深度学习与神经网络——邱锡鹏
一、绪论
人工智能的一个子领域
神经网络:一种以(人工))神经元为基本单元的模型
深度学习:一类机器学习问题,主要解决贡献度分配问题
知识结构:

路线图:

顶会:

1.1 人工智能
诞生:人工智能这个学科的诞生有着明确的标志性事件,就是1956年的达特茅斯(Dartmouth)会议。在这次会议上,“人工智能” 被提出并作为木研究领域的名称。
人工智能=计算机控制+智能行为;
人工智能就是要让机器的行为看起来就像是人所表现出的智能行为一样。 ——John McCarthy ( 1927-2011)
因为要使得计算机能通过图灵测试,计算机必须具备理解语言、学习、记忆、推理、决策等能力 =>
研究领域:
- 机器感知(计算机视觉、语音信息处理、模式识别)
- 学习(机器学习、强化学习)
- 语言(自然语言处理)
- 记忆(知识表示)
- 决策(规划、数据挖掘)
发展时间轴:

1.2 如何开发人工智能系统
很难实现一个程序把这些规则给写下来,比如语音的识别,数字的识别; => 机器学习:机器自己总结规则(函数)

怎么构建这个函数?就是机器学习要解决的事;
用一个根据芒果图片来判断芒果是否甜的模型举例机器学习步骤:


1.3 表示学习
当我们用机器学习来解决一些模式识别任务时,一般的流程包含以下几个步骤:

- 数据预处理:剔除原始数据中的冗余、缺失、异常等无效数据;
- 特征提取:提取有效特征;
- 特征转换:剔除冗余特征、考虑特征间的相关性、对特征进行组合等特征转换操作;
- 预测:建立 f(x) -> y 的模型;
语义鸿沟:人工智能挑战之一,即对文本、图像的理解无法从字符串或者图像的底层特征直接获取;
比如根据一些底层的像素点就能判断这个图像是不是猫啊狗啊,这是挺难的;
Q:什么是好的数据表示?
一个好的数据表示一般有以下优点:
- 具有很强的学习能力;
- 使后续的学习任务变得简单;
- 具有一般性,是任务或者领域独立的;
数据表示是机器学习的核心问题;
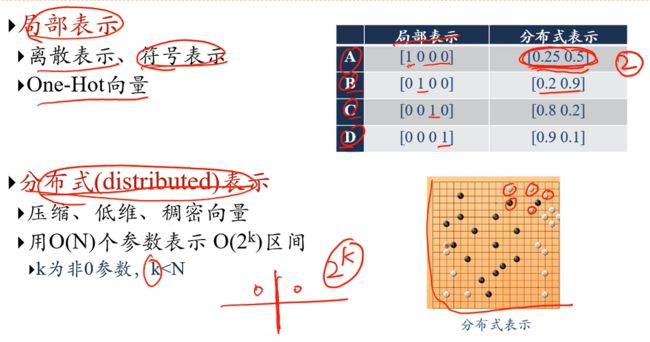
局部表示,1维表示一个语义;分布式表示,n维组合表示一个语义;
对于分布式表示:K维非零参数能够表示2k个语义(假设一个维度分左右,即表示两个语义);而局部表示中,K维只能表示K个语义;
以颜色为例:

分布式表示,3个维度能够表示完所有颜色,而如果用局部表示的话则每个颜色需要一个维度,1千种颜色就需要1千个颜色;说明分布式表示的表示能力很强,但解释能力劣于局部表示;分布式表示对于颜色间的对比、相似等操作也能提供很大的便利;
Q:照这么说,分布式表示岂不是可以表示无穷种颜色,还需要3个维度干嘛???
嵌入:

比如这个词嵌入:

表示学习:如何自动从数据中学习好的表示

传统的特征提取 VS 表示学习:

特征提取有明确的任务或目标,但完成这个任务或目标而提取的特征并不一定有益于后面的分析,而表示学习学习得是有用的特征,有益于右面的分析,但难点在于没有明确地目标,需要后面不断的反馈回来;
1.4 深度学习
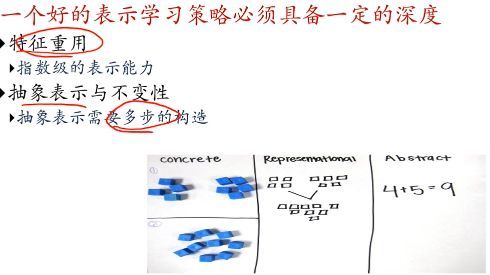
深度学习 = 表示学习 + 决策(预测)学习;

Q:什么叫贡献度分配问题?
是底层特征、中层特征还是高层特征对预测的结果影响较大,即当预测了一个较差的结果,我需要知道这主要是因为底层到中层没处理好还是中层到高层没处理好;拿下象棋举例子,我这一下下在这,我怎么知道这是好还是坏,只能通过最后我赢没赢来反馈反推前面哪一步没下好,这就需要大量的练习经验;
Q:怎么解决贡献度分配问题?
神经网络;
一个图像分类的深度学习模型:

深度学习的数学描述:

如果F(x)是线性函数,那么这个就没意义了,因为多个线性函数嵌套依旧还是线性函数,没有能力的提升;
1.5 神经网络
Q:神经网络如何学习?
赫布法则(Hebb Rule):“当神经元A的一个轴突和神经元B很近,足以对它产生影响,并且持续地、重复地参与了对神经元B的兴奋,那么在这两个神经元或其中之一会发生某种生长过程或新陈代谢变化,以致于神经元A作为能使神经元B兴奋的细胞之一,它的效能加强了。”
- 人脑有两种记忆:长期记忆和短期记忆。短期记忆持续时间不超过一分钟。如果一个经验重复足够的次数,此经验就可储存在长期记忆中。
- 短期记忆转化为长期记忆的过程就称为凝固作用。
- 人脑中的海马区为大脑结构凝固作用的核心区域。
人工神经元:

人工神经网络主要由大量的神经元以及它们之间的有向连接构成。因此考虑三方面︰
- 神经元的激活规则:那个激活函数,到底是怎么激活的,神经元输入到输出之间的映射关系,一般为非线性函数;
- 网络的拓扑结构:不同神经元是怎么连接的;
- 学习算法:通过训练数据来学习神经网络的参数:梯度下降,反馈;
人工神经网络由神经元模型构成,这种由许多神经元组成的信息处理网络具有并行分布结构。
虽然这里将神经网络结构大体上分为三种类型,但是大多数网络都是复合型结构,即一个神经网络中包括多种网络结构。


Q:神经网络如何解决贡献度分配问题?
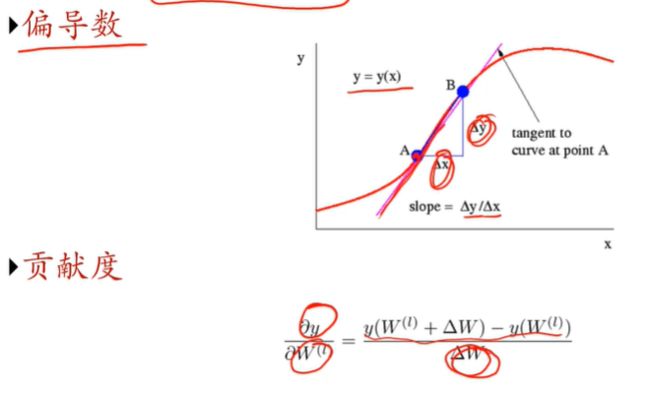
一个点的斜率越大,说明此处 x 的变化对 y 的影响越大,偏导数的概念,那么就知道在哪个地方调参数能够很大程度上影响输出;
二、机器学习概述
2.1 关于概率
概率&随机变量&概率分布

离散随机变量:
伯努利分布:

二项分布:

连续随机变量:
概率密度函数

累计分布函数

联合概率:
都发生指定的情况的概率,就是相乘;
条件概率:
对于离散随机向量(X,Y),已知X=x的条件下,随机变量Y=y的条件概率为

2.2 机器学习
如何构建映射函数 => 大量数据中寻找规律;


机器学习(Machine Learning,ML)是指从有限的观测数据中学习(或“猜测”)出具有一般性的规律,并利用这些规律对未知数据进行预测的方法.
2.3 机器学习类型
- 回归问题:房价预测、股票预测等;
- 分类问题:手写数字识别,垃圾邮件监测、人脸检测;
- 聚类问题:无监督学习,比如找出相似图形;
- 强化学习:与环境交互来学习,比如AlphaGo;
- 多种模型:监督学习+无监督学习等等,自动驾驶;

典型的监督学习:回归、分类;
典型的无监督学习:聚类、降维、密度估计;
2.4 机器学习基本要素
- 数据:有数据才能训练;
- 模型:给定假设空间,从中选择最优模型,能够预测x和y的关系
- 学习准则:判断模式是好是坏;
- 优化算法:用一些数学优化算法来学到所期望的模型;
学习准则:以回归问题为例:

机器学习问题 -> 最优化参数问题;

2.5 泛化和正则化
Q:为什么不用训练集上的错误率还验证模型好坏呢?
涉及到模型的泛化问题;

2.6 举例:线性回归

2.7 举例:多项式回归

2.8 模型选择问题
模型选择
- 拟合能力强的模型一般复杂度会比较高,容易过拟合
- 如果限制模型复杂度,降低拟合能力,可能会欠拟合
如何选择模型?
- 模型越复杂,训练错误越低 ×
- 不能根据训练错误最低来选择模型
- 在选择模型时,测试集不可见
一般这么选择模型:
将训练集分出一部分作为验证集:
然后在训练集上训练模型,选择在验证集上错误率最小的模型;
这可能导致数据稀疏问题,引入交叉验证方法:
将训练集分为S组,每次使用S-1组作为训练集,剩下1组作为验证集,取验证集上平均性能最好的一组;
也可以根据信息准则:AIC、BIC去选择模型
2.9 常用定理
没有免费午餐定理(No Free Lunch Theorem,NFL):对于基于迭代的最优化算法,不存在某种算法对所有问题(有限的搜索空间内)都有效。如果一个算法对某些问题有效,那么它一定在另外一些问题上比纯随机搜索算法更差。
奥卡姆剃刀原理:若无必要,勿增实体,如果能用一个简单模型解决的问题,切勿用一个复杂模型;
归纳偏置:很多学习算法经常会对学习的问题做一些假设,这些假设就称为归纳偏置。
- 在最近邻分类器中,我们会假设在特征空间中,一个小的局部区域中的大部分样本都同属一类。
- 在朴素贝叶斯分类器中,我们会假设每个特征的条件概率是互相独立的。
- 归纳偏置在贝叶斯学习中也经常称为先验(Prior) 。
大数定律(Probably Approximately correct,PAC):当训练集大小D趋向于无穷大时,泛化误差趋向于0,即经验风险趋向于期望风险;
三、线性模型
3.1 分类问题示例

3.2 线性分类模型
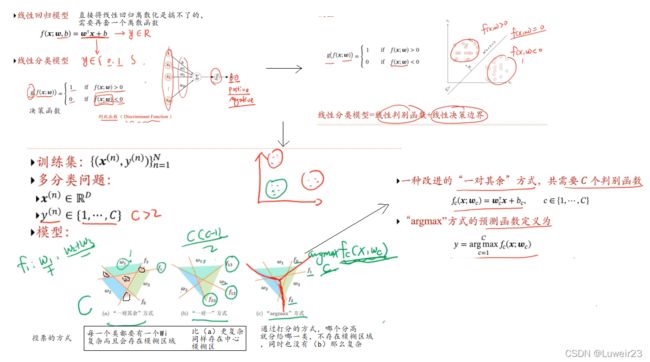
3.3 交叉熵和对数似然

KL散度是用概率分布q来近似p时所造成的信息损失量;
KL(p,q)=H(p,q)-H§
最小化KL散度=最小化交叉熵损失=最大化对数似然
3.4 Logistic回归
logistic回归 != 逻辑回归

3.5 Softmax回归
解决多分类问题;

3.6 感知机

3.7 支持向量机
一个良好的分界线,他要离所有的样本都比较远,这样不至于因为某个噪声点而造成较大的干扰,直观上也会感觉模型的健壮性更好;融入一定的噪声问题;

3.8 升维解决非线性可分问题

对于如何把异或问题升维成线性可分问题https://www.cxybb.com/article/qq_45769063/106563811
四、神经网络
4.1 神经元

4.2 前馈神经网络
通用近似定理:根据通用近似定理,对于具有线性输出层和至少一个使用“挤压”性质的激活函数的隐藏层组成的前馈神经网络,只要其隐藏层神经元的数量足够,它可以以任意的精度来近似任何从一个定义在实数空间中的有界闭集函数;
感觉其实就是一个函数必然可以用多层神经网络来无限逼近;即神经网络可以作为一个“万能”函数来使用,可以用来进行复杂的特征转换,或逼近一个复杂的条件分布。

4.3 反向传播算法
链式法则(Chain Rule)是在微积分中求复合函数导数的一种常用方法。

其实不是很懂,但并不是目前我想要掌握的重点,以后有机会再仔细琢磨;

4.4 计算图与自动微分
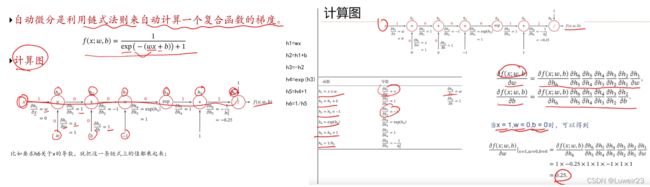
就是利用算子把每一阶段的导数都算出来存储了,相当于把递归给转换成备忘录了,比如h6对h5的导数,并不会关心h5内部怎么实现,是什么函数,而只关心h6和h5的关系;
4.5 优化问题

五、卷积神经网络
Q:为何需要卷积神经网络?

5.1 卷积
Q:何为卷积?
计算一个信号的延迟累计
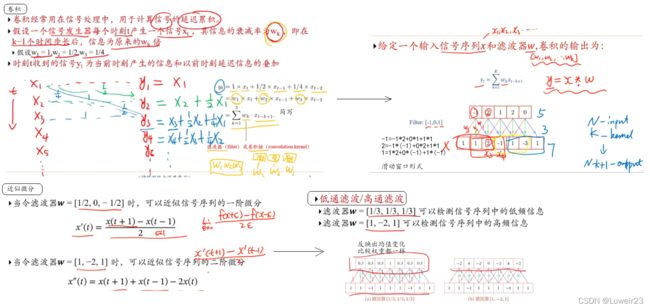
还可以通过增加滑动步长来降低计算次数,减少输出长度;

5.2 卷积神经网络CNN
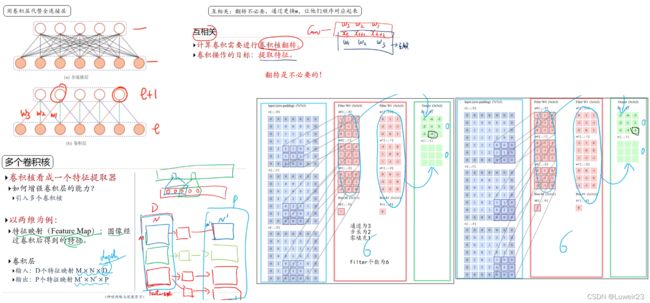

即卷积网络的思想就是:先局部组合,再非局部组合;
5.3 其他卷积网络

5.4 典型卷积网络

后面的网络就比较复杂了,感兴趣可以看:https://www.bilibili.com/video/BV13b4y1177W?p=40
5.5 卷积网络的应用
5.6 应用到文本数据

六、循环神经网络
6.1 增强记忆能力

搞时序数据研究可能需要的重点知识!!!
6.2 循环神经网络RNN
RNN通过使用带自反馈的神经元,能够处理任意长度的时序数据;

如果前馈神经网络可以模拟任何的函数,那么RNN就能模拟任何的程序;
6.3 应用到机器学习

6.4 参数学习与长程依赖问题

6.5 解决长程依赖问题

有兴趣可以听课程,单单字面理解怕是难搞懂;
6.6 GRU和LSTM
重点!
门控循环单元(Gated Recurrent Unit,GRU)
长短期记忆神经网络(Long Short-Term Memory,LSTM)

6.7 深层循环神经网络

循环神经网络优点:
- 引入(短期)记忆
- 图灵完备:近似万能程序
缺点:
- 长程依赖问题;
- 记忆容量问题;
- 并行能力 ;
6.8 循环神经网络应用
语言模型:一切都是概率;
依赖前面的n-1个状态(语法),即为n元语言模型

6.9 扩展到图结构
