2.关于剪枝算法的分类和论文整理
第二篇——关于剪枝算法的分类
- 1.非结构化剪枝
-
- 1.1 非结构化的weights剪枝:
- 2.结构化剪枝
-
- 2.1 Filter/Channel Pruning:
- 2.2 Neuron-wise pruning:
- 2.3 Group-wise Pruning:
- 2.4 Stripe Pruning
-
- ★ {\color{LightPink} \bigstar} ★Pruning Filter In Filter, NIPS2020论文详解
-
- 2.4.1 Pipeline
- 2.4.2 Related work
- 2.4.3 Filter Skeleton (FS) analysis
- 2.4.4 Experiments
- 2.4.5 Rethinking
上次列举了剪枝的分类,分别列举了可以从那几个方面对模型进行剪枝,这里从另一个方向——算法层面上更宏观地对剪枝进行分类并列举出每种方案下的论文,仅仅是最近看过的一些,欢迎各位大神的补充。
1.非结构化剪枝
典型的是weights剪枝
weight pruining中,是在单个权重的粒度上来压缩模型大小。
Weight pruning (WP)起源于1990年Y LeCun的optimal brain damage和Babak Hassibi, David G Stork的Second order derivatives for network pruning: Optimal brain surgeon.这两篇论文基于损失函数的Hessian对权重进行修剪。
说完了weights的起源,我们就来看一下它的发展。由于早期神经网络并不是主流的知识,也没有人用来做现在的分类、检测、识别等任务,至于卷积神经网络虽然在1989年被提出,(Lecun于1989年发表了《Backpropagation Applied to Handwritten Zip Code》是CNN的第一个实现网络),但是通读全文,并没有找到和CNN模型原理有关的解释说明,主要是因为论文没有给出详细的权值更新的公式。所以连权值更新大家都没有详细的算法,又怎么开始权值剪枝呢?
好了,其实要看剪枝的发展直接看剪枝第一篇经典的论文就行了,之所以去写这么一段,也是顺便想回忆一下CNN,
剪枝真正的发展是在2016年Song Han教授他发表的这篇Deep compression: Compressing deep neural networks with pruning, trained, quantization and huffman coding. 向大家揭示了神经网络当中有非常多的冗余性,比如说将像AlexNet压缩35倍它的top1,top5的精度下降时是微乎其微的,因为发现神经网络的weights也好,Activation也好,他有这么高的稀疏性,那后面就提出了很多的方法很多的标准,很多的pipeline,很多的流程去去掉这些冗余性的,其中非常易懂的方法就是每一层我们用greedy的方法去试,我greedy地去去掉这些kernel,看看他对整个模型推理精度的下降是 如何影响的,这就是早期的filter pruning的工作。
好了,回到weights pruning,
1.1 非结构化的weights剪枝:
[1] Song Han教授的这篇Deep compression 基于L1范数准则修剪网络权重,并重新训练网络以恢复性能,该技术可以通过修剪、量化和霍夫曼编码结合到深度压缩pipeline中。如下:
[2] Yiwen Guo, Anbang Yao, and Y urong Chen. Dynamic network surgery for efficient dnns. In Advances in neural information processing systems,NIPS2016. 通过动态的连接剪枝降低了网络的复杂性,将Connection融入到整个过程中,避免了错误的剪枝,使其保持网络的连续性。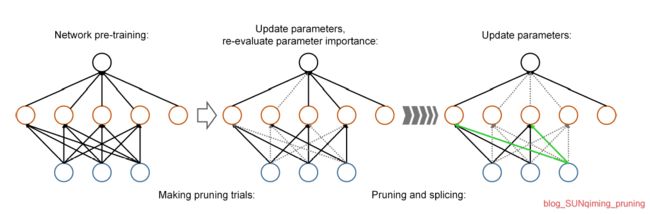
它的实验结果中将LeNet-5和AlexNet中的参数数量分别压缩108倍和17.7倍,而且不损失精度。
[3] Alireza Aghasi, Afshin Abdi, Nam Nguyen, and Justin Romberg. Net-trim: Convex pruning of deep neural networks with performance guarantee,NIPS2017。 通过求解凸优化规划来移除每个DNN层的连接。该程序在每一层寻找一组稀疏的权重,以保持层的输入和输出与最初训练的模型一致。
[4] Zhenhua Liu, Jizheng Xu, Xiulian Peng, and Ruiqin Xiong. Frequency-domain dynamic pruning for convolutional neural networks,NIPS2018。提出了一种利用CNN空间相关性的频域动态剪枝方案。 频域系数在每次迭代中进行动态剪枝,不同频段对精度的重要性不同,对不同频段进行有区别的剪枝。
[5] Hyeong-Ju Kang. Accelerator-aware pruning for convolutional neural networks,IEEE2019的工作,提出了一个新的剪枝方案,且给出了加速器的架构。在所提出的方案中,执行剪枝以使同时提取的激活值对应的每一组权重参数的数量相等。由于在硬件上实现时就是要来考虑这些每一个PE的大小问题,而这些问题本不会在GPU上加速时被考虑。通过这种方式,剪枝方案解决了低效的问题,将加速器性能提高了一倍。

MWMA和MWSA的PE结构如上。
[6] T.-J. Yang, Y.-H. Chen, and V. Sze,Designing energy-efficient convolutional neural networks using energy-aware pruning,CVPR2017,说是使用能量感知的剪枝方法,虽是17年的论文,但是只在AlexNet和GoogLeNet上做了实验,在AlexNet和GoogLeNet的能耗分别降低了3.7倍和1.6倍,精度损失低于1%。
这一篇也是介绍硬件实现的。
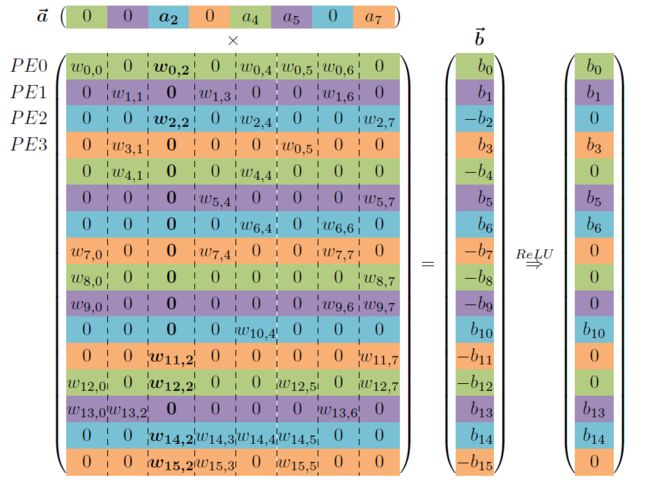
[7] 2016年Song Han教授发表在ISCA的工作也是如此:EIE: efficient inference engine on compressed deep neural network.它的矩阵表示如下图:
[8] J. Yu, A. Lukefahr, D. Palframan, G. Dasika, R. Das, and S. Mahlke,Scalpel: Customizing DNN pruning to the underlying hardware parallelism, 这篇文章提出了一种剪枝方案,称为“手术刀”,他是通过将修剪后的网络结构与数据并行硬件组织相匹配,为底层硬件定制DNN修剪。总的来说,是由两种技术构成——SIMD感知权重的修剪和节点的修剪。SIMD是用来将权重保持在对齐的固定大小组中,从而充分利用SIMD单元。具体待我仔细看看。

论文首先是对比了微控制器/CPU/GPU的执行时间,也就是延时情况,可见MAC的延时是最低的。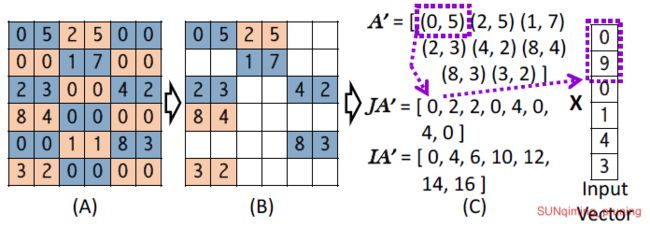
[9] Ning Liu,Xiaolong Ma,Zhiyuan Xu,Yanzhi Wang,Jian Tang,Jieping Ye,AutoCompress: An Automatic DNN Structured Pruning Framework for Ultra-High Compression Rates,AAAI2020,是一个滴滴&东北大学提出的自动剪枝的压缩算法的工作,本文提出了一种名为AutoCompress 的自动结构化剪枝框架,给定一个经过预训练的深度网络,AC会决定每层的剪枝率和剪枝策略。
然而,权重修剪导致非结构化稀疏滤波器,这很难被通用硬件加速,如果没有专用硬件/库,则不能达到压缩和加速的效果。
非 结 构 化 修 剪 可 以 导 致 更 高 的 修 剪 率 , 因 为 其 中 任 意 的 权 重 可 以 被 修 剪 , 但 是 , 由 于 权 重 存 储 是 带 有 索 引 的 稀 疏 矩 阵 格 式 , 它 通 常 会 导 致 像 G P U 这 样 的 高 度 并 行 实 现 的 性 能 下 降 。 而 这 个 问 题 可 以 在 结 构 化 权 重 修 剪 中 克 服 。 \color{Blue}非结构化修剪可以导致更高的修剪率,因为其中任意的权重可以被修剪,但是,由于权重存储是带有索引的稀疏矩阵格式,它通常会导致像GPU这样的高度并行实现的性能下降。而这个问题可以在结构化权重修剪中克服。 非结构化修剪可以导致更高的修剪率,因为其中任意的权重可以被修剪,但是,由于权重存储是带有索引的稀疏矩阵格式,它通常会导致像GPU这样的高度并行实现的性能下降。而这个问题可以在结构化权重修剪中克服。
有兴趣的朋友可以看看上一篇博客——关于剪枝对象的分类(weights剪枝、神经元剪枝、filters剪枝、layers剪枝、channel剪枝、对channel分组剪枝、Stripe剪枝)。
现有的很多方法需要额外的软/硬件加持,比如针对权重剪枝的压缩方法显然不适用于常见的加速矩阵运算的GPU。
2.结构化剪枝
结 构 化 修 剪 方 法 在 通 道 或 甚 至 层 的 层 次 上 进 行 修 剪 。 由 于 原 始 卷 积 结 构 仍 然 保 留 , 因 此 不 需 要 专 用 的 硬 件 / 库 来 实 现 这 些 好 处 。 在 结 构 化 修 剪 方 法 中 , 通 道 修 剪 是 最 受 欢 迎 的 , 因 为 它 在 较 细 粒 度 的 层 面 上 运 行 , 同 时 仍 然 适 合 传 统 的 深 度 学 习 框 架 。 \color{Blue}结构化修剪方法在通道或甚至层的层次上进行修剪。由于原始卷积结构仍然保留,因此不需要专用的硬件/库来实现这些好处。 在结构化修剪方法中,通道修剪是最受欢迎的,因为它在较细粒度的层面上运行,同时仍然适合传统的深度学习框架。 结构化修剪方法在通道或甚至层的层次上进行修剪。由于原始卷积结构仍然保留,因此不需要专用的硬件/库来实现这些好处。在结构化修剪方法中,通道修剪是最受欢迎的,因为它在较细粒度的层面上运行,同时仍然适合传统的深度学习框架。
2.1 Filter/Channel Pruning:
filters Pruning/channels pruning(FP)在卷积核、通道甚至层的级别修剪。由于原始卷积结构仍然保留,所以不需要专用的硬件/库来实现。
[10] Song Han, Jeff Pool, John Tran, and William Dally. Learning both weights and connections for efficient neural network,NIPS2015,这是Song Han大神的第一篇网络压缩论文(NIPS’15),2015年斯坦福和英伟达的一篇论文。是直接不重要的连接置0,对Lenet,AlexNet,vgg16都做出实验。 我把代码放一下http://arxiv.org/abs/1506.02626 他和
[11] Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning filters for efficient convnets,ICLR2017的论文一样。采用了剪枝不重要过滤器的L1范数,这个衡量filters的标准和权重剪枝中一样。也可以归类为神经元的剪枝。我觉得这篇论文主要是比较了独立剪枝和贪婪剪枝的优劣,以及修剪一次并重新训练和迭代修剪并重新训练之间的区别,并告诉了我们哪种方法更好,以及对应的代价。

[12] Yihui He, Xiangyu Zhang, and Jian Sun. Channel pruning for accelerating very deep neural networks,ICCV2017,提出通过基于提出通过基于LASSO回归的通道选择和最小二乘重构来修剪通道,而不是修剪滤波器。
[13] Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan, and Changshui Zhang. Learning efficient convolutional networks through network slimming,ICCV2017.这篇文章应该算是Network slimming的鼻祖论文了,我读剪枝和复现的第一篇文章就是它。这篇文章是通过优化BN层中的缩放因子 γ \gamma γ 作为衡量通道importance的指标,以决定哪些通道不重要,从而按照选择的剪枝率剪去
核心公式是 ∑ ( x , y ) l ( f ( x , W ) , y ) + λ ∑ γ ∈ Γ g ( γ ) \color{blue} \sum_{(x,y)}^{}l(f(x,W),y)+\lambda \sum_{\gamma \in \Gamma }^{}g(\gamma ) ∑(x,y)l(f(x,W),y)+λ∑γ∈Γg(γ)
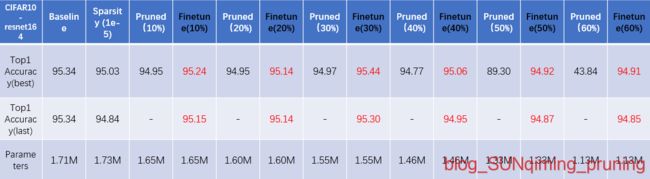
这里顺便公开一下我复现的部分结果:
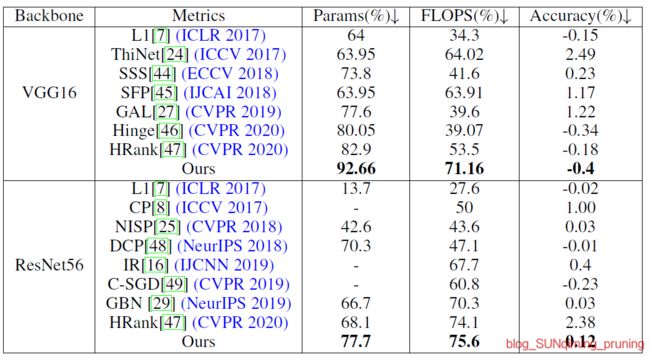
可见:复现的结果是相当不错的,尤其在VGG16上,浮现的结果比论文中竟高近两个点,比最近一些复杂细粒度的pruning方法相差无几,甚至接近CVPR2020的Oral——HRank。同样针对VGG16_CIFAR10,后者在Parameters为2.51M(剪掉82.9%),FLOPs为145.61M(剪掉53.5%)时Accuracy达到最高,但是paper中最好的结果仅为93.43%,可见这篇2017ICCV的工作有多么漂亮。

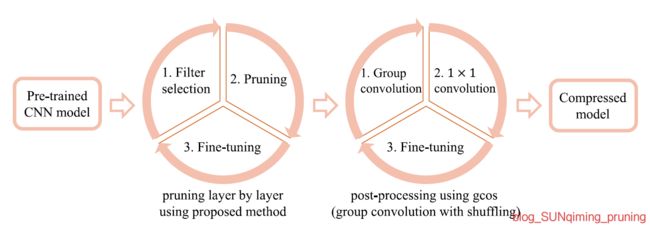
[14] Jian-Hao Luo, Jianxin Wu, Weiyao Lin. Thinet: A filter level pruning method for deep neural network compression,ICCV2017. ThiNet的pipeline如下,主要有两个组成部分,第一个部分是我们常见的三步走,剪枝微调,但后面跟了一步是使用gcos做预训练,
这里使用分组卷积进一步压缩参数。
它引入了ThiNet,正式地将filters剪枝问题作为一个优化问题开始考虑,并建议要基于从下一层计算出的统计信息来修剪filters,而不是当前的Layer。

[15] Pruning convolutional neural networks for resource efficient inference,In ICLR, 2017。这篇ICLR2017的工作使用泰勒展开作为修剪标准的衡量,对filters进行剪枝。
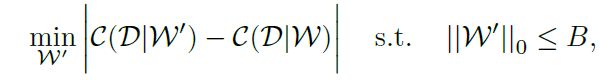
在Bird-200数据集,Vgg16上做了实验,反映了Params和FLOPs的PR与精度下降的程度。是一篇传统的选择某种方法衡量filters importance以此为据prune filters的文章。
开源地址在: http://arxiv.org/abs/1611.06440

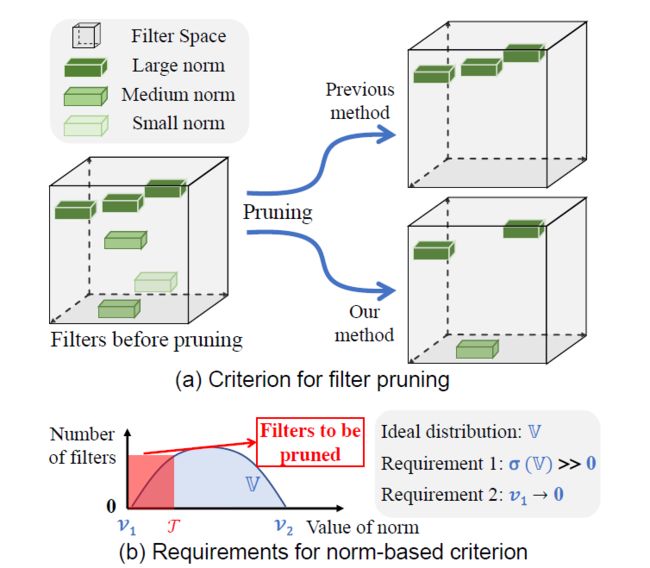
[16] Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration(CVPR2019) ,这是CVPR 2019的一篇oral,简称 FPGM。如下图,这篇论文利用几何中位数(Geometric Median)进行模型剪枝,属于对filters的剪枝。把绝对重要性拉到相对层面,认为与其他filters太相似的filter不重要。
[17] Jian-Hao Luo, Jianxin Wu, Weiyao Lin.《ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression》 ICCV2017 以filter(卷积核)为单位,根据该层filter的输出来判断该filter是否对结果有贡献,如果没有贡献或贡献很小,则直接把这个filter去掉,因此文章的核心就在于filter的选择方式。
这篇论文的结果:VGG-16可以达到减少3.31倍FLOPs和16.63倍的压缩,top-5准确率只下降0.52%。
[18] Yihui He, Ji Lin, Zhijian Liu, Hanrui Wang, Li-Jia Li, Song Han. Amc: Automl for model compression and acceleration on mobile devices.ECCV2018 也有很好的工作,首先提出利用AutoML进行模型压缩,该模型利用强化学习来提供模型压缩策略。这是一篇非常成功的论文,有时间得看一看。17页的论文,只有一张系统框图和几份实验结果,但ECCV不分成两列,看起来还是挺快的。

[19] Shaohui Lin, Rongrong Ji, Chenqian Yan, Baochang Zhang, Liujuan Cao, Qixiang Ye, Feiyue Huang, and David Doermann. Towards optimal structured cnn pruning via generative adversarial learning,ICCV2019. 提出了一种有效的结构化剪枝方法,这一篇提出了基于生成对抗学习的的剪枝策略,我没有了解过生成对抗学习的方法,大体是针对finetune的时间太长、hard pruning mask无法灵活地优化学习过程、训练和正则化过程依赖于样本target等不足提出了生成对抗(GAL)的策略。

[20] Carl Lemaire, Andrew Achkar, and Pierre-Marc Jodoin. Structured pruning of neural networks with budget-aware regularization,ICCV2019,为深度cnn引入了一种预算正则化剪枝框架,该框架自然适合传统的神经网络训练。该框架由一个可学习的掩蔽层、一个新的预算感知目标函数和知识蒸馏的使用组成。
[21] Zhonghui Y ou, Kun Y an, Jinmian Y e, Meng Ma, and Ping Wang. Gate decorator: Global filter pruning method for accelerating deep convolutional neural networks,NIPS2019,提出了一种全局滤波修剪算法Gate Decorator,该算法通过将CNN模型的输出乘以通道缩放因子(即GATE)来对其进行变换,并在CIFAR数据集上取得了最新的结果。它提出了两部分,一部分是用来解决GFIR问题的Gate Decorator算法,另一部分是用来提高剪枝精度的Tick-Tock剪枝框架。此外,作者还提出了group剪枝技术来解决在使用ResNet这样的有shortcut结构的网络进行网络剪枝时遇到的约束剪枝(Constraint Pruning )问题。在ImageNet上的ResNet-50,论文的实验结果在FLOPs上可以达到40%的修剪,而却比baseline的精度提高0.31%。
[22] Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, and Trevor Darrell. Rethinking the value of network pruning,这篇2019年的ICLR论文认为网络继承的权重并不重要,那既然weights不重要了,重要的自然只剩下模型结构了。所以他认为剪枝的本质是网络结构的优化。通过大量的实验结果,深入分析初始化对剪枝的影响。这篇文章做了一些实验,还对比了17年Liu这篇文章和15年Han等人的实验复现对比,但是显然和我的复现结果有一些出入,贴图如下:
也不知道为什么不拿finetune以后的结果对比,而且蓝色的线parameter为2.49M, 3.36M,4.77M,6.59M时,在我的复现中精度应该是完全一样的,和作者有一点出入。

[23] Y . He, X. Zhang, and J. Sun, Channel pruning for accelerating very deep neural networks,ICCV 2017,是在Face++完成的,应该是早期对通道做剪枝的工作之一。这里作者进行channel selection的方式是引入了β作为mask,而且用了LASSO回归的方法。开源地址在: http://arxiv.org/abs/1707.06168
在单层上和first k selects和max response两种方法做了对比,文章比较基础,在今天的视角看来有些结论是理所应当的,比如finetune之后精度会上升很多。有兴趣可以看一看。 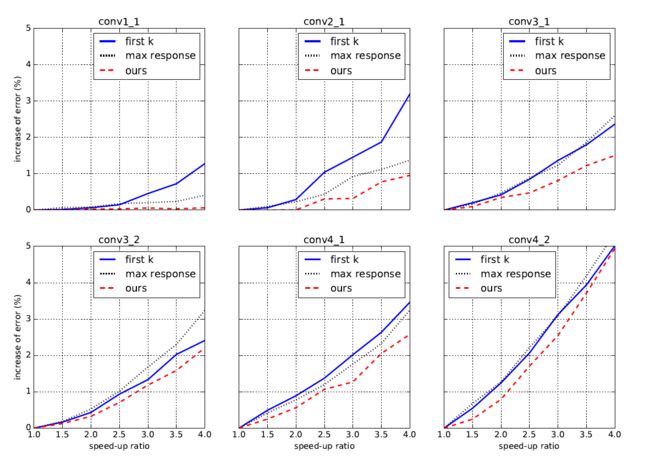
[24] Mingbao Lin, Rongrong Ji, Y an Wang, Yichen Zhang, Baochang Zhang, Y onghong Tian, and Ling Shao. Hrank: Filter pruning using high-rank feature map,2020CVPR Oral,根据输出feature map的秩来决定filters的排序,是一个非常通俗但有效的剪枝衡量方法。
以上是它的Pipeline,上图左栏是特征图的生成,然后生成特征图的秩,这一步很耗时间,要训基本一天左右,得到特征图的秩后,就是按照特征图的秩进行一个排序,对应生成低秩的filters我们把它踢掉,生成高秩的filters我们加以保留,而本文还采取了一个操作,就是对生成秩的大小排在中间的filters我们做一个frozen处理,这篇论文也是我早期复现的一篇,结果算是非常好的。这里贴一下复现结果:


2.2 Neuron-wise pruning:
[25] Ruichi Y u, Ang Li, Chun-Fu Chen, Jui-Hsin Lai, Vlad I Morariu, Xintong Han, Mingfei Gao, Ching-Y ung Lin, and Larry S Davis. Nisp: Pruning networks using neuron importance score propagation.这篇ICCV21018的工作这篇文章考虑到以前我们剪枝只考虑了单层或者两层的误差,但是实际上有些通道你一开始就减掉了,但你不知道他之后会对后面的通道产生多大的影响,因为有的时候只是当时importance低,但是后面可能会对其他通道有很大的影响造成压缩后精度下降的比较厉害,所以作者提出能不能对倒数第二层先剪枝,就是向前评估一下每个通道的重要性得分,通过优化最终响应层的重构误差,并为每个通道传播一个importance score,再结合这个重要性的分数去做剪枝。

2.3 Group-wise Pruning:
通道分组剪枝
就是对通道的分组剪枝,对通道进行分组剪枝其实已经是一个改进的方法了。但是他也有一个明显的弊端。
就是他移除的是某一层中所有的filters相同位置上的权重。但是,每个filters中无效的权重位置可能不同,所以这个方法解决不了这一点。
[26] 如图,CVPR 2016的《Fast convnets using group-wise brain damage》
和[27] NIPS 2016的《Learning structured sparsity in deep neural networks》介绍了对通道进行 分组剪枝的概念,如上图,提出通过group lasso regularization来学习神经网络中的结构化稀疏性。可以看到,分组后每次剪枝都是对每一层中filter的同一个位置剪去,使用“im2col”实现作为过滤器式和通道式修剪,可以有效地处理 分组式修剪。 
[28] IJCNN2019的这篇《Structured pruning for efficient convnets via incremental regularization》提出一种称为IncReg的动态的正则化方法改进了分组剪枝。开源代码在: https://github.com/mingsun-tse/caffe_increg
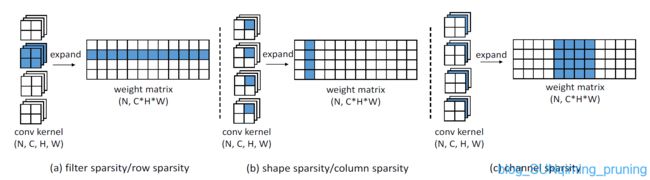
[29] Huizi Mao, Song Han, Jeff Pool, Wenshuo Li, Xingyu Liu, Y u Wang, and William J Dally. Exploring the granularity of sparsity in convolutional neural networks,ICCV2017,进一步探索了修剪粒度的完整范围,并评估它如何影响预测精度。它探索了稀疏性和预测精度之间的关系,设置了几种不同的剪枝粒度等级,分析不同粒度等级下的存储量和硬件效率。
实验结果如上,可见粗粒度比如减filter确实会造成很大的精度损失,论文提出剪枝就像是一个正则化。这篇纯研究粒度对稀疏性影响的论文确实很细腻。

[30] Huan Wang, Qiming Zhang, Y uehai Wang, Lu Y u, and Haoji Hu. Structured pruning for efficient convnets via incremental regularization.,IJCNN2019,通过提出一种动态正则化方法改进了分组剪枝。然而,分组剪枝去掉了某一层中所有过滤器中位于同一位置的权重。由于每个过滤器的无效位置可能不同,分组剪枝可能会导致网络丢失有效信息。相反,我们的方法保持每个滤波器彼此独立,从而可以产生一个更有效的网络结构。
2.4 Stripe Pruning
这就是上篇提到的今年的新工作,在filters里剪枝filter,是最近NeurIPS2020新提出来的工作,腾讯优图的论文,号称刷新了filter剪枝的SOTA效果,将这篇文章之前,先引用一些相关的论文:
[31] Zehao Huang and Naiyan Wang. Data-driven sparse structure selection for deep neural networks. ECCV, 2018.这篇论文也是17页的ECCV论文,Code is available at: https://github.com/huangzehao/
还是根据缩放因子作为importance的衡量,对应灰色的group,block,neuron缩放因子为0,就可以被剪枝掉,这篇的实验结果为:
不知道是为何,这些近年的剪枝paper的实验结果都比我最开始复现的Liu那篇Network slimming的结果要差,这里实验结果表明,vgg16参数量从5M-10M范围内,top1准确率都在94%以下,但是在Network slimming中参数量为3.36M到11.58M时,top1准确率都在95.53%,而且finetune之后更是达到了94%以上,参数量为4.77M时,更是达到了94.16%,远比这里的结果要好。
在Resnet164上的结果也一样不如17年的slimming.
[32] Aditya Kusupati, V . Ramanujan, Raghav Somani, Mitchell Wortsman, Prateek Jain, Sham M. Kakade, and Ali Farhadi. Soft threshold weight reparameterization for learnable sparsity. ICML2020,可学习稀疏性的软阈值权重重参数化,我觉得就是对激活函数中间一块的阈值做了一个处理。
[33] Kai Han, Y unhe Wang, Yixing Xu, Chunjing Xu, Dacheng Tao, and Chang Xu. Full-stack filters to build minimum viable cnns.来自诺亚方舟实验室2019年的开源项目。
[34] Ting Wu Chin, Ruizhou Ding, Cha Zhang, and Diana Marculescu. Towards efficient model compression via learned global ranking.2020-CVPR-Oral,它通过对不同的层所有的filters进行一个整体的排序,排序结果靠后的filters被剪枝掉,从而获得一组具有不同精度/延迟权衡的结构。
Code available at: https://github.com/cmu-enyac/LeGR
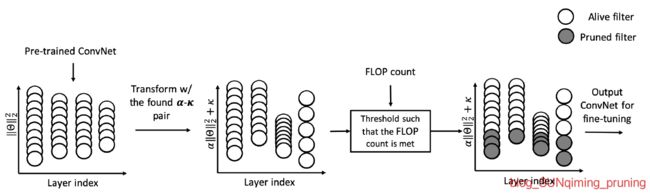
[35] Carl Lemaire, Andrew Achkar, and Pierre Marc Jodoin. Structured pruning of neural networks with budget-aware regularization,CVPR2019。可以控制prune的大小和速度,还用到了知识蒸馏。下面是它的对ResNet的pipeline和实验结果:
这篇论文做的实验很多,有时间的话我也会复现一下。
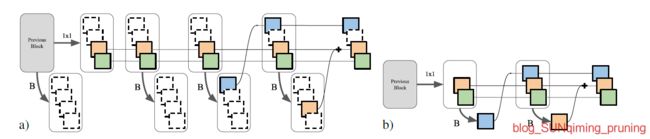
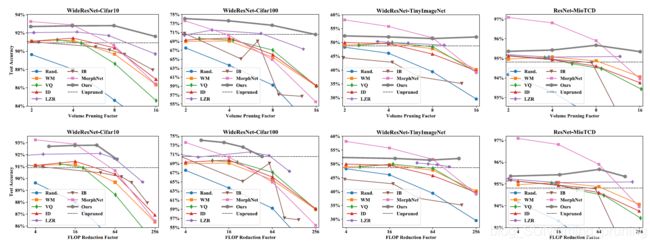
另外,也介绍一些端到端的模型剪枝方法,以端到端的方式联合剪枝滤波器和其他结构。具体地,通过定义一个新的目标函数和稀疏正则化来使baseline和网络的输出与该掩码对齐,从而引入软掩码来缩放这些结构的输出。有时间会整理一下在一些专用硬件上实现的论文,阅读需要时间,码字更不易,下次尽量多出少写,或者专出一些论文的详细阅读。
对filter和channel剪枝的工作有很多,各种算法层出不穷,但是这几年的paper各种算法Accuracy的提升很有限,虽然剪枝的主要目的并不在提升精度,但是从17年的那篇network slimming开始,对剪枝后的模型进行finetune之后精度明显超过baseline,而近几年的结果与17年的工作相比都没有一个明显的进步,而且剪枝率方面也一样。当然,此言的前提是针对vgg网络的调研。
好,接下来介绍这篇Pruning filter in filter,
★ {\color{LightPink} \bigstar} ★Pruning Filter In Filter, NIPS2020论文详解
2.4.1 Pipeline
这篇文章主要考虑的是神经网络的结构属性。他这里的做法很有启发性,结合了两种结构化和非结构化剪枝中的典型方法。就是对weights剪枝和对filters剪枝,因为这两种剪枝方法各有优劣。非结构化的剪枝在硬件方面需要有专用的库支持,但是它的压缩率较高,对filters剪枝在硬件方面更兼容,但在压缩率方面不如前者。所以作者提出了一个方法,叫做在filters中剪枝filter。
那这是怎么做的呢?如上图中一个kernel,它的长和宽是相等的,是k×k×c,那我们就可以按照他的size把它剪成k×k个条,比如一个3×3的卷积,我们就可以把它剪成9 个条纹,然后通过修剪整个条而不是剪掉整个filter,显然就可以实现比传统的filters pruning更精细的一个粒度。这个方法作者叫做SWP。
2.4.2 Related work
另外,有的说法是把prunr按照粒度分为零维→一维→三维,,比如Exploring the granularity of sparsity in convolutional neural networks,ICCV2017,他提出了四种粒度上的剪枝,其实实质就是我们列举出来的weights剪枝、神经元剪枝、通道剪枝和filters剪枝。

这与我们NIPS2020,pruning filter in filter中介绍的其实如出一辙,可见一篇好的论文对相关工作的总结也一定十分到位。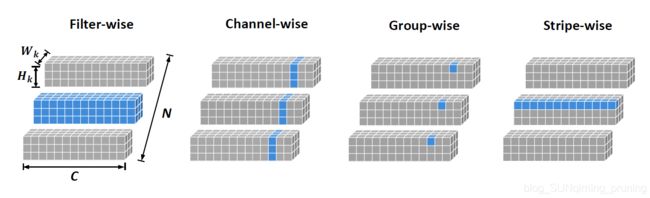
但是前三种scheme都有明显的弊端,前两个就不用讲了。就是他们的剪枝的细粒度不够,对filter就是每次都要减掉一个或者若干个filters,通道也是一样,就是每次都要剪掉若干组通道。对通道进行分组剪枝其实已经是一个改进的方法了。但是他也有一个明显的弊端。就是他移除的是某一层中所有的filters相同位置上的权重。但是,每个filters中无效的权重位置可能不同,所以这个方法解决不了这一点。swp可以保持每个filters彼此独立,所以更胜一筹。
这篇论文的作者跟rethinking the value of network pruning思路是一样的。都是认为网络的体系结构很重要。而且本文中作者认为,Filter本身的结构也很重要。而且他的观点是,内核越大的filters性能越好。就要提出一个形状的概念。这个形状是什么意思呢?比如这个图

这是通道的L1范数值的示意图。从这个图可以看出,filters中并非所有的条纹贡献都相等,对应L1范数非常低的条带就可以删除。那删除以后保留最少条数的,同时保持filters功能的形状就叫做最佳的Filter形状。所以将要解决的一个问题就是我们怎么找到最佳的形状,还提出了一种filters框架来学习这个最佳形状。
2.4.3 Filter Skeleton (FS) analysis
上面的pipeline就是作者提出的学习这个Filter shape的框架,假设第 l {\color{Blue} l} l个卷积层的权重 W l {\color{Blue} W^{l}} Wl的大小为 R N × C × K × K {\color{Blue} R^{N\times C\times K\times K}} RN×C×K×K,N是filter的数量,C是通道的维度,那么该层中FS的大小为 R N × C × K × K {\color{Blue} R^{N\times C\times K\times K}} RN×C×K×K,即Skeleton中的每个值对应于filter中的一个条带,每层中的Skeleton先用一个矩阵初始化。训练过程中,把filter的权重与FS相乘,Loss表达式为: L = ∑ ( x , y ) l o s s ( f ( x , W ⊙ I ) , y ) {\color{Blue} L=\sum_{(x,y)}^{}loss(f(x,W\odot I),y)} L=(x,y)∑loss(f(x,W⊙I),y)
经过推论,作者给出了用FS剪枝的Loss: L = ∑ ( x , y ) l o s s ( f ( x , W ⊙ I ) , y ) + α g ( I ) ) {\color{Blue} L=\sum_{(x,y)}^{}loss(f(x,W\odot I),y)+\alpha g(I))} L=∑(x,y)loss(f(x,W⊙I),y)+αg(I))

左图和右图分别表示baseline和FS在第一个卷积层上的权重分布。由实验和上图可以看出,对于某些数据集,(如CIFAR-10,)即使没有finetune,由SWP修剪的网络也能保持高性能。这是SWP区别于许多其他基于FP的修剪方法的特点,因为finetune是这些传统的剪枝方法三步走中的一步。而条纹剪枝之所以不需要微调是因为FS为会每个filter学习到最佳形状。通过prune掉不重要的条带,filter不会丢失很多有用的信息。相比之下,FP剪枝直接删除filter,就可能会损害网络学习到的信息。
SWP剪枝和FP剪枝的卷积分别为:
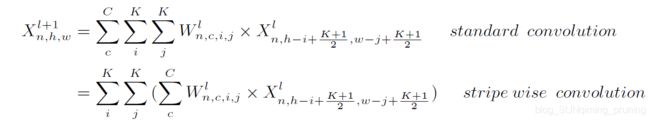
其中 X n , h , w l + 1 {\color{Blue} X_{n,h,w}^{l+1}} Xn,h,wl+1是第 l + 1 {\color{Blue} l+1} l+1层的特征图上的一个点。

2.4.4 Experiments
2.4.5 Rethinking
将每个条纹分为多个组,并修剪每个组中的权重。然而,这些非结构化剪枝方法的一个缺点是所得到的权重矩阵是稀疏的,这在没有专用硬件/库的情况下不能实现压缩和加速。所以虽然这个方法很新颖,但是还是只能在GPU上加速,至于在IC或者ASIC上就很难支持了。