Java基础之数组与集合
Java基础之数组与集合
- 一、数组
- 二、冒泡排序算法
- 三、选择排序算法
- 四、二维数组
- 五、Arrays 工具
- 六、宠物管理系统
- 七、集合 Collection
- 八、List
- 九、重写 equals 方法
- 十、Map
- 十一、Set
- 十二、equals() 与 hashCode()
- 十三、集合排序
- 十四、队列 Queue
- 十五、面向对象和面向过程的区别
一、数组
数组保存的是一组有顺序的、具有相同类型的数据。在一个数组中,所有数据元素的数据类型都是相同的。可以通过数组下标(索引)来访问数组,数据元素根据下标的顺序,在内存中按顺序存放。本节的主要内容是介绍数组的基础知识。
数组的定义:
数据类型 数组名 [] = new 数据类型[数组长度];
要想知道数组的大小可以使用数组的 length 属性 语法:数组名.length
初始化:
int arr [] = new int[12];
arr[0] = 12;
arr[1] = 15;
System.out.println(arr[1]);
注意 new int [12] 表示该数组只能存放 12 个元素,下标索引依次 0…11,不能使用 arr[12] 会报异常 java.lang.ArrayIndexOutOfBoundsException(索引越界异常)
案例:
创建一个 8 位的整数数组,利用循环赋值{1,3,5,7,9,11…},并打印输出数组。
int arr[] = new int[8];
for (int i = 0; i < arr.length; i++) {
arr[i] = i * 2 + 1;
}
System.out.println(Arrays.toString(arr));
当然数组也可以一边初始化一边赋值,此时数组的长度由后面装入的数字个数决定。
int arr[] = { 1, 2, 3, 4, 5, 6 };
数组遍历:从普通循环到增强 for 循环(也叫 foreach)
int arr[] = { 1, 2, 3, 4, 5, 6 };
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
for (int j : arr) {
System.out.println(j);
//此处的j就表示当前正在循环的那个元素,与上面的 arr[i] 等效
}
通过对比两种遍历方式发现:
- 使用普通循环可以获取索引,在很多必须用到索引的场景中只能使用普通循环。
- 使用 foreach 没有办法获取索引,但是代码看起来更精炼。
如上便是数组的基本操作,虽然在后面开发中用得不多,但是 jdk 底层很多地方都在使用数组,掌握数组是程序员必不可少的一步。
练习:
1.小写转大写:编写程序,输入一个只有字母的字符串,判断里面每个字符是否为小写字母,如果是,将它转换成大写字母,否则,不转换。
2.随机找小:首先创建一个长度是 5 的数组,然后给数组的每一位赋予一个 0-100 之间的随机整数,通过 for 循环,遍历数组,找出最小的一个值出来。备注:Math.random() 会得到一个 [0,1) 之间的随机浮点数。
3.数组合并:首先准备两个数组,他俩的长度是 5-10 之间的随机数,并使用 0-100 之间的随机数初始化这两个数组,然后准备第三个数组,第三个数组的长度是前两个的和,并把前两个数组合并到第三个数组中。
4.有 15 个基督徒和 15 个非基督徒在海上遇险,为了能让一部分人活下来不得不将其中 15 个人扔到海里面去,有个人想了个办法就是大家围成一个圈,由某个人开始从 1 报数,报到 9 的人就扔到海里面,他后面的人接着从 1 开始报数,报到 9 的人继续扔到海里面,直到扔掉 15 个人。由于上帝的保佑,15 个基督徒都幸免于难,问这些人最开始是怎么站的,哪些位置是基督徒哪些位置是非基督徒。
参考代码:
import java.util.Arrays;
import java.util.Scanner;
public class ListTest {
public static void main(String[] args) {
t3();
}
//基督教徒
private static void t4() {
boolean[] a = new boolean[30];
int count = 0;
int n = 1;
while (count < 15) {
for (int i = 0; i < a.length; i++) {
if (!a[i]) {
if (n % 9 == 0) {
a[i] = true;
count++;
}
n++;
n = n > 9 ? n - 9 : n;
}
}
}
System.out.println(Arrays.toString(a));
}
/**
* 数组合并
*/
private static void t3() {
int i1 = (int) (Math.random() * 6 + 5);
int i2 = (int) (Math.random() * 6 + 5);
int arr1[] = new int[i1];
int arr2[] = new int[i2];
for (int i = 0; i < arr1.length; i++) {
arr1[i] = (int) (Math.random() * 101);
}
for (int i = 0; i < arr2.length; i++) {
arr2[i] = (int) (Math.random() * 101);
}
System.out.println("第一个数组" + Arrays.toString(arr1));
System.out.println("第二个数组" + Arrays.toString(arr2));
int arrAll[] = new int[arr1.length + arr2.length];
for (int i = 0; i < arrAll.length; i++) {
if (i < arr1.length) {//如果小于第一个数组的长度时,对位赋值
arrAll[i] = arr1[i];
} else {
arrAll[i] = arr2[i - arr1.length];
}
}
//优化后,循环次数变小
// for (int i = 0; i < arr1.length || i < arr2.length; i++) {
// if (i < arr1.length) {
// arrAll[i] = arr1[i];
// }
// if (i < arr2.length) {
// arrAll[arr1.length + i] = arr2[i];
// }
// }
System.out.println("合并后数组" + Arrays.toString(arrAll));
}
/**
* 2.随机找小
*/
private static void t2() {
int[] arr = new int[5];
//填充随机数
for (int i = 0; i < arr.length; i++) {
arr[i] = (int) (Math.random() * 101);
}
//寻找最小值
int min = arr[0];
for (int i = 1; i < arr.length; i++) {
if (min > arr[i]) {
min = arr[i];
}
}
System.out.println("最小值:" + min);
System.out.println(Arrays.toString(arr));
}
/**
* 1.小写转大写
*/
private static void t1() {
Scanner scanner = new Scanner(System.in);
System.out.println("请输入一个包含字母的字符串");
String s = scanner.nextLine();
char[] chars = s.toCharArray();
for (int i = 0; i < chars.length; i++) {
char c = chars[i];
if (c >= 'a' && c <= 'z') {
chars[i] -= 'a' - 'A';//'a' - 'A' 表示大写字母与小写字母 ascii 码的差值
}
//此处使用三目运算符使可读性更差
//chars[i] = (chars[i] >= 'a' && chars[i] <= 'z') ? (char) (chars[i] - ('a' - 'A')) : chars[i];
}
String string = new String(chars);
System.out.println(string);
scanner.close();
}
}
二、冒泡排序算法
排序是将一群数据,按照值的递增(即由小到大)或递减(即由大到小)的次序重新排列的过程。
冒泡排序(Bubble Sorting)的基本思想是:通过依次从前向后(从下标 0 的元素开始),依次比较相邻元素的大小,若发现前面大于后面则交换,使值较大的元素逐渐从前部移向后部(从下标较小的单元移向下标较大的单元),就象水底下的气泡一样逐渐向上冒。
因为排序的过程中,最大的元素不断往后靠,循环的判断的次数也在不断减少,从而减少不必要的比较。
public class MainTest {
public static void main(String[] args) {
int arr[] = {8, 3, 2, 1, 7, 4, 6, 5};
for (int i1 = 0; i1 < arr.length; i1++) {
for (int i = 0; i < arr.length - 1 - i1; i++) {
if (arr[i] > arr[i + 1]) {
int temp = arr[i];
arr[i] = arr[i + 1];
arr[i + 1] = temp;
}
}
}
System.out.println(Arrays.toString(arr));
}
}
冒泡排序算法对学习算法比较有帮助,需要仔细琢磨。也是众多笔试重点,要求必须能手写该算法。
三、选择排序算法
选择排序(Select Sorting)也是一种简单的排序方法。它的基本思想是:第一次从 R[0]-R[n-1] 中选取最小值,与 R[0] 交换,第二次从 R[1]-R[n-1] 中选取最小值,与 R[1] 交换,第三次从 R[2]-R[n-1] 中选取最小值,与 R[2]交换,…,第 i 次从 R[i-1]-R[n-1]中选取最小值,与 R[i-1] 交换,…,第 n-1 次从 R[n-2]-R[n-1]中选取最小值,与 R[n-2] 交换,总共通过 n-1 次,得到一个按排序码从小到大排列的有序序列。
例如,给定 n=8,数组 R 中的 8 个元素的排序码为:(8,3,2,1,7,4,6,5)选择排序过程。
public class MainTest {
public static void main(String[] args) {
int arr[] = {8, 3, 2, 1, 7, 4, 6, 5};
int temp = 0;
for (int i1 = 0; i1 < arr.length; i1++) {
int min = arr[i1];
int minIndex = i1;
for (int i = i1 + 1; i < arr.length; i++) {
if (arr[i] < min) {
min = arr[i];
minIndex = i;
}
}
temp = arr[i1];
arr[i1] = min;
arr[minIndex] = temp;
}
System.out.println(Arrays.toString(arr));
}
}
注意:上面选择排序算法可以优化,在知道最小值索引的情况下,最小值其实可以随时获取,故上面案例中的变量 min 是可以省略的。
练习:
1.用增强型 for 循环找出整数数组中最大的那个数。
2.首先创建一个长度是 5 的数组,并填充 0-100 之间的随机数。使用 for 循环或者 while 循环,对这个数组实现反转效果。
3.编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符串 “”。
示例 1: 输入: [“flower”,“flow”,“flight”] 输出: “fl”
示例 2: 输入: [“dog”,“racecar”,“car”] 输出: “”
说明: 所有输入只包含小写字母 a-z 。
参考代码:
import java.util.Arrays;
public class ListTest {
public static void main(String[] args) {
t2();
}
/**
* 3.最长公共前缀
* 排序完成后,第一个和最后一个永远是差别最大的,比较两端极限即可
*/
private static void t32() {
String[] strings = {"flow", "flower", "fliwht"};
Arrays.sort(strings);//集合排序
System.out.println(strings);
String start = strings[0];//获取第一个字符串
String end = strings[strings.length - 1];//获取最后一个字符串
int length = Math.min(start.length(), end.length());
//获取里面最短的字符串的长度
int i;//记录不同时的索引
for (i = 0; i < length && start.charAt(i) == end.charAt(i); i++) ;
System.out.println(start.substring(0, i));//substring 字符串切割
}
/**
* 3.最长公共前缀
*/
private static void t31() {
String strings[] = {"flower", "flow", "flight"};
String s = strings[0];
char[] chars = s.toCharArray();
int endIndex = 0;
for (int i = 1; i < strings.length; i++) {
String string = strings[i];
char[] temp = string.toCharArray();
for (int j = 0; j < temp.length; j++) {
if (j == chars.length - 1) {
break;
}
if (chars[j] != temp[j]) {
endIndex = j;
chars[j] = ' ';
}
}
}
System.out.println(Arrays.copyOfRange(chars, 0, endIndex));
}
/**
* 2.反转数组
*/
private static void t2() {
int arr[] = new int[5];
for (int i = 0; i < arr.length; i++) {
arr[i] = (int) (Math.random() * 101);
}
System.out.println("原数组:" + Arrays.toString(arr));
for (int i = 0; i < arr.length / 2; i++) {
int temp = arr[i];
arr[i] = arr[arr.length - i - 1];
arr[arr.length - i - 1] = temp;
}
System.out.println("反转后数组:" + Arrays.toString(arr));
}
/**
* 1.增强循环找最大值
*/
private static void t1() {
int arr[] = {12, 78, 2, 45, 63, 4, 546, 15, 64, 4, 6, 46, 456, 4};
int max = arr[0];
for (int i : arr) {
max = max < i ? i : max;//为max寻找最佳值
}
System.out.println(max);
}
}
四、二维数组
用于存储二维数据的集合,每个 arr[i] 又是一个一维数组。(int[][] arr1 = {{1, 3}, {2, 5}, {5, 8}};)
语法:类型 数组名[][] = new 类型[长度][长度];
String arr[][] = new String[10][10];
超级玛丽案例:
要求使用一个 10*10 的二维数组,全部填充 * 用户输入 x 与 y 的值,控制 @ 玛利亚的位置。
请输入x坐标
3
请输入y坐标
2
* * * * * * * * * *
* * @ * * * * * * *
* * * * * * * * * *
* * * * * * * * * *
* * * * * * * * * *
* * * * * * * * * *
* * * * * * * * * *
* * * * * * * * * *
* * * * * * * * * *
* * * * * * * * * *
代码:
public static void main(String[] args) {
String arr[][] = new String[10][10];
for (int i = 0; i < arr.length; i++) {
for (int j = 0; j < arr[i].length; j++) {
arr[i][j] = " * ";
}
}
Scanner scanner = new Scanner(System.in);
System.out.println("请输入x坐标");
int x = scanner.nextInt();
System.out.println("请输入y坐标");
int y = scanner.nextInt();
arr[y - 1][x - 1] = " @ ";
for (int i = 0; i < arr.length; i++) {
for (int j = 0; j < arr[i].length; j++) {
System.out.print(arr[i][j]);
}
System.out.println();
}
}
练习:
1.小岛周长:给定一个包含 0 和 1 的二维网格地图,其中 1 表示陆地 0 表示水域。
网格中的格子水平和垂直方向相连(对角线方向不相连)。整个网格被水完全包围,但其中恰好有一个岛屿(或者说,一个或多个表示陆地的格子相连组成的岛屿)。
岛屿中没有“湖”(“湖” 指水域在岛屿内部且不和岛屿周围的水相连)。格子是边长为 1 的正方形。网格为长方形,且宽度和高度均不超过 100 。计算这个岛屿的周长。
示例 :
输入:
[[0,1,0,0],
[1,1,1,0],
[0,1,0,0],
[1,1,0,0]]
输出: 16

2.在机器学习 AI 数学中二维数组又叫矩阵,编写一个方法完成矩阵的转置,即行转列。

参考代码:
public class ArrayTest {
public static void main(String[] args) {
int arr[][] = {
{0, 1, 0, 0},
{1, 1, 1, 0},
{0, 1, 0, 0},
{1, 1, 0, 0}
};
int[][] arr2 = t2(arr);
}
/**
* 2.在数学中二维数组又叫矩阵,编写一个方法完成正方形矩阵的转置,即行转列。
*/
private static int[][] t2(int[][] matrix) {
int a[][] = new int[matrix[0].length][matrix.length];
for (int i = 0; i < matrix[0].length; i++) {
for (int j = 0; j < matrix.length; j++) {
a[i][j] = matrix[j][i];
}
}
return a;
}
/**
* 1.小岛周长
* 只需要判断上边和左边,一旦有 1 则减 2
*/
private static int t12(int[][] arr) {
int count = 0;//1的数量
for (int[] ints : arr) {
for (int i : ints) {
if (i == 1) {
count++;
}
}
}
count *= 4;
for (int i = 0; i < arr.length; i++) {
for (int j = 0; j < arr[i].length; j++) {
int value = arr[i][j];
if (value == 1) {
//判断上面是否有1
if (i != 0) {
if (arr[i - 1][j] == 1) {
count -= 2;
}
}
//判断左面是否有1
if (j != 0) {
if (arr[i][j - 1] == 1) {
count -= 2;
}
}
}
}
}
return count;
}
/**
* 1.小岛周长
* 一旦出现 1 则表示可能有 4 个边被相加,如果遍历每个 1 时判断它的上下左右是否有 1,如果有则减 1
*/
private static int t11(int[][] arr) {
int count = 0;//1的数量
for (int[] ints : arr) {
for (int i : ints) {
if (i == 1) {
count++;
}
}
}
count *= 4;
for (int i = 0; i < arr.length; i++) {
for (int j = 0; j < arr[i].length; j++) {
int value = arr[i][j];
if (value == 1) {
//判断上面是否有1
if (i != 0) {
if (arr[i - 1][j] == 1) {
count -= 1;
}
}
//判断下面是否有1
if (i != arr.length - 1) {
if (arr[i + 1][j] == 1) {
count -= 1;
}
}
//判断左面是否有1
if (j != 0) {
if (arr[i][j - 1] == 1) {
count -= 1;
}
}
//判断右面是否有1
if (j != arr[i].length - 1) {
if (arr[i][j + 1] == 1) {
count -= 1;
}
}
}
}
}
return count;
}
}
五、Arrays 工具
Arrays 类位于 java.util 包中,主要包含了操纵数组的各种方法。
详见 jdk 开发文档
int[] myList = {1, 2, 3, 4};
int i = Arrays.binarySearch(myList, 1000);//二分法查找
Arrays.sort(myList);//排序
System.out.println(i);
System.out.println(Arrays.toString(myList));//将数组转成字符串
Arrays.fill(myList, 2);//将对应的数组全部填充为某个值
练习:
1.参照 jdk 开发文档,列出 Arrays 3 个常用的方法,并为该方法准备相应的案例。
六、宠物管理系统
思考:既然 int,float,double… 等都可以有数组,那么可不可以有对象数组呢?
一个宠物场有 4 只宠物,分别是:
名字 体重
- 花花 4.5kg
- 白白 5.6kg
- 黑黑 7.8kg
- 红红 9.0kg
请编写一个程序,可以计算他们的平均体重,可以找出体重最大和最小的宠物的名字,可以通过输入宠物的名字,查找它的体重,参照下面的的面向过程代码完成面向对象的开发模式,并说说两种开发模式的优缺点。
注意:基本数据类型判断值相等一般使用 == 即可,而对于引用数据类型(String、Date 等)必须使用 equals 判断值是否相等。equals 来源于 Object,所有对象都有 equals 方法。
通过功能使用包名区分,view(视图层:负责数据的输入与输出),service(服务层:负责减轻视图层压力),database(数据库层:负责存储数据和提供数据的基本操作),entity(实体层:提供数据对象模型)。并将宠物数据持久化到文件。
根据上面功能,将信息持久化到文件。(持久化:将内存中的数据存入文件或数据库,应用第二次启动后还可以找回原来的数据,这种方式叫做持久化)
面向过程代码:
import java.util.Arrays;
import java.util.Scanner;
public class MainTest {
public static void main(String[] args) {
Pet pets[] = new Pet[4];
Scanner scanner = new Scanner(System.in);
for (int i = 0; i < pets.length; i++) {
System.out.println("请输入第" + (i + 1) + "条宠物的名字");
String name = scanner.next();
System.out.println("请输入" + name + "的体重");
double weight = scanner.nextDouble();
pets[i] = new Pet(name, weight);
}
System.out.println(Arrays.toString(pets));
for (; true; ) {
System.out.println("请输入要执行的操作
1:计算他们的平均体重; 2:找出体重最大和最小的宠物的名字;"+
"3:输入宠物的名字,查找它的体重; 0:退出系统");
int i = scanner.nextInt();
if (i == 1) {//计算他们的平均体重
double sum = 0;
for (Pet dog : pets) {
sum += dog.getWeight();
}
System.out.println("平均体重:" + (sum / pets.length));
}
if (i == 2) {//找出体重最大和最小的宠物的名字
double maxWeight = pets[0].getWeight();
String maxName = pets[0].getName();
for (int i1 = 1; i1 < pets.length; i1++) {
if (pets[i1].getWeight() > maxWeight) {
maxWeight = pets[i1].getWeight();
maxName = pets[i1].getName();
}
}
System.out.println("体重最大:" + maxName);
double minWeight = pets[0].getWeight();
String minName = pets[0].getName();
for (int i1 = 1; i1 < pets.length; i1++) {
if (pets[i1].getWeight() < minWeight) {
minWeight = pets[i1].getWeight();
minName = pets[i1].getName();
}
}
System.out.println("体重最小:" + minName);
}
aa:
if (i == 3) {//输入宠物的名字,查找它的体重
System.out.println("请输入宠物名字");
String name = scanner.next();
for (Pet pet : pets) {
if (pet.getName().equals(name)) {
System.out.println(name + "的体重为:" + pet.getWeight());
break aa;
}
}
System.out.println("查无此宠物");
}
if (i == 0) {//输入宠物的名字,查找它的体重
System.out.println("感谢。。。。。欢迎下次使用");
return;
}
}
}
}
在实际开发中数组很少用到,因为其长度不可变。限制较多,一般采用集合。
七、集合 Collection
Java 标准库自带的 java.util 包提供了集合类:Collection,它是除 Map 外所有其他集合类的根接口。Java 的 java.util 包主要提供了以下三种类型的集合。
- List:一种有序列表的集合,例如,按索引排列的 Student 的 List;
- Set:一种保证没有重复元素的集合,例如,所有无重复对象的 Student 的 Set;
- Map:一种通过键值(key-value)查找的映射表集合,例如,根据 Student 的 name 查找对应 Student 的 Map。
由于 Java 的集合设计非常久远,中间经历过大规模改进,我们要注意到有一小部分集合类是遗留类,不应该继续使用:
- Hashtable:一种线程安全的 Map 实现;
- Vector:一种线程安全的 List 实现;
- Stack:基于 Vector 实现的 LIFO 的栈;
还有一小部分接口是遗留接口,也不应该继续使用:
- Enumeration:已被 Iterator取代。
八、List
在集合类中,List 是最基础的一种集合:它是一种有序列表。
List 的行为和数组几乎完全相同:List 内部按照放入元素的先后顺序存放,每个元素都可以通过索引确定自己的位置,List 的索引和数组一样,从 0 开始。
List 在对象存储与删除方面比数组方便许多。如增加时传入索引,即可完成插队式操作。其他对象的索引会自动递增。删除也是一样,对应的索引会降低。
List 主要有以下几个接口:
-
在末尾添加一个元素:void add(E e)
-
在指定索引添加一个元素:void add(int index, E e)
-
删除指定索引的元素:int remove(int index)
-
删除某个元素:int remove(Object e)
-
获取指定索引的元素:E get(int index)
-
获取链表大小(包含元素的个数):int size()
import java.util.ArrayList;
import java.util.List;public class Test {
public static void main(String[] args) {
List list = new ArrayList();
list.add(null);
list.add(“1”);
list.add(“2”);
list.add(1, “3”);
list.remove(2);
for (int i = 0; i < 100; i++) {
list.add(i);
}
System.out.println(list.size());
}
}
但是,实现 List 接口并非只能通过数组(即 ArrayList 的实现方式)来实现,另一种 LinkedList 通过“链表”也实现了 List 接口。在 LinkedList 中,它的内部每个元素都指向下一个元素:

特点:
1.List 内部的元素可以重复
2.List 还允许添加 null
创建 List
除了使用 ArrayList 和 LinkedList ,我们还可以通过 Arrays 接口提供的 asList() 方法,根据给定元素快速创建 List。使用工具类 Arrays.asList() 把数组转换成集合时,不能使用其修改集合相关的方法,它的 add/remove/clear 方法会抛出 UnsupportedOperationException 异常。
List list = Arrays.asList(1, 2, 5);
遍历 List
和数组类似,我们要遍历一个 List,完全可以用 for 循环根据索引配合 get(index) 方法遍历:
List list = Arrays.asList("apple", "pear", "banana");
for (int i = 0; i < list.size(); i++) {
String s = list.get(i);
System.out.println(s);
}
但这种方式并不推荐,一是代码复杂,二是因为 get(int) 方法只有 ArrayList 的实现是高效的,换成 LinkedList 后,索引越大,访问速度越慢。
所以我们要始终坚持使用迭代器 Iterator 来访问 List 。Iterator 本身也是一个对象,但它是由 List 的实例调用 iterator() 方法的时候创建的。Iterator 对象知道如何遍历一个 List,并且不同的 List 类型,返回的 Iterator 对象实现也是不同的,但总是具有最高的访问效率。
Iterator 对象有两个方法:boolean hasNext() 判断是否有下一个元素,E next() 返回下一个元素。因此,使用 Iterator 遍历 List 代码如下:
List list = Arrays.asList("apple", "pear", "banana");
Iterator it = list.iterator();
while (it.hasNext()) {
String s = it.next();
System.out.println(s);
}
使用 Iterator 访问 List 的代码比使用索引更复杂。但是,要记住,通过 Iterator 遍历 List 永远是最高效的方式。并且,由于 Iterator 遍历是如此常用,所以,Java 的 for each 循环本身就可以帮我们使用 Iterator 遍历。把上面的代码再改写如下:
List list = Arrays.asList("apple", "pear", "banana");
for (String str : list) {
System.out.println(str);
}
如上就是集合的基本操作。
Java 集合的设计有几个特点:
一是接口和实现类相分离,例如,有序表的接口是 List,具体的实现类有 ArrayList,LinkedList 等
二是支持泛型,我们可以限制在一个集合中只能放入同一种数据类型的元素,例如:
List list = new ArrayList<>(); // 只能放入String类型
最后,Java 访问集合总是通过统一的方式——迭代器(Iterator)来实现,它最明显的好处在于无需知道集合内部元素是按什么方式存储的。
List 和 Array 转换
把 List 变为 Array 有如下方法,第一种是调用 toArray() 方法直接返回一个 Object[] 数组:
List list = Arrays.asList("apple", "pear", "banana");
Object[] objects = list.toArray();
System.out.println(Arrays.toString(objects));
这种方法会丢失类型信息,所以实际应用很少。 第二种方式是给toArray(T[])传入一个类型相同的 Array,List 内部自动把元素复制到传入的 Array 中:
List list = Arrays.asList("apple", "pear", "banana");
String[] objects = list.toArray(new String[0]);
System.out.println(Arrays.toString(objects));
如果传入的数组不够大,那么 List 内部会创建一个新的刚好够大的数组,填充后返回;如果传入的数组比 List 元素还要多,那么填充完元素后,剩下的数组元素一律填充 null。
反过来,把 Array 变为 List 就简单多了,通过 Arrays.asList 方法最简单,但是注意生成的集合不能进行增删改:
String[] a = {"apple", "pear", "banana"};
List list = Arrays.asList(a);
练习:(默写 30 分钟)
1.把宠物管理系统的数组改成集合,并添加宠物添加和删除功能。
1:计算他们的平均体重;2:找出体重最大和最小的宠物的名字;3:输入宠物的名字,查找它的体重;4:添加宠物;5删除宠物 0:退出系统
九、重写 equals 方法
我们知道 List 是一种有序列表:List 内部按照放入元素的先后顺序存放,并且每个元素都可以通过索引确定自己的位置。
List 还提供了 boolean contains(Object o) 方法来判断 List 是否包含某个指定元素。此外,int indexOf(Object o) 方法可以返回某个元素的索引,如果元素不存在,就返回 -1。这些在简单类型中基本没有问题。但在我们自定义的一些类中就不是这个结果。
案例:
public class Main {
public static void main(String[] args) {
List list = Arrays.asList(
new Person("Xiao Ming"),
new Person("Xiao Hong"),
new Person("Bob")
);
System.out.println(list.contains(new Person("Bob"))); // false
}
}
class Person {
String name;
public Person(String name) {
this.name = name;
}
}
虽然放入了 new Person(“Bob”),但是用另一个 new Person(“Bob”) 查询不到,原因就是 Person 类没有覆写 equals() 方法。
注意:== 如果是基本数据类型,则比较值是否相等。如果是引用类型,则是比较内存地址是否相等,Object 使用 == 判断对象相等。
重写 equals 方法可以使对象知道按照什么规则判断对象是否相等。
@Override
public boolean equals(Object o) {
if (this == o) return true;//== 如果是基本数据类型,则比较值。如果是特殊类型,则是比较内存地址相等,Object 默认使用
if (o == null || getClass() != o.getClass()) return false;//如果对象为空或类型不对,则认为两个对象不相同
Person person = (Person) o;
return Objects.equals(name, person.name);//返回两个对象的name 是否相等
}
Object:判断内存地址是否相同
public boolean equals(Object obj) {
return (this == obj);
}
String:判断每个字符是否相同
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
如上是常见的 equals 方法。
十、Map
根据前面学习,List 是一种顺序列表,如果有一个存储学生 Student 实例的 List,要在 List 中根据 name 查找某个指定的 Student 的分数,应该怎么办?最简单的方法是遍历 List 并判断 name 是否相等,然后返回指定元素:通过一个键去查询对应的值。使用 List 来实现存在效率非常低的问题,因为平均需要扫描一半的元素才能确定,而 Map 这种键值(key-value)映射表的数据结构,作用就是能高效通过 key 快速查找 value(元素)。
案例:根据 name 查询某个 Student 信息
import java.util.HashMap;
import java.util.Map;
public class MapTest {
public static void main(String[] args) {
Student s1 = new Student("小红", 80);
Map map = new HashMap<>();
map.put("小红", s1);
map.put("小张", new Student("小张", 70));
Student student = map.get("小红");
System.out.println(student == s1);
}
}
class Student {
private String name;
private int score;
public Student(String name, int score) {
this.name = name;
this.score = score;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + ''' +
", score=" + score +
'}';
}
}
通过上述代码可知:Map是一种键-值映射表,当我们调用 put(K key, V value) 方法时,就把 key 和 value 做了映射并放入 Map。当我们调用 V get(K key) 时,就可以通过 key 获取到对应的 value。如果 key 不存在,则返回 null。和 List 类似,Map 也是一个接口,最常用的实现类是 HashMap。
如果只是想查询某个 key 是否存在,可以调用 boolean containsKey(K key)方法。
重复放入 key-value 并不会有任何问题,但是一个 key 只能关联一个 value,也就是说如果以相同的键存入不同元素,则只保留最后一个添加的元素。
遍历 Map
对 Map 来说,要遍历 key 可以使用 for each 循环遍历 Map 实例的 keySet() 方法返回的 Set 集合,它包含不重复的 key 的集合:
Map map = new HashMap<>();
map.put("apple", 123);
map.put("pear", 456);
map.put("banana", 789);
for (String key : map.keySet()) {
Integer value = map.get(key);
System.out.println(key + " = " + value);
}
同时遍历 key 和 value 可以使用 for each 循环遍历 Map对象的 entrySet() 集合,它包含每一个 key-value 映射:
Map map = new HashMap<>();
map.put("apple", 123);
map.put("pear", 456);
map.put("banana", 789);
for (Map.Entry entry : map.entrySet()) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println(key + " = " + value);
}
Map 和 List 不同的是,Map 存储的是 key-value 的映射关系,并且,它不保证顺序。在遍历的时候,遍历的顺序既不一定是 put() 时放入的 key 的顺序,也不一定是 key 的排序顺序。使用 Map 时,任何依赖顺序的逻辑都是不可靠的。以 HashMap 为例,假设我们放入"A",“B”,"C"这 3 个 key,遍历的时候,每个 key 会保证被遍历一次且仅遍历一次,但顺序完全没有保证,甚至对于不同的 JDK 版本,相同的代码遍历的输出顺序都是不同的!
注意:Map 用于存储 key-value 的映射,对于充当 key 的对象,是不能重复的,并且,不但需要正确重写 equals() 方法,还要正确重写 hashCode() 方法。
还有一种 Map,它在内部会对 Key 进行排序,这种 Map 就是 SortedMap。注意到 SortedMap 是接口,它的实现类是 TreeMap。
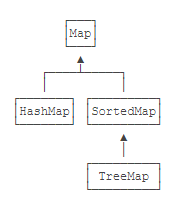
SortedMap 保证遍历时以 Key 的顺序来进行排序。例如,放入的 Key 是"apple"、“pear”、“orange”,遍历的顺序一定是"apple"、“orange”、“pear”,因为 String 默认按字母排序。
练习:
1.使用如下键值对,初始化一个 HashMap: 存储如下键值对
adc - 物理英雄
apc - 魔法英雄
t - 坦克
对这个 HashMap 进行反转,key 变成 value,value 变成 key。
提示: keySet()可以获取所有的 key, values() 可以获取所有的 value。
2.使用 map 完成如下字符串每个字符出现次数的统计。
String s=“字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000”
3.罗马数字包含以下七种字符构成:I, V, X, L,C,D 和 M,它们分别代表以下数值。
字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。
X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。
C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。
给定一个罗马数字,将其转换成整数。输入确保在 1 到 3999 的范围内。
示例 1: 输入: “III” 输出: 3
示例 2: 输入: “IV” 输出: 4
示例 3: 输入: “IX” 输出: 9
示例 4: 输入: “LVIII” 输出: 58
解释: L = 50, V= 5, III = 3.
示例 5: 输入: “MCMXCIV” 输出: 1994
解释: M = 1000, CM = 900, XC = 90, IV = 4.
参考代码:
import java.util.HashMap;
import java.util.Map;
public class MapTest {
private static void t3() {
int out = 0;
String s = "MCMXCIV";
Map map = new HashMap<>();//一种键值对存储结构
map.put('I', 1);
map.put('V', 5);
map.put('X', 10);
map.put('L', 50);
map.put('C', 100);
map.put('D', 500);
map.put('M', 1000);
for (int i = 0; i < s.length(); i++) {
Integer c = map.get(s.charAt(i));
if (i == s.length() - 1) {
out += c;
} else {
Integer next = map.get(s.charAt(i + 1));
if (c >= next) {
out += c;
} else {
out -= c;
}
}
}
System.out.println(out);
}
private static void t2() {
String s = "字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000";
Map map = new HashMap();
char[] chars = s.toCharArray();
for (char c : chars) {
if (map.containsKey(c)) {
map.put(c, map.get(c) + 1);
} else {
map.put(c, 1);
}
}
System.out.println(map);
}
private static void t1() {
Map map = new HashMap<>();
map.put("adc", "物理英雄");
map.put("apc", "魔法英雄");
map.put("t", "坦克");
System.out.println(map);
String[] keys = map.keySet().toArray(new String[0]);//集合转数组
String[] values = map.values().toArray(new String[0]);//集合转数组
map.clear();//清空
for (int i = 0; i < values.length; i++) {
map.put(values[i], keys[i]);
}
System.out.println(map);
}
}
十一、Set
Set 用于存储不重复的元素集合。它主要提供以下几个方法:
- 将元素添加进Set:boolean add(E e)
- 将元素从Set删除:boolean remove(Object e)
- 判断是否包含元素:boolean contains(Object e)
案例:
Set set = new HashSet<>();
System.out.println(set.add("abc")); // true
System.out.println(set.add("xyz")); // true
System.out.println(set.add("xyz")); // false,添加失败,因为元素已存在
System.out.println(set.contains("xyz")); // true,元素存在
System.out.println(set.contains("XYZ")); // false,元素不存在
System.out.println(set.remove("hello")); // false,删除失败,因为元素不存在
System.out.println(set.size()); // 2,一共两个元素
我们经常用 Set 用于去除重复元素。
因为放入 Set 的元素和 Map 的 key 类似,都要正确实现 equals() 和 hashCode() 方法,否则该元素无法正确地放入 Set。
import java.util.*;
public class Hello {
public static void main(String[] args) {
Set set = new HashSet<>();
set.add(new Student("张三"));
set.add(new Student("张三"));
set.add(new Student("张三"));
System.out.println(set);
}
}
class Student {
private String name;
public Student(String name) {
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name);
}
@Override
public String toString() {
return "Student{" +
"name='" + name + ''' +
'}';
}
}
最常用的 Set 实现类是 HashSet,实际上,HashSet 仅仅是对 HashMap 的一个简单封装,Set 接口并不保证有序,而 SortedSet 接口则保证元素是有序的:
- HashSet 是无序的,因为它实现了 Set 接口,并没有实现 SortedSet 接口;
- TreeSet 是有序的,因为它实现了 SortedSet 接口。

使用 TreeSet 和使用 TreeMap 的要求一样,添加的元素必须正确实现 Comparable 接口,如果没有实现 Comparable 接口,那么创建 TreeSet 时必须传入一个 Comparator 对象。
public class Demo {
public static void main(String[] args) {
Set set = new TreeSet<>();
System.out.println(set.add(new User("as")));
System.out.println(set.add(new User("bs")));
System.out.println(set.add(new User("ce")));
System.out.println(set);
}
}
class User implements Comparable{
private String name;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return Objects.equals(name, user.name);
}
@Override
public int hashCode() {
return Objects.hash(name);
}
public User(String name) {
this.name = name;
}
@Override
public int compareTo(User o) {
return this.name.compareTo(o.name);
}
@Override
public String toString() {
return "User{" +
"name='" + name + ''' +
'}';
}
}
练习:
1.现有若干图书信息(包含名称 title、作者 author、定价 price)需要存储到 set 集合中,保证集合中无重复元素,并遍历查看。可以认为所有信息都相同的图书为重复数据。
2.使用集合将全班学生姓名存入一个 Set,再使用随机数抽取出全部学生,以作为下次项目提报的顺序,要保证每次学生抽取的顺序都不相同。
参考代码:
import java.util.HashSet;
import java.util.Objects;
import java.util.Set;
public class SetTest {
public static void main(String[] args) {
t2();
}
private static void t2() {
Set set = new HashSet<>();
set.add("张三");
set.add("张三");
set.add("李四");
set.add("王二");
set.add("麻子");
String[] strings = set.toArray(new String[0]);
int count = 0;
boolean[] flag = new boolean[strings.length];
while (count < strings.length) {
int index = (int) (Math.random() * strings.length);
if (!flag[index]) {
System.out.println(strings[index]);
flag[index] = true;
count++;
}
}
}
private static void t1() {
Set set = new HashSet<>();
set.add(new Book("三国演义", "罗贯中", 100));
set.add(new Book("三国演义", "罗贯中", 100));
set.add(new Book("红楼梦", "曹雪芹", 1000));
for (Book book : set) {
System.out.println(book);
}
}
}
class Book {
private String title;
private String author;
private double price;
public Book(String title, String author, double price) {
this.title = title;
this.author = author;
this.price = price;
}
@Override
public String toString() {
return "Book{" +
"title='" + title + ''' +
", author='" + author + ''' +
", price=" + price +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Book book = (Book) o;
return Double.compare(book.price, price) == 0 &&
Objects.equals(title, book.title) &&
Objects.equals(author, book.author);
}
@Override
public int hashCode() {
return Objects.hash(title, author, price);
}
}
十二、equals() 与 hashCode()
equals() 用于判断两个对象是否相等,在 List 中,contains(包含) 与 indexOf(找到对象的索引) 通常会调用对象的 equals 方法来判断对象是否存在。如果对象没有重写 equals 方法,则使用 object 的 equals 方法(object 的 equals 方法是比较两个对象的内存地址)。
hashCode() 方法用来返回对象的 hash 码,在 HashMap 与 Set 中存储对象时为了快速存取对象,对 map 的键和 set 里面的对象进行 hash 排序,相同 hash 码并不代表对象完全相同,只能代表他们放在同一位置(那个位置是一个链表,不会覆盖),区分 hash 码相同对象必须使用 equals 方法。Object 的 hashode 默认实现通过将对象的内存地址转换为整数来计算对象的哈希码。
hashCode 出现从某种意义上来说,就是为了减少 equals 的次数。从而提高查找的速度。

阿里巴巴开发规范明确规定
只要重写 equals,就必须重写 hashCode;
因为 Set 存储的是不重复的对象,依据 hashCode 和 equals 进行判断,所以 Set 存储的对象必须重写这两个方法;
如果自定义对象做为 Map 的键,那么必须重写 hashCode 和 equals;
String 重写了 hashCode 和 equals 方法,所以我们可以非常愉快地使用 String 对象作为 key 来使用;
如下两个字符串,hash 码相同但是字符串不相同,他们在 Set 中存储的位置相同(该位置是一个链表)。
System.out.println("ABCDEa123abc".hashCode()); // 165374702
System.out.println("ABCDFB123abc".hashCode()); // 165374702
十三、集合排序
有时我们会需要对集合中的数据进行排序,一般实现集合排序有以下两种方法。
方法一: 通过让实体类实现 Comparable 接口,并重写 compareTo 方法,但是这种方法只能针对一个实体进行,不推荐使用。
public class Entity implements Comparable{
String name;
Integer age;
public Entity(String name,Integer age){
this.age=age;
this.name=name;
}
@Override
public int compareTo(Entity o) {
if (this.age>o.age){
return 1;
}else if (this.age 执行时:
List list=new ArrayList<>();
list.add(new Entity("张一",18));
list.add(new Entity("张二",25));
list.add(new Entity("张三",14));
list.add(new Entity("张四",19));
list.add(new Entity("张五",23));
Collections.sort(list);
System.out.println(list);
方法二:通过给 sort 方法传递一个比较器进行比对,也可以 new 一个 Comparator 并在编写处重写比较器的比较方法。
实体类:
public class Entity{
String name;
Integer age;
public Entity(String name, Integer age){
this.age = age;
this.name = name;
}
}
执行时:
List list = new ArrayList<>();
list.add(new Entity("张一", 18));
list.add(new Entity("张二", 25));
list.add(new Entity("张三", 14));
list.add(new Entity("张四", 19));
list.add(new Entity("张五", 23));
list.sort(new Comparator() {
@Override
public int compare(Entity o1, Entity o2) {
return o1.age > o2.age ? 1 : o1.age < o2.age ? -1 : 0;
}
});
System.out.println(list);
其实在真实开发中,排序几乎用不上,一般我们都是使用数据库的排序,一般很少(也不建议)在内存中进行大量数据的排序。
练习:Comparable 接口中 compareTo 方法返回的整数类型支持哪些数字,分别代表哪些意思。
十四、队列 Queue
队列(Queue)是一种常用的集合。Queue 实际上是实现了一个先进先出(FIFO:First In First Out)的有序表。它和 List 的区别在于,List 可以在任意位置添加和删除元素,而 Queue 只有两个操作:
- 把元素添加到队列末尾。
- 从队列头部取出元素。
在 Java 的标准库中,队列接口 Queue 定义了以下几个方法:
- int size():获取队列长度;
- boolean add(E)/boolean offer(E):添加元素到队尾;
- E remove()/E poll():获取队首元素并从队列中删除;
- E element()/E peek():获取队首元素但并不从队列中删除。
注意到添加、删除和获取队列元素总是有两个方法,这是因为在添加或获取元素失败时,这两个方法的行为是不同的。
操作 throw Exception 返回false或null
添加元素到队尾 add(E e) boolean offer(E e)
取队首元素并删除 E remove() E poll()
取队首元素但不删除 E element() E peek()
如:如果调用 add() 方法,当添加失败时(可能超过了队列的容量),它会抛出异常;如果我们调用 offer() 方法来添加元素,当添加失败时,它不会抛异常,而是返回 false。
当我们需要从 Queue 中取出队首元素时,如果当前 Queue 是一个空队列,调用 remove()方法,它会抛出异常;如果我们调用 poll() 方法来取出队首元素,当获取失败时,它不会抛异常,而是返回 null:
案例:
Queue queue = new LinkedList();
queue.offer("张三");
queue.offer("李四");
System.out.println(queue.size());//2
Object pop = queue.poll();//取出对首元素
System.out.println(pop);//张三
System.out.println(queue.size());//1
栈 Stack
栈(Stack)是一种后进先出(LIFO:Last In First Out)的数据结构。
所谓 FIFO,是最先进队列的元素一定最早出队列,而 LIFO 是最后进 Stack 的元素一定最早出 Stack。
因此,Stack 是这样一种数据结构:只能不断地往 Stack 中压入(push)元素,最后进去的必须最早弹出(pop)来:
Stack 只有入栈和出栈的操作:
-
把元素入(压)栈:push(E);
-
把栈顶的元素“弹出”:pop(E);
-
取栈顶元素但不弹出:peek(E)。
Stack stack = new Stack();
stack.push(1);
stack.push(2);
Object pop = stack.pop();
System.out.println(pop);//2
栈和队列基本类似,只需要记住他的数据结构和基本操作方法。
练习:
1.用栈实现队列:栈是先入后出,队列是先入先出。根据这个思想,可以用一个栈作为入队,另一个栈作为出队。
只要把第一个栈的栈顶的元素压入第二个栈就好了,出队的时候输出第二个栈的栈顶,如果第二个栈的空了就需要不断操作从第一个栈的栈顶压入第二个栈,但是如果第一个栈也空了,那就说明所有元素都输出来了。
2.有效的括号
给定一个只包括 ‘(’,’)’,’{’,’}’,’[’,’]’ 的字符串,判断字符串是否有效。 有效字符串需满足: 左括号必须用相同类型的右括号闭合。 左括号必须以正确的顺序闭合。 注意空字符串可被认为是有效字符串。
示例 1: 输入: “()” 输出: true
示例 2: 输入: “()[]{}” 输出: true
示例 3: 输入: “(]” 输出: false
示例 4: 输入: “([)]” 输出: false
示例 5: 输入: “{[]}” 输出: true
3.现在众多编程语言都有许多代码简洁智能的语法糖。请设计 MapUtil 类使其能够不限量的完成单行初始化操作。
MapUtil put = new MapUtil().put("key1", "value1").put("key2", 2).put("key3", true);
System.out.println(put);
参考代码:
import java.util.Stack;
public class StackDemo {
public static void main(String[] args) {
boolean b = t2("(){[([])]}(");
System.out.println(b);
}
private static boolean t2(String s) {
Stack stack = new Stack<>();
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (c == '(' || c == '{' || c == '[') {
stack.push(c);
} else if (!stack.isEmpty()) {
char pop = stack.peek();
if ((c == ')' && pop == '(') || (c == '}' && pop == '{') || (c == ']' && pop == '[')) {
stack.pop();
continue;
}
}
if (stack.empty() && (c == ')' || c == '}' || c == ']')) {
return false;
}
}
return stack.empty();
}
private static void t1() {
StackQueue so = new StackQueue();
so.push(1);
so.push(2);
so.push(3);
so.pop();
so.pop();
so.push(4);
so.pop();
so.push(5);
so.pop();
so.pop();
}
}
class StackQueue {
// 作为入队序列
private Stack stack1 = new Stack();
// 作为出队序列
private Stack stack2 = new Stack();
public void push(int node) {
// 入队时,要保证stack2为空
while (!stack2.empty()) {
stack1.push(stack2.pop());
}
stack1.push(node);
System.out.println("入队元素是:" + stack1.peek());
}
public int pop() {
// 出队时,要保证stack1为空
while (!stack1.empty()) {
stack2.push(stack1.pop());
}
System.out.println("出队元素是:" + stack2.peek());
return stack2.pop();
}
}
public class MapUtil extends HashMap {
@Override
public MapUtil put(String key, Object value) {
super.put(key, value);
return this;
}
}
十五、面向对象和面向过程的区别
面向过程
优点:性能比面向对象高(因为类调用时需要实例化,内存开销比较大,比较消耗系统资源);比如单片机、嵌入式开发、Linux/Unix 等一般采用面向过程开发,性能是最重要的因素。
缺点: 没有面向对象易维护、易复用、易扩展。
面向对象
优点: 易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统更加灵活、更加易于维护。
缺点: 性能比面向过程低。
公司职员薪水管理系统(3天)
功能需求:
- 当有新员工时,将该员工加入到管理系统
- 可以根据员工号,显示该员工的信息
- 可以显示所有员工信息
- 可以修改员工的薪水
- 当员工离职时,将该员工从管理系统中删除
- 可以按照薪水从低到高顺序排序
- 可以统计员工的平均工资,最低工资,最高工资
- 员工数据持久化到硬盘文件,第二次启动数据还存在
- 员工数据每 5 秒保存一次,防止意外断电造成数据丢失
规范需求:
1.要求使用面向对象的编程规范分包开发 entity(实体),database(数据库层) , service(服务层),view(视图层),scheduled(定时任务)
2.数据库层提供员工集合的存储和提供基本的增删改查方法。
3.服务层为视图层提供方法服务。
4.视图层负责输出效果和简单的输入输出。
5.实体层负责存储对象模型(Employee)。
6.实体不允许写过多的方法,只允许 get、set、constructor 和 tostring 等方法,且该方法内不能做无关的运算。
提交内容:
1.专业视频(介绍项目软件的使用)
2.专业 ppt(吸引用户购买,类似于软件新品发布会)
3.源代码(项目的src目录)
4.运行软件及启动脚本(本质还是文本文件)
start.bat(windows 上的启动文件)
start java cn.hx.view.View
start.sh(Linux 上的启动文件)
java cn.hx.view.View
下面为面向过程的代码演示,真实项目必须使用面向对象的设计思想开发。
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Scanner;
public class EmployeeSystem {
public static void main(String[] args) {
ArrayList list = new ArrayList<>();
Scanner scanner = new Scanner(System.in);
while (true) {
System.out.println("公司职员薪水管理系统
1、录入新员工
2、根据工号查询信息" +
"
3、查询所有员工信息
4、通过工号修改员工薪水
5、删除员工信息
6、按薪水高低排序" +
"
7、计算平均工资及最高(低)工资
0、退出系统
请输入对应的数字进行操作:");
int order = scanner.nextInt();
if (order == 1) {
System.out.println("请录入新员工的信息");
System.out.print("工号:");
String id = scanner.next();
System.out.print("姓名:");
String name = scanner.next();
System.out.print("工资:");
float salary = scanner.nextFloat();
Employee employee = new Employee(id, name, salary);
list.add(employee);
System.out.println("创建新员工" + name + "成功!");
} else if (order == 2) {
System.out.println("请录入员工工号:");
String id = scanner.next();
for (int i = 0; i < list.size(); i++) {
Employee employee = list.get(i);
if (employee.getId().equals(id)) {
System.out.println("找到该员工,他的信息是:");
System.out.println("工号:" + id + " 姓号:" + employee.getName()
+ " 薪水:" + employee.getSalary());
} else {
System.out.println("工号不存在或无此人!");
}
}
} else if (order == 3) {
System.out.println("公司所有员工信息如下:");
for (Employee employee : list) {
System.out.println("工号:" + employee.getId() + " 姓名:"
+ employee.getName() + " 工资:" + employee.getSalary());
}
} else if (order == 4) {
System.out.println("请输入工号:");
String id = scanner.next();
System.out.println("将工资修改为:");
float newSalary = scanner.nextFloat();
for (int i = 0; i < list.size(); i++) {
Employee employee = list.get(i);
if (employee.getId().equals(id)) {
employee.setSalary(newSalary);
System.out.println("已将" + employee.getName() + "调整为:" + newSalary);
}
}
System.out.println("工号不存在或无此人,无法进行相应操作!");
} else if (order == 5) {
System.out.println("请输入要删除人员的工号:");
String id = scanner.next();
for (int i = 0; i < list.size(); i++) {
Employee employee = list.get(i);
if (employee.getId().equals(id)) {
list.remove(i);
System.out.println("已将" + employee.getName() + "信息清除!");
}
}
} else if (order == 6) {
System.out.println("已按薪资高低进行排序如下:");
list.sort(new Comparator() {
@Override
public int compare(Employee o1, Employee o2) {
return (int) (o1.getSalary() - o2.getSalary());
}
});
for (Employee employee : list) {
System.out.println("工号:" + employee.getId() + " 姓名:"
+ employee.getName() + " 工资:" + employee.getSalary());
}
} else if (order == 7) {
System.out.println("显示平均工资及最高、最低工资人员信息如下:");
double sum = 0f;
for (int k = 0; k < list.size(); k++) {
Employee Employee = list.get(k);
sum = Employee.getSalary() + sum;
}
System.out.println("共有员工" + list.size() + "人 总工资为:" + sum
+ " 平均工资为:" + sum / list.size());
list.sort(new Comparator() {
@Override
public int compare(Employee o1, Employee o2) {
return (int) (o1.getSalary() - o2.getSalary());
}
});
for (int i = 0; i < list.size(); i++) {
if (i == 0) {
Employee Employee = list.get(i);
System.out.println("工资最高的人员是:" + Employee.getName()
+ " 薪水是:" + Employee.getSalary());
} else if (i == list.size() - 1) {
Employee Employee = list.get(i);
System.out.println("工资最低的人员是:" + Employee.getName()
+ " 薪水是:" + Employee.getSalary());
}
}
} else if (order == 0) {
System.out.println("已正常退出!");
scanner.close();
System.exit(0);
} else {
System.out.println("输入错误,请重新输入!");
}
}
}
}
class Employee {
private String id;
private String name;
private double salary;
//....
}