《Attention is All You Need》论文学习笔记
目录
Abstract
1. Illustrated Transformer
1.1 A High-level look
1.2 Attention
1.2.1 Scale Dot-Product Attention
1.2.2 Multi-Head Attention
1.3 Positional Encoding - Representing the Order of the Sequence
1.4 Detailed Architecture
References
最近在学习Pytorch Tutorial,看到Text章节下面的《SEQUENCE-TO-SEQUENCE MODELING WITH NN.TRANSFORMER AND TORCHTEXT》时对其参考论文《Attention is all you need》 进行学习,下面是一些关键内容和笔记。笔记中大部分图片都从一篇非常优秀的讲解Transformer的技术博客 《The Illustrated Transformer》中截取,感谢博客作者Jay Alammer详细的讲解,也推荐大家去阅读原汁原味的文章。
Abstract
Transformer, proposed in the paper Attention is all you need, is a simple network architecture based on attention mechanisms, without using sequence aligned RNNs or convolutions entirely.
The Transformer follows encoder-decoder architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure 1, respectively.
Why Self-Attention - Target Problems:
- RNN/LSTM/GRU is sequential model, restricting the ability of parallisation and computation efficiency.
- Learning long-range dependencies is a key challenge in many sequence transduction tasks.
Advantages:
- More parallelizable & less training time
- Good ability to solve long-range dependencies
- Generalization to other fileds
Disadvantages:
- Loss of ability to make use of positional information although it uses position embedding
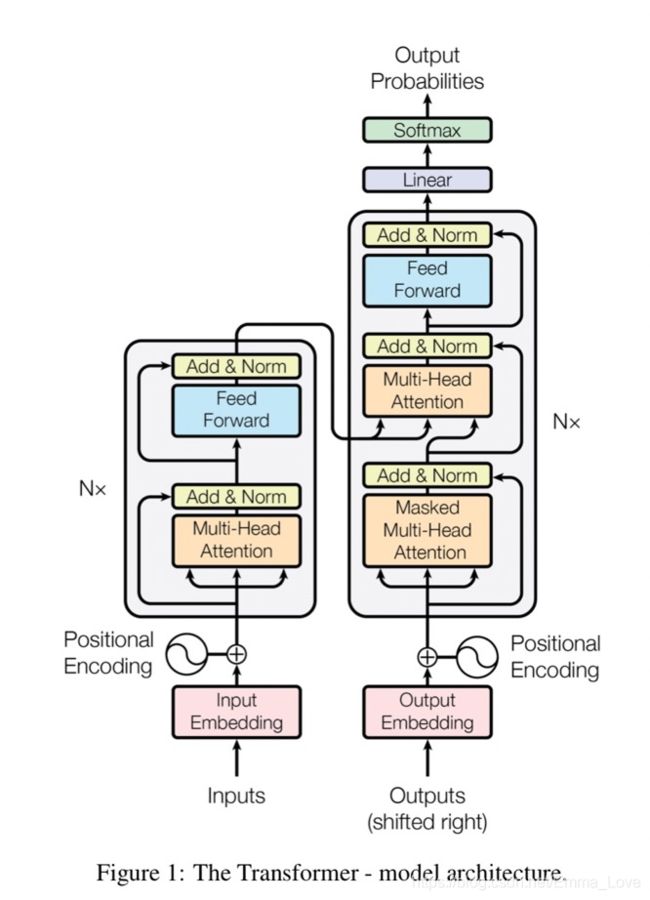
1. Illustrated Transformer
1.1 A High-level look

1.2 Attention
1.2.1 Scale Dot-Product Attention
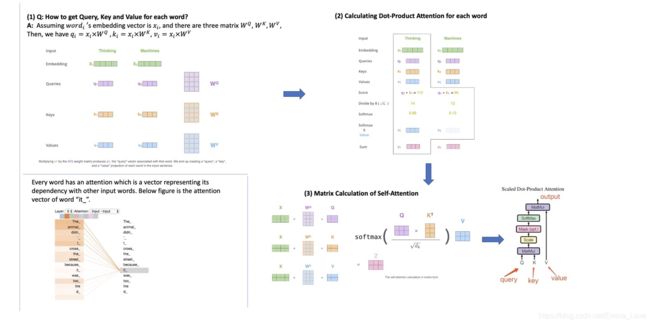
All Attention function can be described as mapping a query and a set of key-value pairs to an ouput, where the query, keys, values and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
Input: query, key, value - vectors computed from word embedding vector.
- query: a vector of
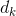 dimensions
dimensions - key: a vector of dimensions
- value: a vector of
 dimensions
dimensions
Output: a vector of dimensions
In practice, we compute the attenction function on a set of queries simultaneously, packed together into a matrix Q, as well as keys and values are packed as K and V.

Details of Attention
1.2.2 Multi-Head Attention
It is beneficial to linearly project the queries, keys and values h times with different, learned linear projections to d_k, d_k, and d_v dimensions.

Details of Multi-Head Attention

1.3 Positional Encoding - Representing the Order of the Sequence
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence.
==> Add "positional encodings" to the input embeddings at the bottoms of the encoder and decoder stacks.
Positional encodings, have the same dimension dmodel as the embeddings, so that the two can be summed.
In this work, use sine and cosine functions of different frequencies:

1.4 Detailed Architecture
References
- Paper《Attention is all you need》 https://arxiv.org/abs/1706.03762
- Blog《The Illustrated Transformer》 http://jalammar.github.io/illustrated-transformer/
- Blog《A guide annotating the paper with PyTorch implementation》 http://nlp.seas.harvard.edu/2018/04/03/attention.html
- Blog《详解Transformer (Attention Is All You Need)》 https://zhuanlan.zhihu.com/p/48508221