线段最大重合问题:最多有多少条线段是重合的
线段最大重合问题:最多有多少条线段是重合的?
提示:这可不是线段树了哦
单纯的贪心问题,这种贪心的问题,互联网大厂经常改编一下来考你,往往是先排序某一个参数,再排序某一个参数,离不开有序表和堆的结合
堆和有序表结合的贪心考题类型,几乎是互联网大厂的第一题的标配题型,因此理解本题,对于你应对大厂笔试有非常大的帮助
文章目录
- 线段最大重合问题:最多有多少条线段是重合的?
-
- @[TOC](文章目录)
- 题目
- 一、审题
- 暴力解:不可取
- 有序表结合小根堆:贪心算法
- 总结
文章目录
- 线段最大重合问题:最多有多少条线段是重合的?
-
- @[TOC](文章目录)
- 题目
- 一、审题
- 暴力解:不可取
- 有序表结合小根堆:贪心算法
- 总结
题目
线段最大重合问题:
有一个N*2二维数组arr,每一个arr[i][0]–arr[i][1]代表一条线段的起点和终点
可能某些线段就重合了,请问你最多有多少条线段重合?
所谓重合就是一条线段的start < 另一条线段的end

一、审题
示例:
arr=
1 3
2 6
4 8

暴力解:不可取
暴力解很容易
M条线段
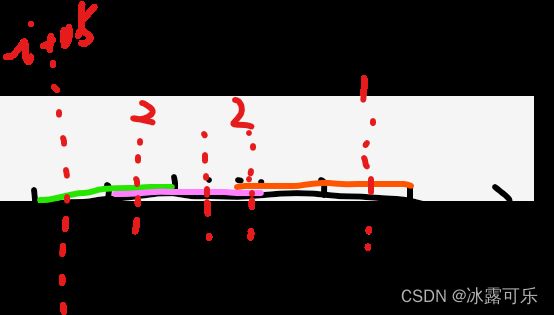
(1)咱们先寻找所有线段中end的最大值N
(2)然后从i=0+0.5开始索引,检查每一个i=0+0.5的点
暴力对比所有的M条线段,有谁都是start–end包围i=0+0.5,统计次数count++,代表覆盖i=0+0.5点的有多少个重合线条
每次统计完,都把i=0+0.5的统计重合条数count,更新给max
这代码就不必仔细写了,你知道暴力解的复杂度高,为啥呢?
遍历N个点,每次对比M条线段
最少也是o(n*m)复杂度
代码你看看就行
//第一暴力法:适合笔试:
//小技巧,因为线段的起点和终点都是整数,所以,我们统计,所有线段起点的最小值,min
//再统计所有线段终点的最大值,这样固定在min和max之间
//利用线段的中点0.5来看,当p==min+0.5开始算,每递增1,都差所有的线段,有包含这个p,一定是重合的
//统计经过p的线段数量是多少,最后
//p个count值,取最大即可
public static int maxCoverCount1(int[][] m){
//给你一个数组,二维的,每个数组0位是起点,1位是终点
//统计左右边界
int L = Integer.MAX_VALUE;
int R = Integer.MIN_VALUE;
for (int i = 0; i < m.length; i++) {
L = Math.min(L, m[i][0]);
R = Math.max(R, m[i][1]);
}
//按照0.5开始暴力寻找覆盖数
int max = 0;
for (double p = L + 0.5; p < R; p+=1) {
//每次递增1
int cur = 0;
for (int i = 0; i < m.length; i++) {
if (m[i][0] < p && p < m[i][1]) cur++;//一旦包含了p,必定重合过
}
//所有线段走一遍,统计最大重复数
max = Math.max(max, cur);
}
//统计完所有p
return max;
}
public static void test(){
int[][] m = {
{1,2},
{1,3},
{3,5},
{4,6},
{8,9}
};//目前重合有4段,但是最大的重合在一段上的只有2,2只最大值2段
System.out.println(maxCoverCount1(m));
}
结果自然OK,就是太复杂,实在不行,笔试时你想不出来方案,就这代码能帮你通过60%的测试案例吧。
2
有序表结合小根堆:贪心算法
这种类似于会议安排问题,往往都是贪心算法,要排序和小根堆结合,解决
会议也是跟线段一样的数据结构,有start和end。
本题的解题思想:
咱们说,啥叫重合?就是有些线条的end>我线的start
咱们这么想,能不能不要暴力查找N个节点 ,而只看线段的start节点们
考虑当前线段的start,看看M条线段,有谁的end会>我线的start,统计这个量就是跟我线重合的数量
每次都要去重复查M条线段吗?不需要!
咱们这么搞
解题流程:
(1)将线段整合为Line数据结构
//线段的数据结构:
public static class LineReview{
public int start;
public int end;
public LineReview(int s, int e){
start = s;
end = e;
}
}
(2)将lines 按照每条线段的start升序排序
线段的排序比较器:
//线段cur按照start排序升序
public static class startReviewComparator implements Comparator<LineReview>{
@Override
public int compare(LineReview o1, LineReview o2){
return o1.start - o2.start;//返回-1,o1放前面
}
}
(3)准备一个小根堆heap,排序方式是线段的end升序排列
小根堆的比较器:
//线段cur按照end升序降序,小根堆的比较器
public static class endReviewComparator implements Comparator<LineReview>{
@Override
public int compare(LineReview o1, LineReview o2){
return o1.end - o2.end;//返回-1,o1放上面
}
}
(4)遍历lines的每一条线i,看看有多少条线会影响我,跟我重合,更新max
具体咋操作呢?就是让小根堆中end<=line[i].start的那些线段,弹出去,他们不会跟我重合的
然后把我line[i]加入小根堆,此时能影响我line[i]的线段们都留在小根堆中了,小根堆的size就是重合数量,更新给max
(5)所有线段操作完,自然结果max已经得到了最大值。
为什么要按照start排序好之后往小根堆放,为何小根堆又是按照end升序排序的?
目的,就是为了在检查当前线段cur时,以便快速让所有M条能影响我的线段,都进堆来【他们end>cur.start,就会影响我】
而且是cur之前的那些线段,循序渐进地进堆,不用我再每次都去遍历M条线段,在这就节约了大量时间。
与此同时,无法影响我cur的线段都不会在小根堆中【他们的end<=cur.start】
另外,我cur之后的那些线段,我暂时都不用放进小根堆的
这里特别注意,你别犯糊涂,想着我cur的end会影响谁呢?我cur后面的线段,先不管,暂不考虑,因为后续还要单独考察他们的start,到后面,我cur.end会影响他们的话,自然会统计在内,更新给max的。
没看明白上面的解释,没关系,咱们看个例子:
咱举个例子你就明白:
arr=
1 6
1 3
2 5
4 7
(1)将线段整合为Line数据结构lines
(2)将lines 按照每条线段的start升序排序 ,上面的顺序基本OK
(3)准备一个小根堆heap,排序方式是线段的end升序排列 ,heap准备好,看下图中heap。
(4)遍历lines的每一条线i,看看有多少条线会影响我,跟我重合,更新max
具体咋操作呢?就是让小根堆中end<=line[i].start的那些线段,弹出去,他们不会跟我重合的
然后把我line[i]加入小根堆,此时能影响我line[i]的线段们都留在小根堆中了,小根堆的size就是重合数量,更新给max
(5)所有线段操作完,结果max已经得到了最大值。
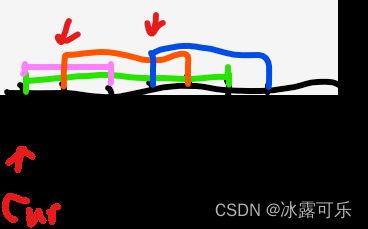
第一次cur线条是:1 6
检查heap有谁的end<=cur.start=1的?没有,不管,直接让cur进堆,统计此时heap.size(),就是max=1
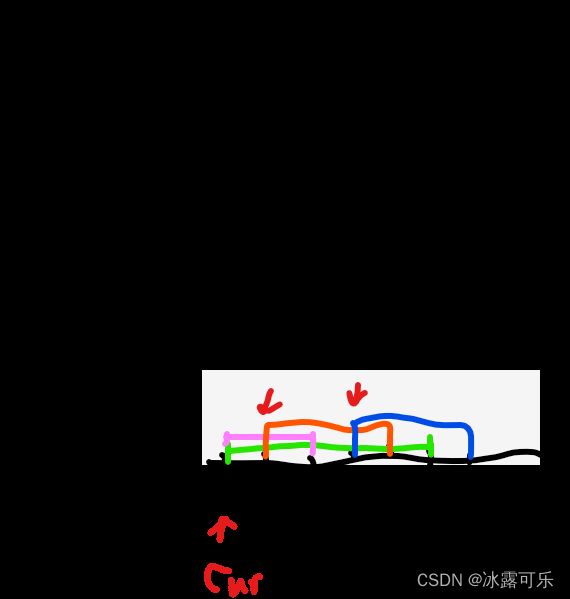
第2次cur线条是:1 3
检查heap有谁的end<=cur.start=1的?没有,不管,直接让cur进堆,统计此时heap.size(),就是max=2
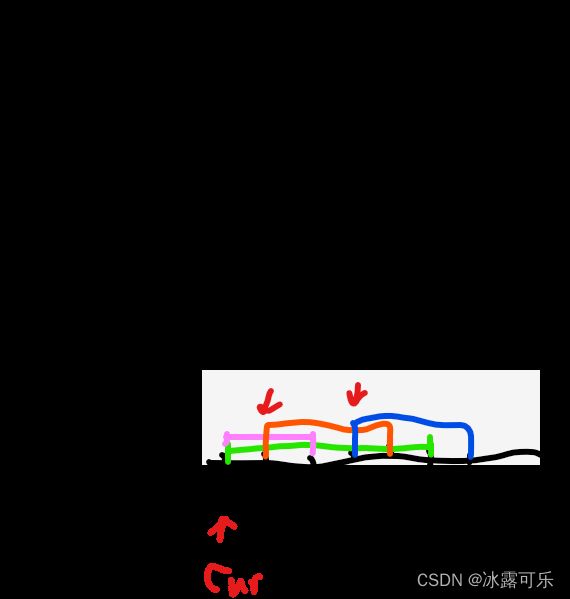
第3次cur线条是:2 5
检查heap有谁的end<=cur.start=2的?目前两条线的end是3和6,都比2大,没有<=2,不管,
直接让cur进堆,堆会按照end自动排序,小的放上面哦,统计此时heap.size(),就是max=3
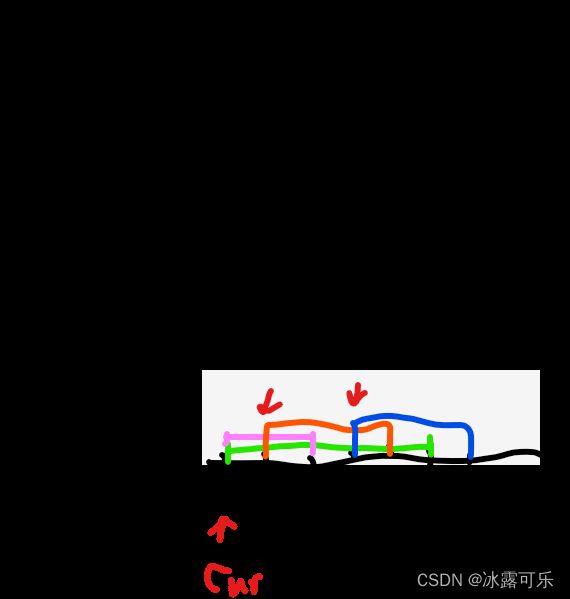
第4次cur线条是:4 7
检查heap有谁的end<=cur.start=4的?目前1 3线条的end是3<=4,将它弹出,因为它不满足重合我cur的条件【x.end>cur.start才叫重合】,
然后让cur进堆,堆会按照end自动排序,小的放上面哦,统计此时heap.size(),就是max=3
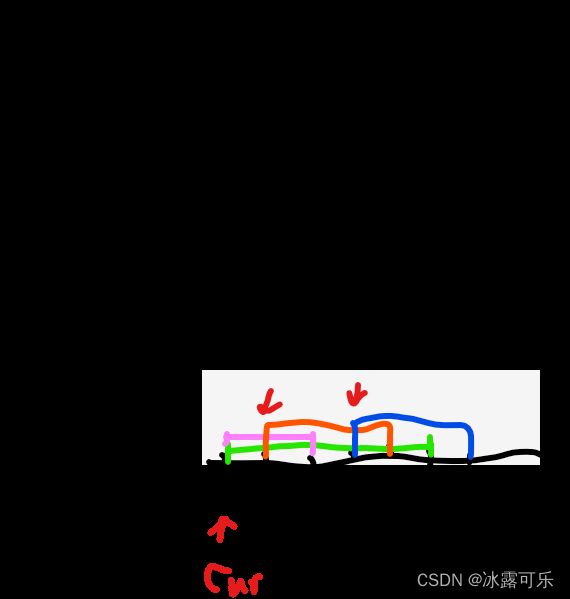
咋样?能理解了不?
我们为啥不担心我cur对后面的线段的影响呢?没事,考虑当前线段cur时,只看前面的线条,我对后面的考虑,后面再说
我们跟随重合的定义来收集答案,x.end>cur.start叫重合,那我就不看cur.end是不是大于后面其他它x.start的事情,早晚我们会去看后边那些x线段的重合情况,都会更新给max
因此,每次只考虑cur之前,谁会影响我cur.start而与我重合,后面的不管,未来都会被更新给max
OK,咱们看看算法的时间复杂度,
(2)排序那o(mlog(m))
(4)放小根堆收集结果那,只每次都考了一个start,一共m条线段,每次cur进小根堆需要o(log(m))排序,故复杂度o(mlog(m))
(2)(4)串行的,所以只考虑这俩最大值就行,复杂度最终是:o(mlog(m))
okay,捋清楚了解题流程,咱们上手撸代码:
(1)将线段整合为Line数据结构lines
(2)将lines 按照每条线段的start升序排序
(3)准备一个小根堆heap,排序方式是线段的end升序排列
(4)遍历lines的每一条线i,看看有多少条线会影响我,跟我重合,更新max
具体咋操作呢?就是让小根堆中end<=line[i].start的那些线段,弹出去,他们不会跟我重合的
然后把我line[i]加入小根堆,此时能影响我line[i]的线段们都留在小根堆中了,小根堆的size就是重合数量,更新给max
(5)所有线段操作完,结果max已经得到了最大值。
手撕代码如下:
public static int mostNumCoverLine(int[][] arr){
if (arr == null || arr.length == 0) return 0;
//(1)将线段整合为Line数据结构lines
int N = arr.length;
LineReview[] lines = new LineReview[N];
for (int i = 0; i < N; i++) {
lines[i] = new LineReview(arr[i][0], arr[i][1]);//变统一的线段数据结构
}
//(2)将lines **按照每条线段的start升序排序**
Arrays.sort(lines, new startReviewComparator());
//(3)准备一个小根堆heap,排序方式是**线段的end降序排列**
PriorityQueue<LineReview> heap = new PriorityQueue<>(new endReviewComparator());
int max = 0;
//(4)遍历lines的每一条线i,看看有多少条线会影响我,跟我重合,更新max
for (int i = 0; i < N; i++) {
LineReview cur = lines[i];//当前线段
//具体咋操作呢?就是让**小根堆中end<=line[i].start的那些线段,弹出去,他们不会跟我重合的**
while (!heap.isEmpty() && heap.peek().end <= cur.start) heap.poll();
//然后把我line[i]加入小根堆,此时能影响我line[i]的线段们都留在小根堆中了,
heap.add(cur);
// 小根堆的size就是重合数量,更新给max
max = Math.max(max, heap.size());
}
//(5)所有线段操作完,结果max已经得到了最大值。
return max;
}
这个代码,是比暴力解复杂了点,但是它就是速度快,o(mlog(m))的速度,
比你**o(n*m)**快多了,往往n>>m的
测试一把:
public static void test2(){
int[][] m = {
{1,2},
{1,3},
{3,5},
{4,6},
{8,9}
};//目前重合有4段,但是最大的重合在一段上的只有2,2只最大值2段
System.out.println(maxCoverCount2(m));
System.out.println(mostNumCoverLine(m));
}
public static void main(String[] args) {
test();
test2();
}
看结果:
2
2
2
本题是一定要思考清楚它贪心的思想,加速点在哪?
本质上本题还是一个舍弃贪心的思想,舍弃那些没必要对比的边界,只看每条线段的start,
面对每条start,不要对比所有m条线段,去暴力搜索谁与我重合,而是用小根堆排除那些不与我重合的线段就行。
我cur后面的线段暂不考虑进来,因为每个线段,前面谁影响它,我们都会更新max的,因此不会漏掉的。
本题这个贪心的点在于:
(1)节约了大量时间暴力搜索i+0.5那些位置,咱们直接看每一个cur.start边界,按照定义判断谁影响我就行。
(2)每次看cur.start时,暴力解都要看所有的m条线段谁能包含i+0.5这个点,咱们贪心先把线段按照start排序,前面依次进堆,堆又按照end排序,这样,检查堆顶,就能很快就能锁定那些前面的线段,那些x.end<=cur.start的的线段x弹出,节约了大量的搜索时间
这俩贪心的点,能大大加速咱们的算法解题流程,还不会漏解。
总结
提示:重要经验:
1)本质上本题还是一个舍弃贪心的思想,舍弃那些没必要对比的边界,只看每条线段的start,先按照start排序线段,同时面对每条start,不要对比所有m条线段,去暴力搜索谁与我重合,而是用小根堆排除那些不与我重合的线段就行。
2)堆和有序表结合的贪心考题类型,几乎是互联网大厂的第一题的标配题型,因此理解本题,对于你应对大厂笔试有非常大的帮助
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。