[Leetcode]回溯算法——python版本
本篇文章根据labuladong的算法小抄汇总回溯算法的相关常见算法,采用python3实现
回溯算法框架(DFS)
-
回溯算法就是DFS算法(depth first searc,深度优先搜索算法),本质上是一种暴力穷举算法
-
回溯问题实际上就是决策树的遍历过程:
1、路径:已经做出的选择
2、选择列表:当前可以做的选择
3、结束条件:到达决策树底层,无法再做选择的条件
-
回溯算法的框架
result = []
def backtrack(路径,选择列表):
if 满足结束条件:
result.add(路径)
return
for 选择 in 选择列表:
做选择
backtrack(路径,选择列表)
撤销选择
全排列问题
问题:n个不重复的数,全排列
import copy
res = []
#主函数,输入一组不重复的数字,返回它们的全排列
def permute(nums):
track = [] #记录路径
backtrack(nums,track)
return res
def backtrack(nums,track):
#触发结束条件
if len(track) == len(nums):
track_ = copy.copy(track)
res.append(track_)
return
for i in range(len(nums)):
#排除不合法选择
if nums[i] in track:
continue
#做选择
track.append(nums[i])
#进入下一层决策树
backtrack(nums,track)
#取消选择
track.pop()
- 回溯算法不像动态规划存在重叠子问题可以优化,它就是纯暴力穷举,复杂度一般都很高
N皇后问题
问题:给定一个N*N的棋盘,让你放置N个皇后,使得它们不能互相攻击(皇后可以共计同一行、同一列、左上左下右上右下四个方向的任意单位)
class Solution:
def solveNQueens(self,n):
def backtrack(board,row):
if len(board) == row:
res.append(copy.deepcopy(board))
for col in range(len(board)):
if not self.isValid(board,row,col):
continue
board[row][col] = 'Q'
backtrack(board,row+1)
board[row][col] = '.'
res = []
board = [['.' for i in range(n)] for j in range(n)]
backtrack(board,0)
for i in range(res):
for j in range(n):
res[i][j] = "".join(res[i][j])
return res
def isValid(self,board,row,col):
n = len(board)
for i in range(row):
if row[i][col] == "Q":
return False
i = row - 1
j = col - 1
while (i >= 0) and (j >= 0):
if board[i][j] == "Q":
return False
i -= 1
j -= 1
i = row - 1
j = col + 1
while (i >= 0) and (j < n):
if board[i][j] == "Q":
return False
i -= 1
j += 1
return True
划分为k个相等子集
#数组视角,O(k^n)
def canPartitionKSubsets(nums,k):
if k > len(nums):
return False
sumNum = sum(nums)
if sumNum % k != 0:
return False
target = sumNum // k
bucket = [0 for i in range(k)]
nums.sort(reverse=True)
return backtrack(nums,0,bucket,target)
def backtrack(nums,index,bucket,target):
if index == len(nums):
for i in range(len(bucket)):
if bucket[i] != tarket:
return False
return True
for i in range(len(bucket)):
if bucket[i] + nums[index] > target:
continue
bucket[i] += nums[index]
if backtrack(nums,index+1,bucket,target):
return True
bucket[i] -= nums[index]
return False
#桶视角,O(k*2^n)
def canPartitionKSubsets(nums,k):
def backtrack(k,bucket,nums,0,used,target):
if k == 0:
return True
if bucket == target:
return backtrack(k-1,bucket,nums,0,used,target)
for i in range(start,len(nums)):
if used[i]:
continue
if nums[i] + bucket > target:
continue
used[i] = True
bucket += nums[i]
if backtrack(k,bucket,nums,i+1,used,target):
return True
used[i] = False
bucket -= nums[i]
return False
if k > len(nums):
return False
sumNum = sum(nums)
if sumNum % k != 0:
return False
used =[False for i in range(len(nums))]
target = sumNum // k
return backtrack(k,0,nums,0,used,target)
- 尽量少量多次,宁可二选一选k次,也不要k选1选一次。
求子集
#数学归纳,O(N*2^N)
def subsets(nums):
if len(nums) == 0:
return [[]]
n = nums.pop()
res = subsets(nums)
for i in range(len(res)):
x = copy.deepcopy(res[i])
res.append(res[i])
res[-1].append(n)
return res
#回溯
def subsets(nums):
def backtrack(nums,start,track):
res.append(track[:])
for i in range(start,len(nums)):
track.append(nums[i])
backtrack(nums,i+1,track)
track.pop()
track = []
res = []
backtrack(nums,0,track)
return res
求组合
def combine(n,k): #输出[1,..,n中k个数字的所有组合]
def backtrack(n,k,start,track):
if k == len(track):
res.append(track[:])
return
for i in range(start,n+1):
track.append(i)
backtrack(n,k,i+1,track)
track.pop()
res = []
if (k <= 0) or (n <= 0):
return res
track = []
backtrack(n,k,1,track)
return res
解数独
def solveSudoku(board):
def isValid(board,r,c,n):
for i in range(9):
if board[i][c] == n:
return False
if board[r][i] == n:
return False
if board[(r//3)*3 + i//3][(c//3)*3 + i%3] == n:
return False
return True
def backtrack(board,i,j):
m = 9
n = 9
if i == m:
return True
if j == n:
return backtrack(board,i+1,0)
if board[i][j] != ".":
return backtrack(board,i,j+1)
for num in range(1,10):
if not isValid(board,i,j,str(num)):
continue
board[i][j] = str(num)
if backtrack(board,i,j+1):
return True
board[i][j] = "."
return False
backtrack(board,0,0)
括号生成
合法括号的性质:
- 左括号数量一定等于右括号数量
- 对于一个合法的括号字符串组合p,必然对于任何0 <= i < len§都有p[0…i]中左括号数量大于等于右括号数量
def generateParenthesis(n):
def backtrack(left,right,track,res):
if right < left:
return
if (left < 0) or (right < 0):
return
if (left == 0) and (right == 0):
res.append(track[:])
return
track.append("(")
backtrack(left - 1,right,track,res)
track.pop()
track.append(")")
backtrack(left,right-1,track,res)
track.pop()
if n == 0:
return []
res = []
track=[]
backtrack(n,n,track,res)
return res
BFS算法框架
- 核心思想:把一些问题抽象成图,从一个点开始,向四周开始扩散
- BFS找到的路径一定最短,但空间复杂度可能比DFS大很多
- 常见场景:在一幅【图】中找到从起点start到终点target的最近距离
#计算从起点到终点的最近距离
def BFS(start,target):
q = [] #核心数据结构
q.append(start) #将起点加入队列
visited.append(start) #避免走回头路
step = 0 #记录扩散的步数
while len(q) != 0:
sz = len(q)
for i in range(sz):
cur
二叉树的最小高度
打开密码锁的最小步数
数据结构
二叉树
翻转二叉树
class TreeNode:
def __init__(self,val=0,left=None,right=None):
self.val = val
self.left = left
self.right = right
class Solution:
def invertTree(self,root):
if root is None:
return None
tmp = root.left
root.left = root.right
root.right = tmp
self.invertTree(root.left)
self.invertTree(root.right)
return root
填充二叉树节点的右侧指针
def connect(root):
if root is None:
return None
connectTwoNode(root.left,root.right)
return root
def connectTwoNode(node1,node2):
if (node1 is None) or (node2 is None):
return
node1.next = node2
connectTwoNode(node1.left,node1.right)
connectTwoNode(node2.left,node2.right)
connectTwoNode(node1.right,node2.left)
二叉树展开为链表
def flatten(root):
if root is None:
return None
flatten(root.left)
flatten(root.right)
left = root.left
right = root.right
root.left = None
root.right = left
p = root
while p.right is not None:
p = p.right
p.right = right
构造最大二叉树
#超过递归深度
def constructMaximumBinaryTree(nums):
return build(nums, 0, nums.length - 1)
def build(nums, lo , hi):
if lo > hi:
return None
index = -1
maxVal = float("-inf")
for i in range(lo,hi+1):
if maxVal < nums[i]:
maxVal = nums[i]
index = i
root = TreeNode(maxVal)
root.left = build(nums,lo,index-1)
root.right = build(nums,index+1,hi)
return root
通过前序和中序遍历结果构造二叉树
def buildTree(preorder,inorder):
return build(preorder,0,len(preorder)-1,inorder,0,len(inorder)-1)
def build(preorder,preStart,preEnd,inorder,inStart,inEnd):
if preStart > preEnd:
return None
rootVal = preorder[preStart]
index = 0
for i in range(inStart,inEnd+1):
if inorder[i] == rootVal:
index = i
break
root = TreeNode(rootVal)
leftSize = index - inStart
root.left = build(preorder,preStart+1,preStart+leftSize,inorder,inStart,index-1)
root.right = build(preorder,preStart+leftSize+1,preEnd,inorder,index+1,inEnd)
return root
通过中序和后序遍历结果构造二叉树
class TreeNode:
def __init__(self,val=0,left=None,right=None):
self.val = val
self.left = left
self.right = right
def buildTree(inorder,postorder):
def build(inorder,instart,inend,postorder,poststart,postend):
if instart > inend:
return None
rootValue = postorder[postend]
for i in range(instart,inend+1):
if inorder[i] == rootValue:
index = i
break
root = TreeNode(rootValue)
leftSize = index-instart
root.left = build(inorder,instart,index-1,postorder,poststart,poststart+leftSize-1)
root.right = build(inorder,index+1,inend,postorder,poststart+leftSize,postend-1)
return root
return build(inorder,0,len(inorder)-1,postorder,0,len(postorder)-1)
寻找重复子树
class treeNode():
def __init__(self,val=0,left=None,right=None):
self.val = val
self.left = left
self.right = right
class Solution:
def findDuplicateSubtrees(self, root: Optional[TreeNode]) -> ist[Optional[TreeNode]]:
def traverse(root):
if root is None:
return None
left = traverse(root.left)
right = traverse(root.right)
subTree = str(left) + "," + str(right)+ "," + str(root.val)
fre = subTree_fre.setdefault(subTree,0)
if fre == 1:
res.append(root)
subTree_fre[subTree] = fre + 1
return subTree
res = []
subTree_fre = dict()
traverse(root)
return res
二叉树的序列化与反序列化
前序遍历
class Codec:
def serialize(self,root):
if root is None:
return "None"
return str(root.val)+","+str(self.serialize(root.left))+","+str(self.serialize(root.right))
def deserialize(self,data):
def dfs(datalist):
data = datalist.pop(0)
if data == "None":
return None
root = TreeNode(int(data))
root.left = dfs(datalist)
root.right = dfs(datalist)
return root
datalist = data.split(",")
return dfs(datalist)
- 中序遍历无法实现反序列化
层级遍历
class Codec:
def serialize(self,root):
if root is None:
return ""
queue = collections.deque([root])
res = []
while queue:
node = queue.popleft()
if node is None:
res.append("None")
continue
res.append(str(node.val))
queue.append(node.left)
queue.append(node.right)
return ",".join(res)
def deserialize(self,data):
if not data:
return []
dataList = data.split(",")
root = TreeNode(int(dataList[0]))
queue = collections.deque(root)
i = 1
while queue:
node = queue.popleft()
if dataList[i] != "None":
node.left = TreeNode(int(dataList[i]))
queue.append(node.left)
i += 1
if dataList[i] != "None":
node.right = TreeNode(int(data))
queue.append(node.right)
i += 1
return root
扁平化嵌套列表迭代器
class NestedIterator:
def __init__(self,nestedList):
self.q = collections.deque()
self.dfs(nestedList)
def dfs(self,nestedList):
for elem in nestedList:
if elem.isInteger():
self.q.append(elem.getInteger())
else:
self.dfs(elem.getList())
def next(self):
return self.q.popleft()
def hasNext(self):
return len(self.q)
二叉树的最近公共祖先LCA
def lowestCommonAncestor(root,p,q):
if root is None:
return None
if (root == p) or (root == q):
return root
left = lowestCommonAncestor(root.left,p,q)
right = lowestCommonAncestor(root.right,p,q)
if (left is not None) and (right is not None):
return root
if (left is None) and (right is None):
return None
return right if left is None else left
完全二叉树的节点个数
完全二叉树:
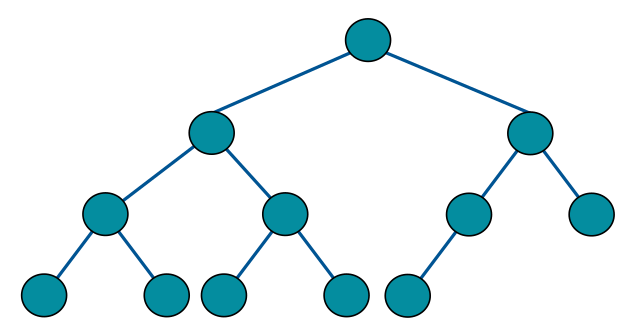
满二叉树:
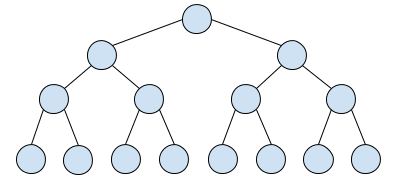
#普通二叉树,时间复杂度O(N)
def countNodes(root):
if root is None:
return 0
return 1 + countNodes(root.left) + countNodes(root.right)
#满二叉树,节点总数和树的高度呈指数关系
def countNodes(root):
h = 0
while root:
root = root.left
h += 1
return pow(2,h) - 1
#完全二叉树,时间复杂度O(logN*logN)
def countNodes(root):
if root is None:
return 0
l = root
r = root
hl = 0
hr = 0
while l:
l = l.left
hl += 1
while r:
r = r.right
hr += 1
if hl == hr:
return pow(2,hl) - 1
return 1 + countNodes(root.left) + countNodes(root.right)
- 由于完全二叉树的性质,其子树一定有一棵是满的
递归改迭代
stk = collections.deque()
#左侧遍历到底,存入栈
def pushLeftBranch(p):
while p:
#前序遍历代码位置
stk.append(p)
p = p.left
def traverse(root):
visited = TreeNode(-1) #指向上一次遍历完的子树根节点
pushLeftBranch(root)
while stk:
p = stk[-1]
if ((p.left is None) or (p.left == visited)) and (p.right != visited):
#中序遍历代码位置
pushLeftBranch(p.right)
if (p.right is None) or (p.right == visited):
#后序遍历代码位置
visited = stk.pop(-1)
- 除了BFS层级遍历外,二叉树还是用递归,因为递归最符合二叉树结构他点
二叉搜索树(BST)
-
BST特点:
1、对于BST的每个节点node,左子树节点的值 < node的值 < 右子树节点的值
2、对于BST的每个节点node,左子树和右子树都是BST
3、BST的中序遍历结果是有序的(升序)
寻找第K小的元素
class Solution:
def kthSmallest(self, root: Optional[TreeNode], k: int) -> int:
self.res = 0
self.rank = 0
self.traverse(root,k)
return self.res
def traverse(self,root,k):
if root is None:
return None
self.traverse(root.left,k)
self.rank += 1
if self.rank == k:
self.res = root.val
return
self.traverse(root.right,k)
BST转化累加树
class Solution():
def convertTree(root):
def convert(root):
if root is None:
return None
convert(root.right)
self.sum += root.val
root.val = self.sum
convert(root.left)
self.sum = 0
convert(root)
return root
判断BST合法性
def isValidBST(root):
return isValidBST(root,None,None)
def isValidBST(root,min,max):
if root is None:
return True
if min is not None and root.val <= min.val:
return False
if max is not None and root.val >= max.val:
return False
return isValidBST(root.left,min,root) and isValidBST(root.right,root,max)
在BST中搜索元素
def search(root,val):
if root is None:
return None
if val > root.val:
return search(root.right,val)
if val < root.val:
return search(root.left,val)
return root
在BST中插入一个数
def insertIntoBST(root,val):
if root is None:
return TreeNode(val)
if val > root.val:
root.right = insertIntoBST(root.right,val)
if val < root.val:
root.left = insertIntoBST(root.left,val)
return root
在BST中删除一个数
class Solution:
def deleteNode(self, root: Optional[TreeNode], key: int) -> Optional[TreeNode]:
def getMin(root):
while root.left is not None:
root = root.left
return root
if root is None:
return None
if root.val == key:
if root.left is None:
return root.right
elif root.right is None:
return root.left
minNode = getMin(root.right)
minNode.left = root.left
minNode.right = root.right
root = minNode
elif root.val < key:
self.deleteNode(root.right,key)
else:
self.deleteNode(root.left,key)
return root
不同的二叉搜索树
class Solution:
def numTrees(self, n: int) -> int:
memo = [[0 for i in range(n+1)] for j in range(n+1)]
return count(1,n,memo)
def count(lo,hi,memo):
if lo > hi:
return 1
if memo[lo][hi] != 0:
return memo[lo][hi]
res = 0
for i in range(lo,hi+1):
left = count(lo,i-1,memo)
right = count(i+1,hi,memo)
res += left * right
memo[lo][hi] = res
return res
不同的二叉搜索树②
def generateTrees(n):
if n == 0:
return TreeNode()
return build(1,n)
def build(lo,hi):
res = []
if lo > hi:
return r[None]
for i in range(lo,hi+1):
leftTree = build(lo,i-1)
rightTree = build(i+1,hi)
for left in leftTree:
for right in rightTree:
root = TreeNode(i)
root.left = left
root.right = right
res.append(root)
return res
二叉搜索子树的最大键值和
import sys
sum = 0
def maxSumBST(root):
traverse(root)
return maxSum
def traverse(root): #返回[isBST,min,max,sum]
if root is None:
return [1,sys.maxsize,-sys.maxsize-1,0]
left = traverse(root.left)
right = traverse(root.right)
res = [0 for i in range(4)]
if (left[0] == 1) and (right[0] == 1) and (left[2] < root.val < right[1]):
#以root为根的二叉树是BST
res[0] = 1
res[1] = min(left[1],root.val)
res[2] = max(right[2],root.val)
res[3] = left[3] + right[3] + root.val
maxSum = max(maxSum,res[3])
else:
res[0] = 0
return res
- BST相关问题:(1)利用BST左小右大的特性提升算法效率;(2)中序遍历的特性(有序)满足题目要求
- 如果当前节点要做的事情需要通过左右子树的计算结果推导出来,就要用到后序遍历
- 要尽可能避免递归函数中调用其他递归函数