树、二叉树、存储结构、二叉数遍历& 数据结构基本概念和术语
文章目录
- 树、二叉树、存储结构、二叉数遍历& 数据结构基本概念和术语
-
-
-
- 数据结构基本概念和术语
- 第四章
-
- 树的基本概念
- 二叉树的基本概念
-
- 什么是二叉树
- 二叉树的基本/特殊状态
- 二叉树的存储结构
-
- 链式存储结构
- 顺序结构存储
- 二叉树的遍历
-
- 二叉树的遍历方法简介
- 来康康代码实现
- 思路:
- 四种遍历方式的时间和空间复杂度
- 根据遍历序列确定二叉树
-
-
树、二叉树、存储结构、二叉数遍历& 数据结构基本概念和术语
数据结构基本概念和术语
- 数据、数据元素和数据项
- 数据:所有被计算机存储、处理的对象。
- 数据元素:数据的基本单位,在程序中作为一个整体而加以考虑和处理。数据元素是运算的基本单位,通常具有完整确定的实际意义。数据元素常常又简称为元素。
- 数据项:一般情况下,数据元素由数据项组成。在数据库中数据项又称为字段或域。它是数 据的不可分割的最小标识单位。
总结
从宏观上看,数据、数据元素和数据项实际上反映了数据组织的三个层次,数据可由若干个数据元素组成,而数据元素又可由若干个数据项组成。
数据结构是相互之间存在一种或多种特定关系的数据元素的集合。它包括数据的逻辑结构、数据的存储结构和数据的基本运算。
-
数据的逻辑结构
-
数据的逻辑结构是指数据元素之间的逻辑关系。所谓逻辑关系是指数据元素之间的关联方式或“邻接关系”。
-
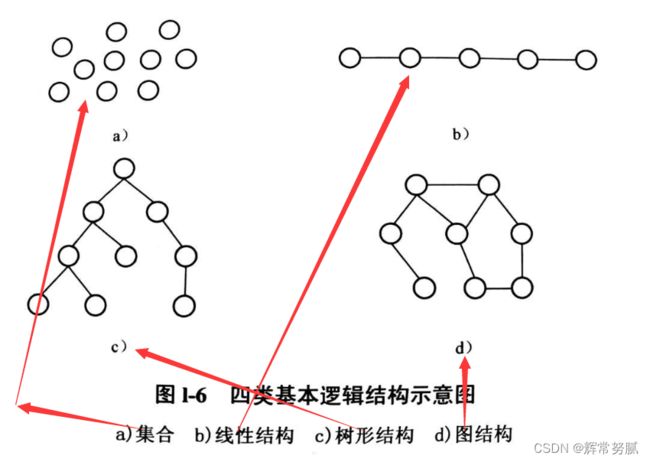
根据数据元素之间的关系,有四类基本的逻辑结构
-
集合
-
线性结构
-
树形结构
-
图结构
-
集合中任意两个结点之间都没有邻接关系,组织形式松散。
-
线性结构中结点按逻辑关系依次排列形成一条“链”,结点之间一个一个依次相邻接。
-
树形结构具有分支、层次特性,其形态像自然界中的树,上层的结点可以和下层多个结点相邻接,但下层结点只能和上层的一个结点相邻接。
-
图结构最复杂,其中任何两个结点都可以相邻接
-
-
-
第四章
树的基本概念
树是一种非线性结构,树与线性表的逻辑关系不同。
- 什么是树?
-
树(Tree)是一类重要的数据结构,其定义如下:
- 树是 n(n 多 0)个结点的有限集合,一棵树满足以下两个条件:
(1)当 n=0 时,称为空树;
(2)当 n>0 时,有且仅有一个称为根的结点,除根结点外,真余结点分 m(m≥0)个互不相交的非空集合 T1,T2,…,Tm,这些集合中的每一个都是一棵树,称为根的子树。
- 树是 n(n 多 0)个结点的有限集合,一棵树满足以下两个条件:
-
森林(Forest)是 m(m>0)棵互不相交的树的集合。树的每个结点的子树是森林。删除一个非空树的根结点,它的子树便构成森林。
-
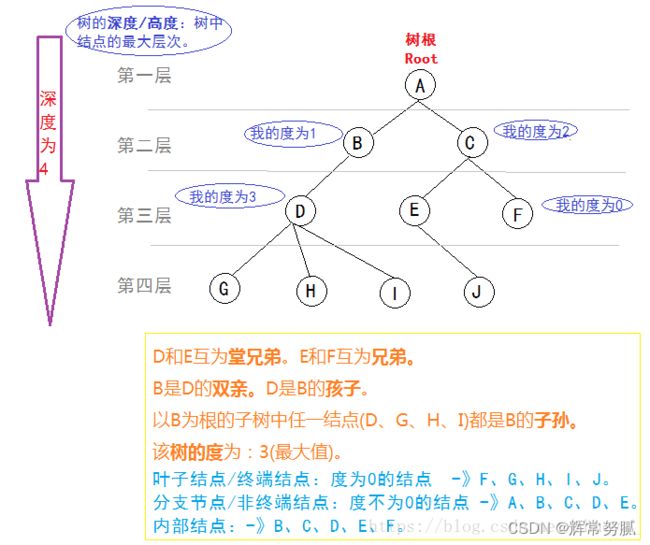
树的基本概念看下面的图
-
形象理解

-
树的定义
-
树:是n(n≥0)个结点(元素)构成的有限集合。当n=0时,称这棵树为空树。在一棵非空树T中:
- 有且只有一个特殊的结点称为树的根结点,根结点没有前驱结点;
- 当n>1,除根结点之外的其余数据元素被分成m(m>0)个互不相交的集合T1,T2,…,Tm,其中每一个集合Ti ( 1 ≤ i ≤ m ) 本身又是一棵树。树T1,T2,…,Tm 称为这个根结点的子树
-
结点:是数据元素的别名。
-
集合:线性表对应的是序列,树对应的是集合。
-
结点的度:树中结点所拥有的子树的个数。
-
树的度:树中各结点度的最大值。
-
二叉树的度为2。
-
叶子结点(终端结点):度为0的结点。
-
分枝结点(非终端结点):度不为0的结点。
-
孩子:树中一个结点的子树的根结点。
-
双亲:树中一个孩子结点的上层结点(唯一)。
-
兄弟:具有同一个双亲的孩子结点互成为兄弟。
-
子孙:一个结点的所有子树中的结点称之为该结点的子孙节点。
-
祖先:从根结点到该结点所经分支上的所有结点。
-
层数:根结点的层数规定为1,其余结点的层数等于它的双亲结点的层数+1。
-
深度:所有结点的最大层次。
-
堂兄弟:双亲在同一层,且双亲不同的结点互为堂兄弟。
-
有序树:如果一棵树中结点的各子树从左到右是有次序的,即若交换了某结点各子树的相对位置则构成不同的树,称这棵树为有序树;反之,则称为无序树。
-
无序树:若树中各结点的子树是无次序的,可以互换,则称为无序树。
-
森林:m(m≥0)棵不相交的树的集合称为森林。自然界中树和森林是不同的概念,但在数据结构中,树和森林只有很小的差别,任何一棵树,删去根结点就变成了森林。
-
注意事项:
-
递归方法是树结构算法的基本特点
-
树的根节点唯一
-
n>0:子树的个数从定义上没有限制,可以很大。
-
子集互不相交:
- 某结点不能同时属于两个子集
- 两个子集的结点之间不能有关系。
-
-
-
树的逻辑表示**(了解)**
-
直观表示法
- 圆圈+数字(字母)+连线(无向)
- 根节点在上,子树画下面(一颗倒长的树)
-
形式化表示法
- T=(D,R)
- D:D为树T中结点的集合
- R:树中结点之间关系的集合
- 当树为空树时,D=φ
- 当树T不为空树时,D={Root}∪Df
- Root为树T的根结点
- Df为树T的根Root的子树集合。
- Df=D1∪D2∪…∪Dm且Di∩Dj=φ,(i≠j,1≤i≤m,1≤j≤m)
- 当树T中结点个数n≤1时,R=φ
- 当树T中结点个数n>1时有:R={
- Root为树T的根结点
- ri是树T的根结点Root的子树Ti的根结点。
- T=(D,R)
-
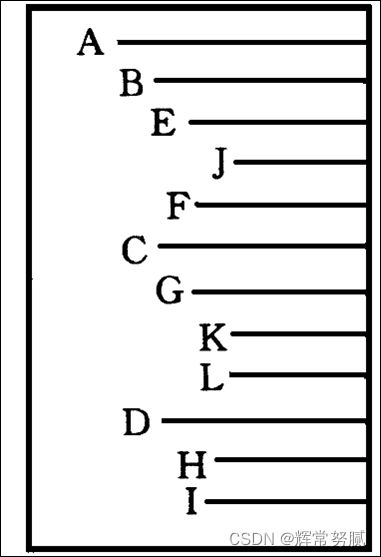
凹入表示法
-
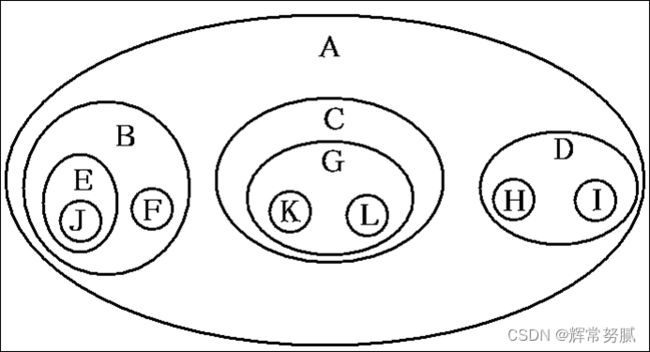
文氏图表示法
-
广义表表示法 - (A(B(E(J),F),C(G(K,L)),D(H,I)))
-
-
森林
m棵互不相交的树的集合**(m=>0)**
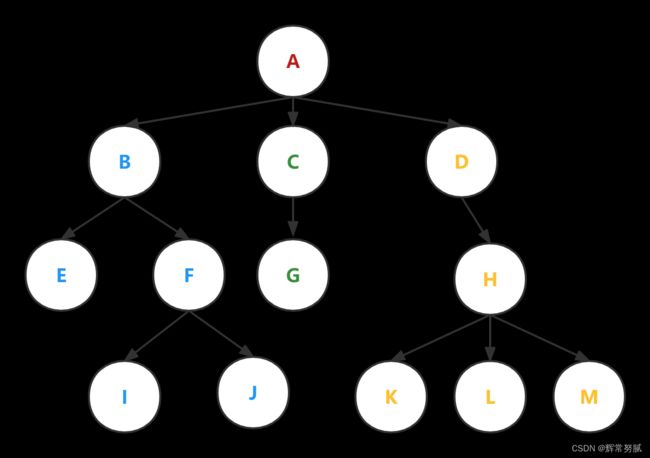
可见,蓝色、绿色、黄色各为一棵树,它们不互相交,共同构成了一个森林,但这个森林本身也是一棵树。
-
树的存储结构
- 顺序存储结构
- 双亲表示法:用一组连续的存储空间存储树的结点,同时在每个结点中,用一个变量存储该结点的双亲结点在数组中的位置。
- 链式存储结构
- 孩子表示法:把每个结点的孩子结点排列起来存储成一个单链表。所以n个结点就有n个链表; 如果是叶子结点,那这个结点的孩子单链表就是空的; 然后n个单链表的的头指针又存储在一个顺序表(数组)中。
- 孩子兄弟表示法:顾名思义就是要存储孩子和孩子结点的兄弟,具体来说,就是设置两个指针,分别指向该结 点的第一个孩子结点和这个孩子结点的右兄弟结点。
- 顺序存储结构
二叉树的基本概念
注意:二叉树是有序树,分左右!!
什么是二叉树
- 二叉树(Binary Tree):
- 二叉树是n(n>=0)个结点的有限集合,该集合或者为空集(空二叉树)、或者由一个根结点和两颗互不相交的、分别称为根结点的左子树和右子树的二叉树组成,其中左子树和右子树也均为二叉树。
- 注意:
- 二叉树的任一结点都有两棵子树(它们中的任何一个都可以是空子树),并且这两棵子树之间有次序关系,即如果互换了位置就成为一棵不同的二叉树。二叉树上任一结点左、右子树的根分别称为该结点的左孩子和右孩子。
- 特点
- 二叉树中每个结点最多有两颗子树,度没有超过2的。
- 左子树和右子树是有顺序的,不能颠倒。
二叉树的基本/特殊状态
-
五种基本状态
-
空二叉树
-
只有一个根节点
-
根节点只有左子树
-
根节点只有右子树
-
根节点既有左子树,又有右子树

-
-
几个特殊的二叉树
-
真二叉树
-
所有节点的
度要么为0,要么为2,即没有只有一个子节点的节点。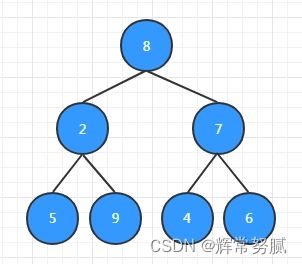
-
-
斜树
- 分为左斜树和右斜树:
- 左斜树:所有节点都只有左子树
- 右斜树:所有节点都只有右子树

- 分为左斜树和右斜树:
-
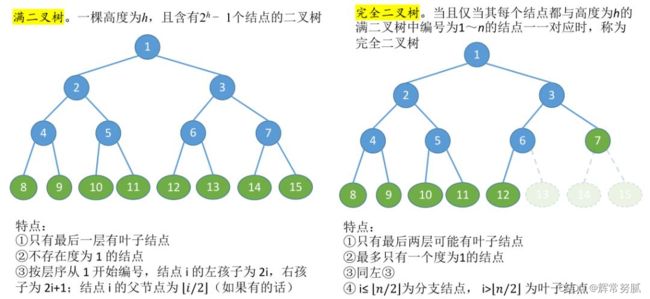
满二叉树和完全二叉树
按层序编号,则可以通过一个结点知道其双亲结点和孩子结点的编号。
-
满二叉树
对二叉树来说,第i层的节点个数最多为2^(i-1)个,如果二叉树的每一层的节点个数都达到最大值,即叶子节点全部在最后一层,非叶子节点一定有左右孩子,这种二叉树称为满二叉树。
-
完全二叉树
完全二叉树就和名字有点不太一样了,除最后一层节点外,其他层节点都必须要有两个子节点,并且最后一层节点都要左排列。
完全二叉树的判断条件没有满二叉树那么苛刻,完全二叉树要求最下面两层的节点,可以没有孩子节点,也可以仅有一个孩子,但最下层的叶子节点必须都在左侧。
-
要满足两个条件:
-
除最后一层节点外,其他层节点都必须要有两个子节点
-
最后一层节点都要左排列
-
【非完全二叉树】需要注意最下层叶子节点必须在左侧,像下面的树违反了这个规则,不是完全二叉树:
- 其实上面的没有满足完全二叉树的例子就可以称为非完全二叉树。
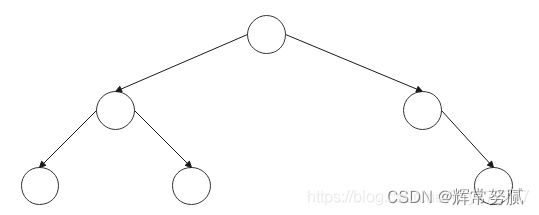
-
-
-
二叉树的存储结构
- 二叉树通常有两类存储结构,顺序存储结构和链式存储结构。
- 链式存储结构在插入删除结点时较方便
- 二叉树每个结点最多两个孩子,所以设计二叉树的结点结构时考虑两个指针指向该结点的两个孩子。
- 在某些情况下,二叉树的顺序存储结构也很有用
- 二叉树的顺序存储结构就是用一组地址连续的存储单元依次自上而下、自左至右存储完全二叉树上的结点元素。
- 链式存储结构在插入删除结点时较方便
链式存储结构
-
由于顺序存储二叉树的空间利用率较低,因此二叉树一般都采用链式存储结构,用链表结点来存储二叉树中的每个结点。在二叉树中,结点结构通过包括若干数据域和若干指针域,二叉链表至少包含3个域:数据域 data、左指针域 lchild和右指针域 rchild,如下图所示:

- n 个结点的二叉链表中含有 n+1 [ 2n-(n-1)=n+1 ] 个空指针域。
- 普通二叉树示意图
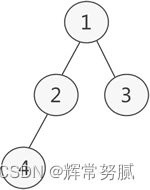
- 如上图若将其采用链式存储,则只需从树的根节点开始,将各个节点及其左右孩子使用链表存储
因此,上图对应的链式存储结构如下图所示:
-
二叉树链式存储结构示意图
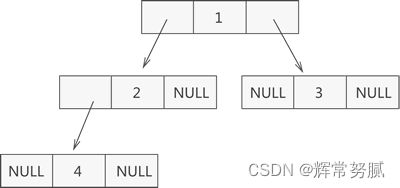
-
由上图可知,采用链式存储二叉树时,其节点结构由 3 部分构成:
-
二叉树节点结构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QcGqMdwy-1652776618648)(image-20220517150513985.png)]](http://img.e-com-net.com/image/info8/179c70290cb2416aa79444c9bc6be6d0.jpg)
-
二叉链表存储结构

顺序结构存储
-
用顺序存储方式数组下标最好从1开始,这样才能利用完全二叉树的性质。
-
二叉树的顺序存储
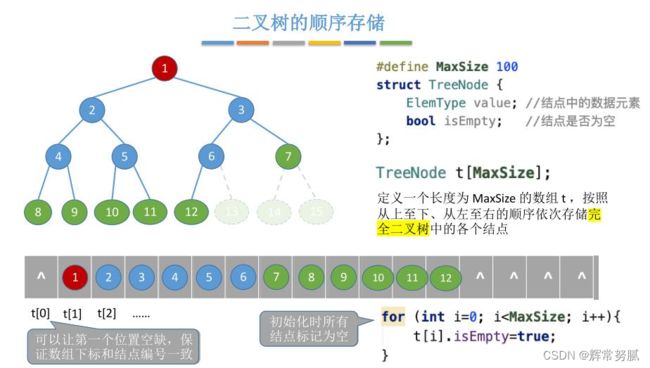
-
依据二叉树的性质,完全二叉树和满二叉树采用顺序存储比较合适,树中结点的序号可以唯一地反映结点之间的逻辑关系这样既能最大可能地节省存储空间,又能利用数组元素的下标值确定结点在二叉树中的位置,以及结点之间的关系。
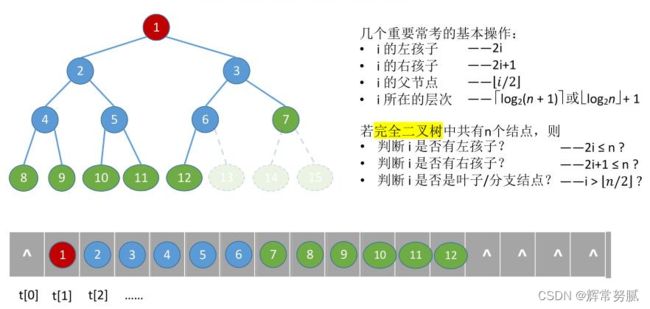
- 但对于一般的二叉树,为了让数组下标能反映二叉树中结点之间的逻辑关系,只能添加一些并不存在的空结点,让其每个结点与完全二叉树上的结点相对照,再存储到一维数组的相应分量中。然而,在最坏情况下,一个高度为h且只有h个结点的单支树却需要占据近2^h-1个存储单元。

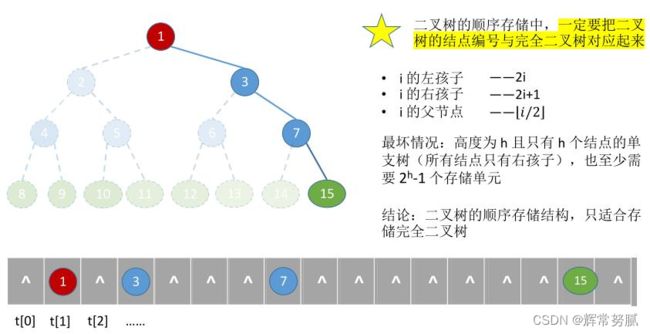
- 结论:
- 二叉树的顺序存储结构,只适合用于存储完全二叉树
二叉树的遍历
二叉树的遍历方法简介
- 先序遍历:若被遍历的二叉树为空,执行空操作 否则, 1)访问根结点; 2)先序遍历左子树; 3)先序遍历右子树。
- 递归
- 非递归
- 中序遍历:若被遍历的二叉树为空,执行空操作 否则, 1)中序遍历左子树; 2)访问根结点; 3)中序遍历右子树。
- 递归
- 非递归
- 后序遍历:若被遍历的二叉树为空,执行空操作 否则, 1)后序遍历左子树; 2)后序遍历右子树; 3)访问根结点。
- 递归
- 非递归
- 层次遍历: 若被遍历的二叉树为空,执行空操作 否则,从树的第一层开始访问,从上而下逐层遍历,在同一层中,按从左到右的顺序对结点逐个访问。
来康康代码实现
private List<Integer> res = new ArrayList<>();
-
先序遍历
-
递归
private void dfs(TreeNode node) { if (node == null) { return; } res.add(node.val); dfs(node.left); dfs(node.right); } -
非递归
public List<Integer> preorderTraversal_Iteration(TreeNode root) { if (root == null) { return res; } Deque<TreeNode> stack = new LinkedList<>(); stack.addFirst(root); while (!stack.isEmpty()) { TreeNode node = stack.removeFirst(); res.add(node.val); //注意这里要先加右子节点,再加左子节点,这样出栈的时候才是先左后右 if (node.right != null) { stack.addFirst(node.right); } if (node.left != null) { stack.addFirst(node.left); } } return res; }
-
-
中序遍历
-
递归
private void dfs(TreeNode node) { if (node == null) { return; } dfs(node.left); res.add(node.val); dfs(node.right); } -
非递归
public List<Integer> inorderTraversal_Iteration(TreeNode root) { Deque<TreeNode> stack = new LinkedList<>(); while (root != null || !stack.isEmpty()) { //先一股脑找到该节点的最左子节点 while (root != null) { stack.addFirst(root);//期间将路径中的节点压入栈中 root = root.left; } root = stack.removeFirst(); res.add(root.val); root = root.right;//转到右子节点 } return res; }
-
-
后序遍历
-
递归
private void dfs(TreeNode node) { if (node == null) { return; } dfs(node.left); dfs(node.right); res.add(node.val); } -
非递归
public List<Integer> postorderTraversal_Iteration(TreeNode root) { Deque<TreeNode> stack = new LinkedList<>(); TreeNode prev = null; while (root != null || !stack.isEmpty()) { //root==null时不进行while循环:来自下面的if,上一轮右子树为空或是右子树已遍历 while (root != null) {//一直遍历到该节点的最左子节点的左子节点(null) stack.addFirst(root); root = root.left; } /* * 这时出栈的元素有两种情况: * 1.一直遍历到的最左子节点; * 2.新弹出一个已存储的节点; */ root = stack.removeFirst(); if (root.right == null || root.right == prev) {//右子树为空或是右子树已遍历 res.add(root.val);//加入该节点 prev = root;//标记该节点已遍历 root = null;//root置为null,下一轮可以从栈中弹出新节点 } else { stack.addFirst(root);//因为右子树存在,把弹出的节点再放回去 root = root.right;//转到右子节点 } } return res; }
-
-
层次遍历
-
广度优先是一种横向的获取方式,先从树的较浅层开始获取节点,直接获取完同层次的所有页面后才进入下一层。层次遍历是广度优先遍历,层次遍历是二叉树按照从根节点到叶子节点的层次关系,一层一层横向遍历各个节点。
-
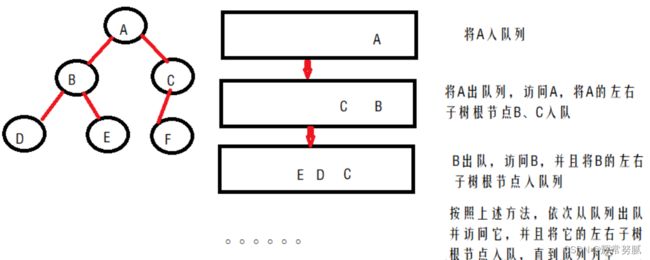
二叉树的层次遍历,是指从二叉树的根结点的这一层开始,逐层向下遍历,在每一层上按从左到右的顺序对结点逐个访问。层次遍历可以用一个队列来实现。
-
层次遍历的非递归借助了队列实现,队列的特点是先进先出。首先访问根节点并进队,队列不为空时出队并输出节点的值,如果当前出队节点有左孩子则左孩子先进队,如果有右孩子则右孩子后进队。
-
思路:
-
递归
private static class Node { int val; Node left; Node right; public Node(int data) { this.val = val; } } private void levelRecursion(Node node, LinkedList<List<Integer>> result, int level) { if (node == null) { return; } if (result.size() < level + 1) {// 说明还需要添加一行 result.addFirst(new ArrayList<Integer>()); } result.get(result.size() - 1 - level).add(node.val); levelRecursion(node.left, result, level + 1); levelRecursion(node.right, result, level + 1); } public List<List<Integer>> levelOrderBottom2(Node root) { LinkedList<List<Integer>> result = new LinkedList<List<Integer>>(); levelRecursion(root, result, 0); return result; } -
非递归
private static class TreeNode { int data; TreeNode leftChild; TreeNode rightChild; public TreeNode(int data) { this.data = data; } } public static void levelOrderTraversal (TreeNode node) { Queue<TreeNode> queue = new LinkedList<TreeNode>(); //将指定的元素插入到这个队列中 queue.offer(node); while (!queue.isEmpty()) { //获取并移除该队列的头 node = queue.poll(); System.out.print(node.data + " "); if (node.leftChild != null) { queue.offer(node.leftChild); } if (node.rightChild != null) { queue.offer(node.rightChild); } } }
-
四种遍历方式的时间和空间复杂度
大O符号(Big O notation):是用于描述函数渐进行为的数学符号。
四种遍历方式中,无论是递归还是非递归,二叉树的每个结点都只被访问一次,所以对于 n个结点的二叉树,时间复杂度均为 O ( n )。
除层序遍历外的其它三种遍历方式,所需辅助空间为遍历过程中栈的最大容量,也就是二叉树的深度,所以空间复杂度与二叉树的形状有关。对于 n 个结点的二叉树,最好情况下是完全二叉树,空间复杂度 O ( l o g 2 n ) ;最坏情况下对应斜二叉树,空间复杂度 O ( n ) 。层序遍历所需辅助空间为遍历过程中队列的最大长度,也就是二叉树的最大宽度 k,所以空间复杂度 O(k)。
根据遍历序列确定二叉树
从上面二叉树的遍历可以看出:如果二叉树中各结点值不同,那么先序、中序、以及后序遍历所得到的序列也是唯一。反过来,如果知道任意两种遍历序列,能否唯一确定这棵二叉树?
首先明确:只有先序中序,后序中序这两种组合可以唯一确定,先序后序不能。
如果知道的是先序中序,那么根据先序遍历先访问根结点的特点在中序序列中找到这个结点,该结点将中序序列分成两部分,左边是这个根结点的左子树中序序列,右边是这个根结点的右子树中序序列。根据这个序列,在先序序列中找到对应的左子序列和右子序列,根据先序遍历先访问根的特点又可以确定两个子序列的根结点,并根据这两个根结点可以将上次划分的两个中序子序列继续划分,如此下去,直到取尽先序序列中的结点时,便可得到对应的二叉树。
后序中序同理,区别是先序序列中第一个结点是根结点,而后序序列中最后一个结点是根结点。
先序和后序不能确定的原因在于不能确定根结点的左右子树。 比如先序序列AB,后序序列BA,根结点是A可以确定,但B是A的左子结点还是右子结点就确定不了了。