深度学习论文笔记(增量学习)——Large Scale Incremental Learning
文章目录
- 前言
- 主要工作
- 算法介绍
-
- 总体流程
- 步骤一:训练CNN模型
-
- loss函数介绍
- 阶段二:训练偏置纠正层
-
- 实验:分类器是否出现分类偏好
-
- 猜测
- 实验
- 引入Bias Correction Layer
- 实验
- Ablation Study
前言
我将看过的增量学习论文建了一个github库,方便各位阅读,地址
主要工作
在大型数据集上,现有的增量学习方法的准确率都不高,归结于两个原因
- 在大型数据集上利用 e x a m p l a r examplar examplar进行增量学习,类别不平衡的问题会随着增量学习次数的增加而变得愈加严重。
- 大型数据集上存在许多相似的类别,类别不平衡下很难区分相似类别。
论文发现类别不平衡会导致全连接层分类器出现分类偏好,由此在全连接层后引入一个偏置纠正层,来尽可能抵消偏好现象,该方法称为BiC算法,在ImageNet100与ImageNet1000上的表现惊人。
算法介绍
总体流程

数据分为旧类别数据与新类别数据,旧类别数据远少于新类别数据,旧类别数据分为两部分 t r a i n o l d 、 v a l o l d train_{old}、val_{old} trainold、valold,新类别数据也分为两部分 t r a i n n e w 、 v a l n e w train_{new}、val_{new} trainnew、valnew
总体分为两个阶段
阶段一:使用 t r a i n o l d 、 t r a i n n e w train_{old}、train_{new} trainold、trainnew训练CNN模型
阶段二:使用 v a l o l d 、 v a l n e w val_{old}、val_{new} valold、valnew训练偏置纠正层
步骤一:训练CNN模型
按国际惯例,这部分会介绍训练CNN模型的loss函数,还是一如既往的知识蒸馏loss,配方没变
首先是训练数据的整合,用 X n ^ \hat{X^n} Xn^表示 e x a m p l a r examplar examplar中的 n n n类旧类别数据集合, X m X^m Xm表示 m m m类新类别的数据集合
loss函数介绍

o n + m ( x ) o^{n+m}(x) on+m(x)与 o ^ n ( x ) \hat o^{n}(x) o^n(x)函数表示新旧模型的输出,按国际惯例,classification loss采用交叉熵,如下:
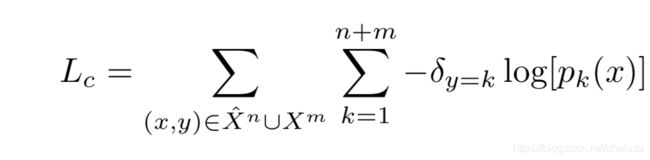
distillation loss的定义如下:
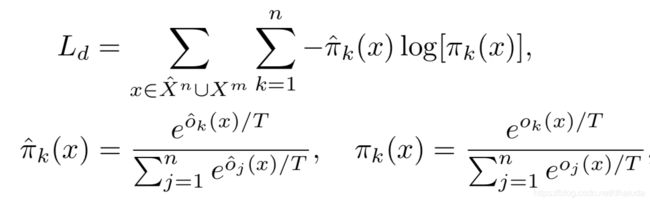
都是按照国际惯例使用的loss函数,在此不多做介绍,需注意,新类别数据的旧类别输出也会用于distillation loss的计算
最终的loss函数如下:

λ = n n + m = 1 1 + m n \lambda=\frac{n}{n+m}=\frac{1}{1+\frac{m}{n}} λ=n+mn=1+nm1,n表示旧类别数目,m表示新类别数目,随着增量学习步骤的增加(m固定,n增加), λ \lambda λ的值逐渐变大,模型越来越倾向于保留已有知识
阶段二:训练偏置纠正层
实验:分类器是否出现分类偏好
猜测
增量学习中,类别不平衡问题明显,会使分类器偏向于数据多的类别
实验
数据集:CIFAR-100
模型:使用上述loss训练的CNN模型
训练方式:利用examplar+20类新类别数据构成训练数据,实现增量学习
实验一
训练的模型准确率下降趋势明显,并且在最后一次增量学习后,从模型的混淆矩阵可以看出模型偏向于预测最后一次学习的20类,如下:

实验二
在实验一的基础上,冻结特征提取器,用旧类别(不是examplar)与新类别的所有数据训练模型,即对全连接层分类器进行训练,与实验一相比,准确率得到提升。
结论
本节实验的准确率结果如下图:

实验一的分类器使用类别不平衡的数据训练,实验二的分类器使用类别平衡的数据进行训练,实验一二模型的不同之处在于分类器。
实验一的模型出现分类偏好,实验二的模型准确率大幅提升,加之实验一的混淆矩阵,足以说明使用distillation loss训练的模型仍然会出现分类偏好,出现分类偏好的原因在于分类器
比较有趣的是,为什么实验二的模型准确率比不上“Train all layers using all data”的模型?也许是特征提取器的差异,即使用全部数据训练的特征提取器能提取更具有分类意义的特征
引入Bias Correction Layer
基于上述分析,为了矫正全连接层分类器的分类偏好,论文引入了偏置纠正层,其实就是一个线性回归层,该层的输出如下:
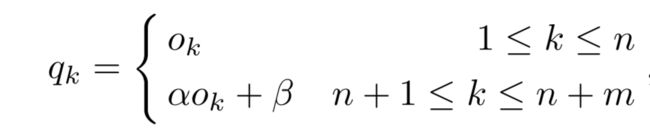
由于分类器偏向于新类别,即新类别的输出普遍比旧类别要大,因此,偏置纠正层主要对新类别分支输出进行矫正,所以对新类别分支引入了 α 、 β \alpha、\beta α、β两个可学习参数。
由于线性回归只有两个参数,训练速度快,并且最终效果不错,因此论文选用线性回归作为偏置矫正层
在阶段二,全连接层分类器以及特征提取器的参数被冻结,用 v a l o l d 、 v a l n e w val_{old}、val_{new} valold、valnew训练上述线性回归模型,按国际惯例,采用的loss函数为极大似然估计推出的交叉熵:
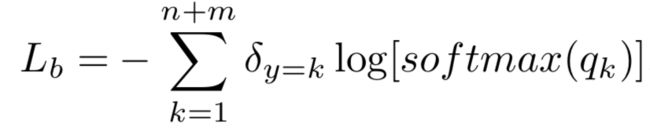
实验
数据集:CIFAR-100、ImageNet-1000、Celeb-10000
baseline:EEIL、iCaRL、LwF
其他:运用了数据增强
在大型数据集上的实验
论文题目是Large Scale,因此论文主要关注BiC在大型数据集上的表现,在ImageNet-1000与Celeb-10000上的表现如下:

表现非常的亮眼,比baseline多出十多个百分点
不同规模数据集下的比较

可看出BiC更适合大规模数据集下的增量学习(点题)
在小规模数据集CIFAR100上的比较

在小规模数据集上的表现不尽人意,提升并不明显,但是仍然具有一定的竞争力,这也说明BiC更适合大规模数据集下的增量学习(点题)
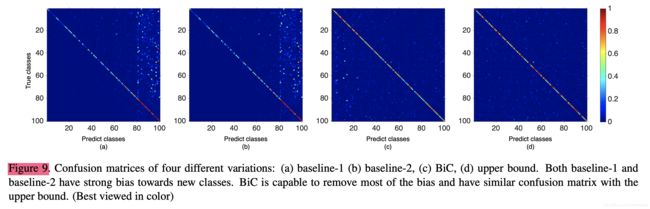
Ablation Study
论文首先比对了BiC各部分对于准确率提升的作用,在CIFAR100上的结果如下:

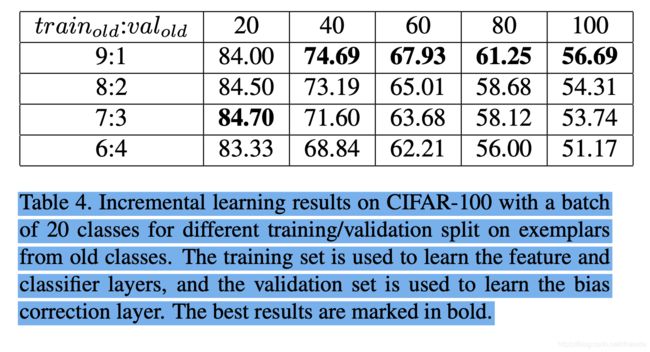
阶段一与阶段二的训练数据比为多少合适呢?结果如下:
论文还比对了构建examplar的样本选择算法,结果如下: