微服务架构(4)——分布式事务
目录:
1、什么是分布式事务
2、分布式事务解决方案
3、集成seata
4、seata原理
什么是分布式事务
在服务拆分之后,完成某一个功能可能需要横跨多个服务,操作多个数据库。
之前操作单一的数据库,只需要保证在这个数据库中执行的操作要么一起成功,要么一起失败。这种事务叫做本地事务。
而操作多个数据库,要保证多个数据库里的操作一起成功或失败的事务就是分布式事务。
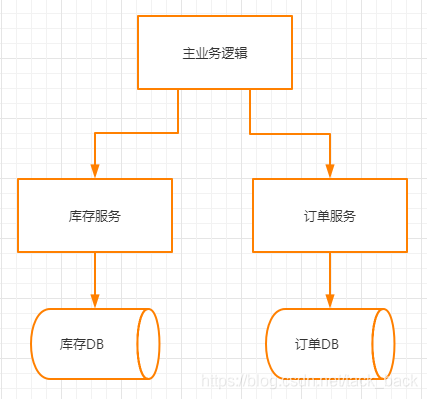
上图中有库存服务和订单服务,库存服务和订单服务都有自己单独的数据库。
在一个下单操作中,需要先调用库存服务减去相应的库存,然后再调用订单服务添加一笔订单。
在正常情况下库存正常扣减了,订单也正常插入了,这时两个库的数据是一致的。
但是在非正常情况下,有可能库存扣减了,但在订单服务进行订单插入的时候,因为数据库宕机或者订单服务宕机等其它因素,导致订单插入失败了。这个时候两个库的数据就 不一致了。明明库存减少了,但是却没有对应的订单信息。
分布式事务就是用来保证多个数据源直接数据的一致性。
分布式事务解决方案
1 两阶段提交(2PC)
在两阶段提交中,存在两个角色,事务协调者和事务参与者。
第一阶段:
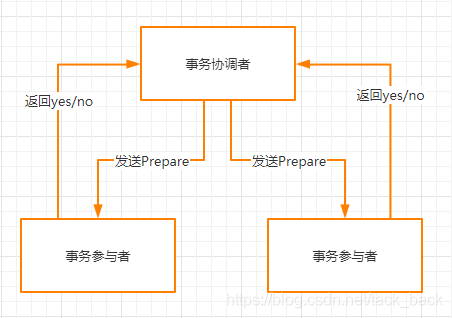
在这一阶段中,事务协调者先发送Prepare消息给各个事务参与者,事务参与者先在自己本地执行相关的数据库操作,但是不进行提交。
执行成功了就给事务协调者返回yes,执行失败者返回no。
第二阶段:
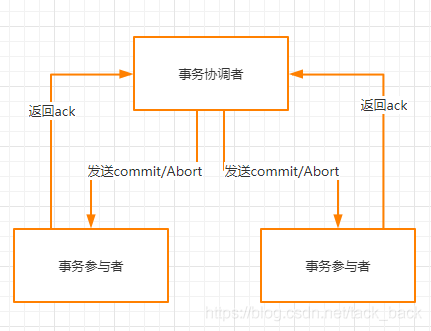
第二阶段事务协调者会根据第一个阶段,各个事务参与者返回的信息来决定发送commit还是abort。
要是第一个阶段所有的事务参与者都是返回的yes,那么这时事务协调者就会发送commit的消息给事务参与者,告诉他们可以进行提交操作了。
事务参与者提交完成后就返回ack,告诉事务协调者已经提交完成。整个分布式事务玩成。
要是第一阶段有任何一个事务参与者返回的是no,那么这时事务协调者就会发送abort的消息给所有事务参与者,告诉他们本次执行不成功,需要进行回滚。
各个事务参与者就对第一阶段执行的操作进行回滚,然后返回ack消息。
存在的问题
1、性能问题:在事务协调者发送Prepare消息后,事务参与者会执行相关的数据库操作,但是不提交。这个时候对应的数据就被锁定了,其它的请求是无法操作这个数据,只有等事务协调者发送commit或者abort消息后,事务参与者提交或者回滚事务才能释放这个锁。
2、单点问题:要是在事务协调者发送Prepare后,事务协调者就宕机了。参与者一直无法接收到commit或者abort消息,事务就一直无法提交,导致资源一直被锁定。
3、数据不一致问题:事务协调者发送的commit消息,由于网络等一些原因,导致部分参与者收到了commit消息提交了事务,而另一部分没有收到没有进行事务提交,导致数据不一致。
2 补偿事务(TCC)
TCC事务是Try、Commit、Cancel三种指令的缩写,其逻辑模式类似于2PC两阶段提交,但是实现方式是在代码层面人为实现的。
第一阶段
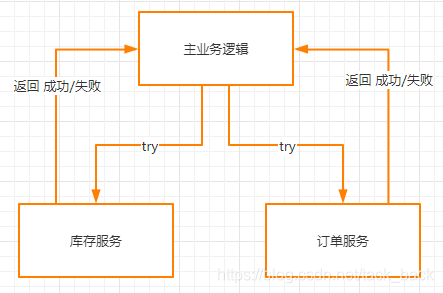
在try这个阶段中,主要用于系统做检测和锁定资源。主业务逻辑会先去调用库存服务和订单服务的try接口,这个接口需要库存服务和订单服务提供。
比如说正常的逻辑是库存服务商品数量减1,订单服务插入一条订单。
而现在try接口里面的逻辑不是直接把商品数量减1,而是添加一个字段叫做锁定商品数量。把需要减去的商品数量存储在这个字段。
订单服务也不是直接插入一条订单数据,而是插入一条状态为未支付的数据。
第二阶段
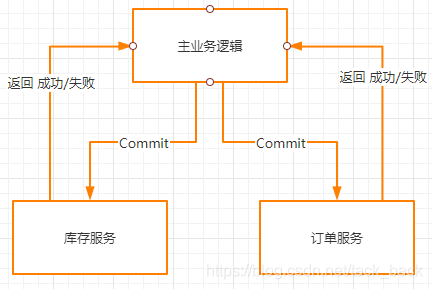
在commit这个阶段,就是真正执行业务操作。commit接口的逻辑就是把之前库存服务锁定数量字段修改为原来的0,订单服务将订单状态修改为已支付状态。这样就完成了一个下单的操作。
第三阶段
在cancel阶段中主要是对之前的操作进行还原,比如说在commit这个阶段中,订单服务commit失败了。那么这个时候数据就 不一致了。这时就需要对数据进行还原。需要对库存服务的锁定数量字段的数据还原回商品数据的字段,订单服务插入的为完成状态的订单数据也需要删除。
存在的问题
1、数据不一致问题:还是无法完全解决数据不一致的问题,因为在commit阶段和cancel阶段还是可能存在失败的问题,最终导致数据不一致。
2、实现起来比较复杂,需要针对不同的操作写对应的 try、commit、cancel的代码。
3 可靠消息最终一致性
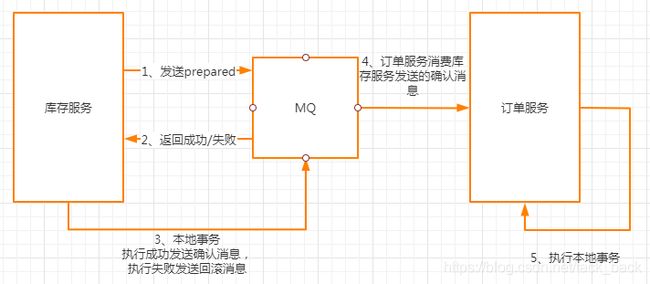
这个方案主要是借助MQ来实现消息的最终一致性。
1、库存服务先给MQ发送一条prepared,这时如果发送失败了就取消后面的的操作,返回下单失败。
2、发送成功了的话,就执行本地扣减库存的操作,扣减成功了就发送一条确认消息给MQ,失败的话就发送回滚消息。
3、MQ收到了确认消息,那么就会被订单服务给消费到,订单服务就可以执行插入订单的逻辑。
在2步骤中,有可能MQ会因为网络的原因没有收到库存服务发送的确认消息,MQ会轮询prepared状态的消息,去库存服务确认这个消息是否需要回滚或是提交,库存服务查询到这个商品已经扣减了就进行提交,没有扣减就进行回滚。
在3步骤中,如果订单服务插入订单失败,那就进行重试。重试多次后还是不行,可以设置消息提醒,进行人工干预。
存在的问题
数据只是最终一致,有可能下完单后,立刻去查订单,发现不存在订单。要过一会儿才能查询得到。
集成seata
在项目里集成seata来解决分布式事务问题。
1、部署seata server
我这边是通过docker 来进行部署的。
先通过命令
docker pull seataio/seata-server
来拉取seata-server镜像。
然后通过命令
docker run -d --name seata-server -p 8091:8091 -e SEATA_IP=124.77.18.18 -e STORE_MODE=file seataio/seata-server
启动seata server。
最后我们通过 docker ps 看到 seata server已经启动成功了。
![]()
2、添加seata
在项目的pom文件里添加seata依赖。
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
在dubboclient和dubboserver里面都需要添加。
这里需要注意一下Spring Cloud、Spring Cloud Alibaba和 Spring Boot之间版本的对应关系,可以参照 版本说明 进行选择搭配。
3、添加seata配置文件
需要将seata的配置文件file.config和registry.conf,放到resource目录下面。
这两个配置文件直接从github里面拿。dubboclient和dubboserver都需要添加。
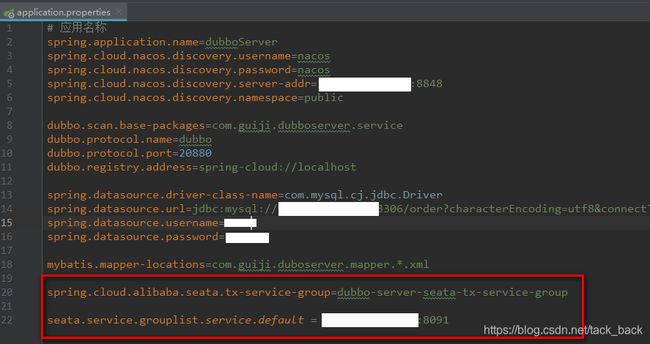
4、修改配置文件
在dubboclient和dubboserver的application.proproperties配置文件里面分别加上下面两行配置
// seata事务组名称,与file.config 里面 vgroupMapping 一致
spring.cloud.alibaba.seata.tx-service-group=dubbo-server-seata-tx-service-group
//seata server 部署地址
seata.service.grouplist.service.default = 12.7.1.1:8091
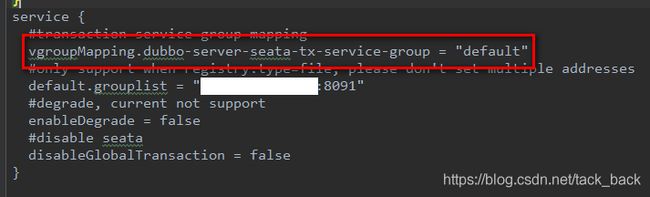
修改dubboclient和dubboserver的file.config文件。
service {
#transaction service group mapping
vgroupMapping.dubbo-client-seata-tx-service-group = "default"
#only support when registry.type=file, please don't set multiple addresses
default.grouplist = "12.7.1.1:8091"
#degrade, current not support
enableDegrade = false
#disable seata
disableGlobalTransaction = false
}
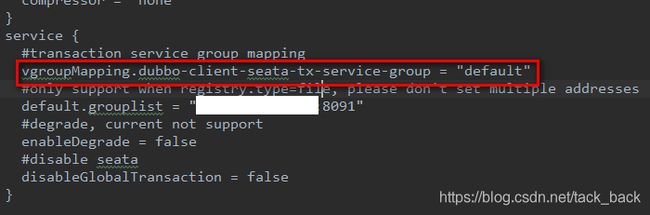
把vgroupMapping后面的那一串字符改成,application.proproperties里面配置的事务组名称。
dubboclient配置:

dubboserver配置:
5、创建UNDO_LOG 表
需要创建回滚日志表来记录回滚的日志,用于分布式事务提交失败时,回滚相关数据。
需要在所有涉及到分布式事务的库中创建这个表。
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;

6、使用
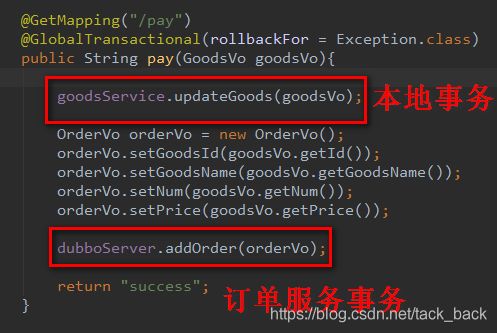
上述步骤都做完了之后,就只需要在涉及分布式事务的方法里面加上@GlobalTransactional注解,就能解决分布式事务的问题了。
seata原理
Seata框架中一个分布式事务包含3中角色:
Transaction Coordinator (TC): 事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚。
Transaction Manager ™: 控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议。
Resource Manager (RM): 控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚。
TC也就是我们部署的seata server这个服务。
TM和RM的实现逻辑就是在我们项目中引入的seata的这个依赖包里面。
分布式事务在Seata中的执行流程:
1、TM 向 TC 申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的 XID。
2、XID 在微服务调用链路的上下文中传播。
3、RM 向 TC 注册分支事务,接着执行这个分支事务并提交(重点:RM在第一阶段就已经执行了本地事务的提交/回滚),最后将执行结果汇报给TC。
4、TM 根据 TC 中所有的分支事务的执行情况,发起全局提交或回滚决议。
5、TC 调度 XID 下管辖的全部分支事务完成提交或回滚请求。
上述流程结合我们的项目来理解就是
1、当看到方法中加了@GlobalTransactional注解时,表明涉及到分布式事务,这时TM就会发送一个请求到TC申请一个全局唯一的XID。
2、在调用订单服务的时候,会带上这个XID。
3、在订单服务执行添加订单数据操作的时候,RM就会向TC注册分支事务,并且会生成一条回滚的日志,比如这里是添加一条订单数据,那么生成的回滚日志就是删除一条订单数据。然后把添加一条订单的操作和保存回滚日志到undo_log里面的操作都在一个事务里提交。这里就会一起成功或者一起失败。最终会把成功或者失败的结果返回给TC。
4、TM要是在TC中得到的是所有分支事务都执行成功,也就是说库存服务扣减库存成功,订单服务增加订单也成功,那么就发起提交。
要是有一个事务执行失败,则发起回滚。
5、TC根据发起的提交或是回滚命令来决定分支事务是否执行回滚的操作,就是执行存储在undo_log里面的回滚命令。