从数据到模型:轻舟智航自动驾驶高效感知技术解读

12 月 24 日,一段全无人自动驾驶 Demo 引起了网友的热议,视频中一辆无人的士在城市晚高峰时段完成三个订单,实现了自动躲避外卖小哥、火车站送客、礼让行人等复杂操作。技术的背后体现了“轻、快、高效”的研发理念。
本文介绍轻舟智航在自动驾驶感知技术研发方面的最新探索和实践。轻舟智航的感知技术研发聚焦方法的快捷、高效,从数据高效和模型高效两个维度为出发,提出了一系列既具有前瞻性又具有工程落地可行性的解决方案。本文结合全景分割,单目深度估计,点云的运动估计,红绿灯识别和基于点云的 3D 物体跟踪等典型感知任务,对轻舟智航的高效感知技术进行分析和解读。
1. 数据高效
据统计,一辆搭载相机、激光雷达、毫米波等多种传感器的无人驾驶车辆每天大约会产生 4TB 数据,这些数据只有不到 5% 的数据用于开发,而最终能用作标注进行模型训练的则更少。数据高效主要解决的是如何充分挖掘和利用海量的无标注数据用来开发感知模型。
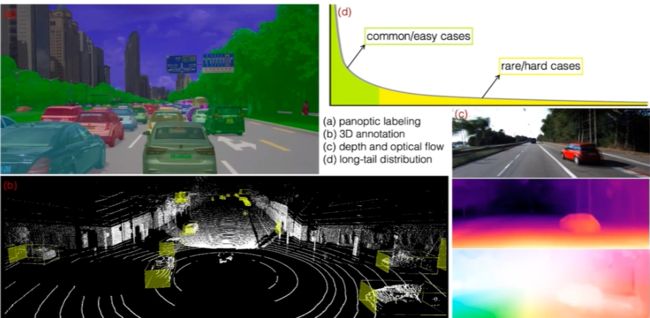
上图所示的是几种典型的感知任务的标注数据。(a)展示的是图像的全景分割,需要进行逐像素的标注,标注非常耗时;(b)是 3D 点云的目标检测框标注,标注难度大且容易出错;(c)所示的是通过单目相机或者是多帧进行逐像素的深度估计或者光流估计,这种任务几乎无法进行人工标注;(d)展示的是感知任务的数据分布,是一个典型的长尾分布。真正有价值的数据,往往集中在分布的尾部,发现并标注这样的数据非常困难,因此传统的人工标注的效率实际上是比较低的。为了解决数据高效的问题,轻舟智航的研究团队从半监督学习、自监督学习和数据合成等方法出发,针对具体的感知任务提出了一系列解决方案。
Case 1:基于半监督学习的全景分割
在计算机视觉中,图像语义分割(semantic segmentation)的任务是预测每个像素点的语义类别;实例分割(instance segmentation)的任务是预测每个实例物体包含的像素区域。全景分割的任务是为图像中每个像素点赋予类别标签和实例索引,生成全局的、统一的分割图像。
全景分割任务可以分解为两个模块,即语义分割和实例分割。由于需要逐像素的标签,标注难度和成本非常大。利用半监督学习可以结合部分的标注数据和大量的无标注数据来训练模型,是解决全景分割数据利用效率的一个可行的方案。
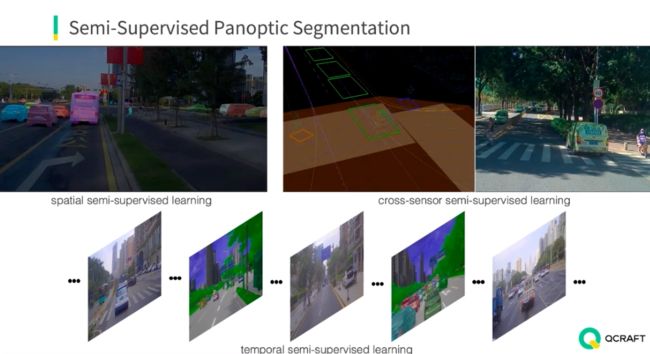
具体来说,可以从三个方面入手解决。第一个方面是空间维度的半监督学习,即在一帧图像中,只标注部分实例,其它的部分通过算法来挖掘。另一个方面是时间维度的半监督学习,利用视频数据的连续性,相邻帧之间变化的区域比较小,只标注关键帧,借助伪标签等半监督学习技术可以节省大量的标注工作量。第三个方面是从多传感器融合的角度出发,比如将点云中标注的点投影到图像,可以生成图像中的标注。这三种方式可以结合起来,最终提高全景分割模型的性能。
下图所示的是训练得到的模型在测试图像上的预测结果(上:语义分割,下:全景分割),可以看到通过半监督学习得到的模型获得了非常好的表现。

Case 2:基于自监督学习的单目深度估计
单目深度估计是指从单个相机获取的图像中估计出每一个像素的深度信息。由于真实世界图像的深度信息标注非常困难,目前很多方法都借助自监督学习来解决。
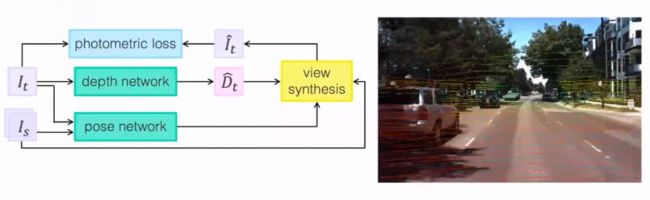
下图左侧所示是一种经典的自监督单目深度估计模型。其输入包括前后两帧图像,即目标图像,和取自目标图像相邻帧的源图像。该模型包含两个网络,其中 depth 网络从目标图像估计每个像素的深度,pose 网络的输入为目标和源图像,输出两个图像之间的 6 自由度(6-DoF)位姿变换。源图像根据估计的位姿以及深度信息可以合成一个新的目标图像,通过计算目标图像与合成图像之间的光度误差(photometric loss)可以得到自监督学习的损失函数。
上述模型假设场景是静态的,但是自动驾驶场景中有大量的运动物体,在这种情况下,上述模型的性能会有显著下降。研究团队提出新的混合位姿模型,充分考虑每一个运动物体的位置姿态信息,从而大幅改善了对动目标场景的深度估计。
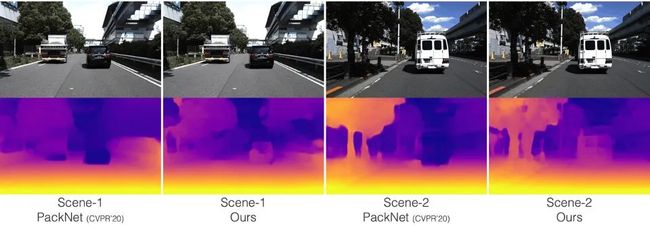
上图所示为单目深度估计的实验对比,其中 PackNet 是 CVPR'20 提出的深度估计模型,可以看到研究团队设计的模型相比该模型有明显性能提高,尤其是对运动目标的深度估计。PackNet 对上图中运动的黑车和白车深度估计不准确,将其估计为无穷远点,而轻舟智航研究团队提出的方法很好地克服了这一问题。
Case 3:基于自监督学习的点云运动估计
对于自动驾驶来说,动态场景中目标的运动状态估计是一个非常重要的任务,运动估计可以影响检测、跟踪、预测、规划等多个模块,进而影响整个自动驾驶系统的安全性和稳定性。现有的运动估计方法通常需要收集大量的标注数据进行训练,然而人工标注点云数据是一个非常困难,耗时的工作,标注成本高且容易出错。如何高效利用海量的无标注的数据来训练点云运动估计模型是学术界和工业界亟待解决的难题。
为了解决这个难题,轻舟智航创新性地提出了一种用于点云运动估计的自监督学习方法。这个方法巧妙地利用了相机和激光雷达提供的图像和点云两种模态的数据,从两种模态数据中找到一致性元素,建立正则化条件,从而提供准确的自监督信号。该自监督学习方法取得了和当前监督学习模型相媲美的性能,该方法结合监督学习进行微调后,可以取得优于现有监督学习模型的性能。这一研究成果已被 CVPR'21 收录。

论文链接:
https://arxiv.org/abs/2104.08683
代码链接:
https://github.com/qcraftai/pillar-motion
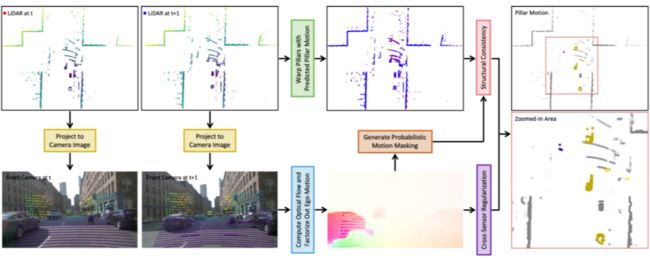
上图所示的是提出的自监督学习的基本框架。在训练阶段,模型的输入是前后两帧点云数据,以及对应的图像数据。该模型的输出是点云中动态目标的运行状态。值得一提的是,图像数据仅仅用于训练阶段提供正则约束,在推理阶段,仅有上图所示上半部分点云相关的分支,因此在推理阶段模型十分高效。
对于输入的激光点云,该方法采用体柱(pillar)的数据表示。体柱表示最初用于点云三维目标检测(PointPillars)。该方法先将点云投影到 HxW 大小格网的鸟瞰图(BEV)平面,每一个格网单元可能有多个高度值不同的点,可以视为一个柱状的点云,因此该格网单元称为体柱。体柱的表示简化了运动场景,只需要考虑水平方向运动情况,而且同一个体住内的点云运动状态可以视为一致的,因此点云运动估计问题可以简化为求解体柱的运动估计。
利用前后两帧点云结构一致性,可以用下面的基于距离变换的损失函数构建基础的自监督学习模型:
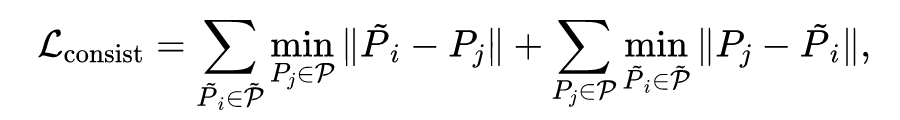
其中 为应用估计的体柱运动变换之后得到的点云, 为当前帧的真实点云。这个模型本质上是利用变换后的点云和原始点云最近邻点的关系来近似体柱的运动。这个模型最大的问题在于依赖点到点的对应关系。由于点云的稀疏性以及遮挡等因素,连续扫描的两帧点云有可能无法建立精确的点与点的对应。因此这种基于最近邻结构一致性的方法容易带来噪声,降低模型的性能。
为了解决这个问题,研究团队提出利用图像中的光流信息来建立辅助的正则项。由于图像和点云已经通过外参标定配准,可以将点云投影到图像平面,建立激光点云运动和图像像素光流的对应关系。当然,直接利用光流进行测量是不可行的,因为图像光流受到车体自身运动和目标运动的双重影响。因此还需要将车体自身运动因子分解出来。将预测的体柱运动投影到图像平面,利用光流信息可以建立如下正则化损失函数:
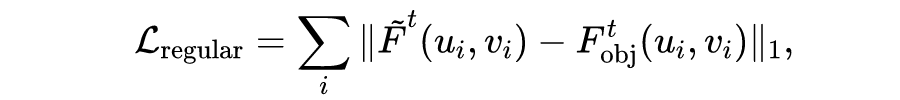
其中 是点云投影到图像平面得到的运动估计, 是图像光流得到的物体运动估计。这个损失函数建立了体柱运动估计和图像光流运动估计的自监督学习,通过训练优化促使体柱运动估计接近图像光流的运动估计。

在通过光流获得目标的运动估计之后,还可以将其反投影到点云中,从而对点的运动或者静止概率用下式估计:
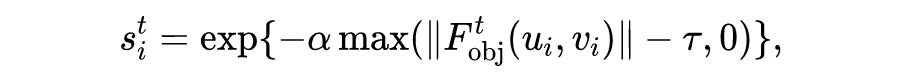
将体柱内的每个点的概率求平均可以得到体柱的运动概率值。这个概率值可以作为结构一致性损失函数 中的样本权重,从而提高自监督信号的质量。上图左侧显示的是图像光流估计的结果,彩色点表示运动目标,白色点表示静态物体,右侧所示的是反投影后在 BEV 视角下的显示体柱的静态概率值,颜色越深代表静态概率越高。
最后,借鉴光流估计中的平滑损失函数,体柱的运动估计损失函数中也可以加上局部平滑损失:
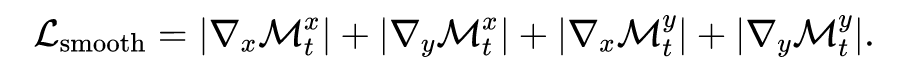
最终完整的自监督损失函数可以记为:
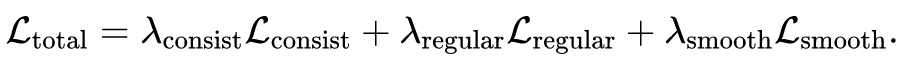
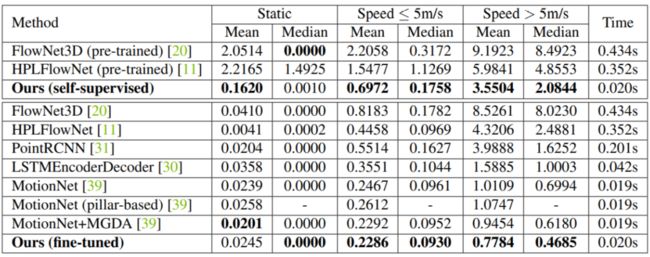
所提出的模型在自动驾驶公开数据集 nuScenes 上进行了评估,下表显示的是和当前先进的算法的比较。可以看到提出的自监督模型取得了比 FlowNet3D 和 HPLFlowNet 更好的性能,而且这两个模型在 FlyingThings3D 和 KITTI SceneFlow 数据集上进行了有监督的预训练。通过在训练集上微调,提出的模型达到了当前最好的性能。
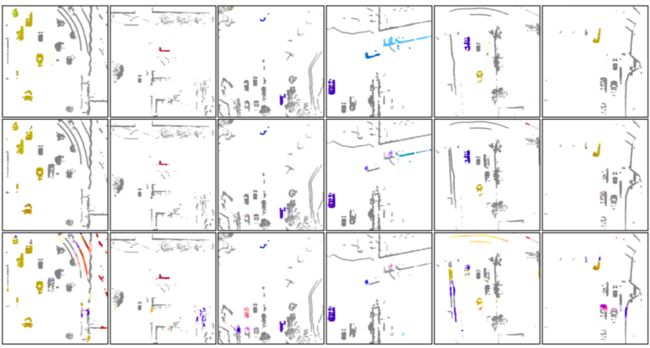
下图所示的是定性的可视化结果,第一行是真值,第二行是完整版本的模型预测的结果,第三行是只用结构一致性损失函数训练得到的模型的输出结果。可以看到完整版的模型预测结果非常接近真值,而只用结构一致性损失函数的预测结果并不理想,很多地面点也估计成了运动目标,而有的动态目标却估计成了静态目标。从这个可视化可以看出引入图像光流对自监督模型的性能带来了很大的提高。
Case 4:生成式模型用于数据合成
除了上述的自监督、半监督方法,数据高效还可以通过数据合成来实现。红绿灯识别是自动驾驶感知系统的基础模块,也是对于计算机视觉从业者来说相对简单的问题,然而真实自动驾驶场景中的红绿灯识别实际上面临很多挑战。比如说闪烁的红绿灯的识别,这种情况相对比较少,闪烁频率多样,短时间大规模收集这样的数据进行标注,并不是一件容易的任务。研究团队提出通过生成式模型来合成大量闪烁的红绿灯的数据,从而有助于快速地开发出识别出闪烁红绿灯的模型。
一个直接的方法是采用生成模型例如 StyleGAN 来生成合成数据,但是这种无条件(unconditional)的生成模型无法控制所生成图像的类别。通过条件式(conditional)生成模型,如下图所示,在输入端除了输入 latent code,还将类别信息通过类嵌入(class embedding)的方式输入网络。在损失函数上,加入类别预测的损失函数,这样就可以把无条件的生成模型转换成基于类别嵌入的条件式生成模型,实现类别可控的图像生成。
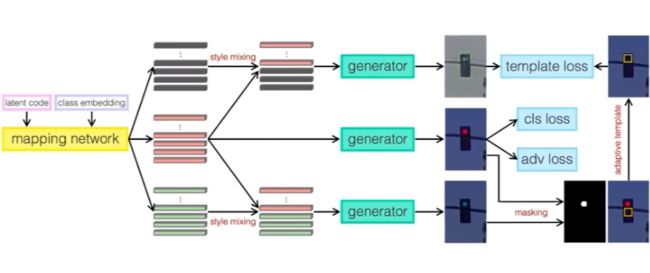
为了生成闪烁的红绿灯图像,除了类别可控的生成,还需要解决状态可控的生成,比如,生成红灯由亮到灭的图像。为了解决这个问题,研究团队提出一种通过样式特征组合和自适应生成模版的方法可以实现这个目的。上图所示红色代表红灯样式特征,灰色代表灯灭特征,绿色代表绿灯特征。虽然通过样式特征组合,红灯和绿灯生成的效果较好,但是灯灭的效果并不理想。研究团队进一步利用出自适应生成模板,根据模板推断灯灭的位置,然后用这个模板去督导灯灭的数据生成,从而可以生成更加逼真的灯灭的数据。最终的闪烁红绿的的生成效果如下图所示。
2. 模型高效
前面介绍的是高效感知中的数据高效,即如何高效利用数据来提高感知模块性能,高效感知的另一方面还体现在模型高效。所谓模型高效是指在设计模型时,充分利用数据驱动的优势,最大限度地减少手工调参,减少人工调试成本,提高模型部署的效率。下面以自动驾驶中的多目标跟踪为例,介绍轻舟智航在模型高效方面的工作。
三维多目标跟踪是自动驾驶感知模块的关键技术。tracking-by-detection 是目前业内经典的多目标跟踪技术。改方法对每一帧点云进行检测,然后通过匹配帧间的检测框来实现跟踪。当前比较流行的三维多目标跟踪方法包括 AB3DMOT、CenterPoint、PnPNet 等。
基于 tracking-by-detection 的三维多目标跟踪框架最大的弊端是需要人工设计规则和调试相关的参数来完成启发式匹配。人工设计的规则受限于工程师的领域和先验知识,调试匹配规则参数时,往往费时费力,在更换数据场景之后,往往需要重新调试,因此可扩展性差。那么,是否可以从数据驱动的角度考虑,设计模型自动学习匹配规则且不依赖大量的手动调参呢?
针对这个问题,研究团队提出了一种端到端的联合检测和跟踪范式 SimTrack:“Exploring Simple 3D Multi-Object Tracking for Autonomous Driving”,该论文收录于 ICCV'21。

论文链接:
https://arxiv.org/abs/2108.10312
代码链接:
https://github.com/qcraftai/simtrack
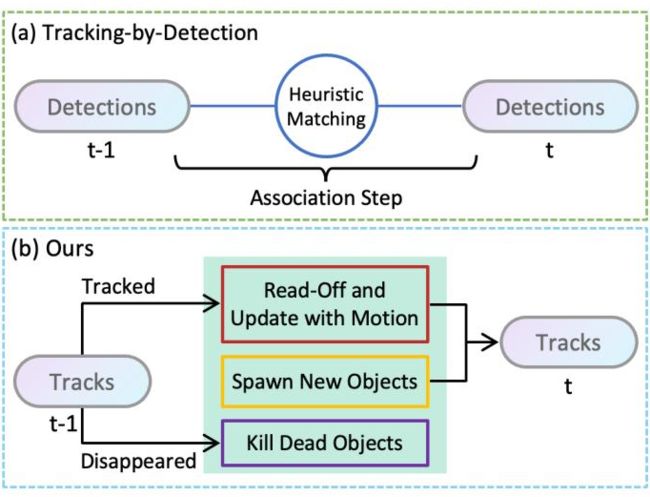
上图(a)所示是一种典型的 tracking-by-detection 框架,检测器在 t-1 和 t 帧分别检测到目标,通过启发式匹配方法进行数据关联,从而完成 t-1 帧到 t 帧的跟踪。图(b)是轻舟智航提出的数据驱动的跟踪方法,绿色框表示的是模型的核心模块。在该模型中,同时处理多目标跟踪中的三个最基本的任务:(1)更新跟踪目标的位置;(2)创建新的轨迹;(3)剔除失效的轨迹。下面,对该模型是如何实现上述三个任务的,进行详细解读。
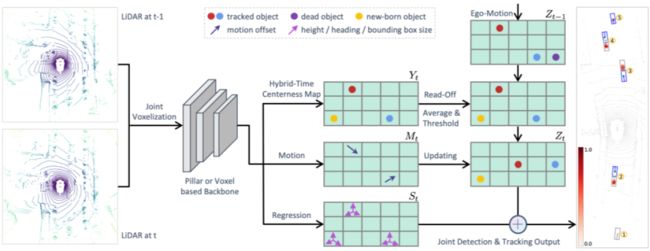
SimTrack 的模型输入是单帧或者多帧累积的点云,通过对点云数据体素化,将不规则的三维点云数据转换成规则的格网数据。体素化的点云可以通过经典的 PointPillar 的方式提取特征,也可以通过三维稀疏卷积直接提特征,最后都统一转换成可用于深度卷积神经网络处理的二维特征图。在提取完特征之后,采用 CenterNet 的解码器方式,通过全卷积网络得到输出的热力图(heat map / centerness map),在该热力图上对每个格网回归三维检测框以及预测目标类别。
如上图所示 SimTrack 输出包含三个序列:(1)检测分支(hybrid-time centerness map),用于检测目标在输入序列第一次出现的位置,该分支能够关联前一时刻与当前时刻的检测信息,同时还能滤除消失的目标,也可以检测新出现的目标;(2)运动估计分支(motion),预测目标在多帧点云序列中的偏移量,用于将(1)中的检测结果更新到当前帧;(3)回归分支(regression),预测目标的其他属性,如尺寸和朝向等。

上述模型结构用于训练阶段,在推理和测试阶段,还将结合上一时刻的 centerness map 进行优化。推理的算法流程如上图所示,对于 t=0 时刻,网络只执行检测任务,用于初始化跟踪轨迹。对于 t>0 时刻,先将上一时刻的 centerness map 通过自车位姿估计转换到当前时刻,转换后的 centerness map 和当前时刻的 centerness map 相加求平均,得到当前时刻的检测结果,该检测结果通过上一时刻对应的格网位置直接得到目标的跟踪索引,同时通过阈值判断剔除失效的跟踪目标,对新的检测目标,初始化新的跟踪轨迹。最后,使用运动估计分支预测的目标偏移,更新当前帧目标的位置。

研究团队在 Waymo 和 nuScenes 数据集上进行了实验。Waymo 验证集上的实验结果如上表所示。评估方法采用多目标跟踪通用的评估指标。其中 Baseline 是 Waymo 官方提供的传统的基于卡尔曼滤波的方法,从实验结果可以看到,提出的模型相比 Baseline 和 CenterPoint 在各个指标上均有较大提高。更重要的是,SimTrack 不需要手动设计匹配规则或者调试相关的参数,从而极大简化了模型的开发和提升了模型泛化性能。
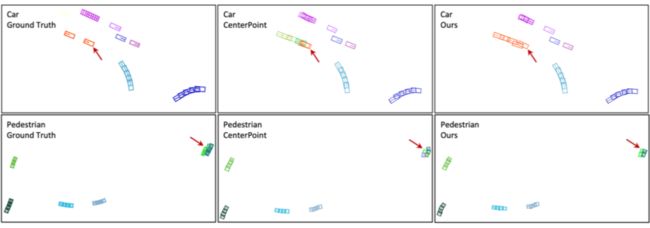
上图为在 nuScenes 数据集上车辆和行人跟踪的可视化结果,左侧第一列为真值,中间列为 CenterPoint 的跟踪结果,右侧是 SimTrack 的结果,不同的颜色代表不同的目标 ID。可以看到 SimTrack 相比 CenterPoint 跟踪效果更加鲁棒。
3. 总结
本文介绍了轻舟智航在自动驾驶高效感知技术方面的探索和实践,结合典型的感知任务案例,从数据高效和模型高效两个方面进行了深入解析。这种快捷、高效的主线研发的思想,对于自动驾驶感知模型的快速开发和部署有重要的意义,值得广大自动驾驶感知方向的研究人员学习和借鉴。

参考文献
[1] Guizilini V, Ambrus R, Pillai S, et al. 3D Packing for Self-Supervised Monocular Depth Estimation. CVPR, 2020.
[2] Karras T, Laine S , Aila T. A Style-Based Generator Architecture for Generative Adversarial Networks. CVPR, 2019.
[3] Alex H Lang, Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. PointPillars: Fast encoders for object detection from point clouds. In CVPR, 2019.
[4] Yan Yan, Yuxing Mao, and Bo Li. SECOND: Sparsely embedded convolutional detection. Sensors, 2018.
[5] Tianwei Yin, Xingyi Zhou, and Philipp Krahenbul. Center-based 3D object detection and tracking. In CVPR, 2021.
[6] Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. In CVPR, 2020.
[7] Chenxu Luo, Xiaodong Yang, Alan L. Yuille. Self-Supervised Pillar Motion Learning for Autonomous Driving. CVPR, 2021.
[8] Xingyu Liu, Charles Qi, and Leonidas Guibas. FlowNet3D: Learning scene flow in 3D point clouds. In CVPR, 2019.
[9] Xiuye Gu, Yijie Wang, Chongruo Wu, Yong-Jae Lee, and Panqu Wang. HPLFlowNet: Hierarchical permutohedral lattice FlowNet for scene flow estimation on large-scale point clouds. In CVPR, 2019.
[10] Chenxu Luo, Xiaodong Yang, Alan L. Yuille. Exploring Simple 3D Multi-Object Tracking for Autonomous Driving. ICCV, 2021.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
