么能建立人脉?我这里说的人脉,是你的独立人脉。 以一个普通的银行柜员</div>
</li>
<li><a href="/article/1245.htm"
title="JSP基础" target="_blank">JSP基础</a>
<span class="text-muted">百合不是茶</span>
<a class="tag" taget="_blank" href="/search/jsp/1.htm">jsp</a><a class="tag" taget="_blank" href="/search/%E6%B3%A8%E9%87%8A/1.htm">注释</a><a class="tag" taget="_blank" href="/search/%E9%9A%90%E5%BC%8F%E5%AF%B9%E8%B1%A1/1.htm">隐式对象</a>
<div>
1,JSP语句的声明
<%! 声明 %> 声明:这个就是提供java代码声明变量、方法等的场所。
表达式 <%= 表达式 %> 这个相当于赋值,可以在页面上显示表达式的结果,
程序代码段/小型指令 <% 程序代码片段 %>
2,JSP的注释
<!-- --> </div>
</li>
<li><a href="/article/1372.htm"
title="web.xml之session-config、mime-mapping" target="_blank">web.xml之session-config、mime-mapping</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/web.xml/1.htm">web.xml</a><a class="tag" taget="_blank" href="/search/servlet/1.htm">servlet</a><a class="tag" taget="_blank" href="/search/session-config/1.htm">session-config</a><a class="tag" taget="_blank" href="/search/mime-mapping/1.htm">mime-mapping</a>
<div>session-config
1.定义:
<session-config>
<session-timeout>20</session-timeout>
</session-config>
2.作用:用于定义整个WEB站点session的有效期限,单位是分钟。
mime-mapping
1.定义:
<mime-m</div>
</li>
<li><a href="/article/1499.htm"
title="互联网开放平台(1)" target="_blank">互联网开放平台(1)</a>
<span class="text-muted">Bill_chen</span>
<a class="tag" taget="_blank" href="/search/%E4%BA%92%E8%81%94%E7%BD%91/1.htm">互联网</a><a class="tag" taget="_blank" href="/search/qq/1.htm">qq</a><a class="tag" taget="_blank" href="/search/%E6%96%B0%E6%B5%AA%E5%BE%AE%E5%8D%9A/1.htm">新浪微博</a><a class="tag" taget="_blank" href="/search/%E7%99%BE%E5%BA%A6/1.htm">百度</a><a class="tag" taget="_blank" href="/search/%E8%85%BE%E8%AE%AF/1.htm">腾讯</a>
<div>现在各互联网公司都推出了自己的开放平台供用户创造自己的应用,互联网的开放技术欣欣向荣,自己总结如下:
1.淘宝开放平台(TOP)
网址:http://open.taobao.com/
依赖淘宝强大的电子商务数据,将淘宝内部业务数据作为API开放出去,同时将外部ISV的应用引入进来。
目前TOP的三条主线:
TOP访问网站:open.taobao.com
ISV后台:my.open.ta</div>
</li>
<li><a href="/article/1626.htm"
title="【MongoDB学习笔记九】MongoDB索引" target="_blank">【MongoDB学习笔记九】MongoDB索引</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/mongodb/1.htm">mongodb</a>
<div>索引
可以在任意列上建立索引
索引的构造和使用与传统关系型数据库几乎一样,适用于Oracle的索引优化技巧也适用于Mongodb
使用索引可以加快查询,但同时会降低修改,插入等的性能
内嵌文档照样可以建立使用索引
测试数据
var p1 = {
"name":"Jack",
"age&q</div>
</li>
<li><a href="/article/1753.htm"
title="JDBC常用API之外的总结" target="_blank">JDBC常用API之外的总结</a>
<span class="text-muted">白糖_</span>
<a class="tag" taget="_blank" href="/search/jdbc/1.htm">jdbc</a>
<div> 做JAVA的人玩JDBC肯定已经很熟练了,像DriverManager、Connection、ResultSet、Statement这些基本类大家肯定很常用啦,我不赘述那些诸如注册JDBC驱动、创建连接、获取数据集的API了,在这我介绍一些写框架时常用的API,大家共同学习吧。
ResultSetMetaData获取ResultSet对象的元数据信息
</div>
</li>
<li><a href="/article/1880.htm"
title="apache VelocityEngine使用记录" target="_blank">apache VelocityEngine使用记录</a>
<span class="text-muted">bozch</span>
<a class="tag" taget="_blank" href="/search/VelocityEngine/1.htm">VelocityEngine</a>
<div>VelocityEngine是一个模板引擎,能够基于模板生成指定的文件代码。
使用方法如下:
VelocityEngine engine = new VelocityEngine();// 定义模板引擎
Properties properties = new Properties();// 模板引擎属</div>
</li>
<li><a href="/article/2007.htm"
title="编程之美-快速找出故障机器" target="_blank">编程之美-快速找出故障机器</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/%E7%BC%96%E7%A8%8B%E4%B9%8B%E7%BE%8E/1.htm">编程之美</a>
<div>
package beautyOfCoding;
import java.util.Arrays;
public class TheLostID {
/*编程之美
假设一个机器仅存储一个标号为ID的记录,假设机器总量在10亿以下且ID是小于10亿的整数,假设每份数据保存两个备份,这样就有两个机器存储了同样的数据。
1.假设在某个时间得到一个数据文件ID的列表,是</div>
</li>
<li><a href="/article/2134.htm"
title="关于Java中redirect与forward的区别" target="_blank">关于Java中redirect与forward的区别</a>
<span class="text-muted">chenbowen00</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/servlet/1.htm">servlet</a>
<div>在Servlet中两种实现:
forward方式:request.getRequestDispatcher(“/somePage.jsp”).forward(request, response);
redirect方式:response.sendRedirect(“/somePage.jsp”);
forward是服务器内部重定向,程序收到请求后重新定向到另一个程序,客户机并不知</div>
</li>
<li><a href="/article/2261.htm"
title="[信号与系统]人体最关键的两个信号节点" target="_blank">[信号与系统]人体最关键的两个信号节点</a>
<span class="text-muted">comsci</span>
<a class="tag" taget="_blank" href="/search/%E7%B3%BB%E7%BB%9F/1.htm">系统</a>
<div>
如果把人体看做是一个带生物磁场的导体,那么这个导体有两个很重要的节点,第一个在头部,中医的名称叫做 百汇穴, 另外一个节点在腰部,中医的名称叫做 命门
如果要保护自己的脑部磁场不受到外界有害信号的攻击,最简单的</div>
</li>
<li><a href="/article/2388.htm"
title="oracle 存储过程执行权限" target="_blank">oracle 存储过程执行权限</a>
<span class="text-muted">daizj</span>
<a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/%E5%AD%98%E5%82%A8%E8%BF%87%E7%A8%8B/1.htm">存储过程</a><a class="tag" taget="_blank" href="/search/%E6%9D%83%E9%99%90/1.htm">权限</a><a class="tag" taget="_blank" href="/search/%E6%89%A7%E8%A1%8C%E8%80%85/1.htm">执行者</a><a class="tag" taget="_blank" href="/search/%E8%B0%83%E7%94%A8%E8%80%85/1.htm">调用者</a>
<div>在数据库系统中存储过程是必不可少的利器,存储过程是预先编译好的为实现一个复杂功能的一段Sql语句集合。它的优点我就不多说了,说一下我碰到的问题吧。我在项目开发的过程中需要用存储过程来实现一个功能,其中涉及到判断一张表是否已经建立,没有建立就由存储过程来建立这张表。
CREATE OR REPLACE PROCEDURE TestProc
IS
fla</div>
</li>
<li><a href="/article/2515.htm"
title="为mysql数据库建立索引" target="_blank">为mysql数据库建立索引</a>
<span class="text-muted">dengkane</span>
<a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a><a class="tag" taget="_blank" href="/search/%E6%80%A7%E8%83%BD/1.htm">性能</a><a class="tag" taget="_blank" href="/search/%E7%B4%A2%E5%BC%95/1.htm">索引</a>
<div>前些时候,一位颇高级的程序员居然问我什么叫做索引,令我感到十分的惊奇,我想这绝不会是沧海一粟,因为有成千上万的开发者(可能大部分是使用MySQL的)都没有受过有关数据库的正规培训,尽管他们都为客户做过一些开发,但却对如何为数据库建立适当的索引所知较少,因此我起了写一篇相关文章的念头。 最普通的情况,是为出现在where子句的字段建一个索引。为方便讲述,我们先建立一个如下的表。</div>
</li>
<li><a href="/article/2642.htm"
title="学习C语言常见误区 如何看懂一个程序 如何掌握一个程序以及几个小题目示例" target="_blank">学习C语言常见误区 如何看懂一个程序 如何掌握一个程序以及几个小题目示例</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/c/1.htm">c</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a>
<div>如果看懂一个程序,分三步
1、流程
2、每个语句的功能
3、试数
如何学习一些小算法的程序
尝试自己去编程解决它,大部分人都自己无法解决
如果解决不了就看答案
关键是把答案看懂,这个是要花很大的精力,也是我们学习的重点
看懂之后尝试自己去修改程序,并且知道修改之后程序的不同输出结果的含义
照着答案去敲
调试错误
</div>
</li>
<li><a href="/article/2769.htm"
title="centos6.3安装php5.4报错" target="_blank">centos6.3安装php5.4报错</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/centos6/1.htm">centos6</a>
<div>报错内容如下:
Resolving Dependencies
--> Running transaction check
---> Package php54w.x86_64 0:5.4.38-1.w6 will be installed
--> Processing Dependency: php54w-common(x86-64) = 5.4.38-1.w6 for </div>
</li>
<li><a href="/article/2896.htm"
title="JSONP请求" target="_blank">JSONP请求</a>
<span class="text-muted">flyer0126</span>
<a class="tag" taget="_blank" href="/search/jsonp/1.htm">jsonp</a>
<div>
使用jsonp不能发起POST请求。
It is not possible to make a JSONP POST request.
JSONP works by creating a <script> tag that executes Javascript from a different domain; it is not pos</div>
</li>
<li><a href="/article/3023.htm"
title="Spring Security(03)——核心类简介" target="_blank">Spring Security(03)——核心类简介</a>
<span class="text-muted">234390216</span>
<a class="tag" taget="_blank" href="/search/Authentication/1.htm">Authentication</a>
<div>核心类简介
目录
1.1 Authentication
1.2 SecurityContextHolder
1.3 AuthenticationManager和AuthenticationProvider
1.3.1 &nb</div>
</li>
<li><a href="/article/3150.htm"
title="在CentOS上部署JAVA服务" target="_blank">在CentOS上部署JAVA服务</a>
<span class="text-muted">java--hhf</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/jdk/1.htm">jdk</a><a class="tag" taget="_blank" href="/search/centos/1.htm">centos</a><a class="tag" taget="_blank" href="/search/Java%E6%9C%8D%E5%8A%A1/1.htm">Java服务</a>
<div> 本文将介绍如何在CentOS上运行Java Web服务,其中将包括如何搭建JAVA运行环境、如何开启端口号、如何使得服务在命令执行窗口关闭后依旧运行
第一步:卸载旧Linux自带的JDK
①查看本机JDK版本
java -version
结果如下
java version "1.6.0"</div>
</li>
<li><a href="/article/3277.htm"
title="oracle、sqlserver、mysql常用函数对比[to_char、to_number、to_date]" target="_blank">oracle、sqlserver、mysql常用函数对比[to_char、to_number、to_date]</a>
<span class="text-muted">ldzyz007</span>
<a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a><a class="tag" taget="_blank" href="/search/SQL+Server/1.htm">SQL Server</a>
<div>oracle &n</div>
</li>
<li><a href="/article/3404.htm"
title="记Protocol Oriented Programming in Swift of WWDC 2015" target="_blank">记Protocol Oriented Programming in Swift of WWDC 2015</a>
<span class="text-muted">ningandjin</span>
<a class="tag" taget="_blank" href="/search/protocol/1.htm">protocol</a><a class="tag" taget="_blank" href="/search/WWDC+2015/1.htm">WWDC 2015</a><a class="tag" taget="_blank" href="/search/Swift2.0/1.htm">Swift2.0</a>
<div>其实最先朋友让我就这个题目写篇文章的时候,我是拒绝的,因为觉得苹果就是在炒冷饭, 把已经流行了数十年的OOP中的“面向接口编程”还拿来讲,看完整个Session之后呢,虽然还是觉得在炒冷饭,但是毕竟还是加了蛋的,有些东西还是值得说说的。
通常谈到面向接口编程,其主要作用是把系统设计和具体实现分离开,让系统的每个部分都可以在不影响别的部分的情况下,改变自身的具体实现。接口的设计就反映了系统</div>
</li>
<li><a href="/article/3531.htm"
title="搭建 CentOS 6 服务器(15) - Keepalived、HAProxy、LVS" target="_blank">搭建 CentOS 6 服务器(15) - Keepalived、HAProxy、LVS</a>
<span class="text-muted">rensanning</span>
<a class="tag" taget="_blank" href="/search/keepalived/1.htm">keepalived</a>
<div>(一)Keepalived
(1)安装
# cd /usr/local/src
# wget http://www.keepalived.org/software/keepalived-1.2.15.tar.gz
# tar zxvf keepalived-1.2.15.tar.gz
# cd keepalived-1.2.15
# ./configure
# make &a</div>
</li>
<li><a href="/article/3658.htm"
title="ORACLE数据库SCN和时间的互相转换" target="_blank">ORACLE数据库SCN和时间的互相转换</a>
<span class="text-muted">tomcat_oracle</span>
<a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/sql/1.htm">sql</a>
<div>SCN(System Change Number 简称 SCN)是当Oracle数据库更新后,由DBMS自动维护去累积递增的一个数字,可以理解成ORACLE数据库的时间戳,从ORACLE 10G开始,提供了函数可以实现SCN和时间进行相互转换;
用途:在进行数据库的还原和利用数据库的闪回功能时,进行SCN和时间的转换就变的非常必要了;
操作方法: 1、通过dbms_f</div>
</li>
<li><a href="/article/3785.htm"
title="Spring MVC 方法注解拦截器" target="_blank">Spring MVC 方法注解拦截器</a>
<span class="text-muted">xp9802</span>
<a class="tag" taget="_blank" href="/search/spring+mvc/1.htm">spring mvc</a>
<div>应用场景,在方法级别对本次调用进行鉴权,如api接口中有个用户唯一标示accessToken,对于有accessToken的每次请求可以在方法加一个拦截器,获得本次请求的用户,存放到request或者session域。
python中,之前在python flask中可以使用装饰器来对方法进行预处理,进行权限处理
先看一个实例,使用@access_required拦截:
? </div>
</li>
</ul>
</div>
</div>
</div>
<div>
<div class="container">
<div class="indexes">
<strong>按字母分类:</strong>
<a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a
href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a
href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a
href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a
href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a
href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a
href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a
href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a
href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a>
</div>
</div>
</div>
<footer id="footer" class="mb30 mt30">
<div class="container">
<div class="footBglm">
<a target="_blank" href="/">首页</a> -
<a target="_blank" href="/custom/about.htm">关于我们</a> -
<a target="_blank" href="/search/Java/1.htm">站内搜索</a> -
<a target="_blank" href="/sitemap.txt">Sitemap</a> -
<a target="_blank" href="/custom/delete.htm">侵权投诉</a>
</div>
<div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved.
<!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>-->
</div>
</div>
</footer>
<!-- 代码高亮 -->
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script>
<link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/>
<script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script>
</body>
</html>